From Weight Perturbation to Feature Attribution for Explaining Fully Connected Neural Networks
Pith reviewed 2026-05-19 16:01 UTC · model grok-4.3
The pith
Perturbing weights attached to input features produces reliable attributions that avoid bias and out-of-distribution problems in occlusion methods for fully connected neural networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
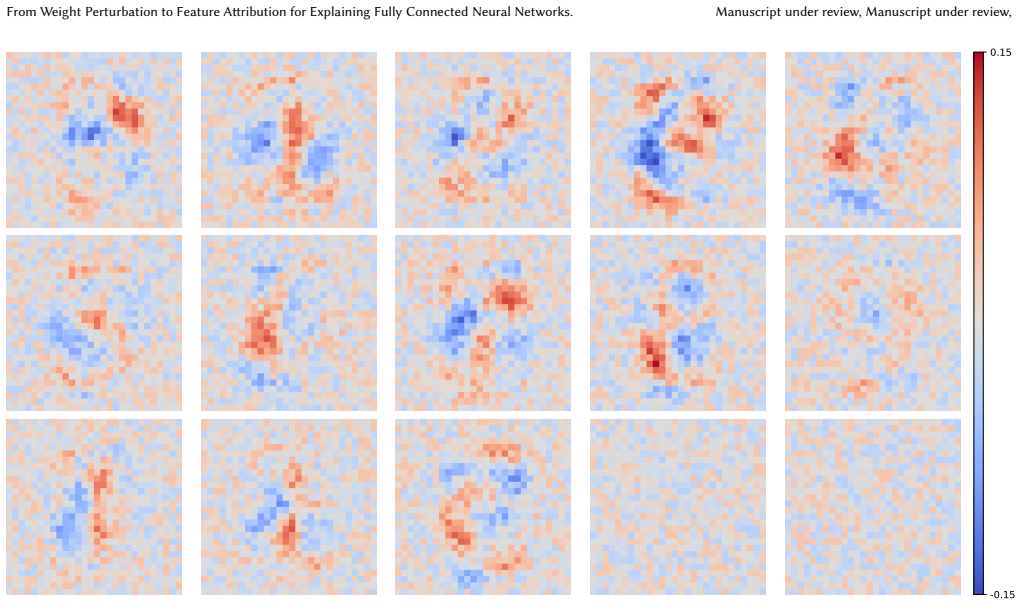
Applying perturbation to the features' attached weights instead of their values leads to novel attribution methods XWP and XWP_c that mitigate common limitations in Occlusion techniques such as Added Bias and Out-of-Distribution data and achieve competitive performance in identifying image signals for simple DNNs on standard baseline metrics.
What carries the argument
Weight perturbation for attribution, the process of measuring a feature's importance by altering the weights connected to that feature while keeping input values fixed.
If this is right
- XWP and XWP_c can generate explanations for fully connected network predictions without the bias that value occlusion often adds.
- The methods reach performance levels comparable to leading attribution techniques on standard image signal detection metrics.
- Simple rule-based perturbation of weights offers one path to more stable interpretability in basic deep networks.
- This approach contributes a framework for reducing long-standing weaknesses in occlusion-based explainability.
Where Pith is reading between the lines
- The same weight perturbation idea could be tried on other model types where changing input values risks creating unrealistic samples.
- It may reduce reliance on separate validation steps that current attribution methods often need.
- Similar weight-focused changes might help explain decisions in models beyond image tasks.
Load-bearing premise
That perturbing weights attached to features produces a valid and unbiased measure of feature importance that directly addresses the added bias and out-of-distribution problems of value perturbation without introducing new artifacts or requiring additional validation on the specific network architecture.
What would settle it
A direct comparison on image classification tasks with fully connected networks where XWP attributions fail to highlight the same input regions that human-labeled ground truth or multiple other attribution methods consistently identify.
