The Velocity Deficit: Initial Energy Injection for Flow Matching
Pith reviewed 2026-06-30 21:48 UTC · model grok-4.3
The pith
MSE training in flow matching underestimates initial velocity and leaves samples short of the data manifold.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
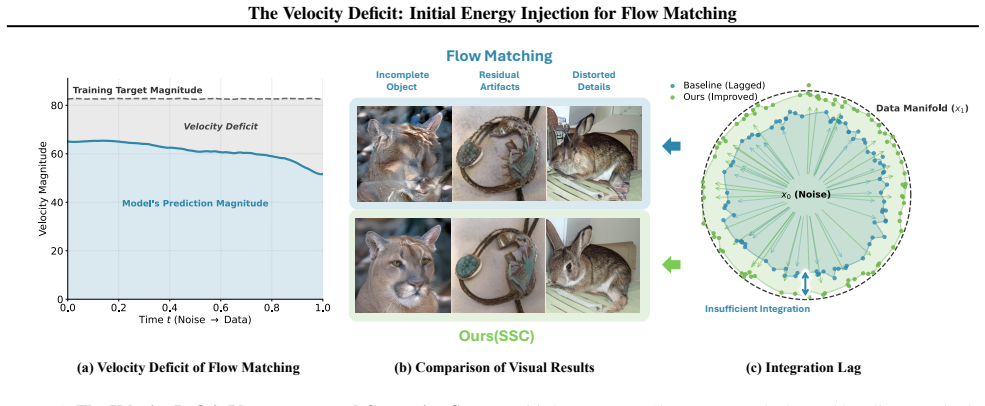
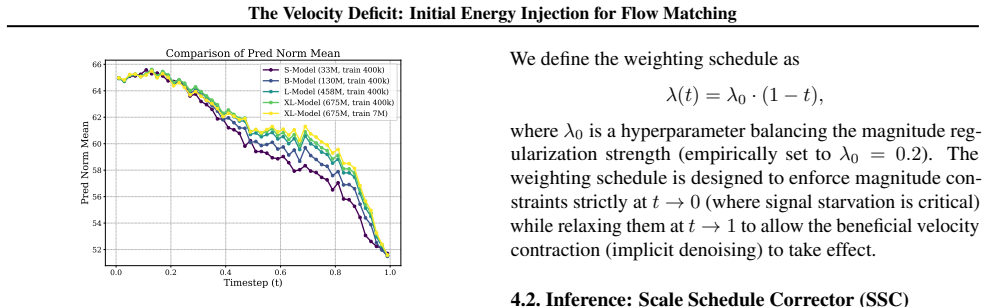
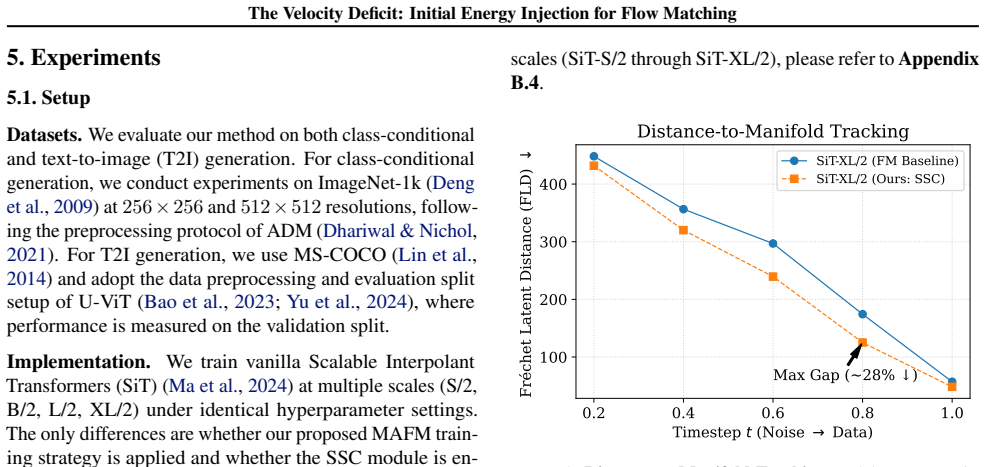
Flow matching models trained with the MSE objective suffer from a systematic underestimation of velocity magnitude at the beginning of the trajectory. This velocity deficit produces integration lag, in which generated samples fail to reach the data manifold. The deficit can be corrected by initial energy injection, which restores proper starting speed while preserving the beneficial contraction at the trajectory's end.
