Tadpole: Autoencoders as Foundation Models for 3D PDEs with Online Learning
Pith reviewed 2026-05-19 16:36 UTC · model grok-4.3
The pith
Autoencoders pre-trained on single-channel spatial crops of synthetic 3D PDE data transfer to dynamics learning and generation across diverse physical systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Tadpole is pre-trained as an autoencoder on single-channel spatial crops from an efficient online data-generation framework for 3D PDEs. This setup allows training on diverse synthetic data at massive scale. Although the pre-training task is reconstruction only, the learned representations transfer to heterogeneous physical systems. For dynamics learning, a novel fine-tuning strategy integrates low-rank adaptation, latent-space transformations, and reintroduced skip connections to achieve temporal modeling with a minimal number of trainable parameters. The model shows strong performance when applied to reconstruction, dynamics prediction, and generative modeling across different PDE systems.
What carries the argument
The central mechanism is the autoencoder pre-trained on single-channel spatial crops from online-generated 3D PDE data, paired with a parameter-efficient fine-tuning strategy that uses low-rank adaptation and latent-space transformations.
If this is right
- One pre-trained model can handle multiple downstream tasks on 3D PDEs without full retraining.
- Transfer across systems with different state variable counts and spatial resolutions becomes feasible.
- Dynamics prediction requires only a small number of additional parameters after pre-training.
- Online data generation removes storage limits and supports effectively unlimited training diversity.
- Generative modeling of physical fields can reuse the same base representations.
Where Pith is reading between the lines
- The same pre-training might reduce the need for domain-specific simulation code when adapting to new physics.
- Extending the approach to real-world sensor data instead of purely synthetic inputs could test broader applicability.
- Combining the latent representations with explicit boundary or initial condition inputs may further improve long-term prediction stability.
Load-bearing premise
Representations obtained by autoencoding single-channel spatial crops from synthetic 3D PDE data will transfer effectively to temporal dynamics modeling and generative tasks in different physical systems without large amounts of task-specific data or architecture changes.
What would settle it
Finding that fine-tuning Tadpole on a new physical system requires as many parameters or yields no better accuracy than training a fresh model from scratch on the target data would falsify the transfer claim.
Figures













































read the original abstract
We introduce Tadpole, a novel foundation model for three-dimensional partial differential equations (PDEs) that addresses key challenges in transferability, scalability to high dimensionality, and multi-functionality. Tadpole is pre-trained as an autoencoder on synthetic 3D PDE data generated by an efficient online data-generation framework. This enables large-scale, diverse training without storage or I/O overhead, demonstrated by scaling to an equivalent of hundreds of terabytes of training data. By autoencoding single-channel spatial crops, Tadpole learns rich and transferable representations across heterogeneous physical systems with varying numbers of state variables and spatial resolutions. Although pre-trained solely as an autoencoder, Tadpole can be efficiently applied for multiple downstream tasks beyond reconstruction, including dynamics learning and generative modeling. For dynamics learning, we propose a novel parameter-efficient fine-tuning strategy that integrates low-rank adaptation, latent-space transformations, and reintroduced skip connections, achieving accurate temporal modeling with a minimal number of trainable parameters. Tadpole demonstrates strong fine-tuning performance across various downstream tasks, highlighting its versatility and effectiveness as a foundation model for 3D PDE learning. Source code and pre-trained weights of Tadpole are available at https://github.com/tum-pbs/tadpole
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Tadpole, a foundation model for 3D PDEs pre-trained as an autoencoder on synthetic data generated via an online framework that scales to hundreds of terabytes without storage overhead. Pre-training uses single-channel spatial crops to learn representations claimed to transfer across heterogeneous physical systems with varying numbers of state variables and resolutions. A parameter-efficient fine-tuning strategy combining low-rank adaptation, latent-space transformations, and reintroduced skip connections is proposed for downstream tasks including dynamics learning and generative modeling, with the authors reporting strong fine-tuning performance. Source code and pre-trained weights are released.
