From Scenes to Elements: Multi-Granularity Evidence Retrieval for Verifiable Multimodal RAG
Pith reviewed 2026-06-30 20:31 UTC · model grok-4.3
The pith
GranuRAG retrieves evidence at the visual-element level instead of whole scenes to make multimodal RAG verifiable and more accurate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating detected visual elements rather than whole scenes as the atomic units for retrieval and grounding, GranuRAG produces evidence that can be explicitly attributed, thereby supporting verifiable generation on fine-grained multimodal questions that involve only partial views of entities.
What carries the argument
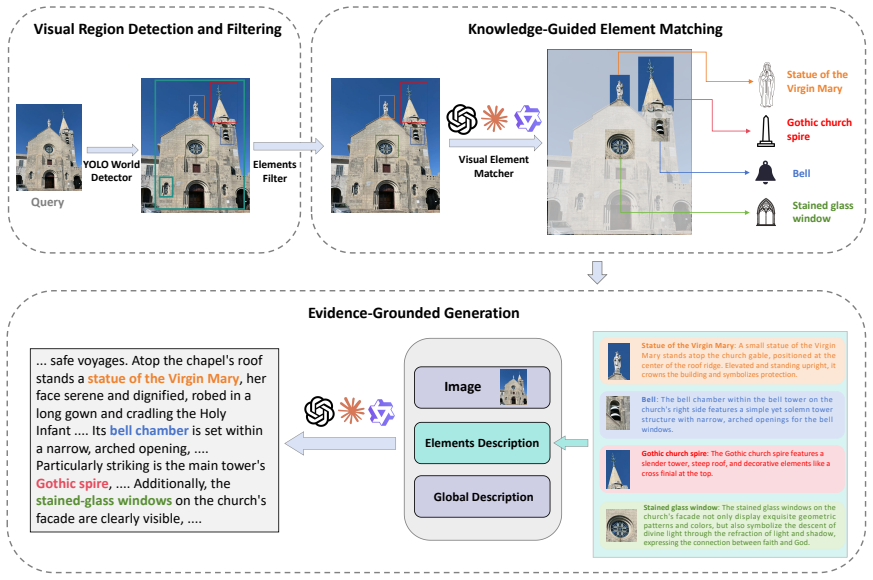
GranuRAG three-stage pipeline that performs element-level detection and classification, followed by multi-granularity cross-modal alignment for retrieval, and attribution-constrained generation.
If this is right
- Retrieval can now be aligned to the exact granularity of a user's query rather than defaulting to full scenes.
- Generation failures can be traced to specific missing or misclassified elements instead of opaque attention weights.
- The same element annotations enable evaluation of partial-observation robustness across different viewpoints of the same landmark.
- Performance improves by as much as 29.2 percent on the introduced benchmark relative to prior scene-level methods.
Where Pith is reading between the lines
- The framework could be applied to video or 3D scenes where elements persist across frames or viewpoints.
- Attribution constraints might be extended to penalize generation that references elements absent from the retrieved set.
- Element-level units could serve as a common interface for mixing retrieval from image databases with structured knowledge bases.
Load-bearing premise
Element detection and classification can be performed reliably enough that it does not introduce new errors large enough to cancel the reported gains.
What would settle it
A controlled test in which element-detection error rates are measured separately and shown to reduce end-to-end accuracy below the scene-level baselines.
