Emotion-Attended Stateful Memory (EASM):The Architecture for Hyper-Personalization at Scale
Pith reviewed 2026-06-30 20:32 UTC · model grok-4.3
The pith
A stateful memory architecture that tracks user emotions improves language model responses in grounding, clarity, and validation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
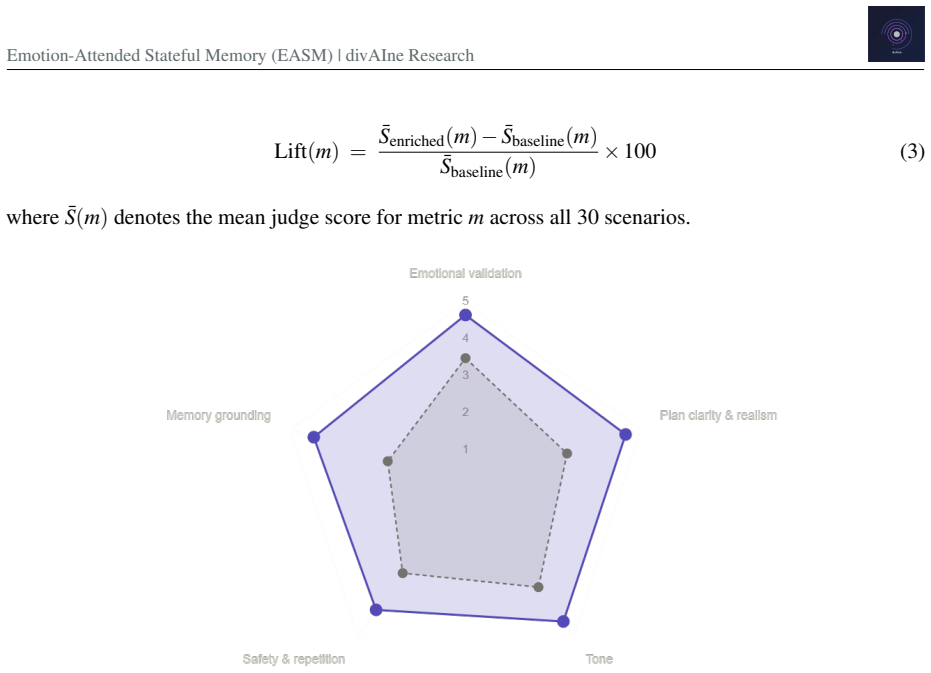
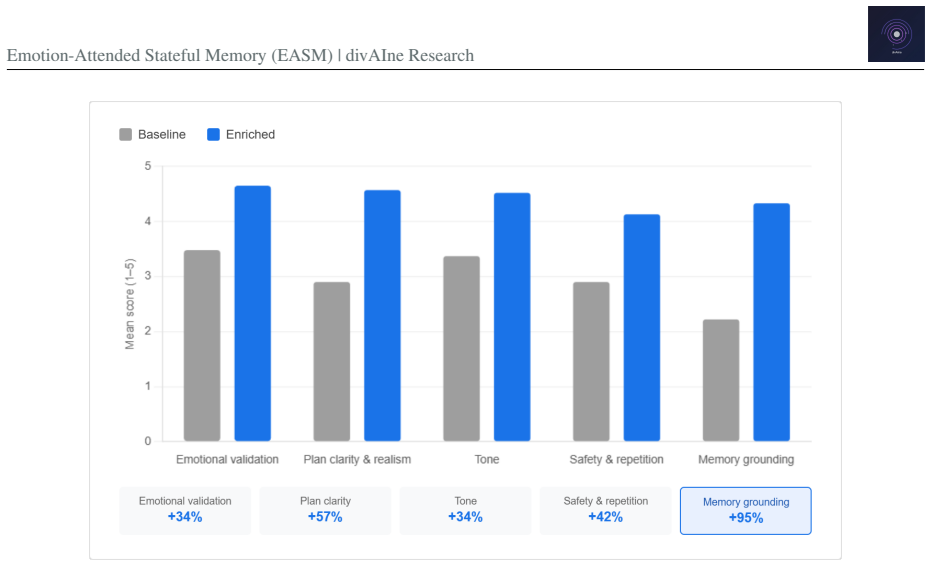
The paper claims that an emotion-attended stateful memory architecture, which dynamically constructs user-specific conversational context using long-term history, emotional signals, and inferred intent at inference time, consistently outperforms a stateless baseline across thirty non-scripted conversations in six emotional categories, delivering 95 percent better memory grounding, 57 percent better plan clarity, and 34 percent better emotional validation, with the gains remaining stable even in emotionally adversarial settings.