What carries the argument
Initial Energy Injection, which boosts the initial velocity magnitude to offset contraction induced by the MSE objective.
If this is right
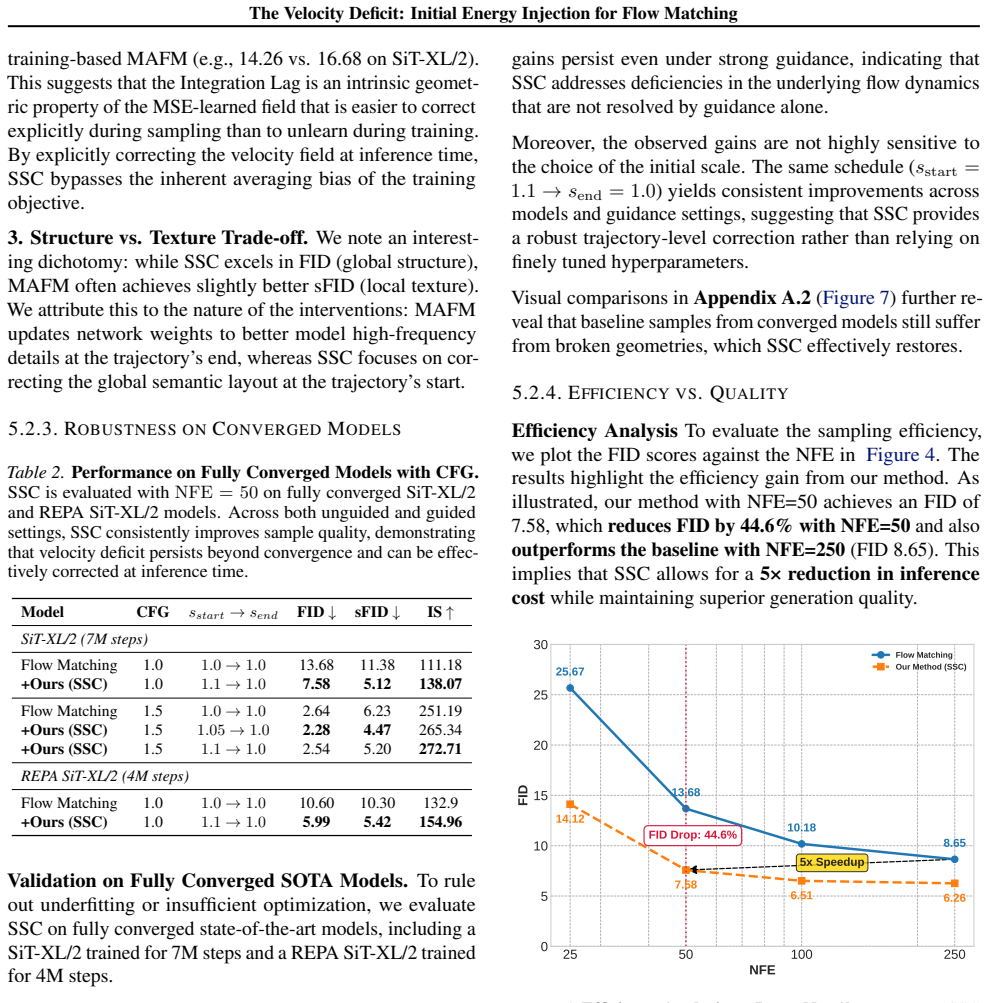
- The scale schedule corrector raises ImageNet-256 FID from 13.68 to 7.58 while cutting the required steps by a factor of five.
- A 50-step generator using the correction surpasses a 250-step uncorrected baseline.
- The same correction improves FID by roughly 22 percent on MS-COCO text-to-image generation.
- Both the training-time magnitude-aware loss and the inference-time schedule fix produce measurable gains.
Where Pith is reading between the lines
- If the MSE objective consistently biases velocity fields toward lower speeds, magnitude-aware losses could become the default for any flow-based generative model.
- The start-versus-end asymmetry suggests that time-dependent reweighting of the training loss might further reduce integration lag without changing the overall schedule.