Figures


read the original abstract
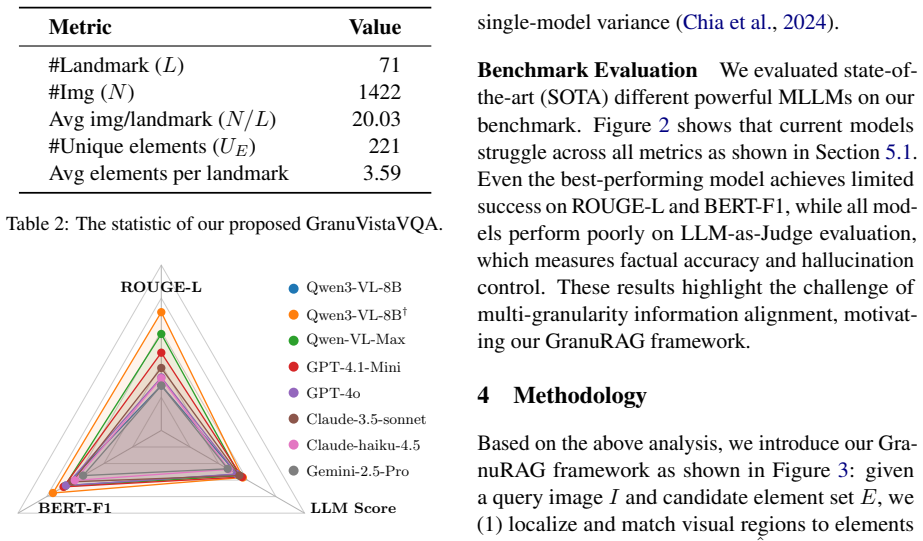
Multimodal Retrieval-Augmented Generation (RAG) systems retrieve evidence at coarse granularities (entire images or scenes), creating a mismatch with fine-grained user queries and making failures unverifiable. We introduce GranuVistaVQA, a multimodal benchmark featuring real-world landmarks with element-level annotations across multiple viewpoints, capturing the partial observation challenge where individual images contain only subsets of entities. We further propose GranuRAG, a multi-granularity framework that treats visual elements as first-class retrieval units through three stages: element-level detection and classification, multi-granularity cross-modal alignment for evidence retrieval, and attribution-constrained generation. By grounding retrieval at the element level rather than relying on implicit attention, our approach enables transparent error diagnosis. Experiments demonstrate that GranuRAG achieves up to 29.2% improvement over six strong baselines for this task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
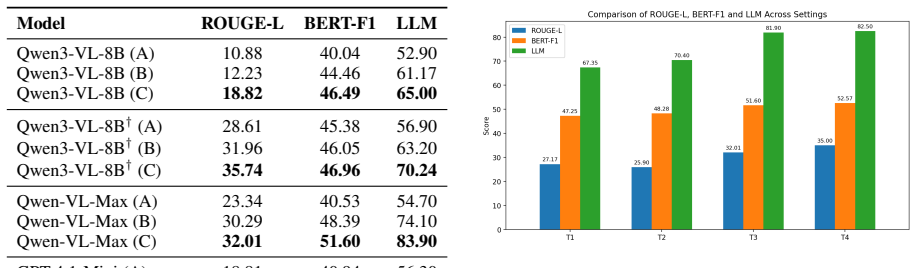
Summary. The paper introduces the GranuVistaVQA benchmark, which provides element-level annotations for real-world landmarks across multiple viewpoints to capture partial observations, and proposes GranuRAG, a three-stage multi-granularity framework (element-level detection and classification, multi-granularity cross-modal alignment for retrieval, and attribution-constrained generation) for verifiable multimodal RAG. It claims that grounding retrieval at the element level (rather than scene-level or implicit attention) enables transparent error diagnosis and yields up to 29.2% improvement over six strong baselines.
Significance. If the performance gains hold after proper controls and the element-level detection stage proves reliable without offsetting errors, the work would meaningfully advance verifiable multimodal RAG by resolving granularity mismatches between queries and evidence. The new benchmark with real-world partial-observation data is a concrete contribution that could support future falsifiable evaluations.
