Fast Adversarial Attacks with Gradient Prediction
Pith reviewed 2026-06-30 21:15 UTC · model grok-4.3
The pith
Linear regression on forward hidden states predicts input gradients accurately enough to replace the backward pass in fast adversarial attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
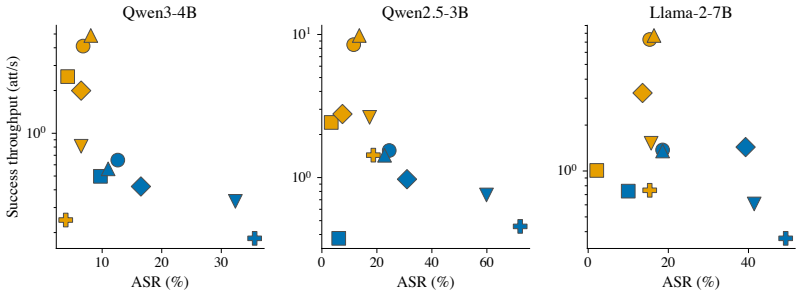
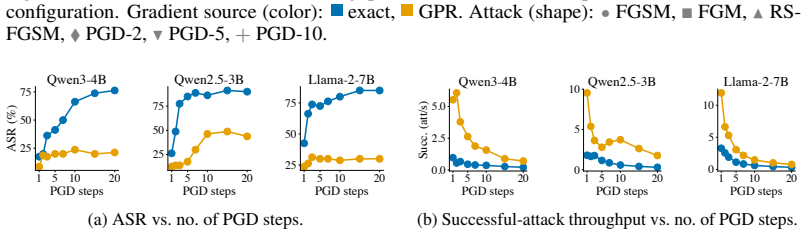
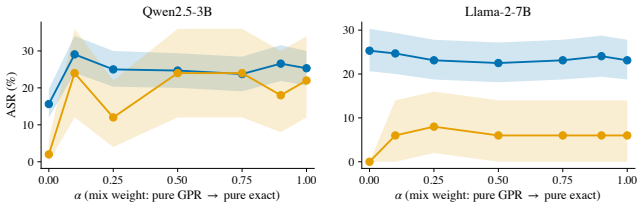
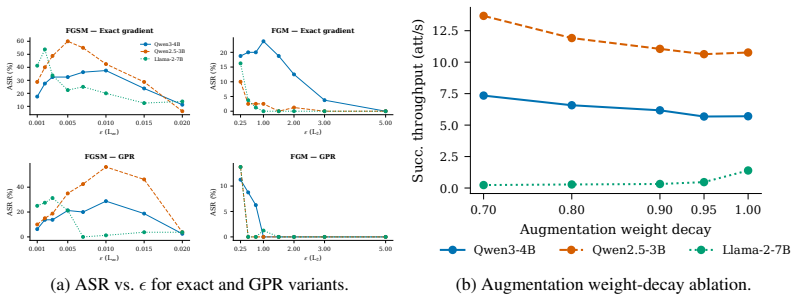
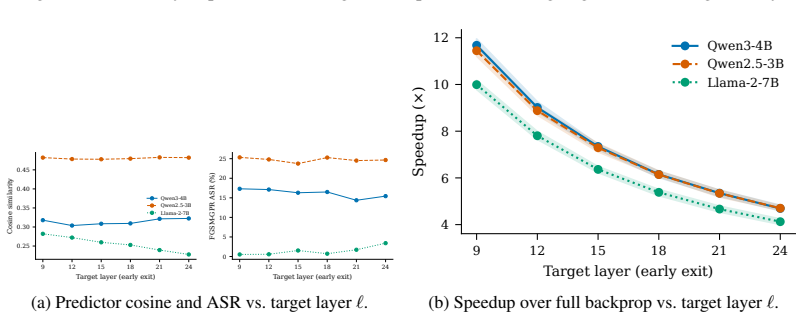
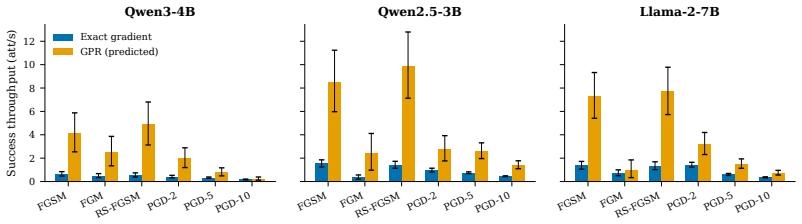
The central discovery is that a lightweight linear regressor fitted to map forward-pass hidden states to input gradients can generate adversarial perturbations that recover much of FGSM's attack performance, yielding a 532% increase in throughput by eliminating the need for a backward pass. The method is motivated by a kernel view of neural networks and is exact in the NTK regime.