- The same initial-velocity correction may transfer to other ODE or velocity-field generative methods that currently rely on plain MSE training.
Load-bearing premise
The assumption that underestimated initial velocity is the main reason samples fail to reach the data manifold rather than limits in model capacity or integration accuracy.
What would settle it
Train a flow matching model on a low-dimensional toy distribution where the required initial velocity can be calculated exactly; if the learned velocity magnitude at t near 0 matches the exact requirement yet samples still fail to reach the manifold, the velocity-deficit account is falsified.
Figures



read the original abstract
While Flow Matching theoretically guarantees constant-velocity trajectories, we identify a critical breakdown in high-dimensional practice: the Velocity Deficit. We show that the MSE objective systematically underestimates velocity magnitude, causing generated samples to fail to reach the data manifold-a phenomenon we term Integration Lag. To rectify this, we propose Initial Energy Injection, instantiated via two complementary methods: the training-based Magnitude-Aware Flow Matching (MAFM) and the training-free Scale Schedule Corrector (SSC). Both are grounded in our discovery of a crucial asymmetry: velocity contraction causes harmful kinetic stagnation at the trajectory's start, yet acts as a beneficial denoising mechanism at its end. Empirically, SSC yields significant efficiency gains with zero retraining and just one line of code. On ImageNet-1k (256x256), it improves FID by 44.6% (from 13.68 to 7.58) and achieves a 5x speedup, enabling a 50-step generator (FID 7.58) to beat a 250-step baseline (FID 8.65). Furthermore, our methods generalize to Text-to-Image tasks and high-resolution generation, improving FID on MS-COCO by ~22%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that flow matching's MSE objective produces a systematic 'Velocity Deficit' by underestimating velocity magnitude, resulting in 'Integration Lag' where generated samples fail to reach the data manifold. It identifies a position-dependent asymmetry in velocity contraction (harmful kinetic stagnation at trajectory start, beneficial denoising at end) and proposes 'Initial Energy Injection' via Magnitude-Aware Flow Matching (MAFM, training-based) and Scale Schedule Corrector (SSC, training-free, one-line change). On ImageNet-1k 256x256, SSC improves FID from 13.68 to 7.58 (44.6%) with 5x speedup; gains also reported on MS-COCO text-to-image and high-resolution tasks.
Significance. If the empirical improvements and generalization hold under full verification, the training-free SSC could offer immediate practical value for flow-matching generators by improving sample quality and reducing inference steps without retraining. The work highlights a potential mismatch between theoretical constant-velocity trajectories and high-dimensional MSE practice.
major comments (1)
- [Abstract] Abstract: The central mechanistic claim rests on an asymmetry in velocity contraction effects (harmful at start, beneficial at end) that is presented as justifying Initial Energy Injection, yet no derivation is supplied showing why or at what point the sign of the effect changes, nor a controlled ablation that isolates only this sign while holding scale, schedule, and other factors fixed. This directly underpins the need for position-specific correction rather than generic rescaling.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed feedback. The comment on the mechanistic justification for position-specific correction is well-taken, and we address it directly below. We will revise the manuscript accordingly to include the requested derivation and ablation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central mechanistic claim rests on an asymmetry in velocity contraction effects (harmful at start, beneficial at end) that is presented as justifying Initial Energy Injection, yet no derivation is supplied showing why or at what point the sign of the effect changes, nor a controlled ablation that isolates only this sign while holding scale, schedule, and other factors fixed. This directly underpins the need for position-specific correction rather than generic rescaling.
Authors: We agree that a formal derivation of the sign-change point and a controlled ablation isolating the position-specific effect would strengthen the central claim. The asymmetry follows from the fact that early in the trajectory the remaining distance to the data manifold is large, so velocity underestimation produces irreversible kinetic stagnation, whereas late in the trajectory the remaining distance is small and the same underestimation functions as additional denoising. In the revision we will add (i) a short derivation that identifies the transition threshold as the point where the expected velocity magnitude falls below the residual integration distance scaled by the schedule, and (ii) an ablation that applies magnitude correction only on [0, t*] or only on [t*, 1] while freezing all other hyperparameters. These additions will be included in the next version. revision: yes
Circularity Check
No circularity; claims rest on empirical observation without self-referential definitions or fitted inputs renamed as predictions.