Significance. If the transferability and efficiency claims hold under rigorous validation, Tadpole would offer a meaningful step toward foundation models for scientific machine learning on high-dimensional 3D PDEs, where data scale and task diversity are persistent bottlenecks. The online data-generation approach and the explicit parameter-efficient fine-tuning recipe are practical contributions. The public release of code and weights is a clear strength that supports reproducibility and community follow-up.
major comments (2)
- [Abstract and pre-training section] Abstract and the description of the pre-training objective: the central claim that an autoencoder trained only on reconstruction of single-channel static spatial crops produces latents sufficient for accurate temporal dynamics modeling on multi-state systems rests on the fine-tuning strategy compensating for the complete absence of temporal derivatives and cross-channel interactions in pre-training; this assumption is load-bearing and requires explicit ablation evidence (e.g., comparison of latent features with and without temporal context) to substantiate transfer across differing numbers of state variables.
- [Fine-tuning and dynamics learning section] Fine-tuning strategy description: the integration of LoRA, latent transformations, and skip connections is presented as achieving accurate time-stepping with minimal trainable parameters, yet the manuscript does not quantify how much of the dynamical information is recovered by each component versus what must be learned from scratch; without such decomposition, the efficiency claim cannot be fully evaluated.
minor comments (2)
- [Method] Notation for the latent-space transformations should be defined more explicitly, including the precise form of the skip-connection reintroduction.
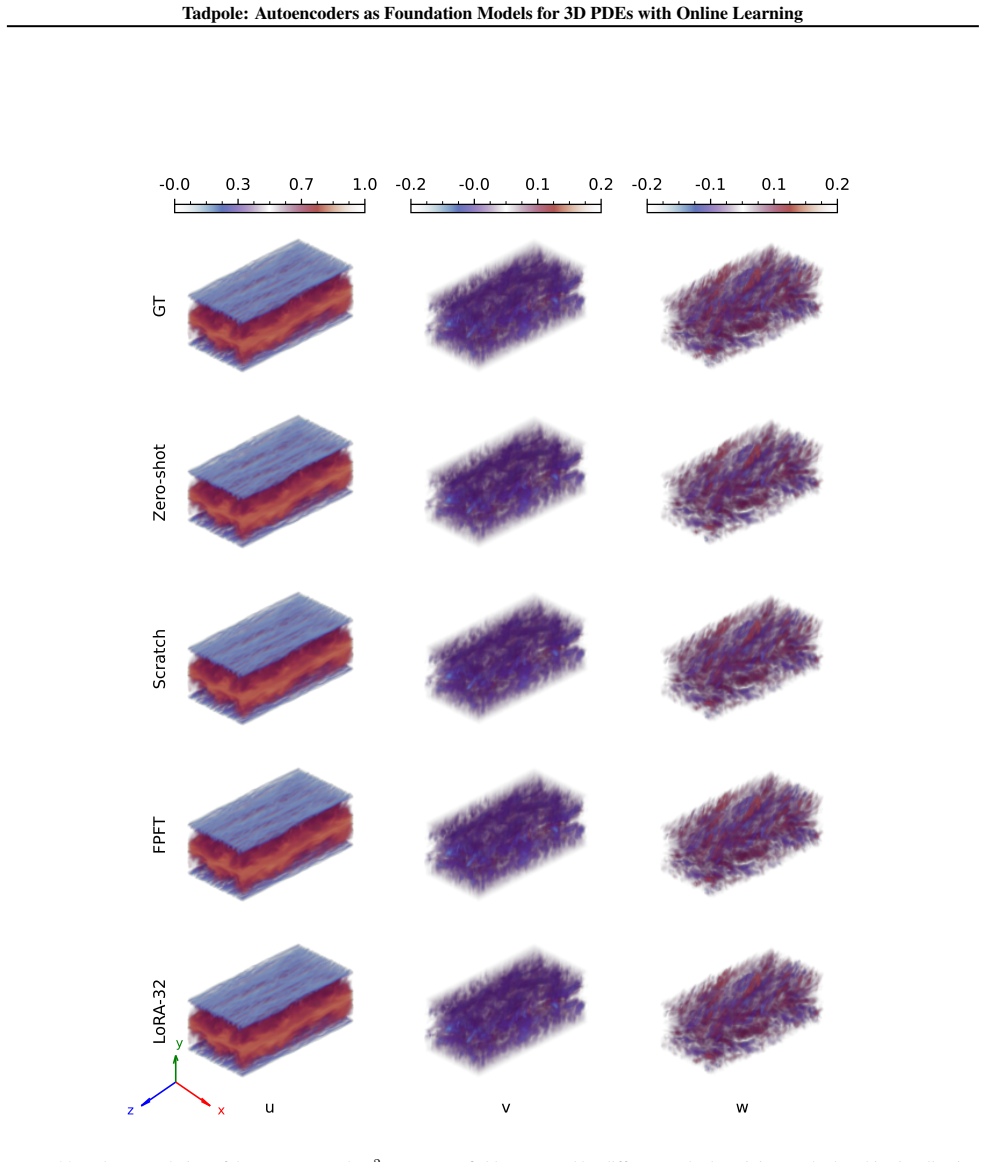
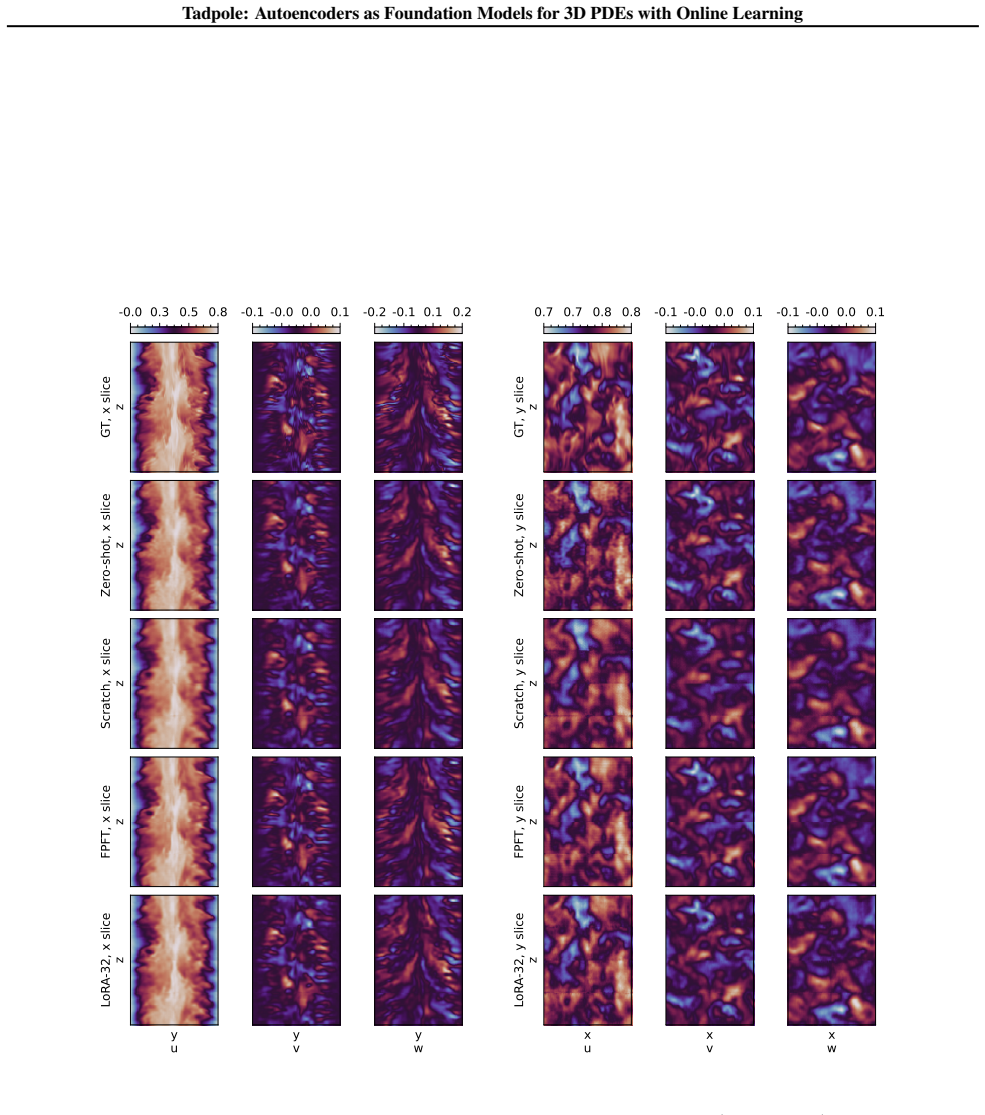
- [Results] Figure captions and axis labels in the results visualizations would benefit from clearer indication of which PDE system and resolution each panel corresponds to.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and recommendation for major revision. We address each major comment below with clarifications and commitments to strengthen the manuscript through additional analyses.
