On the Stability of Growth in Structural Plasticity
Pith reviewed 2026-05-19 15:34 UTC · model grok-4.3
The pith
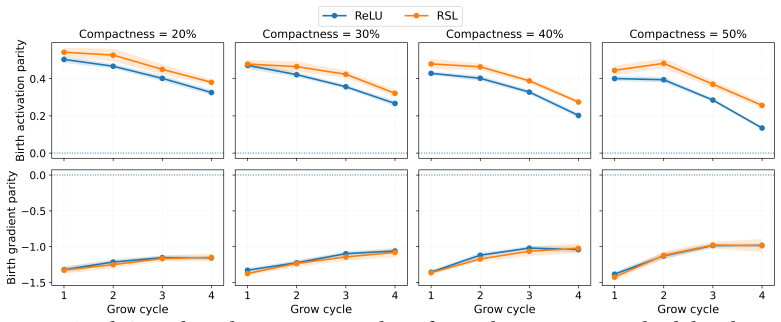
Newborn network units participate in the forward pass but receive weaker gradients than units present from the start.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Newborn units are often forward-active but backward-starved: they participate in the forward computation, yet receive much weaker gradient signal than incumbent units. This disadvantage is minor in small MLP benchmarks but becomes clear in harder image-classification settings with a convolutional trunk. Grow can achieve high final accuracy during the structural-editing procedure, while Prune is stronger when performance is averaged over the training trajectory or when the final sparse network is retrained from scratch.
What carries the argument
The insertion problem: new units are added into an already specialized optimization trajectory, producing systematically weaker back-propagated gradients than those received by units that have been present from initialization.
Load-bearing premise
By the time new units are inserted the optimization trajectory has already specialized, so their gradient signals are weaker than those of the original units.
What would settle it
Direct measurement of per-unit gradient magnitudes right after insertion across multiple runs; if new units consistently receive gradient norms comparable to incumbent units, the central claim would not hold.
Figures
















read the original abstract
Standard deep-learning pipelines usually choose the network architecture before training and keep it fixed throughout optimization. In contrast, a model can also be adapted by editing its structure during training, for example by pruning existing hidden-neuron units or growing new ones. Although growth is appealing for adaptive and continual systems, we show that it is not simply the inverse of pruning. Pruning selects among units that have participated in training from the start, whereas growth inserts new units into an already specialized optimization trajectory. We isolate this insertion problem and show that newborn units are often forward-active but backward-starved: they participate in the forward computation, yet receive much weaker gradient signal than incumbent units. This disadvantage is minor in small MLP benchmarks, but becomes clear in harder image-classification settings with a convolutional trunk. In these settings, \textsc{Grow} can achieve high final accuracy during the structural-editing procedure, while \textsc{Prune} is stronger when performance is averaged over the training trajectory or when the final sparse network is retrained from scratch. Interventions targeting optimizer state, insertion, selection, and trainability show that improving the integration of newborn units can improve adaptive performance, but does not automatically produce better final subnetworks. In continual-learning benchmarks stressing plasticity loss, \textsc{Grow} becomes competitive mainly when new units have enough time to integrate. Together, these results suggest that \textsc{Grow} should be evaluated not only as an architecture-search operator, but as a time-sensitive optimization process whose success depends on insertion stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines structural plasticity in deep networks by comparing growth (adding new units mid-training) to pruning (removing units). It argues that growth is not the inverse of pruning because new units are inserted into an already-specialized optimization trajectory, resulting in newborn units that are forward-active but backward-starved (participating in the forward pass yet receiving systematically weaker gradient signals than incumbent units). This is demonstrated through controlled experiments on MLPs and convolutional image-classification tasks, interventions targeting optimizer state/insertion/selection/trainability, distinctions between final accuracy and trajectory-averaged/retrained performance, and continual-learning settings where integration time affects competitiveness.
