COAL: Counterfactual and Observation-Enhanced Alignment Learning for Discriminative Referring Multi-Object Tracking
Pith reviewed 2026-06-30 21:18 UTC · model grok-4.3
The pith
COAL resolves the sparsity-discriminability paradox in referring multi-object tracking by densifying semantic supervision with vision-language models and counterfactual augmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
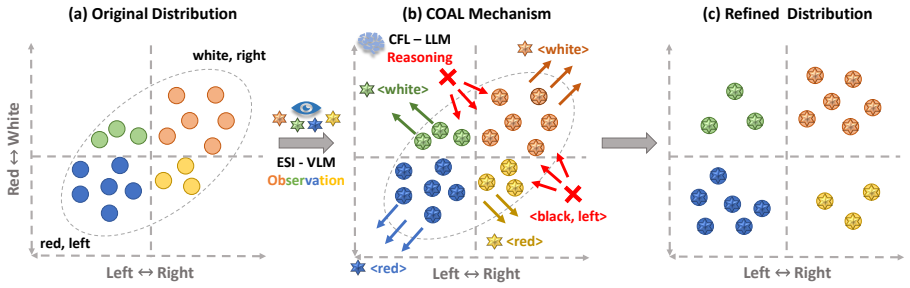
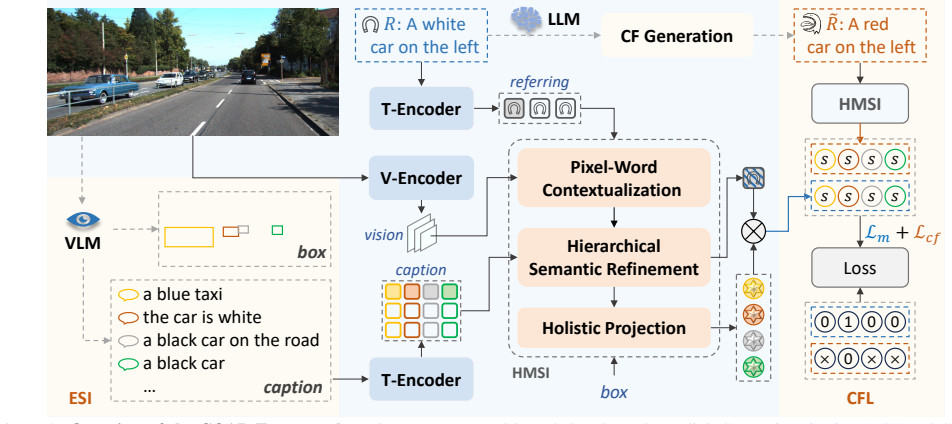
COAL advances RMOT by introducing Explicit Semantic Injection via VLM to densify the observation space and Counterfactual Learning via LLM to augment supervision and enforce attribute verification. These are unified in the Hierarchical Multi-Stream Integration architecture to distill external knowledge into discriminative representations, resulting in a 7.28% HOTA improvement on Refer-KITTI-V2.
What carries the argument
Hierarchical Multi-Stream Integration (HMSI) architecture that integrates Explicit Semantic Injection (ESI) and Counterfactual Learning (CFL) to perform knowledge regularization.
If this is right
- Densifies the observation space to enhance instance discriminability in homogeneous scenarios.
- Augments supervision through counterfactual examples to enforce attribute verification and reduce semantic collapse.
- Achieves state-of-the-art performance with a 7.28% HOTA gain on the Refer-KITTI-V2 benchmark.
Where Pith is reading between the lines
- Similar knowledge regularization could be applied to other sparse-supervision problems in computer vision such as referring segmentation.
- Effectiveness may vary with the accuracy and domain alignment of the chosen VLM and LLM.
- The hybrid architecture suggests potential for end-to-end variants that reduce reliance on external model calls at inference time.
Load-bearing premise
The VLM and LLM outputs for semantic injection and counterfactual augmentation are sufficiently accurate and do not introduce new biases or shortcut opportunities in the target domain.
What would settle it
An ablation study on Refer-KITTI-V2 that removes the ESI and CFL components and shows no performance gain over prior methods would falsify the claim that knowledge regularization resolves the paradox.