What carries the argument
linear regression fitted on forward-pass hidden states to predict input gradients
If this is right
- Adversarial examples can be generated at significantly higher throughput for robustness evaluation and red-teaming.
- Adversarial training can use more examples within the same compute budget.
- The approach extends to other gradient-based attacks that rely on input gradients.
- Practical finite-width networks still benefit even outside the exact NTK regime.
Where Pith is reading between the lines
- Similar prediction techniques might accelerate other methods that require input gradients, such as certain optimization or interpretability tools.
- If the linear predictor generalizes across architectures, it could reduce the cost of large-scale adversarial robustness benchmarks.
- Testing the method on very deep or recurrent networks would reveal how far the NTK-motivated approximation holds.
- The throughput gains could enable real-time adversarial example generation in some applications.
Load-bearing premise
A linear regressor fitted on forward-pass hidden states can produce input gradients sufficiently accurate to generate effective adversarial perturbations on finite-width networks outside the exact NTK regime.
What would settle it
Measuring attack success rate on a standard image classification model and finding that the predicted-gradient attacks achieve substantially lower success rates than FGSM at the same perturbation budget.
Figures
read the original abstract
Generating adversarial examples at scale is a core primitive for robustness evaluation, adversarial training, and red-teaming, yet even "fast" attacks such as FGSM remain throughput-limited by the cost of a backward pass. We introduce a family of attacks that eliminates the backward pass by predicting the input gradient from forward-pass hidden states via a lightweight linear regression. The approach is motivated by a kernel view of neural networks and is exact in the Neural Tangent Kernel regime, while remaining effective for practical finite-width models. Empirically, our methods recover much of FGSM's attack performance while using only a small fraction of the time, corresponding to a $532\%$ increase in throughput. These results suggest gradient prediction as a simple and general route to significantly faster adversarial generation under realistic wall-clock constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a family of adversarial attacks that replace the backward pass of FGSM with a linear regression predictor of the input gradient from forward-pass hidden states. The construction is motivated by a kernel view of neural networks and is exact in the infinite-width NTK regime; the authors claim it remains effective for practical finite-width models, recovering much of FGSM attack success while delivering a 532% throughput increase.
Significance. If the empirical claims are substantiated, the work would provide a practical route to higher-throughput adversarial example generation, which is relevant for robustness evaluation and adversarial training pipelines. The NTK-derived motivation supplies a clear theoretical starting point, though the finite-width extension rests entirely on empirical fit quality.
major comments (2)
- [Abstract] Abstract: the central claim that the methods 'recover much of FGSM's attack performance' while achieving a '532% increase in throughput' is stated without any description of experimental protocol, regressor training procedure, validation set, baselines, number of runs, or statistical tests. Soundness of the throughput and attack-success claims cannot be assessed from the supplied text.
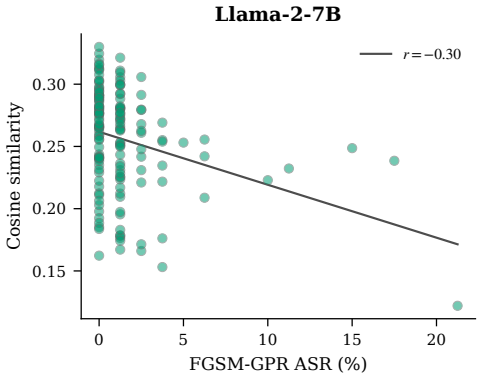
- [Abstract] Abstract / method description: the linear regressor is fitted on hidden-state/gradient pairs drawn from data, yet the paper presents the output as a 'prediction' whose accuracy for finite-width networks is asserted without analytic bounds or error analysis outside the exact NTK limit. If fit quality degrades on deeper architectures or shifted distributions, the generated perturbations may lose effectiveness, directly undermining the claimed throughput advantage.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating where revisions will be made to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the methods 'recover much of FGSM's attack performance' while achieving a '532% increase in throughput' is stated without any description of experimental protocol, regressor training procedure, validation set, baselines, number of runs, or statistical tests. Soundness of the throughput and attack-success claims cannot be assessed from the supplied text.
Authors: We agree that the abstract's brevity prevents inclusion of full experimental details. The complete manuscript describes the regressor training on hidden-state/gradient pairs from a held-out validation set, the FGSM baseline, multiple runs with statistical reporting, and throughput measurements under controlled conditions. In the revision we will expand the abstract with a concise reference to the empirical protocol and add a dedicated experimental setup subsection early in the paper to make these elements immediately accessible. revision: yes
-
Referee: [Abstract] Abstract / method description: the linear regressor is fitted on hidden-state/gradient pairs drawn from data, yet the paper presents the output as a 'prediction' whose accuracy for finite-width networks is asserted without analytic bounds or error analysis outside the exact NTK limit. If fit quality degrades on deeper architectures or shifted distributions, the generated perturbations may lose effectiveness, directly undermining the claimed throughput advantage.
