MaxSketch: Robust Distinct Counting in Streams via Random Projections
Pith reviewed 2026-05-19 20:04 UTC · model grok-4.3
The pith
A max-linear sketch over random Gaussian projections recovers distinct counts in noisy streams using only logarithmic memory when observations share geometric structure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce MaxSketch, a simple max-linear sketch built from random Gaussian projections, and prove that it succeeds in estimating the number of distinct latent objects. Concretely, we show that under this assumption m = O~(log n / ε²) random projections (and hence O~(log n/ε²) memory) suffice to recover the true distinct count within a (1+ε) factor.
What carries the argument
MaxSketch, the max-linear sketch that records the highest projection value of each observed point onto m random Gaussian vectors and uses the count of distinct maxima to estimate latent objects.
If this is right
- Streaming pipelines processing image or embedding streams can maintain distinct counts with memory scaling only logarithmically in the number of objects.
- The same sketch continues to work on data generated outside the original training distribution, as confirmed by the image-stream experiments.
- The memory bound removes the √n barrier that holds for arbitrary metric spaces once geometric structure is present.
- Distinct-count queries become practical subroutines inside larger representation-learning systems that already produce the required embeddings.
Where Pith is reading between the lines
- The same projection mechanism may apply to other streaming primitives such as heavy-hitter detection inside the same embedding space.
- Quantifying the minimal margin or embedding dimension needed for the geometric separation would give an explicit sample-complexity trade-off.
- Hybrid sketches could combine MaxSketch with classical hash-based methods for data that mixes exact repeats with noisy variants.
Load-bearing premise
The input observations of each latent object share enough geometric closeness that their random projections produce separable maximum values at the stated memory cost.
What would settle it
A controlled experiment on synthetic data where points are placed uniformly at random without clusters, checking whether the recovered count deviates from the true number of groups by more than (1+ε) when using only O(log n / ε²) projections.
Figures

read the original abstract
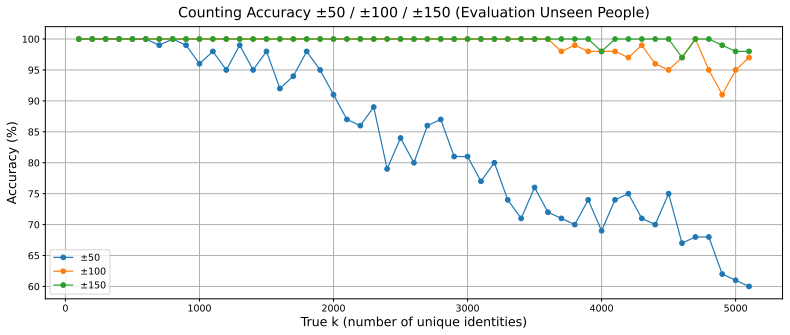
Estimating the number of distinct elements in a data stream is well understood when repeated elements are identical. In modern settings, however, observations are high-dimensional and noisy, so repeated instances of the same object are only approximately similar -- for example, different images of the same individual may vary significantly at the pixel level. Classical sketches such as HyperLogLog rely on consistent hash values for identical elements and break down in this regime. Recent work on robust distinct counting in general metric spaces achieves $\widetilde{\Theta}(\sqrt{n})$ memory, which is tight in the worst case. We show that substantially improved memory guarantees are possible under geometric structure common in learned representations. We introduce MaxSketch, a simple max-linear sketch built from random Gaussian projections, and prove that it succeeds in estimating the number of distinct latent objects. Concretely, we show that under this assumption $m = \widetilde{O} (\log n / \varepsilon^2)$ random projections (and hence $\widetilde{O} (\log n/\varepsilon^2)$ memory) suffice to recover the true distinct count within a $(1+\varepsilon)$ factor. Experiments on image streams confirm that MaxSketch accurately estimates distinct counts and generalizes beyond the training regime. Our results bridge classical streaming algorithms and modern representation learning, showing how geometric structure can fundamentally reduce the complexity of distinct counting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MaxSketch, a max-linear sketch constructed from random Gaussian projections, for estimating the number of distinct latent objects in high-dimensional noisy data streams. Under the assumption of geometric structure common in learned representations, it claims that m = O~(log n / ε²) projections (hence the same memory) suffice to recover the true distinct count within a (1+ε) factor, improving on the worst-case Θ(√n) memory of prior metric-space methods. Experiments on image streams are reported to confirm accuracy and generalization.
