ACE-LoRA: Adaptive Orthogonal Decoupling for Continual Image Editing
Pith reviewed 2026-06-30 21:43 UTC · model grok-4.3
The pith
Adaptive orthogonal decoupling lets diffusion models learn new image edits without forgetting old ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
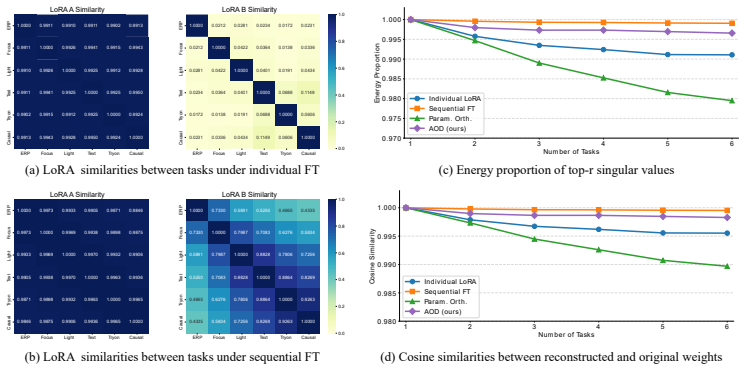
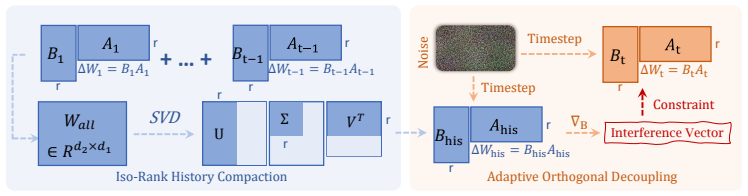
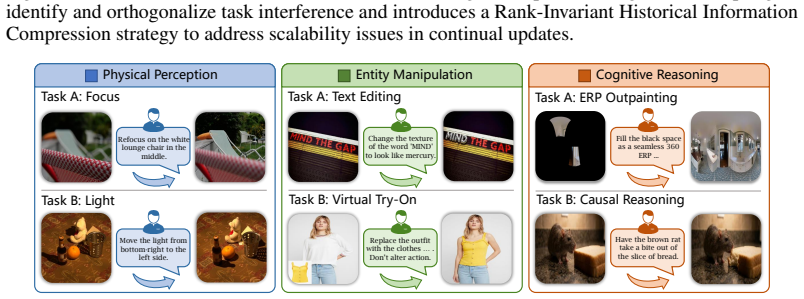
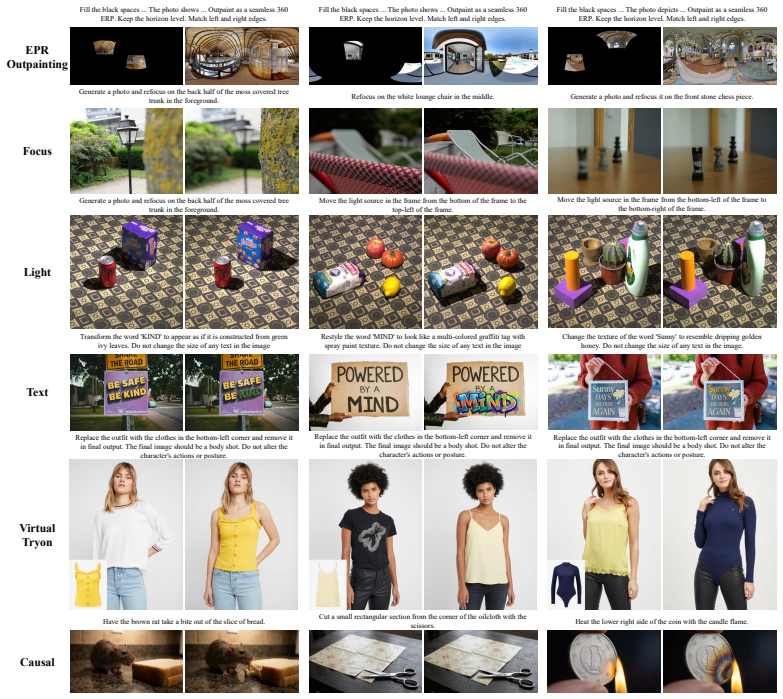
ACE-LoRA mitigates catastrophic forgetting in continual image editing by using Adaptive Orthogonal Decoupling to identify and orthogonalize task interference and Rank-Invariant Historical Information Compression to maintain scalability, leading to improved instruction fidelity, visual realism, and robustness compared to existing approaches on the CIE-Bench benchmark.
