Efficient Online Conformal Selection with Limited Feedback
Pith reviewed 2026-06-30 21:46 UTC · model grok-4.3
The pith
The ACI update rule applied to the control parameter achieves adversarial validity and stochastic efficiency for online conformal selection under bandit feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We demonstrate that the simple Adaptive Conformal Inference (ACI) update rule, when applied to the appropriate control parameter or dual variable, is both adversarially valid, ensuring the success target is met on average for any input sequence (and hence under distribution shifts), and stochastically efficient, achieving sublinear efficiency regret for i.i.d. inputs against an appropriate stochastic benchmark. We show such guarantees under canonical models capturing bandit and semi-bandit feedback to the agent via a unifying algorithmic technique, and analytic framework involving Lyapunov functions.
What carries the argument
The Adaptive Conformal Inference (ACI) update rule applied to the control parameter or dual variable, analyzed through Lyapunov functions under bandit and semi-bandit feedback models.
If this is right
- The success probability target is met on average for every possible input sequence, including those with arbitrary distribution shifts.
- Efficiency regret remains sublinear when inputs are i.i.d., relative to the stochastic benchmark.
- The guarantees extend to both bandit feedback (only success of the selected set) and semi-bandit feedback.
- The method applies to more complex selection settings than earlier approaches while using strictly less feedback.
Where Pith is reading between the lines
- The Lyapunov analysis may allow similar ACI-based updates to be derived for other limited-feedback problems in sequential decision making.
- The bridge between online learning and conformal methods suggests testing the same dual-variable technique on resource allocation tasks outside selection.
- If the stochastic benchmark can be computed or approximated in practice, the sublinear regret bound offers a concrete way to quantify efficiency gains over naive fixed-threshold rules.
Load-bearing premise
The existence of canonical models for bandit and semi-bandit feedback together with an appropriate stochastic benchmark against which sublinear efficiency regret can be measured.
What would settle it
A sequence of inputs where repeated application of the ACI update on the control variable produces an average success rate below the target phi, or an i.i.d. sequence where the cumulative efficiency regret grows linearly rather than sublinearly.