What carries the argument
Emotion-Attended Stateful Memory (EASM) architecture that dynamically constructs user-specific conversational context using long-term history, emotional signals, and inferred intent at inference time.
If this is right
- Memory-enriched responses achieve higher memory grounding than stateless baselines.
- Conversational plans gain clarity when long-term context is supplied.
- Emotional validation improves when emotional signals are attended to across sessions.
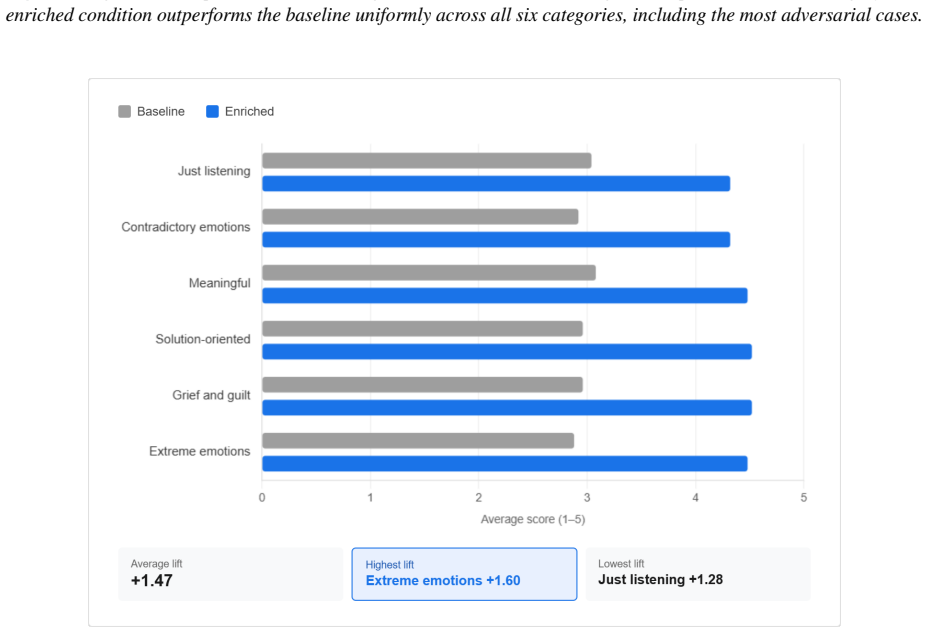
- Advantages remain present in conversations involving grief, distress, and uncertainty.
Where Pith is reading between the lines
- The same memory layer could be combined with retrieval methods to handle both personal history and external knowledge.
- Efficient indexing of stored emotional and factual traces would be needed before the approach scales to thousands of users.
Load-bearing premise
Results from a test of thirty conversations with one language model suffice to support claims of reliable performance at scale and in real emotional stress.
What would settle it
A larger experiment with hundreds of users and more varied conversation types that finds no measurable difference between the memory-enriched and stateless conditions would show the reported gains do not hold.
Figures
read the original abstract
Current language model systems remain fundamentally stateless across sessions, limiting their ability to personalize interactions over time. While retrieval-augmented generation and fine-tuning improve knowledge access and domain capability, they do not enable persistent understanding of individual users. We propose an emotion-attended stateful memory architecture that dynamically constructs user-specific conversational context using long-term history, emotional signals, and inferred intent at inference time. To evaluate its impact, we conducted a controlled A/B study across thirty non-scripted conversations spanning six emotionally distinct categories using the same underlying language model in both conditions. The memory-enriched condition consistently outperformed the stateless baseline across all evaluated scenarios. The largest gains were observed in memory grounding (95% improvement), plan clarity (57%), and emotional validation (34%). Results remained consistent even in emotionally adversarial conversations involving grief, distress, and uncertainty. These findings suggest that stateful emotional memory may represent a foundational infrastructure layer for hyper-personalized AI systems, though broader validation across larger and more diverse evaluations remains necessary
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Emotion-Attended Stateful Memory (EASM) architecture to enable persistent, user-specific conversational context in language models by integrating long-term history, emotional signals, and inferred intent at inference time. It evaluates this via a controlled A/B study of thirty non-scripted conversations across six emotional categories using the same underlying LM, reporting that the memory-enriched condition outperformed the stateless baseline with gains of 95% in memory grounding, 57% in plan clarity, and 34% in emotional validation, including in emotionally adversarial scenarios. The authors position EASM as foundational infrastructure for hyper-personalization at scale while noting that broader validation remains necessary.