What carries the argument
Adaptive Orthogonal Decoupling, which detects task interference and enforces orthogonality between task-specific parameter updates to minimize forgetting.
Load-bearing premise
That interfering directions between different editing tasks can be accurately identified in the low-rank parameter space and made orthogonal without reducing the effectiveness of the adaptations for any task.
What would settle it
Training the model on a series of sequential editing tasks and then measuring a substantial decline in performance on the first tasks relative to a model trained only on those first tasks would falsify the effectiveness of the decoupling.
Figures


read the original abstract
State-of-the-art diffusion models often rely on parameter-efficient fine-tuning to perform specialized image editing tasks. However, real-world applications require continual adaptation to new tasks while preserving previously learned knowledge. Despite the practical necessity, continual learning for image editing remains largely underexplored. We propose ACE-LoRA, a dynamic regularization framework for continual image editing that effectively mitigates catastrophic forgetting. ACE-LoRA leverages Adaptive Orthogonal Decoupling to identify and orthogonalize task interference, and introduces a Rank-Invariant Historical Information Compression strategy to address scalability issues in continual updates. To facilitate continual learning in image editing and provide a standardized evaluation protocol, we introduce CIE-Bench, the first comprehensive benchmark in this domain. CIE-Bench encompasses diverse and practically relevant image editing scenarios with a balanced level of difficulty to effectively expose limitations of existing models while remaining compatible with parameter-efficient fine-tuning. Extensive experiments demonstrate that our method consistently outperforms existing baselines in terms of instruction fidelity, visual realism, and robustness to forgetting, establishing a strong foundation for continual learning in image editing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ACE-LoRA, a dynamic regularization framework for continual image editing with diffusion models that uses Adaptive Orthogonal Decoupling to identify and orthogonalize task interference in LoRA parameter space together with Rank-Invariant Historical Information Compression for scalability; it also introduces the CIE-Bench benchmark covering diverse editing scenarios and claims consistent outperformance over baselines on instruction fidelity, visual realism, and resistance to forgetting.
Significance. If the central claims hold, the work would be significant as the first dedicated benchmark and method for continual parameter-efficient adaptation in image editing, addressing a practical gap in generative model deployment; the introduction of CIE-Bench as a standardized, difficulty-balanced evaluation protocol is a clear strength that could enable reproducible progress.
major comments (3)
- [Abstract and §3] Abstract and §3 (method description): the claim that Adaptive Orthogonal Decoupling 'identifies and orthogonalizes task interference' such that prior-task performance remains intact rests on the unverified assumption that LoRA-matrix orthogonality preserves functional independence under the highly non-linear diffusion mapping from text+image conditioning to output pixels; no derivation or experiment is shown demonstrating that parameter-space orthogonality implies output-space independence on the image manifold.
- [§4] §4 (experiments): the abstract asserts outperformance on instruction fidelity, realism, and forgetting robustness, yet the provided text contains no quantitative tables, ablation results, or details on controls (e.g., how CIE-Bench tasks are sequenced, what metrics quantify 'robustness to forgetting'); without these the central empirical claim cannot be assessed.
- [§3.2] §3.2 (Rank-Invariant Historical Information Compression): the scalability strategy is described only at a high level; it is unclear whether the compression preserves the orthogonality constraints enforced by Adaptive Orthogonal Decoupling or introduces new interference, which is load-bearing for the continual-learning guarantee.
minor comments (2)
- [§3] Notation for the orthogonality constraint and the rank-invariant compression operator should be defined explicitly with equations rather than prose descriptions.
- [§4.1] CIE-Bench task descriptions and difficulty balancing criteria are mentioned but not enumerated; a table listing the editing operations, prompt styles, and dataset sources would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving theoretical clarity, experimental presentation, and methodological detail. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method description): the claim that Adaptive Orthogonal Decoupling 'identifies and orthogonalizes task interference' such that prior-task performance remains intact rests on the unverified assumption that LoRA-matrix orthogonality preserves functional independence under the highly non-linear diffusion mapping from text+image conditioning to output pixels; no derivation or experiment is shown demonstrating that parameter-space orthogonality implies output-space independence on the image manifold.