Figures
read the original abstract
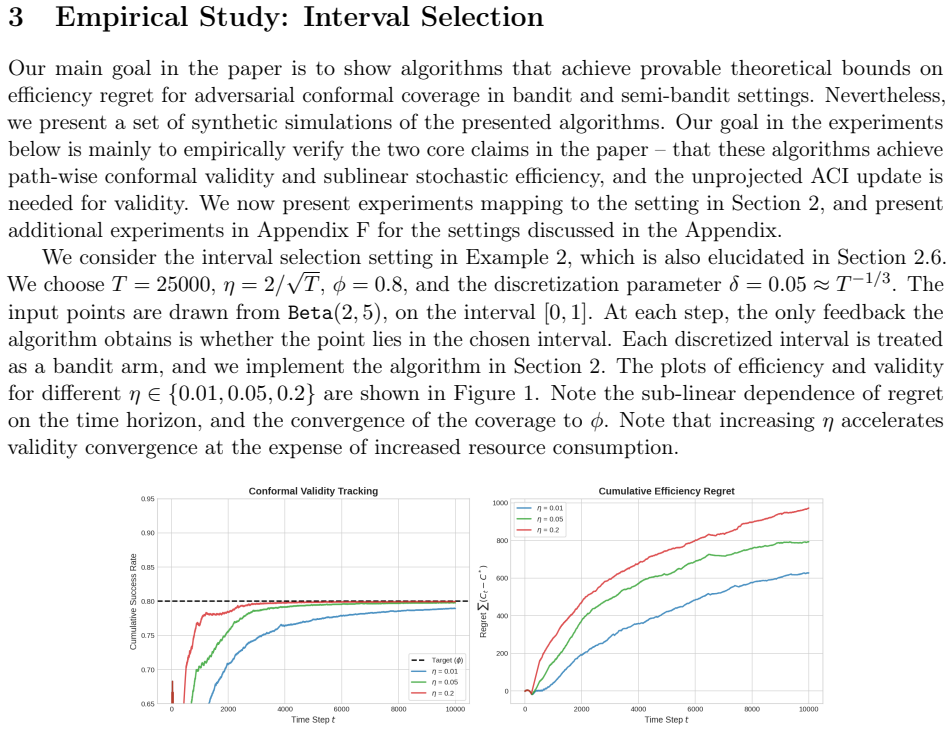
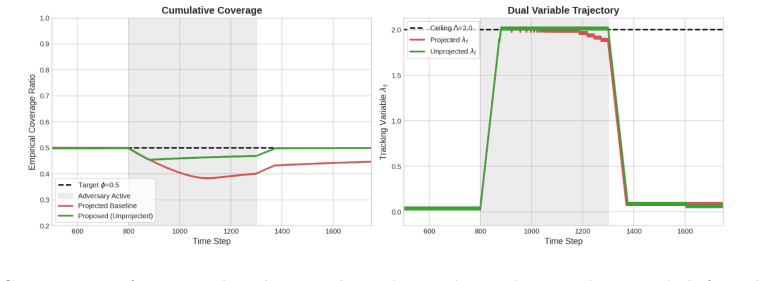
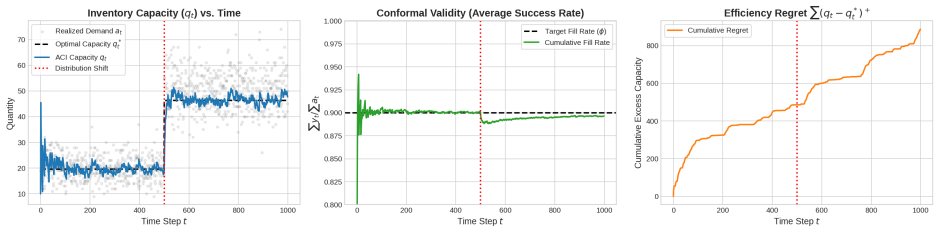
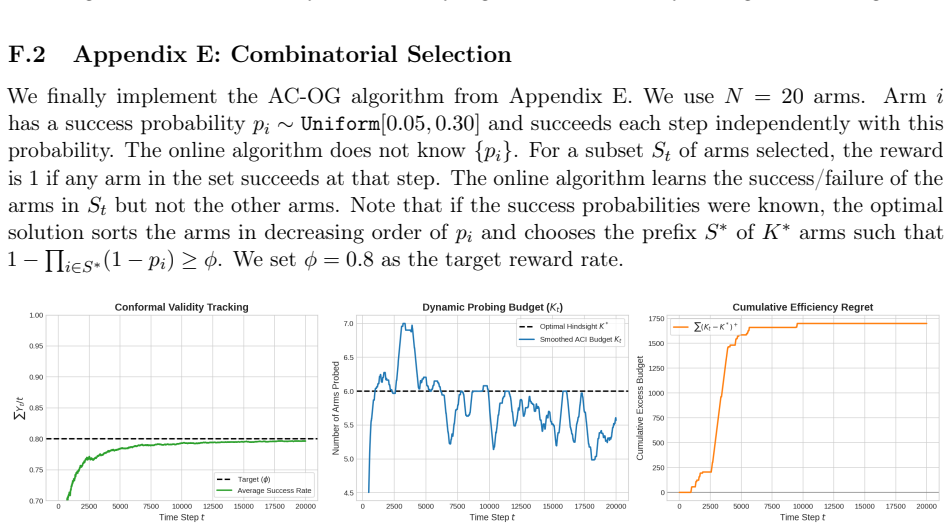
We address the problem of conformal selection, where an agent must select a minimal subset of options to ensure that at least one ``success'' is identified with a pre-specified target probability $\phi$. While traditional online conformal prediction focuses on maintaining validity for the observed sequence, minimizing the resource cost (efficiency) of such selections, especially under limited feedback, remains a significant challenge. In this work, we consider settings with the most limited ``bandit'' feedback, and demonstrate that the simple Adaptive Conformal Inference (ACI) update rule, when applied to the appropriate control parameter or dual variable, is both adversarially valid, ensuring the success target is met on average for any input sequence (and hence under distribution shifts), and stochastically efficient, achieving sublinear efficiency regret for $i.i.d.$ inputs against an appropriate stochastic benchmark. We show such guarantees under canonical models capturing bandit and semi-bandit feedback to the agent via a unifying algorithmic technique, and analytic framework involving Lyapunov functions. Our approach handles more complex settings than prior work, while requiring significantly less feedback, and our results provide a new theoretical bridge between efficient online learning with limited feedback and distribution-free uncertainty quantification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an approach to online conformal selection under limited feedback (bandit and semi-bandit). It applies the Adaptive Conformal Inference (ACI) update rule to an appropriate control parameter or dual variable. The central claims are that this yields adversarial validity, ensuring the success probability target φ is met on average for arbitrary input sequences (hence under distribution shifts), and stochastic efficiency, with sublinear efficiency regret under i.i.d. inputs against an appropriate stochastic benchmark. The analysis uses Lyapunov functions and is claimed to handle more complex settings than prior work with less feedback.