full rationale
The provided abstract and description contain no equations, no self-citations used to justify core premises, and no instances where a quantity is defined in terms of itself or where a prediction reduces by construction to a fitted parameter from the same data. The Velocity Deficit and Integration Lag are presented as observed phenomena from MSE behavior, the asymmetry is described as a discovered fact motivating the methods, and MAFM/SSC are introduced as proposed fixes. This structure is self-contained against external benchmarks with no load-bearing reduction to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Classifier-Free Diffusion Guidance
URLhttps://arxiv.org/abs/2207.12598. Ho, J., Jain, A., and Abbeel, P. Denoising diffusion prob- abilistic models. InAdvances in Neural Information Processing Systems, volume 33, pp. 6840–6851,
work page internal anchor Pith review Pith/arXiv arXiv
- [2]
-
[3]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., V o, H., Szafraniec, M., Khalidov, V ., Fernandez, P., Haziza, D., Massa, F., El- Nouby, A., et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv
- [4]
-
[5]
Improving and generalizing flow-based generative models with minibatch optimal transport
Tong, A., Fatras, K., Malkin, N., Huguet, G., Zhang, Y ., Rector-Brooks, J., Wolf, G., and Bengio, Y . Improving and generalizing flow-based generative models with mini- batch optimal transport.arXiv preprint arXiv:2302.00482,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
URL https://arxiv.org/ abs/2410.10629. Yu, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., and Xie, S. Representation alignment for generation: Training diffusion transformers is easier than you think. arXiv preprint arXiv:2410.06940,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Magic", whimsical Ghibli style' SANA A cartoon bee with a sign
11 The Velocity Deficit: Initial Energy Injection for Flow Matching A. Qualitative Results A.1. Visual Comparison on the state-of-the-art text-to-image model A soot sprite carrying a banner that says "Magic", whimsical Ghibli style' SANA A cartoon bee with a sign "Buzz" An astronaut floating in space with a digital screen saying "Explore". A samurai rabbi...
2024
-
[8]
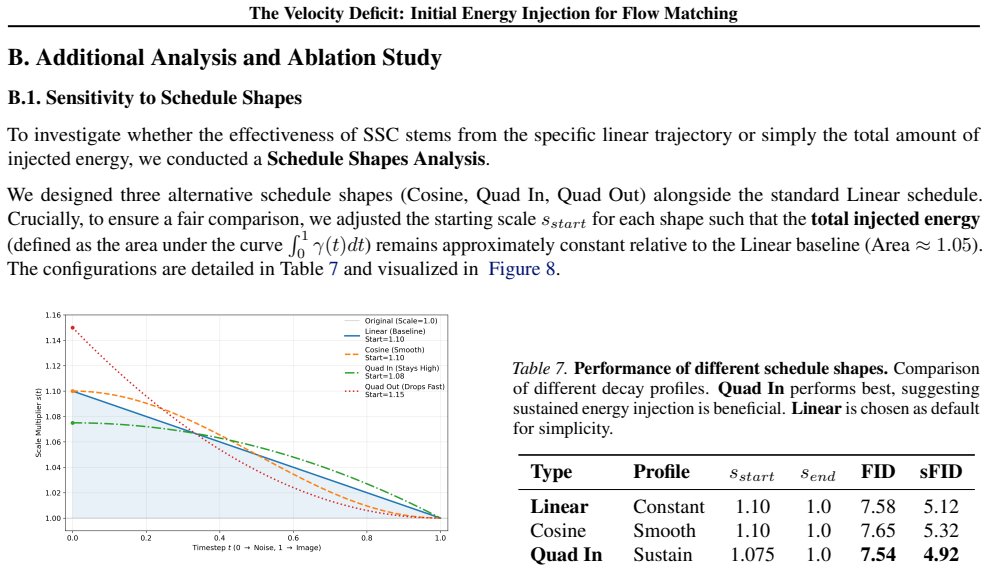
All schedules are calibrated to provide strictly comparable total energy injection (Area Under Curve)
Figure 8.Visualization of Scale Schedules.Comparison of Linear, Cosine, Quad In, and Quad Out curves. All schedules are calibrated to provide strictly comparable total energy injection (Area Under Curve). Table 7.Performance of different schedule shapes.Comparison of different decay profiles.Quad Inperforms best, suggesting sustained energy injection is b...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.