Exploring Vision-Language Models for Online Signature Verification: A Zero-Shot Capability Study
Pith reviewed 2026-06-30 21:31 UTC · model grok-4.3
The pith
Zero-shot vision-language models can distinguish random signature forgeries at an equal error rate of 0.32 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
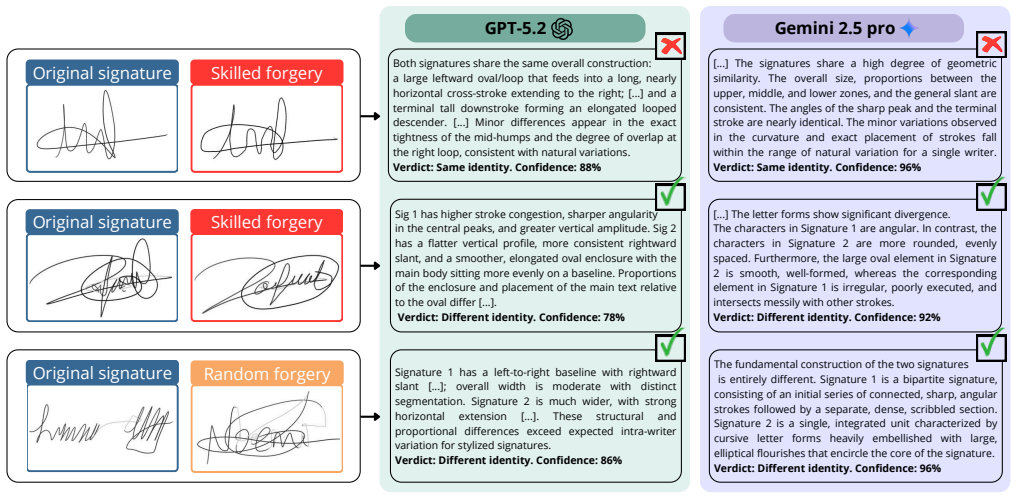
State-of-the-art vision-language models achieve an equal error rate of 0.32% in mobile random forgery scenarios on the SVC benchmark when processing converted signature images, outperforming supervised state-of-the-art systems. In skilled forgery scenarios performance is significantly worse, and chain-of-thought reasoning leads to a rationalization trap where the models produce kinematic hallucinations to justify forgery artifacts as natural variability.
What carries the argument
The conversion of kinematic time-series into static images encoding pressure as stroke opacity, along with the use of latent token probabilities to generate biometric scores.
If this is right
- Zero-shot VLMs excel at random forgery detection but struggle with skilled forgeries.
- Performance varies based on the quality of the input signal.
- Chain-of-thought prompting can reduce accuracy by introducing hallucinations.
- VLMs offer a new zero-shot approach for certain biometric verification tasks.
Where Pith is reading between the lines
- Image-based representations of dynamic data could extend to verifying other time-series biometrics.
- Methods to mitigate the rationalization trap might improve VLM reliability in verification.
- Results suggest exploring zero-shot methods for related security applications like document authentication.
Load-bearing premise
The static image representation derived from the time-series data contains sufficient biometric details for the vision-language model to accurately separate genuine signatures from forgeries.
What would settle it
Running the same zero-shot process on a dataset consisting only of skilled forgeries and finding error rates much higher than 0.32% would show the exceptional performance does not generalize.
Figures


read the original abstract
Recent advancements in Vision-Language Models (VLMs) have demonstrated strong capabilities in general visual reasoning, yet their applicability to rigorous biometric tasks remains unexplored. This work presents an exploratory study evaluating the zero-shot performance of state-of-the-art VLMs (GPT-5.2 and Gemini 2.5 Pro) on the Signature Verification Challenge (SVC) benchmark. To enable visual processing, raw kinematic time-series are converted into static images, encoding pressure information into stroke opacity whenever available in the source data. Furthermore, we introduce a scoring protocol that extracts latent token probabilities to compute robust biometric scores. Experimental results reveal a significant performance dichotomy dependent on signal quality and forgery type. In random forgery scenarios, the zero-shot VLM achieves exceptional discrimination, with GPT-5.2 reaching an Equal Error Rate of 0.32% in mobile tasks, outperforming supervised state-of-the-art systems. Conversely, in skilled forgery scenarios, where the task is more challenging because both signatures are almost identical, the results are significantly worse, and a critical "Rationalization Trap" emerges: chain-of-thought (CoT) reasoning degrades performance as the model produces kinematic hallucinations to justify forgery artifacts as natural variability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an exploratory study evaluating the zero-shot performance of VLMs (GPT-5.2 and Gemini 2.5 Pro) on the SVC benchmark for online signature verification. Kinematic time-series are converted to static images with pressure encoded as stroke opacity, and token-probability extraction is used for scoring. Key claims include exceptional random-forgery discrimination (GPT-5.2 reaches 0.32% EER on mobile tasks, outperforming supervised SOTA) but poor skilled-forgery results, plus the emergence of a 'Rationalization Trap' in which chain-of-thought reasoning produces kinematic hallucinations that degrade performance.