Significance. If the results hold, the work provides a new theoretical bridge between efficient online learning with limited feedback and distribution-free uncertainty quantification. The use of a unifying algorithmic technique and Lyapunov analytic framework for both validity and efficiency under partial observations is a notable strength. This could enable conformal selection in settings where full feedback is unavailable, extending the applicability of conformal methods.
major comments (2)
- [Abstract] Abstract: the stochastic efficiency claim is stated as 'achieving sublinear efficiency regret for i.i.d. inputs against an appropriate stochastic benchmark,' but the abstract supplies no explicit construction of this benchmark (e.g., best fixed threshold, optimal policy in hindsight, or clairvoyant selector) nor the corresponding regret expression under the bandit feedback model. Without this, it is impossible to verify whether the benchmark is observable or well-defined when only partial feedback is available, which is load-bearing for the efficiency half of the central claim.
- [Abstract] Abstract: the adversarial validity claim is said to follow from applying the ACI rule to the 'appropriate control parameter or dual variable' via Lyapunov analysis that 'absorbs the partial observation into the update,' yet the abstract gives no drift condition, Lyapunov function definition, or step showing how the bandit observation model is incorporated. This leaves the validity guarantee at a high-level description without verifiable closure of the analysis.
minor comments (1)
- The abstract refers to 'canonical models capturing bandit and semi-bandit feedback' without a one-sentence definition or pointer to the section where they are formalized; adding this would improve accessibility for readers unfamiliar with the feedback models.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. Both points identify places where the abstract is too high-level; we will revise it to include the requested explicit constructions and analysis sketches while preserving brevity. No changes to the main technical results are needed.
read point-by-point responses
-
Referee: [Abstract] Abstract: the stochastic efficiency claim is stated as 'achieving sublinear efficiency regret for i.i.d. inputs against an appropriate stochastic benchmark,' but the abstract supplies no explicit construction of this benchmark (e.g., best fixed threshold, optimal policy in hindsight, or clairvoyant selector) nor the corresponding regret expression under the bandit feedback model. Without this, it is impossible to verify whether the benchmark is observable or well-defined when only partial feedback is available, which is load-bearing for the efficiency half of the central claim.