major comments (2)
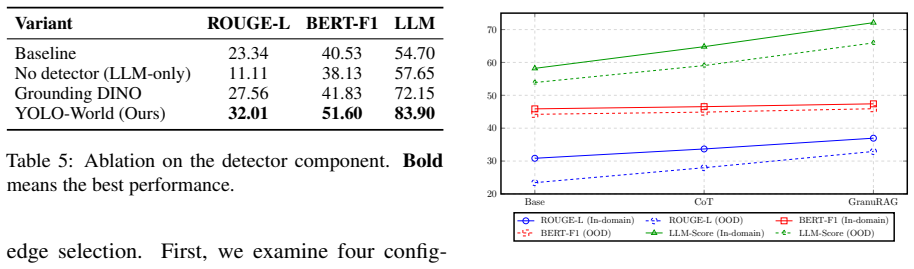
- [Framework and Experiments] The central claim that element-level detection serves as a reliable first-class retrieval unit is invoked in the three-stage framework description but is not independently validated (e.g., no separate detection accuracy metrics, ablation on detection errors, or analysis showing that detection failures do not offset the 29.2% retrieval/generation gains).
- [Experiments] The reported 29.2% improvement over six baselines cannot be assessed for robustness because the abstract (and thus the provided description) supplies no dataset statistics, error bars, cross-validation details, or controls against post-hoc baseline selection; full results tables would need to demonstrate that the gains are not driven by a single easy subset.
minor comments (2)
- [Methods] Notation for the three stages and the cross-modal alignment step should be formalized with explicit equations or pseudocode to allow reproduction.
- [Framework] Clarify how the attribution-constrained generation stage interacts with the retrieval units; the current description leaves open whether attribution is enforced at inference or only post-hoc.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on validating the detection stage and assessing result robustness. We address each major comment below.
read point-by-point responses
-
Referee: [Framework and Experiments] The central claim that element-level detection serves as a reliable first-class retrieval unit is invoked in the three-stage framework description but is not independently validated (e.g., no separate detection accuracy metrics, ablation on detection errors, or analysis showing that detection failures do not offset the 29.2% retrieval/generation gains).
Authors: We agree that the manuscript would be strengthened by independent validation of the detection stage. The GranuVistaVQA benchmark supplies element-level ground truth, enabling such metrics. In the revision we will add precision/recall for element detection, an ablation isolating detection errors, and analysis confirming that any detection failures reduce rather than inflate the reported gains. revision: yes
-
Referee: [Experiments] The reported 29.2% improvement over six baselines cannot be assessed for robustness because the abstract (and thus the provided description) supplies no dataset statistics, error bars, cross-validation details, or controls against post-hoc baseline selection; full results tables would need to demonstrate that the gains are not driven by a single easy subset.
Authors: The full manuscript already reports dataset statistics (landmarks, viewpoints, element counts) in Section 3, error bars from multiple runs in Section 5 tables, and per-query-type breakdowns. The benchmark construction with multiple partial-observation viewpoints is intended to mitigate single-subset dominance. We did not perform cross-validation because GranuVistaVQA is a fixed held-out test set; we will add explicit subset-performance tables and baseline-selection rationale in the revision. revision: partial
Circularity Check
No significant circularity detected
full rationale
The manuscript describes a three-stage framework (element detection/classification, cross-modal alignment, attribution-constrained generation) and reports empirical gains on a new benchmark. No equations, fitted parameters, or derivation steps are present that reduce by construction to inputs. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The central claims rest on experimental comparison to baselines rather than any self-referential reduction, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hallucination of Multimodal Large Language Models: A Survey
Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930. Guanhua Chen, Yutong Yao, Lidia S. Chao, Xuebo Liu, and Derek F. Wong. 2025a. SGIC: A self-guided iterative calibration framework for RAG. InProceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), ACL 20...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large lan- guage models.Preprint, arXiv:2301.12597. Chin-Yew Lin. 2004. ROUGE: A package for auto- matic evaluation of summaries. InText Summariza- tion Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics. Weizhe Lin, Jinghong Chen, Jingbia...
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[3]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Kosmos-2: Grounding multimodal large language models to the world.arXiv preprint arXiv:2306.14824. Shraman Pramanick, Rama Chellappa, and Subhashini Venugopalan. 2024. Spiqa: A dataset for multimodal question answering on scientific papers.Advances in Neural Information Processing Systems, 37:118807– 118833. Alec Radford, Jong Wook Kim, Chris Hallacy, Adi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.