Figures

read the original abstract
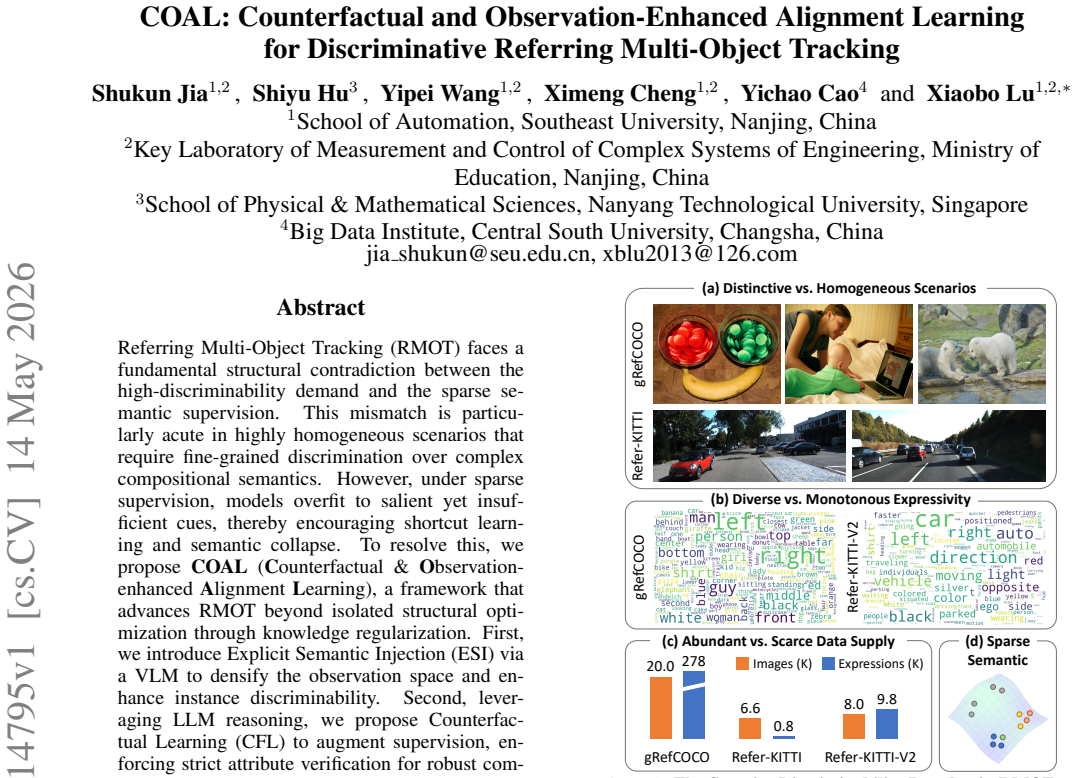
Referring Multi-Object Tracking (RMOT) faces a fundamental structural contradiction between the high-discriminability demand and the sparse semantic supervision. This mismatch is particularly acute in highly homogeneous scenarios that require fine-grained discrimination over complex compositional semantics. However, under sparse supervision, models overfit to salient yet insufficient cues, thereby encouraging shortcut learning and semantic collapse. To resolve this, we propose COAL (Counterfactual and Observation-enhanced Alignment Learning), a framework that advances RMOT beyond isolated structural optimization through knowledge regularization. First, we introduce Explicit Semantic Injection (ESI) via a VLM to densify the observation space and enhance instance discriminability. Second, leveraging LLM reasoning, we propose Counterfactual Learning (CFL) to augment supervision, enforcing strict attribute verification for robust compositional recognition. These strategies are unified within a Hierarchical Multi-Stream Integration (HMSI) architecture, which distills external knowledge into domain-specific discriminative representations. Experiments on Refer-KITTI and Refer-KITTI-V2 benchmarks validate COAL's efficacy. Notably, it surpasses the state-of-the-art by 7.28% HOTA on the highly challenging Refer-KITTI-V2. These results demonstrate the effectiveness of knowledge regularization for resolving the sparsity-discriminability paradox in RMOT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents COAL, a framework for Referring Multi-Object Tracking (RMOT) that addresses the sparsity-discriminability paradox via knowledge regularization. It introduces Explicit Semantic Injection (ESI) using a VLM to densify the observation space, Counterfactual Learning (CFL) using an LLM to augment supervision with strict attribute verification, and unifies them in a Hierarchical Multi-Stream Integration (HMSI) architecture. Experiments on Refer-KITTI and Refer-KITTI-V2 report a 7.28% HOTA gain over state-of-the-art on the latter benchmark.