Significance. If the central empirical claims hold after validation of the conversion and scoring steps, the work would demonstrate that general-purpose VLMs can achieve strong zero-shot biometric discrimination on random forgeries without fine-tuning or examples, potentially reducing reliance on task-specific training data. The identification of the Rationalization Trap offers a concrete observation about reasoning limitations in fine-grained verification tasks.
major comments (2)
- [Abstract / image-conversion protocol] Abstract and methods description of image conversion: the headline 0.32% EER claim on random forgeries rests on rendering (x,y,pressure,time) series as static images with opacity for pressure. This step discards velocity and acceleration signals that the online signature literature treats as core biometric cues; without an ablation or analysis showing that gross shape mismatch alone suffices for the reported discrimination, it is unclear whether the VLM is performing biometric extraction or simply detecting the shape differences built into random forgeries by construction.
- [Experimental results / scoring protocol] Experimental results and scoring protocol: the token-probability scoring method used to compute EER is not anchored to any calibrated distance metric or compared against standard online-signature distance measures. Consequently the reported 0.32% EER (and its superiority to supervised baselines) cannot be directly interpreted or compared without additional verification of threshold setting and protocol equivalence.
minor comments (2)
- [Experimental setup] Specify the exact SVC subsets and mobile-task definitions used, and clarify whether pressure data were available for all evaluated signatures.
- [Discussion] The term 'Rationalization Trap' is introduced without a formal definition or quantitative metric; a brief operationalization would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract / image-conversion protocol] Abstract and methods description of image conversion: the headline 0.32% EER claim on random forgeries rests on rendering (x,y,pressure,time) series as static images with opacity for pressure. This step discards velocity and acceleration signals that the online signature literature treats as core biometric cues; without an ablation or analysis showing that gross shape mismatch alone suffices for the reported discrimination, it is unclear whether the VLM is performing biometric extraction or simply detecting the shape differences built into random forgeries by construction.
Authors: We agree that converting the time-series to static images discards explicit velocity and acceleration cues emphasized in the online signature literature. The conversion was chosen to enable direct use of VLM visual processing on a 2D representation that includes shape and pressure (via opacity). The strong random-forgery results show that VLMs can discriminate from this visual encoding alone. We will revise the manuscript to add explicit discussion of this limitation, clarify the exploratory visual zero-shot focus, and note that full dynamic ablation lies outside the current scope as future work. revision: partial
-
Referee: [Experimental results / scoring protocol] Experimental results and scoring protocol: the token-probability scoring method used to compute EER is not anchored to any calibrated distance metric or compared against standard online-signature distance measures. Consequently the reported 0.32% EER (and its superiority to supervised baselines) cannot be directly interpreted or compared without additional verification of threshold setting and protocol equivalence.
Authors: The token-probability method is a VLM-specific technique that derives scores from output token likelihoods without fine-tuning or example-based calibration. EER follows the standard SVC protocol. We will expand the methods section with additional detail on score formation, threshold selection, and the rationale for this approach in the zero-shot setting. A side-by-side comparison with traditional metrics such as DTW is not directly applicable but we will add a clarifying note on interpretability and protocol differences. revision: yes
Circularity Check
Empirical evaluation with no internal derivations or self-referential predictions
full rationale
The paper is an exploratory empirical study that converts kinematic signature time-series to static images, feeds them to external VLMs (GPT-5.2, Gemini 2.5 Pro), and reports EER on the SVC benchmark using a token-probability scoring protocol. No equations, fitted parameters, predictions, or derivation chains appear in the work. Central claims rest on direct experimental outcomes against external models and datasets rather than any reduction to self-defined quantities or self-citations. This is the most common honest finding for pure evaluation papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs can process converted signature images meaningfully for biometric discrimination