Significance. If the central empirical observations hold, the work usefully highlights an asymmetry in dynamic architecture methods and frames growth as a time-sensitive optimization process rather than a pure architecture-search operator. The targeted interventions and separation of final vs. averaged performance provide concrete guidance for adaptive and continual-learning systems. Credit is due for the reproducible-style interventions and the focus on plasticity loss in continual benchmarks.
major comments (2)
- [§4.2] §4.2 (gradient-signal experiments): the claim that newborn units receive 'much weaker gradient signal' is central to the insertion-problem argument, yet the manuscript does not specify the precise metric (e.g., per-unit L2 norm, cosine similarity to incumbent gradients, or layer-wise averages) nor whether any scaling or normalization is applied before comparison; without this, it is difficult to assess whether the observed difference is an artifact of initialization scale or a genuine optimization-trajectory effect.
- [Table 3] Table 3 and associated text (image-classification results): the reported advantage of Grow on final accuracy versus Prune on trajectory-averaged or retrained performance lacks error bars, number of random seeds, or statistical tests; given that the central claim rests on these performance distinctions, the absence of variability measures makes it impossible to judge whether the differences are robust or could be explained by post-hoc run selection.
minor comments (3)
- [Abstract] Abstract and §2: the phrase 'backward-starved' is used repeatedly before any quantitative definition or figure reference is given; a short parenthetical or footnote linking to the measurement protocol would improve readability.
- [§5] §5 (continual-learning experiments): the statement that 'Grow becomes competitive mainly when new units have enough time to integrate' would benefit from an explicit plot or table showing accuracy as a function of insertion timing or number of subsequent epochs.
- [§3] Notation: the distinction between 'final accuracy during the structural-editing procedure' and 'performance averaged over the training trajectory' is important but introduced without a compact symbol or equation; adding a brief definition in §3 would reduce ambiguity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript examining the asymmetry between growth and pruning in structural plasticity. We address each major comment below and outline the revisions we will make to improve clarity and reporting standards.
read point-by-point responses
-
Referee: [§4.2] §4.2 (gradient-signal experiments): the claim that newborn units receive 'much weaker gradient signal' is central to the insertion-problem argument, yet the manuscript does not specify the precise metric (e.g., per-unit L2 norm, cosine similarity to incumbent gradients, or layer-wise averages) nor whether any scaling or normalization is applied before comparison; without this, it is difficult to assess whether the observed difference is an artifact of initialization scale or a genuine optimization-trajectory effect.
Authors: We agree that the gradient metric requires explicit definition to rule out artifacts. In the experiments, gradient signal strength was quantified as the L2 norm of the gradient with respect to each unit's incoming parameters, averaged across the batch and over post-insertion training steps; no additional per-unit scaling or normalization was applied beyond the standard back-propagation and Adam optimizer state. We have revised §4.2 to state this definition verbatim, added a short paragraph explaining why the L2 norm is appropriate for comparing backward starvation, and included a supplementary check confirming that the observed gap remains after matching initialization variance. These changes directly address the concern. revision: yes
-
Referee: Table 3 and associated text (image-classification results): the reported advantage of Grow on final accuracy versus Prune on trajectory-averaged or retrained performance lacks error bars, number of random seeds, or statistical tests; given that the central claim rests on these performance distinctions, the absence of variability measures makes it impossible to judge whether the differences are robust or could be explained by post-hoc run selection.
Authors: The referee correctly identifies a reporting gap. The Table 3 results were obtained from five independent random seeds, with the reported trends consistent across all runs. In the revised manuscript we will add standard-deviation error bars to the table, explicitly state the number of seeds, and include a brief statistical note (paired t-tests on the key metrics) either in the main text or as a short supplement paragraph. This will allow readers to assess robustness directly. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper advances empirical claims about the stability of structural growth versus pruning in neural networks, supported by benchmark comparisons, interventions on optimizer state and insertion timing, and observations of gradient signals in convolutional and continual-learning settings. No derivation chain, first-principles equations, or fitted parameters are presented that reduce by construction to inputs defined within the paper itself; the central distinction between Grow and Prune rests on externally measurable performance differences rather than self-referential definitions or self-citation load-bearing arguments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Once training has progressed, the optimization trajectory has specialized such that newly inserted units receive systematically weaker gradients.