Significance. If the central claims hold after verification of the external model outputs, the work would be significant for RMOT by demonstrating how VLM/LLM knowledge can densify sparse supervision and reduce shortcut learning in homogeneous scenes. The combination of explicit semantic injection and counterfactual augmentation offers a concrete mechanism for compositional discrimination that could influence other tracking and referring tasks facing similar supervision mismatches.
major comments (3)
- [Abstract] Abstract: the 7.28% HOTA improvement on Refer-KITTI-V2 is stated without baseline scores, per-method breakdowns, or ablation isolating ESI versus CFL contributions, preventing assessment of whether the gain is load-bearing or attributable to the proposed modules.
- [Methods] Methods (ESI/CFL sections): no error rates, human validation, or domain-specific accuracy metrics are supplied for the VLM outputs in ESI or the LLM-generated counterfactuals in CFL; without these, the claim that these modules resolve rather than propagate semantic collapse cannot be evaluated.
- [Experiments] Experiments: the assumption that VLM/LLM signals are unbiased for fine-grained RMOT attributes is load-bearing for the entire performance delta, yet no ablation or failure-case analysis on Refer-KITTI-V2 is described to test whether mislabeled attributes introduce new shortcuts.
minor comments (1)
- [Abstract] The phrase 'sparsity-discriminability paradox' is used without a formal definition or citation to prior literature on similar supervision issues in referring tasks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that directly strengthen the manuscript's transparency and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 7.28% HOTA improvement on Refer-KITTI-V2 is stated without baseline scores, per-method breakdowns, or ablation isolating ESI versus CFL contributions, preventing assessment of whether the gain is load-bearing or attributable to the proposed modules.
Authors: We agree that the abstract would benefit from additional context. In the revised version we will report the baseline HOTA scores of the compared methods on Refer-KITTI-V2, include a concise per-method breakdown, and summarize the ablation isolating ESI versus CFL contributions so readers can directly evaluate the source of the reported gain. revision: yes
-
Referee: [Methods] Methods (ESI/CFL sections): no error rates, human validation, or domain-specific accuracy metrics are supplied for the VLM outputs in ESI or the LLM-generated counterfactuals in CFL; without these, the claim that these modules resolve rather than propagate semantic collapse cannot be evaluated.
Authors: We acknowledge that quantitative validation of the external modules is necessary to support the claim. Although the original submission focused on end-to-end tracking performance, we will add error rates, human validation statistics, and domain-specific accuracy metrics for both the VLM outputs in ESI and the LLM-generated counterfactuals in CFL to the revised methods section. revision: yes
-
Referee: [Experiments] Experiments: the assumption that VLM/LLM signals are unbiased for fine-grained RMOT attributes is load-bearing for the entire performance delta, yet no ablation or failure-case analysis on Refer-KITTI-V2 is described to test whether mislabeled attributes introduce new shortcuts.
Authors: The concern about potential bias and new shortcuts is valid. We will incorporate an ablation study together with a failure-case analysis focused on Refer-KITTI-V2 that explicitly examines whether mislabeled attributes from the external models introduce unintended shortcuts, thereby testing the robustness of the performance delta. revision: yes
Circularity Check
No circularity; method uses external pre-trained VLM/LLM without self-referential reduction
full rationale
The paper describes COAL as a framework that applies Explicit Semantic Injection via VLM and Counterfactual Learning via LLM within a Hierarchical Multi-Stream Integration architecture to address the sparsity-discriminability paradox in RMOT. No equations, fitting procedures, or derivation steps appear in the provided text. The approach depends on external pre-trained models for knowledge regularization rather than any internal definitions, fitted parameters renamed as predictions, or self-citation chains that reduce the central claim to its own inputs. Empirical results on Refer-KITTI-V2 are presented as validation, not as a mathematical derivation that collapses by construction. This is a standard non-circular empirical method paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained VLMs and LLMs produce sufficiently accurate and unbiased semantic and counterfactual signals for the RMOT task.