Figures





read the original abstract
Fully Connected Neural Networks (FCNNs) are often regarded as simple and intuitive architectures, yet they serve as the foundation for more complex models. Nonetheless, the lack of consensus on their interpretability continues to pose challenges, underscoring the enduring relevance of simpler, attribution-based approaches for understanding even the most advanced neural architectures. In this regard, we explore a novel idea for estimating feature attribution, by applying perturbation to the features' attached weights instead of their values. This method offers a fresh perspective aimed at mitigating common limitations in Occlusion techniques, such as Added Bias and Out-of-Distribution data. The application of this rule leads to the formation of a pair of novel attribution methods we call XWP and XWP_c. Founded on simple rules, our methods achieve competitive performance in identifying image signals for simple DNNs, competing with the most established attribution methods on standard baseline metrics. Our work thus contributes to the field of Explainability by introducing a robust framework that paves the way for addressing these long-standing vulnerabilities, and leads to more reliable and interpretable model explanations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that perturbing the weights attached to input features (rather than their values) in fully connected neural networks yields two new attribution methods, XWP and XWP_c, that mitigate the added-bias and out-of-distribution problems of occlusion techniques while achieving competitive performance on standard baseline metrics for identifying image signals in simple DNNs.
Significance. If the weight-perturbation approach can be shown to isolate marginal feature contributions without introducing new global-model or interaction artifacts, and if the competitive performance is confirmed by quantitative experiments with proper controls, the work would supply a simple, parameter-light alternative to value-based occlusion that could improve reliability of explanations for FCNNs and their descendants.
major comments (3)
- [Abstract] Abstract: the claim of 'competitive performance ... on standard baseline metrics' is stated without any quantitative results, error bars, or experimental-setup details, leaving the central empirical claim unsupported by verifiable evidence.
- [Method description] Description of XWP and XWP_c: no derivation (via chain rule, marginal contribution, or Shapley-style decomposition) is supplied showing that the output delta obtained by perturbing a feature's attached weight equals the marginal contribution of that feature or remains unbiased once non-linearities and downstream layers are present; the mitigation of occlusion artifacts is therefore asserted rather than demonstrated.
- [Experimental evaluation] Experimental evaluation: the absence of any reported numbers, ablation studies, or comparisons with established methods (e.g., occlusion, gradient-based) prevents assessment of whether the proposed scores actually avoid the confounding the skeptic note identifies.
minor comments (1)
- [Abstract] The subscript 'c' in XWP_c is introduced without an immediate definition of what the variant differs from the base XWP method.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that identify key areas for strengthening the manuscript. We address each major comment below and will make substantial revisions to provide the requested empirical support, derivations, and comparisons.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'competitive performance ... on standard baseline metrics' is stated without any quantitative results, error bars, or experimental-setup details, leaving the central empirical claim unsupported by verifiable evidence.
Authors: We agree that the abstract's claim requires concrete support. In the revised manuscript we will update the abstract to report specific quantitative metrics (e.g., AUC or accuracy on baseline tests) together with error bars and a concise description of the experimental protocol. revision: yes
-
Referee: [Method description] Description of XWP and XWP_c: no derivation (via chain rule, marginal contribution, or Shapley-style decomposition) is supplied showing that the output delta obtained by perturbing a feature's attached weight equals the marginal contribution of that feature or remains unbiased once non-linearities and downstream layers are present; the mitigation of occlusion artifacts is therefore asserted rather than demonstrated.
Authors: The referee correctly notes the absence of a formal derivation. We will add a dedicated subsection that derives the attribution scores from a marginal-contribution perspective and analyzes the effect of non-linear activations and subsequent layers to clarify when the weight-perturbation delta remains unbiased. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation: the absence of any reported numbers, ablation studies, or comparisons with established methods (e.g., occlusion, gradient-based) prevents assessment of whether the proposed scores actually avoid the confounding the skeptic note identifies.