Significance. If the central memory bound holds under the stated geometric assumption, the result is significant: it shows how representation-learning structure can reduce distinct-counting complexity from √n to polylog(n), bridging classical streaming algorithms with modern ML pipelines. The provision of confirming experiments on real image data and the parameter-free character of the claimed bound (once the geometric assumption is granted) are strengths.
major comments (2)
- [Main theorem / proof of the memory bound] Main theorem (the O~(log n / ε²) bound): the proof sketch relies on each new distinct embedding producing a strictly larger max-projection value with high probability. This requires a minimum separation δ (angular or Euclidean) between any two distinct latent vectors that is independent of n. If δ = o(1) and shrinks with the number of distinct items k ≤ n, the per-projection success probability drops and a union bound over Θ(k) items forces an extra log k or 1/δ² factor into m, contradicting the stated bound. The manuscript must explicitly state the dependence of δ on n (or prove δ = Ω(1) under the geometric assumption).
- [Proof section (concentration / union-bound argument)] Concentration analysis for the max operator: the argument that m = O~(log n / ε²) suffices for (1+ε) approximation appears to use a per-projection failure probability that is independent of k. Without an explicit lower bound on the probability that a new object exceeds the current max (which itself depends on δ), the overall success probability may fall below 1-1/poly(n) once k grows with n.
minor comments (2)
- [Introduction / assumption statement] Clarify the precise definition of the geometric assumption (e.g., minimum angle or distance) and state whether it is assumed to hold with high probability or deterministically.
- [Experiments] In the experimental section, report the exact values of m used relative to the theoretical bound and include ablation on projection dimension versus observed error.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments. The feedback has helped us identify areas where the assumptions and proof details need to be made more explicit. We address each major comment below and plan to incorporate revisions to clarify the geometric assumption and strengthen the analysis.
read point-by-point responses
-
Referee: [Main theorem / proof of the memory bound] Main theorem (the O~(log n / ε²) bound): the proof sketch relies on each new distinct embedding producing a strictly larger max-projection value with high probability. This requires a minimum separation δ (angular or Euclidean) between any two distinct latent vectors that is independent of n. If δ = o(1) and shrinks with the number of distinct items k ≤ n, the per-projection success probability drops and a union bound over Θ(k) items forces an extra log k or 1/δ² factor into m, contradicting the stated bound. The manuscript must explicitly state the dependence of δ on n (or prove δ = Ω(1) under the geometric assumption).
Authors: We agree with the referee that the dependence of the minimum separation δ must be stated explicitly. Under the geometric structure assumption for learned representations, we posit that distinct latent vectors are separated by a constant angular distance δ = Ω(1), which is independent of n and k. This is a standard assumption in representation learning, where embeddings of different objects are designed to be well-separated. With this, the probability that a new projection exceeds the current max is bounded below by a positive constant depending only on δ and the Gaussian projection. Consequently, the union bound over k items requires only an additional O(log k) factor, which is absorbed into the Õ notation since k ≤ n. We will revise the manuscript to explicitly state this assumption on δ and include a brief justification based on properties of learned embeddings. revision: yes
-
Referee: [Proof section (concentration / union-bound argument)] Concentration analysis for the max operator: the argument that m = O~(log n / ε²) suffices for (1+ε) approximation appears to use a per-projection failure probability that is independent of k. Without an explicit lower bound on the probability that a new object exceeds the current max (which itself depends on δ), the overall success probability may fall below 1-1/poly(n) once k grows with n.