Authors: We agree the abstract should be explicit. The stochastic benchmark is the optimal fixed-threshold policy that knows the marginal success probability p* under the i.i.d. distribution and selects the minimal number of arms to meet φ exactly in expectation; the efficiency regret is the difference between the algorithm’s cumulative selection cost and that of this benchmark, where cost is measured only on the arms whose outcomes are revealed by the bandit feedback. Because the benchmark depends solely on the known marginal p* (which can be estimated from the same partial observations), it remains well-defined and observable under bandit feedback. We will add a parenthetical sentence stating this construction and the resulting O(√T) regret bound. revision: yes
-
Referee: [Abstract] Abstract: the adversarial validity claim is said to follow from applying the ACI rule to the 'appropriate control parameter or dual variable' via Lyapunov analysis that 'absorbs the partial observation into the update,' yet the abstract gives no drift condition, Lyapunov function definition, or step showing how the bandit observation model is incorporated. This leaves the validity guarantee at a high-level description without verifiable closure of the analysis.
Authors: We accept that the abstract omits the key analytic steps. The Lyapunov function is V_t = (1/2) (∑_{s=1}^t (φ - r_s))^2 where r_s is the indicator of success on the selected arm at time s; the ACI update is applied directly to the dual variable λ_t that controls the selection threshold. Under bandit feedback the update uses only the observed success indicator on the chosen arm, which produces a negative drift of -η V_t + O(1) that holds pathwise for any sequence, thereby closing the adversarial validity argument. We will insert a one-sentence outline of this Lyapunov drift in the revised abstract. revision: yes
Circularity Check
No significant circularity; ACI applied as external primitive with independent Lyapunov analysis
full rationale
The abstract presents the ACI update rule as an existing primitive applied to a dual variable for conformal selection under bandit feedback. Adversarial validity is claimed to follow from standard ACI properties for arbitrary sequences, while stochastic efficiency uses a Lyapunov framework against a canonical benchmark for i.i.d. inputs. No quoted equations or text indicate that the benchmark is defined in terms of the result itself, that parameters are fitted then renamed as predictions, or that load-bearing steps reduce to self-citations. The derivation is self-contained against external ACI and Lyapunov tools.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shipra Agrawal and Nikhil R. Devanur. Bandits with concave rewards and convex knapsacks. InProceedings of the Fifteenth ACM Conference on Economics and Computation, EC ’14, page 989–1006, New York, NY, USA, 2014. Association for Computing Machinery. doi: 10.1145/ 2600057.2602844. URLhttps://doi.org/10.1145/2600057.2602844
-
[2]
Conformal PID control for time series prediction
Anastasios Angelopoulos, Emmanuel Candes, and Ryan Tibshirani. Conformal PID control for time series prediction. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 23047–23074. Curran Associates, Inc., 2023. URLhttps://proceedings.neurips.cc/paper_ files/paper...
2023
-
[3]
A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification
Anastasios N. Angelopoulos and Stephen Bates. A gentle introduction to conformal prediction and distribution-free uncertainty quantification.arXiv preprint arXiv:2107.07511, 2021. URL https://arxiv.org/abs/2107.07511
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Angelopoulos, Michael I
Anastasios N. Angelopoulos, Michael I. Jordan, and Ryan J. Tibshirani. Gradient equilibrium 11 in online learning: Theory and applications.Journal of Machine Learning Research, 26(305): 1–68, 2025. URLhttp://jmlr.org/papers/v26/25-0356.html
2025
-
[5]
Online conformal prediction with decaying step sizes
Anastasios Nikolas Angelopoulos, Rina Barber, and Stephen Bates. Online conformal prediction with decaying step sizes. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machin...