Reference graph
Works this paper leans on
-
[1]
Asadi, K., Fakoor, R., and Sabach, S. (2023). Resetting the optimizer in deep rl: An empirical study.Advances in Neural Information Processing Systems, 36:72284–72324
work page 2023
- [2]
-
[3]
Bellec, G., Kappel, D., Maass, W., and Legenstein, R. (2017). Deep rewiring: Training very sparse deep networks.arXiv preprint arXiv:1711.05136
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Cai, Z., Sener, O., and Koltun, V. (2021). Online continual learning with natural distribution shifts: An empirical study with visual data. InProceedings of the IEEE/CVF international conference on computer vision, pages 8281–8290
work page 2021
-
[5]
Chen, T., Goodfellow, I., and Shlens, J. (2016). Net2net: Accelerating learning via knowledge transfer. InICLR
work page 2016
-
[6]
Cheney, N., Schrimpf, M., and Kreiman, G. (2017). On the robustness of convolutional neural networks to internal architecture and weight perturbations.arXiv preprint arXiv:1703.08245
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
Dai, X., Yin, H., and Jha, N. K. (2019). Nest: A neural network synthesis tool based on a grow-and-prune paradigm.IEEE Transactions on Computers, 68(10):1487–1497
work page 2019
-
[8]
Sparse networks from scratch: Faster training without losing performance, 2019
Dettmers, T. and Zettlemoyer, L. (2019). Sparse networks from scratch: Faster training without losing performance.arXiv preprint arXiv:1907.04840
-
[9]
F., Lan, Q., Rahman, P., Mahmood, A
Dohare, S., Hernandez-Garcia, J. F., Lan, Q., Rahman, P., Mahmood, A. R., and Sutton, R. S. (2024). Loss of plasticity in deep continual learning.Nature, 632:768—774
work page 2024
-
[10]
Evci, U., Gale, T., Menick, J., Sampedro, P., Lorch, E., and Sohl-Dickstein, J. (2020). Rigging the lottery: Making all tickets winners. InNeurIPS
work page 2020
-
[11]
Evci, U., van Merrienboer, B., Unterthiner, T., Pedregosa, F., and Vladymyrov, M. (2022). Gradmax: Growing neural networks using gradient information. InInternational Conference on Learning Representations
work page 2022
-
[12]
PathNet: Evolution Channels Gradient Descent in Super Neural Networks
Fernando, C., Banarse, D., Blundell, C., Zwols, Y., Ha, D., Rusu, A. A., Pritzel, A., and Wierstra, D. (2017). Pathnet: Evolution channels gradient descent in super neural networks.arXiv preprint arXiv:1701.08734
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
Frankle, J. and Carbin, M. (2018). The lottery ticket hypothesis: Finding sparse, trainable neural networks.arXiv preprint arXiv:1803.03635
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Frankle, J., Dziugaite, G. K., Roy, D. M., and Carbin, M. (2019). Stabilizing the lottery ticket hypothesis.arXiv: Learning
work page 2019
-
[15]
Ghunaim, Y., Bibi, A., Alhamoud, K., Alfarra, M., Al Kader Hammoud, H. A., Prabhu, A., Torr, P. H., and Ghanem, B. (2023). Real-time evaluation in online continual learning: A new hope. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11888–11897
work page 2023
-
[16]
An Empirical Investigation of Catastrophic Forgetting in Gradient-Based Neural Networks
Goodfellow, I. J., Mirza, M., Xiao, D., Courville, A., and Bengio, Y. (2013). An empirical investigation of catastrophic forgetting in gradient-based neural networks.arXiv preprint arXiv:1312.6211. 10
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[17]
Gordon, A., Eban, E., Nachum, O., Chen, B., Wu, H., Yang, T.-J., and Choi, E. (2018). Morphnet: Fast & simple resource-constrained structure learning of deep networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1586–1595
work page 2018
-
[18]
Han, S., Mao, H., and Dally, W. J. (2015a). Deep compression: Compressing deep neural net- works with pruning, trained quantization and huffman coding.arXiv preprint arXiv:1510.00149
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Han, S., Pool, J., Tran, J., and Dally, W. (2015b). Learning both weights and connections for efficient neural network.Advances in neural information processing systems, 28
-
[20]
Kang, H., Mina, R. J. L., Madjid, S. R. H., Yoon, J., Hasegawa-Johnson, M., Hwang, S. J., and Yoo, C. D. (2022). Forget-free continual learning with winning subnetworks. In Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., and Sabato, S., editors,Proceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of...