Authors: We acknowledge that the current manuscript lacks the quantitative evidence needed for rigorous assessment. The revision will include tabulated numerical results, ablation studies on perturbation magnitude and choice of baseline, and head-to-head comparisons against occlusion and gradient-based methods on the same datasets and metrics. revision: yes
Circularity Check
No circularity: method defined by direct rule application, evaluated empirically
full rationale
The paper proposes XWP and XWP_c by directly defining feature attribution via weight perturbation on attached parameters rather than input values. No equations, derivations, or self-citations are presented that reduce the attribution scores to fitted parameters, prior self-referential results, or inputs by construction. Performance is assessed via standard baseline metrics on image signals for simple DNNs, making the central contribution an empirical proposal rather than a closed-loop derivation. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Perturbing weights attached to features yields a faithful attribution without introducing bias or distribution shift
Reference graph
Works this paper leans on
-
[1]
Shreyash Arya, Sukrut Rao, Moritz Böhle, and Bernt Schiele. 2024. B-cosification: Transforming Deep Neural Networks to be Inherently Interpretable. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran Associates, Inc., 62756–62786. doi:10.52202/079017-2007
-
[2]
Beyza Nur Aydoğan and Tevfik Aytekin. 2025. An in-depth analysis of KernelSHAP and SamplingSHAP: assessing robustness, error, and efficiency. Knowledge and Information Systems67 (2025), 10545 – 10579. https://api. semanticscholar.org/CorpusID:282832460
work page 2025
-
[3]
Alejandro Barredo Arrieta, Natalia Díaz-Rodríguez, Javier Del Ser, Adrien Ben- netot, Siham Tabik, Alberto Barbado, Salvador Garcia, Sergio Gil-Lopez, Daniel Molina, Richard Benjamins, Raja Chatila, and Francisco Herrera. 2020. Ex- plainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI.Information...
- [4]
-
[5]
Alexander Binder, Sebastian Bach, Gregoire Montavon, Klaus-Robert Muller, and Wojciech Samek. 2016. Layer-Wise Relevance Propagation for Deep Neural Network Architectures. InInformation Science and Applications (ICISA) 2016, Kuinam J. Kim and Nikolai Joukov (Eds.). Springer Singapore, Singapore, 913– 922
work page 2016
-
[6]
Alexander Binder, Grégoire Montavon, Sebastian Bach, Klaus-Robert Müller, and Wojciech Samek. 2016. Layer-wise Relevance Propagation for Neural Networks with Local Renormalization Layers. arXiv:1604.00825 [cs.CV] https://arxiv.org/ abs/1604.00825
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[7]
Ho Chan and Eduardo Veas. 2024. Importance Estimate of Features via analysis of their Weight and Gradient profile. (04 2024). doi:10.21203/rs.3.rs-4217886/v1
-
[8]
Aditya Chattopadhay, Anirban Sarkar, Prantik Howlader, and Vineeth N Balasub- ramanian. 2018. Grad-CAM++: Generalized Gradient-Based Visual Explanations for Deep Convolutional Networks. In2018 IEEE Winter Conference on Applications of Computer Vision (W ACV). 839–847. doi:10.1109/WACV.2018.00097
-
[9]
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova Das- Sarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah....