Authors: The construction is exact only in the infinite-width NTK limit; for finite-width networks the method is presented as an empirical approximation whose utility is validated through attack-success and throughput measurements. We do not supply analytic error bounds outside the NTK regime, as obtaining such bounds for practical finite networks is an open theoretical question not addressed in this work. The manuscript instead reports consistent recovery of FGSM performance across the evaluated models and data distributions. We will add quantitative fit-quality metrics (e.g., gradient prediction MSE on held-out data) to the revised version to better characterize when the approximation remains reliable. revision: partial
Circularity Check
No significant circularity; method is explicitly data-dependent regression with empirical validation
full rationale
The paper presents an explicit algorithmic method: fit a linear regressor on forward-pass hidden states to approximate input gradients, motivated by exactness in the NTK limit. This is not a first-principles derivation whose output is smuggled back as input; the regression coefficients are learned from data as part of the attack construction, and performance claims are supported by direct empirical comparison to FGSM rather than by any self-referential reduction. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text to justify core steps. The approach is self-contained as a practical approximation technique whose validity rests on measured attack success rates, not on tautological equivalence.
Axiom & Free-Parameter Ledger
free parameters (1)
- linear regression coefficients
axioms (1)
- domain assumption Gradient prediction from hidden states is exact in the Neural Tangent Kernel regime
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2511.05187. Wojciech Marian Czarnecki, Grzegorz ´Swirszcz, Max Jaderberg, Simon Osindero, Oriol Vinyals, and Koray Kavukcuoglu. Understanding synthetic gradients and decoupled neural interfaces. In International Conference on Machine Learning, pages 904–912. PMLR,
-
[2]
Goodfellow, Jonathon Shlens, and Christian Szegedy
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. In Yoshua Bengio and Yann LeCun, editors,3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings,
2015
-
[3]
Explaining and Harnessing Adversarial Examples
URLhttp://arxiv.org/abs/1412.6572. Andrew Ilyas, Logan Engstrom, Anish Athalye, and Jessy Lin. Black-box adversarial attacks with limited queries and information. InProceedings of the 35th International Conference on Machine Learning, ICML 2018, July
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Black-box Adversarial Attacks with Limited Queries and Information
URLhttps://arxiv.org/abs/1804.08598. Arthur Jacot, Franck Gabriel, and Clément Hongler. Neural tangent kernel: Convergence and generalization in neural networks.Advances in neural information processing systems, 31,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Kenneth Li, Oam Patel, Fernanda B
URLhttps://openreview.net/forum?id=B1EA-M-0Z. Kenneth Li, Oam Patel, Fernanda B. Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference- time intervention: Eliciting truthful answers from a language model. In Alice Oh, Tris- tan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing S...
2023
-
[6]
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu
URL http://papers.nips.cc/paper_files/paper/2023/hash/ 81b8390039b7302c909cb769f8b6cd93-Abstract-Conference.html. Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. In6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Cana...
2023
-
[7]
Gaussian Process Behaviour in Wide Deep Neural Networks
URL https://openreview.net/forum?id= rJzIBfZAb. Alexander G de G Matthews, Mark Rowland, Jiri Hron, Richard E Turner, and Zoubin Ghahramani. Gaussian process behaviour in wide deep neural networks.arXiv preprint arXiv:1804.11271,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Davis, Gavin Taylor, and Tom Goldstein
URL https: //arxiv.org/abs/1904.12843. Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
-
[10]
Goodfellow, and Rob Fergus
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian J. Goodfellow, and Rob Fergus. Intriguing properties of neural networks. In Yoshua Bengio and Yann LeCun, editors,2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings,
2014
-
[11]
Metamorphictestingoflarge languagemodelsfornaturallanguageprocessing.doi:10.48550/arXiv
URL https://arxiv.org/ abs/1905.00877. Andy Zou, Long Phan, Sarah Li Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representa...
work page internal anchor Pith review doi:10.48550/arxiv 1905
-
[12]
The augmentation procedure is GCG-trajectory augmentation plus random one-token suffix perturbations as described above. • Evaluation and timing.We use the HarmBench custom judge for HarmBench and Jail- breakJudge for JailbreakBench; JailbreakJudge is Llama-3-70B-Instruct quantized and served with Ollama. Attacked-model responses use default generation pa...
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.