work page 2022
-
[21]
Kingma, D. P. and Ba, J. (2014). Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[22]
Krizhevsky, A. (2009). Learning multiple layers of features from tiny images. InUniversity of Toronto Technical Report
work page 2009
- [23]
- [24]
-
[25]
Lecun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998). Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324
work page 1998
-
[26]
Li, X., Zhou, Y., Wu, T., Socher, R., and Xiong, C. (2019). Learn to grow: A continual structure learning framework for overcoming catastrophic forgetting. InInternational conference on machine learning, pages 3925–3934. PMLR
work page 2019
-
[27]
Activation Function Design Sustains Plasticity in Continual Learning
Lillo, L. and Cheney, N. (2025). Activation function design sustains plasticity in continual learning.arXiv preprint arXiv:2509.22562
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
A., Pascanu, R., and Dabney, W
Lyle, C., Zheng, Z., Nikishin, E., Pires, B. A., Pascanu, R., and Dabney, W. (2023). Understanding plasticity in neural networks. InInternational Conference on Machine Learning, pages 23190– 23211. PMLR
work page 2023
-
[29]
Mallya, A., Davis, D., and Lazebnik, S. (2018). Piggyback: Adapting a single network to multiple tasks by learning to mask weights. InProceedings of the European conference on computer vision (ECCV), pages 67–82
work page 2018
-
[30]
Mallya, A. and Lazebnik, S. (2018). Packnet: Adding multiple tasks to a single network by iterative pruning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 7765–7773
work page 2018
-
[31]
Miconi, T. (2016). Neural networks with differentiable structure.arXiv preprint arXiv:1606.06216
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[32]
Mocanu, D. C. et al. (2018). Scalable training of artificial neural networks with adaptive sparse connectivity. InAAAI. 11
work page 2018
- [33]
- [34]
-
[35]
On the Convergence of Adam and Beyond
Reddi, S. J., Kale, S., and Kumar, S. (2019). On the convergence of adam and beyond.arXiv preprint arXiv:1904.09237
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[36]
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A. C., and Fei-Fei, L. (2015). ImageNet Large Scale Visual Recognition Challenge.International Journal of Computer Vision (IJCV), 115(3):211–252
work page 2015
-
[37]
Rusu, A. A., Rabinowitz, N. C., Desjardins, G., Soyer, H., Kirkpatrick, J., Kavukcuoglu, K., Pascanu, R., and Hadsell, R. (2016). Progressive neural networks.arXiv preprint arXiv:1606.04671
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[38]
Wei, T., Wang, C., Rui, Y., and Chen, C. W. (2016). Network morphism. InProceedings of the 33rd International Conference on Machine Learning (ICML)
work page 2016
-
[39]
Wu, L., Liu, B., Stone, P., and Liu, Q. (2020). Firefly neural architecture descent: a general approach for growing neural networks.Advances in neural information processing systems, 33:22373–22383
work page 2020
-
[40]
Wu, L., Wang, D., and Liu, Q. (2019). Splitting steepest descent for growing neural architectures. Advances in neural information processing systems, 32
work page 2019
-
[41]
Xiao, H., Rasul, K., and Vollgraf, R. (2017). Fashion-mnist: a novel image dataset for bench- marking machine learning algorithms.arXiv preprint arXiv:1708.07747
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
Xiong, R., Yang, Y., He, D., Zheng, K., Zheng, S., Xing, C., Zhang, H., Lan, Y., Wang, L., and Liu, T. (2020). On layer normalization in the transformer architecture. InInternational conference on machine learning, pages 10524–10533. PMLR
work page 2020
- [43]
-
[44]