Authors: We acknowledge that the manuscript does not provide a formal derivation connecting LoRA parameter orthogonality to functional independence in the non-linear diffusion output space. The approach is motivated by reducing interference in parameter space, with empirical support from CIE-Bench results showing preserved prior-task performance. In revision we will add a dedicated discussion subsection and an ablation experiment that measures output-space similarity (e.g., via perceptual metrics) before and after orthogonalization to better substantiate the assumption. revision: partial
-
Referee: [§4] §4 (experiments): the abstract asserts outperformance on instruction fidelity, realism, and forgetting robustness, yet the provided text contains no quantitative tables, ablation results, or details on controls (e.g., how CIE-Bench tasks are sequenced, what metrics quantify 'robustness to forgetting'); without these the central empirical claim cannot be assessed.
Authors: The full manuscript contains §4 with quantitative tables, ablation studies, task sequencing details for CIE-Bench, and forgetting metrics (performance retention on prior tasks). We apologize if these elements were not visible in the reviewed version and will ensure all tables, controls, and metric definitions are explicitly presented and cross-referenced in the revised submission. revision: yes
-
Referee: [§3.2] §3.2 (Rank-Invariant Historical Information Compression): the scalability strategy is described only at a high level; it is unclear whether the compression preserves the orthogonality constraints enforced by Adaptive Orthogonal Decoupling or introduces new interference, which is load-bearing for the continual-learning guarantee.
Authors: We will expand §3.2 with a detailed algorithmic description and analysis showing that the rank-invariant compression operates on the orthogonal subspaces without altering their mutual orthogonality, thereby preserving the interference-mitigation property. A short proof sketch and pseudocode will be added to demonstrate that no new interference is introduced. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes a new empirical method (ACE-LoRA) consisting of Adaptive Orthogonal Decoupling and Rank-Invariant Historical Information Compression, plus a new benchmark (CIE-Bench). No equations, parameter fits presented as predictions, or load-bearing self-citations appear in the provided text. Claims rest on experimental results rather than a derivation that reduces to its own inputs by construction. This matches the common case of a self-contained method paper with independent empirical content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Instructpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. InCVPR, pages 18392–18402, 2023
2023
-
[2]
Continual learning with tiny episodic memories
Arslan Chaudhry, Marcus Rohrbach, Mohamed Elhoseiny, Thalaiyasingam Ajanthan, P Dokania, P Torr, and M Ranzato. Continual learning with tiny episodic memories. InWorkshop on Multi-Task and Lifelong Reinforcement Learning, 2019
2019
-
[3]
Coin: A benchmark of continual instruction tuning for multimodel large language models.NeurIPS, 2024
Cheng Chen, Junchen Zhu, Xu Luo, Heng T Shen, Jingkuan Song, and Lianli Gao. Coin: A benchmark of continual instruction tuning for multimodel large language models.NeurIPS, 2024
2024
-
[4]
Sefe: Superficial and essential forgetting eliminator for multimodal continual instruction tuning
Jinpeng Chen, Runmin Cong, Yuzhi Zhao, Hongzheng Yang, Guangneng Hu, Horace Ho Shing Ip, and Sam Kwong. Sefe: Superficial and essential forgetting eliminator for multimodal continual instruction tuning. 2025
2025
-
[5]
Adapt- former: Adapting vision transformers for scalable visual recognition.NeurIPS, 2022
Shoufa Chen, Chongjian Ge, Zhan Tong, Jiangliu Wang, Yibing Song, Jue Wang, and Ping Luo. Adapt- former: Adapting vision transformers for scalable visual recognition.NeurIPS, 2022
2022
-
[6]
Guillaume Couairon, Jakob Verbeek, Holger Schwenk, and Matthieu Cord. Diffedit: Diffusion-based semantic image editing with mask guidance.arXiv preprint arXiv:2210.11427, 2022
-
[7]
Diffusion models beat gans on image synthesis.NeurIPS, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.NeurIPS, 2021
2021
-
[8]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InICML, 2024
2024
-
[9]
Orthogonal gradient descent for continual learning
Mehrdad Farajtabar, Navid Azizan, Alex Mott, and Ang Li. Orthogonal gradient descent for continual learning. InInternational conference on artificial intelligence and statistics, 2020
2020