work page 2021
- [10]
-
[11]
Ruth C. Fong and Andrea Vedaldi. 2017. Interpretable Explanations of Black Boxes by Meaningful Perturbation. In2017 IEEE International Conference on Computer Vision (ICCV). Association for Computing Machinery, 3449–3457. doi:10.1109/ ICCV.2017.371
work page 2017
-
[12]
Atticus Geiger, Duligur Ibeling, Amir Zur, Maheep Chaudhary, Sonakshi Chauhan, Jing Huang, Aryaman Arora, Zhengxuan Wu, Noah Goodman, Christopher Potts, and Thomas Icard. 2025. Causal Abstraction: A Theoretical Foundation for Mechanistic Interpretability. arXiv:2301.04709 [cs.AI] https://arxiv.org/abs/2301. 04709
- [13]
- [14]
-
[15]
Jean Kaddour, Aengus Lynch, Qi Liu, Matt J. Kusner, and Ricardo Silva. 2022. Causal Machine Learning: A Survey and Open Problems. arXiv:2206.15475 [cs.LG] https://arxiv.org/abs/2206.15475
-
[16]
Pantelis Linardatos, Vasilis Papastefanopoulos, and Sotiris B. Kotsiantis. 2020. Explainable AI: A Review of Machine Learning Interpretability Methods.Entropy 23 (2020), 45. https://api.semanticscholar.org/CorpusID:229722844
work page 2020
-
[17]
Scott M. Lundberg and Su-In Lee. 2017. A unified approach to interpreting model predictions. InProceedings of the 31st International Conference on Neural Information Processing Systems(Long Beach, California, USA)(NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 4768–4777
work page 2017
-
[18]
Mariusz Karol Nowak and Kamil Lelowicz. 2021. Weight Perturbation as a Method for Improving Performance of Deep Neural Networks. In2021 25th International Conference on Methods and Models in Automation and Robotics (MMAR). 127–132. doi:10.1109/MMAR49549.2021.9528460
-
[19]
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. 2020. Zoom In: An Introduction to Circuits.Distill(2020). doi:10.23915/distill.00024.001 https://distill.pub/2020/circuits/zoom-in
-
[20]
Vitali Petsiuk, Abir Das, and Kate Saenko. 2018. RISE: Randomized Input Sampling for Explanation of Black-box Models. arXiv:1806.07421 [cs.CV] https://arxiv.org/ abs/1806.07421
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[21]
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2016. "Why Should I Trust You?": Explaining the Predictions of Any Classifier. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining(San Francisco, California, USA)(KDD ’16). Association for Computing Machinery, New York, NY, USA, 1135–1144. doi:10.1145/...
-
[22]
Samad, Rahim Hossain, and Khan M
Manar D. Samad, Rahim Hossain, and Khan M. Iftekharuddin. 2021. Dynamic Perturbation of Weights for Improved Data Reconstruction in Unsupervised Learning. In2021 International Joint Conference on Neural Networks (IJCNN). 1–7. doi:10.1109/IJCNN52387.2021.9533539
-
[23]
Avanti Shrikumar, Peyton Greenside, and Anshul Kundaje. 2017. Learning im- portant features through propagating activation differences. InProceedings of the 34th International Conference on Machine Learning - Volume 70(Sydney, NSW, Australia)(ICML’17). JMLR.org, 3145–3153
work page 2017
-
[24]
Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. 2013. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps.CoRRabs/1312.6034 (2013). https://api.semanticscholar.org/CorpusID: 1450294
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[25]
Pascal Sturmfels, Scott Lundberg, and Su-In Lee. 2020. Visualizing the Im- pact of Feature Attribution Baselines.Distill(2020). doi:10.23915/distill.00022 https://distill.pub/2020/attribution-baselines
-
[26]
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. 2017. Axiomatic attribution for deep networks. InProceedings of the 34th International Conference on Machine Learning - Volume 70(Sydney, NSW, Australia)(ICML’17). JMLR.org, 3319–3328
work page 2017
-
[27]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. InProceedings of the 31st International Conference on Neural Information Processing Systems(Long Beach, California, USA)(NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 6000–6010
work page 2017
-
[28]
Saurabh Vyawahare. 2024. TMNIST (Typeface MNIST). Kaggle. https://www. kaggle.com/datasets/saurabhvyawahare/tmnist-typeface-mnist
work page 2024
-
[29]
Dongxian Wu, Shu-Tao Xia, and Yisen Wang. 2020. Adversarial Weight Perturba- tion Helps Robust Generalization. InAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin (Eds.), Vol. 33. Curran Associates, Inc., 2958–2969. https://proceedings.neurips.cc/ paper_files/paper/2020/file/1ef91c212e30e14bf...
work page 2020
-
[30]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland Vollgraf. 2017.Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv:cs.LG/1708.07747 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Matthew D. Zeiler and Rob Fergus. 2014. Visualizing and Understanding Convo- lutional Networks. InComputer Vision – ECCV 2014, David Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tuytelaars (Eds.). Springer International Publishing, Cham, 818–833. 7 Manuscript under review, Manuscript under review, Lymperopoulos et al. Sample OCCL SHAP RISE IG LRP XWP XWP...
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.