Yoon, J., Yang, E., Lee, J., and Hwang, S. J. (2017). Lifelong learning with dynamically expand- able networks.arXiv preprint arXiv:1708.01547
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
You, Y., Li, J., Reddi, S., Hseu, J., Kumar, S., Bhojanapalli, S., Song, X., Demmel, J., Keutzer, K., and Hsieh, C.-J. (2019). Large batch optimization for deep learning: Training bert in 76 minutes. arXiv preprint arXiv:1904.00962
work page internal anchor Pith review arXiv 2019
-
[46]
Yuan, X., Savarese, P., and Maire, M. (2023). Accelerated training via incrementally growing neural networks using variance transfer and learning rate adaptation.Advances in Neural Information Processing Systems, 36:16673–16692
work page 2023
- [47]
-
[48]
C., Dvornek, N., Papademetris, X., and Duncan, J
Zhuang, J., Tang, T., Ding, Y., Tatikonda, S. C., Dvornek, N., Papademetris, X., and Duncan, J. (2020). Adabelief optimizer: Adapting stepsizes by the belief in observed gradients.Advances in neural information processing systems, 33:18795–18806. 12 Submission Checklist
work page 2020
-
[49]
For all authors. . . (a) Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? [Yes] The abstract and introduction accurately reflect the paper’s contributions and scope. (b) Did you describe the limitations of your work? [Yes] We discuss limitations, including the restricted architectural setting...
work page 2022
-
[50]
If you ran experiments. . . (a) Did you use the same evaluation protocol for all methods being compared (e.g., same benchmarks, data (sub)sets, available resources, etc.)? [Yes] All compared methods use the same datasets, architectures, training budgets, evaluation checkpoints, and compactness targets unless explicitly stated. (b) Did you specify all the ...
-
[51]
With respect to the code used to obtain your results. . . (a) Did you include the code, data, and instructions needed to reproduce the main experimental results, including all dependencies (e.g., requirements.txt with explicit versions), random seeds, an instructive README with installation instructions, and execution commands (ei- ther in the supplementa...
-
[52]
If you used existing assets (e.g., code, data, models). . . (a) Did you cite the creators of used assets? [Yes] We cite the creators of all datasets, algorithms, and software assets used. (b) Did you discuss whether and how consent was obtained from people whose data you’re using/curating if the license requires it? [N/A] We use standard public benchmark ...
-
[53]
If you created/released new assets (e.g., code, data, models). . . (a) Did you mention the license of the new assets (e.g., as part of your code submission)? [Yes] The license for released code and assets is specified. (b) Did you include the new assets either in the supplemental material or as aurl(to, e.g., GitHub or Hugging Face)? [Yes] The released as...
-
[54]
If you used crowdsourcing or conducted research with human subjects. . . (a) Did you include the full text of instructions given to participants and screenshots, if appli- cable? [No] No crowdsourcing or human-subject experiments were conducted. (b) Did you describe any potential participant risks, with links to institutional review board (irb) approvals,...
-
[55]
If you included theoretical results. . . (a) Did you state the full set of assumptions of all theoretical results? [No] The paper does not present theoretical results. (b) Did you include complete proofs of all theoretical results? [No] The paper does not present theoretical results. 15 A Datasets, Benchmarks and Hyperparameters A.1 Datasets and Benchmark...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.