Reference graph
Works this paper leans on
-
[1]
Refergpt: To- wards zero-shot referring multi-object tracking
[Chamitiet al., 2025 ] Tzoulio Chamiti, Leandro Di Bella, Adrian Munteanu, and Nikos Deligiannis. Refergpt: To- wards zero-shot referring multi-object tracking. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 3849–3858,
2025
-
[2]
Multi-granularity local- ization transformer with collaborative understanding for referring multi-object tracking.IEEE Transactions on In- strumentation and Measurement,
[Chenet al., 2025 ] Jiajun Chen, Jiacheng Lin, Guojin Zhong, You Yao, and Zhiyong Li. Multi-granularity local- ization transformer with collaborative understanding for referring multi-object tracking.IEEE Transactions on In- strumentation and Measurement,
2025
-
[3]
ikun: Speak to trackers without retrain- ing
[Duet al., 2024 ] Yunhao Du, Cheng Lei, Zhicheng Zhao, and Fei Su. ikun: Speak to trackers without retrain- ing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19135– 19144,
2024
-
[4]
Visual-linguistic representation learning with deep cross-modality fusion for referring multi-object tracking
[Heet al., 2024 ] Wenyan He, Yajun Jian, Yang Lu, and Hanzi Wang. Visual-linguistic representation learning with deep cross-modality fusion for referring multi-object tracking. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6310–6314. IEEE,
2024
-
[5]
Toward modalities correlation for rgb-t tracking.IEEE Trans- actions on Circuits and Systems for Video Technology, 34(10):9102–9111,
[Huet al., 2024 ] Xiantao Hu, Bineng Zhong, Qihua Liang, Shengping Zhang, Ning Li, and Xianxian Li. Toward modalities correlation for rgb-t tracking.IEEE Trans- actions on Circuits and Systems for Video Technology, 34(10):9102–9111,
2024
-
[6]
Curriculum adaptation for one-stream rgb– t tracking.Pattern Recognition, page 113494,
[Huet al., 2026 ] Xiantao Hu, Fansheng Zeng, Bineng Zhong, Zhangyong Tang, Wenxuan Fang, Jun Li, Ying Tai, and Jian Yang. Curriculum adaptation for one-stream rgb– t tracking.Pattern Recognition, page 113494,
2026
-
[7]
[Huanget al., 2024 ] Wenjun Huang, Yang Ni, Hanning Chen, Yirui He, Ian Bryant, Yezi Liu, and Mohsen Imani. Tell me what to track: Infusing robust language guid- ance for enhanced referring multi-object tracking.arXiv preprint arXiv:2412.12561,
-
[8]
[Liet al., 2025a ] Weize Li, Yunhao Du, Qixiang Yin, Zhicheng Zhao, Fei Su, and Daqi Liu. Just functioning as a hook for two-stage referring multi-object tracking.arXiv preprint arXiv:2503.07516,
-
[9]
Cognitive dis- entanglement for referring multi-object tracking.Informa- tion Fusion, page 103349,
[Lianget al., 2025 ] Shaofeng Liang, Runwei Guan, Wang- wang Lian, Daizong Liu, Xiaolou Sun, Dongming Wu, Yutao Yue, Weiping Ding, and Hui Xiong. Cognitive dis- entanglement for referring multi-object tracking.Informa- tion Fusion, page 103349,
2025
-
[10]
Echotrack: Auditory referring multi-object tracking for autonomous driving.IEEE Transactions on Intelligent Transportation Systems,
[Linet al., 2024 ] Jiacheng Lin, Jiajun Chen, Kunyu Peng, Xuan He, Zhiyong Li, Rainer Stiefelhagen, and Kailun Yang. Echotrack: Auditory referring multi-object tracking for autonomous driving.IEEE Transactions on Intelligent Transportation Systems,
2024
-
[11]
Gres: Generalized referring expression segmenta- tion
[Liuet al., 2023 ] Chang Liu, Henghui Ding, and Xudong Jiang. Gres: Generalized referring expression segmenta- tion. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 23592–23601,
2023
-
[12]
Grounding dino: Marrying dino with grounded pre-training for open-set object detec- tion
[Liuet al., 2024 ] Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detec- tion. InEuropean conference on computer vision, pages 38–55. Springer,
2024
-
[13]
Hota: A higher order metric for evalu- ating multi-object tracking.International journal of com- puter vision, 129(2):548–578,
[Luitenet al., 2021 ] Jonathon Luiten, Aljosa Osep, Patrick Dendorfer, Philip Torr, Andreas Geiger, Laura Leal-Taix´e, and Bastian Leibe. Hota: A higher order metric for evalu- ating multi-object tracking.International journal of com- puter vision, 129(2):548–578,