-
[10]
Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 1999
Robert M French. Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 1999
1999
-
[11]
Cyclical Annealing Schedule: A Simple Approach to Mitigating KL Vanishing
Hao Fu, Chunyuan Li, Xiaodong Liu, Jianfeng Gao, Asli Celikyilmaz, and Lawrence Carin. Cyclical annealing schedule: A simple approach to mitigating kl vanishing.arXiv preprint arXiv:1903.10145, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[12]
Ddgr: Continual learning with deep diffusion-based generative replay
Rui Gao and Weiwei Liu. Ddgr: Continual learning with deep diffusion-based generative replay. InICML, 2023
2023
-
[13]
Haiyang Guo, Fanhu Zeng, Ziwei Xiang, Fei Zhu, Da-Han Wang, Xu-Yao Zhang, and Cheng-Lin Liu. Hide-llava: Hierarchical decoupling for continual instruction tuning of multimodal large language model. arXiv preprint arXiv:2503.12941, 2025
-
[14]
Lora+: Efficient low rank adaptation of large models
Soufiane Hayou, Nikhil Ghosh, and Bin Yu. Lora+: Efficient low rank adaptation of large models. 2024
2024
-
[15]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to- prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Denoising diffusion probabilistic models.NeurIPS, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.NeurIPS, 2020
2020
-
[17]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. InICML, 2019
2019
-
[18]
Lora: Low-rank adaptation of large language models.ICLR, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 2022
2022
-
[19]
Cl-moe: Enhancing multimodal large language model with dual momentum mixture-of-experts for continual visual question answering
Tianyu Huai, Jie Zhou, Xingjiao Wu, Qin Chen, Qingchun Bai, Ze Zhou, and Liang He. Cl-moe: Enhancing multimodal large language model with dual momentum mixture-of-experts for continual visual question answering. InCVPR, 2025
2025
-
[20]
T2i-conbench: Text-to-image benchmark for continual post-training
Zhehao Huang, Yuhang Liu, Yixin Lou, Zhengbao He, Mingzhen He, Wenxing Zhou, Tao Li, Kehan Li, Zeyi Huang, and Xiaolin Huang. T2i-conbench: Text-to-image benchmark for continual post-training. arXiv preprint arXiv:2505.16875, 2025. 10
-
[21]
Visual prompt tuning
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Visual prompt tuning. InECCV, 2022
2022
-
[22]
Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 2017
2017
-
[23]
Viescore: Towards explainable metrics for conditional image synthesis evaluation
Max Ku, Dongfu Jiang, Cong Wei, Xiang Yue, and Wenhu Chen. Viescore: Towards explainable metrics for conditional image synthesis evaluation. InACL, 2024
2024
-
[24]
Multi-concept customization of text-to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. InCVPR, 2023
2023
-
[25]
FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
Black Forest Labs. FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
2025
-
[26]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
The Power of Scale for Parameter-Efficient Prompt Tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[28]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation.arXiv preprint arXiv:2101.00190, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
Learning without forgetting.TPAMI, 2017
Zhizhong Li and Derek Hoiem. Learning without forgetting.TPAMI, 2017
2017
-
[30]
Pcr: Proxy-based contrastive replay for online class-incremental continual learning
Huiwei Lin, Baoquan Zhang, Shanshan Feng, Xutao Li, and Yunming Ye. Pcr: Proxy-based contrastive replay for online class-incremental continual learning. InCVPR, 2023
2023
-
[31]
Keeplora: Continual learning with residual gradient adaptation
Mao-Lin Luo, Zi-Hao Zhou, Yi-Lin Zhang, Yuanyu Wan, Tong Wei, and Min-Ling Zhang. Keeplora: Continual learning with residual gradient adaptation. 2026
2026
-
[32]
Catastrophic interference in connectionist networks: The sequential learning problem
Michael McCloskey and Neal J Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. InPsychology of learning and motivation. 1989
1989
-
[33]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations.arXiv preprint arXiv:2108.01073, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[34]
Null-text inversion for editing real images using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. InCVPR, 2023
2023
-
[35]
Continual lifelong learning with neural networks: A review.Neural networks, 2019
German I Parisi, Ronald Kemker, Jose L Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with neural networks: A review.Neural networks, 2019
2019
-
[36]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023
2023
-