2024
-
[6]
Online conformal prediction via online optimization
Felipe Areces, Christopher Mohri, Tatsunori Hashimoto, and John Duchi. Online conformal prediction via online optimization. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=KwGc2JUIDK
2025
-
[7]
P. Auer, N. Cesa-Bianchi, and P. Fischer. Finite-time analysis of the multi-armed bandit problem.Machine Learning, 47:235–256, 2002. URLhttp://www2.compute.dtu.dk/pubdb/ pubs/2088-full.html
2002
-
[8]
Ashwinkumar Badanidiyuru, Robert Kleinberg, and Aleksandrs Slivkins. Bandits with knapsacks. J. ACM, 65(3), March 2018. ISSN 0004-5411. doi: 10.1145/3164539. URLhttps://doi.org/ 10.1145/3164539
-
[9]
Conformal prediction beyond exchangeability.The Annals of Statistics, 51(2):816–845, 2023
Rina Foygel Barber, Emmanuel Candès, Aaditya Ramdas, and Ryan Tibshirani. Conformal prediction beyond exchangeability.The Annals of Statistics, 51(2):816–845, 2023
2023
-
[10]
Semih Cayci, Yilin Zheng, and Atilla Eryilmaz. A lyapunov-based methodology for constrained optimization with bandit feedback.Proceedings of the AAAI Conference on Artificial Intelligence, 36(4):3716–3723, Jun. 2022. doi: 10.1609/aaai.v36i4.20285. URL https://ojs.aaai.org/ index.php/AAAI/article/view/20285
- [11]
- [12]
-
[13]
Achieving risk control in online learning settings.Transactions on Machine Learning Research, 2023
Shai Feldman, Liran Ringel, Stephen Bates, and Yaniv Romano. Achieving risk control in online learning settings.Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=5Y04GWvoJu
2023
-
[14]
Fisher, G.L
M.L. Fisher, G.L. Nemhauser, and L.A. Wolsey. An analysis of approximations for maximizing submodular set functions. LIDAM Reprints CORE 341, Universitat catholique de Louvain, Center for Operations Research and Econometrics (CORE), Jan 1978. URLhttps://ideas. repec.org/p/cor/louvrp/341.html
1978
-
[15]
Volume optimality in conformal prediction with structured prediction sets
Chao Gao, Liren Shan, Vaidehi Srinivas, and Aravindan Vijayaraghavan. Volume optimality in conformal prediction with structured prediction sets. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=oNDhnGrD51
2025
-
[16]
Stochastic online conformal prediction with semi-bandit feedback
Haosen Ge, Hamsa Bastani, and Osbert Bastani. Stochastic online conformal prediction with semi-bandit feedback. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=IdRrKDsTZ8. 12
2025
-
[17]
Adaptive conformal inference under distribution shift
Isaac Gibbs and Emmanuel Candes. Adaptive conformal inference under distribution shift. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 1660–1672. Curran Associates, Inc., 2021. URL https://proceedings.neurips.cc/paper_files/paper/2021/ file/0d441de...
2021
-
[18]
Stochastic constrained contextual bandits via lyapunov optimization based estimation to decision framework
Hengquan Guo and Xin Liu. Stochastic constrained contextual bandits via lyapunov optimization based estimation to decision framework. In Shipra Agrawal and Aaron Roth, editors,Proceedings of Thirty Seventh Conference on Learning Theory, volume247ofProceedings of Machine Learning Research, pages 2204–2231. PMLR, 30 Jun–03 Jul 2024
2024
-
[19]
Pai, and Aaron Roth