Authors: We thank the referee for this observation. To address this, we will expand the proof to derive an explicit lower bound on the success probability p for a new distinct item to update the max, which is p ≥ c(δ) > 0 when δ = Ω(1). Then, using standard Chernoff bounds or similar concentration inequalities for the number of updates, with m = O~(log n / ε²) we ensure that the estimated count is within (1+ε) with high probability. The failure probability per item is exponentially small in m, allowing the union bound to succeed. We will include these details in the revised proof section. revision: yes
Circularity Check
No circularity; derivation relies on independent probabilistic analysis under stated geometric assumption
full rationale
The paper introduces MaxSketch as a max-linear sketch over random Gaussian projections and derives the m = O~(log n / ε²) memory bound from standard concentration properties of Gaussians combined with the external geometric structure assumption on latent embeddings. No step reduces the claimed bound to a fitted parameter, self-definition, or load-bearing self-citation chain; the analysis is presented as following from first-principles random projection arguments rather than renaming or smuggling prior results by the same authors. The central claim remains independent of the target distinct-count output and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Observations arise from a small number of latent objects whose representations exhibit geometric structure that random projections can exploit for distinct counting.
Reference graph
Works this paper leans on
-
[1]
Stéphane Boucheron, Gábor Lugosi, and Olivier Bousquet. Concentration inequalities. In Summer school on machine learning, pages 208–240. Springer, 2003
work page 2003
-
[2]
Streaming algorithms for robust distinct elements
Di Chen and Qin Zhang. Streaming algorithms for robust distinct elements. InProceedings of the 2016 International Conference on Management of Data, pages 1433–1447, 2016
work page 2016
-
[3]
Distinct sampling on streaming data with near-duplicates
Jiecao Chen and Qin Zhang. Distinct sampling on streaming data with near-duplicates. In Proceedings of the 37th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems, pages 369–382, 2018
work page 2018
-
[4]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PmLR, 2020
work page 2020
-
[5]
Loglog counting of large cardinalities
Marianne Durand and Philippe Flajolet. Loglog counting of large cardinalities. InEuropean Symposium on Algorithms, pages 605–617. Springer, 2003
work page 2003
-
[6]
Philippe Flajolet, Éric Fusy, Olivier Gandouet, and Frédéric Meunier. Hyperloglog: the analysis of a near-optimal cardinality estimation algorithm.Discrete mathematics & theoretical computer science, (Proceedings), 2007
work page 2007
-
[7]
Philippe Flajolet and G Nigel Martin. Probabilistic counting algorithms for data base applica- tions.Journal of computer and system sciences, 31(2):182–209, 1985
work page 1985
-
[8]
Cnn-based density estimation and crowd counting: A survey.arXiv preprint arXiv:2003.12783, 2020
Guangshuai Gao, Junyu Gao, Qingjie Liu, Qi Wang, and Yunhong Wang. Cnn-based density estimation and crowd counting: A survey.arXiv preprint arXiv:2003.12783, 2020
-
[9]
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020
work page 2020
-
[10]
XY Han, Vardan Papyan, and David L Donoho. Neural collapse under mse loss: Proximity to and dynamics on the central path.arXiv preprint arXiv:2106.02073, 2021
-
[11]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020
work page 2020
-
[12]
Jingu Heo and Marios Savvides. Face recognition across pose using view based active appear- ance models (vbaams) on cmu multi-pie dataset. InInternational Conference on Computer Vision Systems, pages 527–535. Springer, 2008
work page 2008
-
[13]
Stefan Heule, Marc Nunkesser, and Alexander Hall. Hyperloglog in practice: Algorithmic engineering of a state of the art cardinality estimation algorithm. InProceedings of the 16th International Conference on Extending Database Technology, pages 683–692, 2013
work page 2013
-
[14]
Long short-term memory.Neural computation, 9(8):1735–1780, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural computation, 9(8):1735–1780, 1997
work page 1997
-
[15]
Labeled faces in the wild: A database forstudying face recognition in unconstrained environments
Gary B Huang, Marwan Mattar, Tamara Berg, and Eric Learned-Miller. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. InWorkshop on faces in’Real-Life’Images: detection, alignment, and recognition, 2008
work page 2008