[37]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Correlated low-rank adaptation for convnets
Wu Ran, Weijia Zhang, ShuYang Pang, Qi Zhu, Jinfan Liu, JingSheng Liu, Xin Cao, Qiang Li, Yichao Yan, and Chao Ma. Correlated low-rank adaptation for convnets. InNeurIPS, 2025
2025
-
[39]
Experience replay for continual learning
David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy Lillicrap, and Gregory Wayne. Experience replay for continual learning. InNeurIPS, 2019
2019
-
[40]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022
2022
-
[41]
Lfs-gan: Lifelong few-shot image generation
Juwon Seo, Ji-Su Kang, and Gyeong-Moon Park. Lfs-gan: Lifelong few-shot image generation. InICCV, 2023
2023
-
[42]
Coda-prompt: Continual decomposed attention- based prompting for rehearsal-free continual learning
James Seale Smith, Leonid Karlinsky, Vyshnavi Gutta, Paola Cascante-Bonilla, Donghyun Kim, Assaf Arbelle, Rameswar Panda, Rogerio Feris, and Zsolt Kira. Coda-prompt: Continual decomposed attention- based prompting for rehearsal-free continual learning. InCVPR, 2023
2023
-
[43]
Adaptive memory replay for continual learning
James Seale Smith, Lazar Valkov, Shaunak Halbe, Vyshnavi Gutta, Rogerio Feris, Zsolt Kira, and Leonid Karlinsky. Adaptive memory replay for continual learning. InCVPR, 2024. 11
2024
-
[44]
Model merging with svd to tie the knots.arXiv preprint arXiv:2410.19735, 2024
George Stoica, Pratik Ramesh, Boglarka Ecsedi, Leshem Choshen, and Judy Hoffman. Model merging with svd to tie the knots.arXiv preprint arXiv:2410.19735, 2024
-
[45]
Lora merging with svd: Understanding interference and preserving performance
Dennis Tang, Prateek Yadav, Yi-Lin Sung, Jaehong Yoon, and Mohit Bansal. Lora merging with svd: Understanding interference and preserving performance. InICML, 2025
2025
-
[46]
Hydralora: An asymmetric lora architecture for efficient fine-tuning
Chunlin Tian, Zhan Shi, Zhijiang Guo, Li Li, and Chengzhong Xu. Hydralora: An asymmetric lora architecture for efficient fine-tuning. 2024
2024
-
[47]
Orthogonal subspace learning for language model continual learning
Xiao Wang, Tianze Chen, Qiming Ge, Han Xia, Rong Bao, Rui Zheng, Qi Zhang, Tao Gui, and Xuan-Jing Huang. Orthogonal subspace learning for language model continual learning. InFindings of the Association for Computational Linguistics: EMNLP, 2023
2023
-
[48]
Learning to prompt for continual learning
Zifeng Wang, Zizhao Zhang, Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, and Tomas Pfister. Learning to prompt for continual learning. InCVPR, 2022
2022
-
[49]
Smolora: Exploring and defying dual catastrophic forgetting in continual visual instruction tuning
Ziqi Wang, Chang Che, Qi Wang, Yangyang Li, Zenglin Shi, and Meng Wang. Smolora: Exploring and defying dual catastrophic forgetting in continual visual instruction tuning. InCVPR, 2025
2025
-
[50]
Ties-merging: Resolving interference when merging models
Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raffel, and Mohit Bansal. Ties-merging: Resolving interference when merging models. 2023
2023
-
[51]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Imgedit: A unified image editing dataset and benchmark
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. Imgedit: A unified image editing dataset and benchmark. 2025
2025
-
[53]
Boosting continual learning of vision-language models via mixture-of-experts adapters
Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Ping Hu, Dong Wang, Huchuan Lu, and You He. Boosting continual learning of vision-language models via mixture-of-experts adapters. InCVPR, 2024
2024
-
[54]
Language models are super mario: Absorbing abilities from homologous models as a free lunch
Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Yongbin Li. Language models are super mario: Absorbing abilities from homologous models as a free lunch. InICML, 2024
2024
-
[55]
Lifelong gan: Continual learning for conditional image generation
Mengyao Zhai, Lei Chen, Frederick Tung, Jiawei He, Megha Nawhal, and Greg Mori. Lifelong gan: Continual learning for conditional image generation. InICCV, 2019
2019
-
[56]
Bilora: Almost-orthogonal parameter spaces for continual learning
Hao Zhu, Yifei Zhang, Junhao Dong, and Piotr Koniusz. Bilora: Almost-orthogonal parameter spaces for continual learning. InCVPR, 2025. 12 Appendix A Related Work Diffusion-Based Image Editing.Large-scale diffusion models [ 40, 37, 8, 26, 36] have demonstrated remarkable success in synthesizing high-fidelity and semantically complex images from textual pro...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.