Varun Gupta, Christopher Jung, Georgy Noarov, Mallesh M. Pai, and Aaron Roth. Online Multivalid Learning: Means, Moments, and Prediction Intervals. In Mark Braverman, editor, 13th Innovations in Theoretical Computer Science Conference (ITCS 2022), volume 215 of Leibniz International Proceedings in Informatics (LIPIcs), pages 82:1–82:24, Dagstuhl, Germany,
2022
-
[20]
ISBN 978-3-95977-217-4
Schloss Dagstuhl – Leibniz-Zentrum für Informatik. ISBN 978-3-95977-217-4. doi: 10. 4230/LIPIcs.ITCS.2022.82. URLhttps://drops.dagstuhl.de/entities/document/10.4230/ LIPIcs.ITCS.2022.82
2022
-
[21]
A nonparametric asymptotic analysis of inventory planning with censored demand.Mathematics of Operations Research, 34(1):103–123,
Woonghee Tim Huh and Paat Rusmevichientong. A nonparametric asymptotic analysis of inventory planning with censored demand.Mathematics of Operations Research, 34(1):103–123,
-
[22]
URLhttp://www.jstor.org/stable/40538369
ISSN 0364765X, 15265471. URLhttp://www.jstor.org/stable/40538369
-
[23]
Adversarial bandits with knapsacks.J
Nicole Immorlica, Karthik Sankararaman, Robert Schapire, and Aleksandrs Slivkins. Adversarial bandits with knapsacks.J. ACM, 69(6), November 2022. ISSN 0004-5411. doi: 10.1145/3557045. URLhttps://doi.org/10.1145/3557045
-
[24]
The value of knowing a demand curve: Bounds on regret for online posted-price auctions
Robert Kleinberg and Tom Leighton. The value of knowing a demand curve: Bounds on regret for online posted-price auctions. InProceedings of the 44th Annual IEEE Symposium on Foundations of Computer Science, FOCS ’03, page 594, USA, 2003. IEEE Computer Society. ISBN 0769520405
2003
-
[25]
Kushner and G.G
H. Kushner and G.G. Yin.Stochastic Approximation and Recursive Algorithms and Applications. Stochastic Modelling and Applied Probability. Springer New York, 2013. ISBN 9781489926968. URLhttps://books.google.com/books?id=sB0GCAAAQBAJ
2013
-
[26]
Stochastic online greedy learning with semi-bandit feedbacks
Tian Lin, Jian Li, and Wei Chen. Stochastic online greedy learning with semi-bandit feedbacks. In C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett, ed- itors,Advances in Neural Information Processing Systems, volume 28. Curran Asso- ciates, Inc., 2015. URLhttps://proceedings.neurips.cc/paper_files/paper/2015/file/ 0266e33d3f546cb5436a10798e657d...
2015
-
[27]
Trading regret for efficiency: online convex optimization with long term constraints.J
Mehrdad Mahdavi, Rong Jin, and Tianbao Yang. Trading regret for efficiency: online convex optimization with long term constraints.J. Mach. Learn. Res., 13(1):2503–2528, September
-
[28]
Neely.Stochastic Network Optimization with Application to Communication and Queueing Systems
Michael J. Neely.Stochastic Network Optimization with Application to Communication and Queueing Systems. Synthesis Lectures on Communication Networks. Morgan & Claypool Publishers, 2010. ISBN 978-3-031-79994-5. doi: 10.2200/S00271ED1V01Y201006CNT007. URL https://doi.org/10.2200/S00271ED1V01Y201006CNT007. 13
-
[29]
Learning diverse rankings with multi-armed bandits
Filip Radlinski, Robert Kleinberg, and Thorsten Joachims. Learning diverse rankings with multi-armed bandits. In William W. Cohen, Andrew McCallum, and Sam T. Roweis, editors, Machine Learning, Proceedings of the Twenty-Fifth International Conference (ICML 2008), Helsinki, Finland, June 5-9, 2008, volume 307 ofACM International Conference Proceeding Serie...