invented entities (1)
-
Rationalization Trap
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Behavioral Biometrics & Continuous User Authenti- cation on Mobile Devices: A Survey,
I. Stylioset al., “Behavioral Biometrics & Continuous User Authenti- cation on Mobile Devices: A Survey,”Information Fusion, 2021
2021
-
[2]
DeepSign: Deep On-Line Signature Verification,
R. Tolosanaet al., “DeepSign: Deep On-Line Signature Verification,” IEEE Transactions on Biometrics, Behavior, and Identity Science, 2021
2021
-
[3]
AirSignatureDB: Exploring In-Air Signature Biometrics in the Wild and its Privacy Concerns,
M. Robledo-Morenoet al., “AirSignatureDB: Exploring In-Air Signature Biometrics in the Wild and its Privacy Concerns,” inProc. IEEE International Joint Conference on Biometrics (IJCB), 2025
2025
-
[4]
Type2Branch: Keystroke Biometrics Based on a Dual-Branch Architecture With Attention Mechanisms and Set2set Loss,
N. Gonzalezet al., “Type2Branch: Keystroke Biometrics Based on a Dual-Branch Architecture With Attention Mechanisms and Set2set Loss,”IEEE Transactions on Information Forensics and Security, 2025
2025
-
[5]
Exploring Transformers for Behavioural Biometrics: A Case Study in Gait Recognition,
P. Delgado-Santoset al., “Exploring Transformers for Behavioural Biometrics: A Case Study in Gait Recognition,”Pattern Recognition, 2023
2023
-
[6]
DsDTW: Local Representation Learning With Deep soft-DTW for Dynamic Signature Verification,
J. Jianget al., “DsDTW: Local Representation Learning With Deep soft-DTW for Dynamic Signature Verification,”IEEE TIFS, 2022
2022
-
[7]
General Purpose Artificial Intelligence Systems (GPAIS): Properties, Definition, Taxonomy, Societal Implications and Responsible Governance,
I. Trigueroet al., “General Purpose Artificial Intelligence Systems (GPAIS): Properties, Definition, Taxonomy, Societal Implications and Responsible Governance,”Information Fusion, 2024
2024
-
[8]
arXiv preprint arXiv:2405.17247 (2024) 1
F. Bordeset al., “An Introduction to Vision-Language Modeling,”arXiv preprint arXiv:2405.17247, 2024
-
[9]
Learning Transferable Visual Models From Natural Language Supervision,
A. Radfordet al., “Learning Transferable Visual Models From Natural Language Supervision,” inProc. International Conference on Machine Learning, 2021
2021
-
[10]
Deep Generative Models: Survey,
A. Oussidiet al., “Deep Generative Models: Survey,” inProc. Interna- tional Conference on Intelligent Systems and Computer Vision, 2018
2018
-
[11]
Large Language Models in Medicine,
A. J. Thirunavukarasuet al., “Large Language Models in Medicine,” Nature Medicine, 2023
2023
-
[12]
Evaluating ChatGPT and GPT-4 for Visual Programming,
A. Singla, “Evaluating ChatGPT and GPT-4 for Visual Programming,” in Proc. ACM Conference on International Computing Education Research, 2023
2023
-
[13]
ChatGPT for Good? On Opportunities and Challenges of Large Language Models for Education,
E. Kasneciet al., “ChatGPT for Good? On Opportunities and Challenges of Large Language Models for Education,”Learning and Individual Differences, 2023
2023
-
[14]
Hallucination of Multimodal Large Language Models: A Survey
Z. Baiet al., “Hallucination of Multimodal Large Language Models: A Survey,”arXiv preprint arXiv:2404.18930, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
SVC-onGoing: Signature verification competition,
R. Tolosanaet al., “SVC-onGoing: Signature verification competition,” Pattern Recognition, 2022
2022
-
[16]
Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges Toward Respon- sible AI,
A. Barredo Arrietaet al., “Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges Toward Respon- sible AI,”Information fusion, 2019
2019
-
[17]
Evaluating Vision Language Models for Hand- written Text Recognition,
L. Diez Garciaet al., “Evaluating Vision Language Models for Hand- written Text Recognition,” inProc. International Conference on Disrup- tive Technologies, 2025
2025
-
[18]
Can Vision-Language Models Evaluate Handwritten Math?
O. Nathet al., “Can Vision-Language Models Evaluate Handwritten Math?”arXiv preprint arXiv:2501.07244, 2025
-
[19]
How Good is ChatGPT at Face Biometrics? A First Look into Recognition, Soft Biometrics, and Explainability,
I. Deandres-Tameet al., “How Good is ChatGPT at Face Biometrics? A First Look into Recognition, Soft Biometrics, and Explainability,”IEEE Access, 2024
2024
-
[20]
R. Sevastjanovaet al., “Beware the Rationalization Trap! When Lan- guage Model Explainability Diverges From Our Mental Models of Language,”arXiv preprint arXiv:2207.06897, 2022
-
[21]
PBa-LLM: Privacy-and bias-aware NLP using named-entity recognition (NER),
G. Manceraet al., “PBa-LLM: Privacy-and bias-aware NLP using named-entity recognition (NER),” inProc. International Conference on Document Analysis and Recognition, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.