read point-by-point responses
-
Referee: [Abstract and pre-training section] Abstract and the description of the pre-training objective: the central claim that an autoencoder trained only on reconstruction of single-channel static spatial crops produces latents sufficient for accurate temporal dynamics modeling on multi-state systems rests on the fine-tuning strategy compensating for the complete absence of temporal derivatives and cross-channel interactions in pre-training; this assumption is load-bearing and requires explicit ablation evidence (e.g., comparison of latent features with and without temporal context) to substantiate transfer across differing numbers of state variables.
Authors: We appreciate the referee highlighting this key assumption. The pre-training on single-channel static crops is intentionally designed to learn general spatial representations that can transfer across heterogeneous PDE systems. The manuscript shows this transfer empirically via strong fine-tuning performance on dynamics tasks with varying state variables and resolutions. To directly address the request for explicit ablation evidence, we will add in the revised manuscript comparisons of latent features and downstream performance with versus without temporal context during fine-tuning, as well as ablations isolating cross-channel effects. These will substantiate the transferability claims. revision: yes
-
Referee: [Fine-tuning and dynamics learning section] Fine-tuning strategy description: the integration of LoRA, latent transformations, and skip connections is presented as achieving accurate time-stepping with minimal trainable parameters, yet the manuscript does not quantify how much of the dynamical information is recovered by each component versus what must be learned from scratch; without such decomposition, the efficiency claim cannot be fully evaluated.
Authors: We agree that a quantitative breakdown of each fine-tuning component's contribution would strengthen the efficiency evaluation. The current results demonstrate overall low parameter counts and accurate time-stepping, but to provide the requested decomposition, we will include in the revised manuscript ablation studies that enable or disable LoRA, latent-space transformations, and skip connections individually. These will report trainable parameter counts and prediction errors for each variant, clarifying the dynamical information recovered by each versus what is learned from scratch. revision: yes
Circularity Check
No circularity: empirical results from distinct pre-training and fine-tuning objectives
full rationale
The paper is an empirical ML study introducing Tadpole as a pre-trained autoencoder on synthetic 3D PDE spatial crops, followed by parameter-efficient fine-tuning for dynamics and generative tasks. No derivation chain exists that reduces predictions or claims to inputs by construction; performance claims rest on observed transfer across systems rather than any fitted parameter being renamed as a prediction or any self-citation defining the outcome. The pre-training objective (reconstruction of single-channel crops) and downstream objectives (temporal modeling via LoRA and skip connections) are explicitly separated, with results validated through experiments on heterogeneous PDEs. This is self-contained against external benchmarks of model performance.
Axiom & Free-Parameter Ledger
free parameters (1)
- LoRA rank and scaling factors
axioms (1)
- domain assumption Autoencoding single-channel spatial crops yields representations transferable across PDEs with different numbers of state variables and resolutions
invented entities (1)
-
Tadpole model
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
By autoencoding single-channel spatial crops, Tadpole learns rich and transferable representations across heterogeneous physical systems with varying numbers of state variables and spatial resolutions.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Tadpole-DFT introduces a lightweight sub-network S between the pre-trained Tadpole encoder and decoder with a residual connection... LoRA fine-tuning
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URL https://proceedings.mlr.press/ v235/chen24n.html. Cox, S. and Matthews, P. Exponential Time Dif- ferencing for Stiff Systems. Journal of Compu- tational Physics , 176(2):430–455, 2002. ISSN 0021-9991. doi: https://doi.org/10.1006/jcph.2002
-
[2]
URL https://www.sciencedirect.com/ science/article/pii/S0021999102969950. Ding, N., Qin, Y ., Yang, G., Wei, F., Yang, Z., Su, Y ., Hu, S., Chen, Y ., Chan, C.-M., Chen, W., Yi, J., Zhao, W., Wang, X., Liu, Z., Zheng, H.-T., Chen, J., Liu, Y ., Tang, J., Li, J., and Sun, M. Parameter-efficient fine-tuning of large-scale pre-trained language models. Nature...