Significance. If the empirical claims can be substantiated with full methodological details, the work would address a recognized limitation of stateless LLMs and offer a practical mechanism for long-term personalization without retraining. The focus on emotional signals and adversarial robustness is timely. The manuscript provides no machine-checked proofs, open code, or parameter-free derivations, so its contribution rests entirely on the reported A/B comparison.
major comments (2)
- [Evaluation / Results section] Evaluation / Results section: The A/B study reports specific percentage improvements (95% memory grounding, 57% plan clarity, 34% emotional validation) but supplies no information on the evaluation metrics, number or training of raters, inter-rater reliability, blinding, or any statistical tests (p-values, confidence intervals, effect sizes). This information is required to assess whether the observed deltas support the headline claims of consistent outperformance and robustness.
- [Introduction and Discussion] Introduction and Discussion: The manuscript positions EASM as 'foundational infrastructure for hyper-personalization at scale' and claims robustness in 'emotionally adversarial settings,' yet the supporting evidence is limited to N=30 conversations with no scaling experiments, computational-cost analysis, or tests on larger user cohorts. The abstract itself flags the need for broader validation, creating a mismatch between the strength of the claims and the scope of the evidence.
minor comments (1)
- [Abstract] Abstract: The abstract would be clearer if it briefly indicated the core mechanisms of EASM (e.g., how emotional signals are extracted or how memory is attended) rather than focusing exclusively on the empirical deltas.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where methodological transparency and alignment between claims and evidence can be strengthened. We respond to each major comment below.
read point-by-point responses
-
Referee: [Evaluation / Results section] Evaluation / Results section: The A/B study reports specific percentage improvements (95% memory grounding, 57% plan clarity, 34% emotional validation) but supplies no information on the evaluation metrics, number or training of raters, inter-rater reliability, blinding, or any statistical tests (p-values, confidence intervals, effect sizes). This information is required to assess whether the observed deltas support the headline claims of consistent outperformance and robustness.
Authors: We agree that the manuscript as submitted does not provide sufficient detail on the human evaluation protocol. In the revised version we will add an expanded Evaluation subsection that specifies the three binary success metrics (memory grounding, plan clarity, emotional validation), the use of three independent raters who received training on the scoring rubric, inter-rater reliability (Fleiss’ kappa), blinding procedures, and the statistical tests applied to the paired comparisons (including p-values, confidence intervals, and effect sizes). This addition will allow readers to evaluate the reported improvements directly. revision: yes
-
Referee: [Introduction and Discussion] Introduction and Discussion: The manuscript positions EASM as 'foundational infrastructure for hyper-personalization at scale' and claims robustness in 'emotionally adversarial settings,' yet the supporting evidence is limited to N=30 conversations with no scaling experiments, computational-cost analysis, or tests on larger user cohorts. The abstract itself flags the need for broader validation, creating a mismatch between the strength of the claims and the scope of the evidence.
Authors: The abstract already contains the explicit qualifier that broader validation remains necessary, and the results are presented as observations from a controlled N=30 study rather than as proof of scalability. Nevertheless, we acknowledge that certain phrasings in the Introduction and Discussion could be read as stronger than the current evidence warrants. In revision we will add a dedicated Limitations paragraph that reiterates the preliminary scope, notes the absence of scaling or cost analyses, and moderates the language around 'foundational infrastructure' while preserving the observation that the tested gains support further investigation of stateful emotional memory. revision: partial
Circularity Check
No circularity: empirical A/B evaluation is independent of inputs
full rationale
The paper proposes an architecture and reports results from a controlled A/B study of 30 conversations. No equations, fitted parameters, self-citations, or derivations appear in the provided text. The performance claims (95%/57%/34% gains) are presented as direct empirical observations rather than reductions of any input by construction. This satisfies the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Baddeley, A. D. (1986).Working memory. Oxford University Press. Bower, G. H. (1981). Mood and memory.American Psychologist,36(2), 129–148. https://doi.org/10.1037/ 0003-066X.36.2.129 Chen, T., Lu, J., Shen, Y ., & Zhang, L. (2026). ES-MemEval: Benchmarking conversational agents on personalized long-term emotional support.Proceedings of the Web Conference (WWW)
1986
-
[2]
arXiv:2602.01885. Godden, D. R., & Baddeley, A. D. (1975). Context-dependent memory in two natural environments: On land and underwater.British Journal of Psychology,66(3), 325–331. Lazarus, R. S. (1991).Emotion and adaptation. Oxford University Press. Lu, J., & Li, Y . (2025). Dynamic affective memory management for personalized LLM agents. arXiv. https:...
-
[3]
https: //arxiv.org/abs/2306.05685 Zhong, W., et al. (2024). MemoryBank: Enhancing large language models with long-term memory.AAAI
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
arXiv:2305.10250. 18
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.