-
[16]
Approximate nearest neighbors: towards removing the curse of dimensionality
Piotr Indyk and Rajeev Motwani. Approximate nearest neighbors: towards removing the curse of dimensionality. InProceedings of the thirtieth annual ACM symposium on Theory of computing, pages 604–613, 1998
work page 1998
-
[17]
Locality-preserving hashing in multidimensional spaces
Piotr Indyk, Rajeev Motwani, Prabhakar Raghavan, and Santosh Vempala. Locality-preserving hashing in multidimensional spaces. InProceedings of the twenty-ninth annual ACM symposium on Theory of computing, pages 618–625, 1997. 10
work page 1997
-
[18]
An optimal algorithm for the dis- tinct elements problem
Daniel M Kane, Jelani Nelson, and David P Woodruff. An optimal algorithm for the dis- tinct elements problem. InProceedings of the twenty-ninth ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems, pages 41–52, 2010
work page 2010
-
[19]
Ryan Kortvelesy, Steven Morad, and Amanda Prorok. Generalised f-mean aggregation for graph neural networks.Advances in Neural Information Processing Systems, 36:34439–34450, 2023
work page 2023
-
[20]
Michel Ledoux and Michel Talagrand.Probability in Banach Spaces: isoperimetry and processes, volume 23. Springer, 1991
work page 1991
-
[21]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. InProceedings of the IEEE international conference on computer vision, pages 3730–3738, 2015
work page 2015
-
[22]
Vardan Papyan, XY Han, and David L Donoho. Prevalence of neural collapse during the terminal phase of deep learning training.Proceedings of the National Academy of Sciences, 117(40):24652–24663, 2020
work page 2020
-
[23]
Learning aggregation functions.arXiv preprint arXiv:2012.08482, 2020
Giovanni Pellegrini, Alessandro Tibo, Paolo Frasconi, Andrea Passerini, and Manfred Jaeger. Learning aggregation functions.arXiv preprint arXiv:2012.08482, 2020
-
[24]
Sefik Serengil and Alper Özpınar. A benchmark of facial recognition pipelines and co-usability performances of modules.Bili¸ sim Teknolojileri Dergisi, 17(2):95–107, 2024
work page 2024
-
[25]
Cambridge university press, 2014
Shai Shalev-Shwartz and Shai Ben-David.Understanding machine learning: From theory to algorithms. Cambridge university press, 2014
work page 2014
-
[26]
The one-sided barrier problem for gaussian noise.Bell System Technical Journal, 41(2):463–501, 1962
David Slepian. The one-sided barrier problem for gaussian noise.Bell System Technical Journal, 41(2):463–501, 1962
work page 1962
-
[27]
On deep set learning and the choice of aggregations
Maximilian Soelch, Adnan Akhundov, Patrick van der Smagt, and Justin Bayer. On deep set learning and the choice of aggregations. InInternational Conference on Artificial Neural Networks, pages 444–457. Springer, 2019
work page 2019
-
[28]
On the limitations of representing functions on sets
Edward Wagstaff, Fabian Fuchs, Martin Engelcke, Ingmar Posner, and Michael A Osborne. On the limitations of representing functions on sets. InInternational conference on machine learning, pages 6487–6494. PMLR, 2019
work page 2019
-
[29]
Deep sets.Advances in neural information processing systems, 30, 2017
Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabas Poczos, Russ R Salakhutdinov, and Alexander J Smola. Deep sets.Advances in neural information processing systems, 30, 2017
work page 2017
-
[30]
Qin Zhang. Robust statistical analysis on streaming data with near-duplicates in general metric spaces.Proceedings of the ACM on Management of Data, 3(2):1–25, 2025
work page 2025
-
[31]
Jinxin Zhou, Xiao Li, Tianyu Ding, Chong You, Qing Qu, and Zhihui Zhu. On the optimization landscape of neural collapse under mse loss: Global optimality with unconstrained features. In International Conference on Machine Learning, pages 27179–27202. PMLR, 2022
work page 2022
-
[32]
Zhihui Zhu, Tianyu Ding, Jinxin Zhou, Xiao Li, Chong You, Jeremias Sulam, and Qing Qu. A geometric analysis of neural collapse with unconstrained features.Advances in Neural Information Processing Systems, 34:29820–29834, 2021. 11 A Appendix: Extended Related Work A.1 Classical Sketching and Cardinality Estimation The problem of estimating the number of d...
work page 2021
-
[33]
is a survey about direct count regression in images (e.g., counting people in a crowd). These methods differ fundamentally from our work: they predict total counts in a single image, not distinct elements in a stream. No theoretical guarantees or handling of weak supervision. A.5 Permutation-invariant models and max aggregation. In deep learning, permutat...
-
[34]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.