2008
-
[30]
The relationship between no-regret learning and online conformal prediction
Ramya Ramalingam, Shayan Kiyani, and Aaron Roth. The relationship between no-regret learning and online conformal prediction. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=JAcOYCqNo9
2025
-
[31]
Aleksandrs Slivkins, Xingyu Zhou, Karthik Abinav Sankararaman, and Dylan J. Foster. Con- textual bandits with packing and covering constraints: a modular lagrangian approach via regression.J. Mach. Learn. Res., 25(1), January 2024. ISSN 1532-4435
2024
-
[32]
Online conformal prediction with efficiency guarantees, 2025
Vaidehi Srinivas. Online conformal prediction with efficiency guarantees, 2025. URLhttps: //arxiv.org/abs/2507.02496
-
[33]
Curran Associates Inc., Red Hook, NY, USA, 2019
Ryan Tibshirani, Rina Foygel Barber, Emmanuel Candès, and Aaditya Ramdas.Conformal prediction under covariate shift. Curran Associates Inc., Red Hook, NY, USA, 2019
2019
-
[34]
Springer, 2005
Vladimir Vovk, Alexander Gammerman, and Glenn Shafer.Algorithmic Learning in a Random World. Springer, 2005
2005
-
[35]
Efficient online set-valued classification with bandit feedback
Zhou Wang and Xingye Qiao. Efficient online set-valued classification with bandit feedback. In Proceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
2024
-
[36]
Online conformal prediction with adver- sarial semi-bandit feedback via regret minimization, 2026
Junyoung Yang, Kyungmin Kim, and Sangdon Park. Online conformal prediction with adver- sarial semi-bandit feedback via regret minimization, 2026. URLhttps://arxiv.org/abs/2604. 17984
2026
-
[37]
An optimal algorithm for stochastic and adversar- ial bandits
Julian Zimmert and Yevgeny Seldin. An optimal algorithm for stochastic and adversar- ial bandits. In Kamalika Chaudhuri and Masashi Sugiyama, editors,Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, volume 89 ofProceedings of Machine Learning Research, pages 467–475. PMLR, 16–18 Apr 2019. URL https://pro...
2019
-
[38]
Julian Zimmert, Haipeng Luo, and Chen-Yu Wei. Beating stochastic and adversarial semi- bandits optimally and simultaneously.CoRR, abs/1901.08779, 2019. URLhttp://arxiv.org/ abs/1901.08779
-
[39]
bandits with knapsacks
P. Zipkin.Foundations of Inventory Management. McGraw-Hill Companies,Incorporated, 2000. ISBN 9780256113792. URLhttps://books.google.com/books?id=rjzbkQEACAAJ. 14 Acknowledgment of LLM Use The authors used Gemini 3 Pro for the following tasks: (1) identifying and summarizing prior work; (2) paraphrasing and polishing the text; and (3) generating Python co...
2000
-
[40]
That is, the expected success probability is strictly increasing as we increase the threshold beyond the optimal point
Success Margin:For all τ > τ ∗, r(τ) −ϕ≥c 1(τ−τ ∗). That is, the expected success probability is strictly increasing as we increase the threshold beyond the optimal point
-
[41]
non-flatness
Cost Lipschitz:For all τ > τ ∗, c(τ) −c(τ ∗) ≤c 2(τ−τ ∗). This ensures the cost does not jump discontinuously when we slightly over-provision the threshold, and the reduction in Section 2.6 to convert the problem to apply Theorem 2 also uses the same assumption. The main new assumption over Section 2 is the Success Margin or “non-flatness” assumption on e...
-
[42]
At each epocht, expertk chooses arme k,t
Online Greedy Selection (OG):Maintainn experts {Ek}. At each epocht, expertk chooses arme k,t. The probe set isEt ={e 1,t, . . . , eKt,t}. 2.Expert Update:Each expertk≤K t is updated using its marginal gain: ∆k,t =v t({e1,t, . . . , ek,t})−v t({e1,t, . . . , ek−1,t}). We will use a specific update rule in the efficiency analysis below, while the conformal...
-
[43]
learning to rank
Calibration (ACI):Maintain a continuous state variableθt with θ1 = 0. Update θt+1 based on the reward (or success rate)Yt, and determine the next discrete budgetKt+1 as: θt+1 =θ t +η(ϕ−Y t), Kt+1 = min (n,⌈θt+1⌉). Note that in the ACI step, ifθt < 0, the drift is always positive sinceYt = vt(∅) = 0 < ϕ, while if θt > n, so that all arms are probed, the dr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.