-
[3]
doi: https://doi.org/10.1016/j.neucom.2021.04
-
[4]
Holzschuh, B., Liu, Q., Kohl, G., and Thuerey, N
URL https://www.sciencedirect.com/ science/article/pii/S0925231221006706. Holzschuh, B., Liu, Q., Kohl, G., and Thuerey, N. PDE- transformer: Efficient and versatile transformers for physics simulations. In Singh, A., Fazel, M., Hsu, D., Lacoste-Julien, S., Berkenkamp, F., Maharaj, T., Wagstaff, K., and Zhu, J. (eds.), International Confer- ence on Machin...
-
[5]
URL https:// epubs.siam.org/doi/10.1137/24M1636071
doi: 10.1137/24M1636071. URL https:// epubs.siam.org/doi/10.1137/24M1636071. Jollie, D., Sun, J., Zhang, Z., and Schaeffer, H. Time- Series Forecasting, Knowledge Distillation, and Refine- ment within a Multimodal PDE Foundation Model, 2024. URL https://arxiv.org/abs/2409.11609. Kassam, A.-K. and Trefethen, L. N. Fourth-Order Time- Stepping for Stiff PDEs...
-
[6]
URL https://openreview.net/forum? id=n7qGCmluZr. Li, Y ., Perlman, E., Wan, M., Yang, Y ., Meneveau, C., Burns, R., Chen, S., Szalay, A., and Eyink, G. A public turbulence database cluster and applications to study Lagrangian evolution of velocity increments in turbulence. Journal of Turbulence, 9:N31, 2008. doi: 10.1080/14685240802376389. URL https://doi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1080/14685240802376389 2008
-
[7]
URL https://openreview.net/forum? id=0r9mhjRv1E. Siddik, A. B., Oyen, D., Most, A., Kucer, M., and Biswas, A. SPUS: A Lightweight and Parameter-Efficient Foun- dation Model for PDEs, 2025. URL https://arxiv. org/abs/2510.01370. Song, Z., Yuan, J., and Yang, H. FMint: Bridging Human Designed and Data Pretrained Models for Differential Equation Foundation M...
-
[8]
URL https://openreview.net/forum? id=GLDMCwdhTK. Ye, Z., Liu, Z., Wu, B., Jiang, H., Chen, L., Zhang, M., Huang, X., Meng, Q., Zou, J., Liu, H., and Dong, B. PDEformer-2: A Versatile Foundation Model for Two- Dimensional Partial Differential Equations, 2025. URL https://arxiv.org/abs/2507.15409. Zhang, D., Feng, T., Xue, L., Wang, Y ., Dong, Y ., and Tang...
-
[9]
If this buffer fills up, the simulator pauses, preventing memory overflows
Transmission Queue (FIFO): The simulation server pushes completed transport samples into a finite-sized First-In- First-Out buffer. If this buffer fills up, the simulator pauses, preventing memory overflows. From this queue, data is sent to all participating training GPUs in a round-robin fashion
-
[10]
New frames are received here before being processed for the training cache
Local Staging Buffer (FIFO): Each training GPU maintains an incoming “mailbox” queue. New frames are received here before being processed for the training cache
-
[11]
Background threads continuously replenish this cache
Consumer Cache (MFU): On the training side, frames are moved from the staging buffer into a larger local cache governed by a Most-Frequently-Used (MFU) replacement policy. Background threads continuously replenish this cache. The training loop samples batches from the Consumer Cache rather than the stream directly. This decouples the training step time fr...
-
[12]
The corrupted trajectory is immediately discarded
-
[13]
The specific simulator instance responsible is reset with a new random seed and parameters
-
[14]
A global error counter is incremented. If the error counter exceeds a tolerance threshold (set to 10 events per training run), the entire training process is halted to allow for debugging. This ensures that the model is never exposed to corrupted gradients. Multi-Node and Distributed Training Our default configuration utilizes a single node with four GPUs...
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.