2021
-
[14]
[Lvet al., 2025 ] Weiyi Lv, Ning Zhang, Hanyang Sun, Haoran Jiang, Kai Zhao, Jing Xiao, and Dan Zeng. Vision-motion-reference alignment for referring multi- object tracking via multi-modal large language models. arXiv preprint arXiv:2511.17681,
-
[15]
Mls-track: Multilevel semantic interaction in rmot.arXiv preprint arXiv:2404.12031,
[Maet al., 2024 ] Zeliang Ma, Song Yang, Zhe Cui, Zhicheng Zhao, Fei Su, Delong Liu, and Jingyu Wang. Mls-track: Multilevel semantic interaction in rmot.arXiv preprint arXiv:2404.12031,
-
[16]
Learning transferable visual models from nat- ural language supervision
[Radfordet al., 2021 ] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from nat- ural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR,
2021
-
[17]
[Renet al., 2024 ] Tianhe Ren, Yihao Chen, Qing Jiang, Zhaoyang Zeng, Yuda Xiong, Wenlong Liu, Zhengyu Ma, Junyi Shen, Yuan Gao, Xiaoke Jiang, et al. Dino-x: A unified vision model for open-world object detection and understanding.arXiv preprint arXiv:2411.14347,
-
[18]
Referring multi-object tracking
[Wuet al., 2023 ] Dongming Wu, Wencheng Han, Tiancai Wang, Xingping Dong, Xiangyu Zhang, and Jianbing Shen. Referring multi-object tracking. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14633–14642,
2023
-
[19]
[Yanget al., 2025 ] An Yang, Anfeng Li, Baosong Yang, Be- ichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Bytetrack: Multi-object track- ing by associating every detection box
[Zhanget al., 2022 ] Yifu Zhang, Peize Sun, Yi Jiang, Dong- dong Yu, Fucheng Weng, Zehuan Yuan, Ping Luo, Wenyu Liu, and Xinggang Wang. Bytetrack: Multi-object track- ing by associating every detection box. InEuropean con- ference on computer vision, pages 1–21. Springer,
2022
-
[21]
Bootstrapping referring multi- object tracking.arXiv preprint arXiv:2406.05039,
[Zhanget al., 2024 ] Yani Zhang, Dongming Wu, Wencheng Han, and Xingping Dong. Bootstrapping referring multi- object tracking.arXiv preprint arXiv:2406.05039,
-
[22]
Hff-tracker: A hierarchical fine-grained fusion tracker for referring multi-object tracking
[Zhaoet al., 2025 ] Zeyong Zhao, Yanchao Hao, Minghao Zhang, Qingbin Liu, Bo Li, Dianbo Sui, Shizhu He, and Xi Chen. Hff-tracker: A hierarchical fine-grained fusion tracker for referring multi-object tracking. InProceed- ings of the AAAI Conference on Artificial Intelligence, vol- ume 39, pages 10528–10536,
2025
-
[23]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
[Zhuet al., 2020 ] Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159,
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[24]
Cgatracker: Correlation-aware graph alignment for referring multi-object tracking.IEEE Transactions on Circuits and Systems for Video Technology,
[Zhuanget al., 2025 ] Siping Zhuang, Guangyao Li, Qiangqiang Wu, Yang Lu, Hai-Miao Hu, and Hanzi Wang. Cgatracker: Correlation-aware graph alignment for referring multi-object tracking.IEEE Transactions on Circuits and Systems for Video Technology,
2025
-
[25]
We elabo- rate on the data preprocessing, network architecture, training strategy, and inference procedure employed throughout the experiments
Supplementary Material A Implementation Details This section provides a comprehensive description of the im- plementation details for the COAL framework. We elabo- rate on the data preprocessing, network architecture, training strategy, and inference procedure employed throughout the experiments. A.1 Data Preprocessing We leverage foundation models to con...
2024
-
[26]
Figure A2:Illustration of LLM Counterfactual Generation.The LLM synthesizes hard negative samples by randomly replacing an attribute fragment (blue) with a context-aware counterfactual variant (orange). This stochastic perturbation generates high-interference distractors, supervising the model to acquire a comprehensive com- positional understanding and p...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.