IO-SVD: Input-Output Whitened SVD for Adaptive-Rank LLM Compression
Pith reviewed 2026-05-20 21:10 UTC · model grok-4.3
The pith
IO-SVD compresses LLMs by whitening both input activations and output prediction sensitivity to limit accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
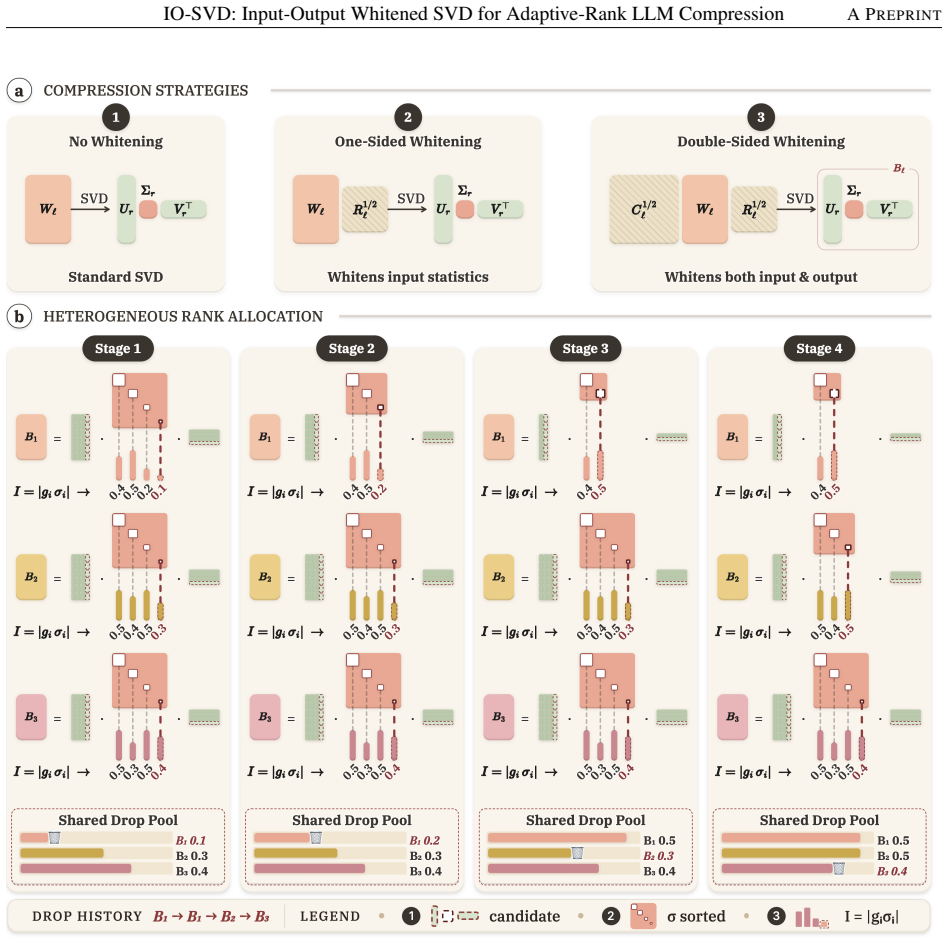
IO-SVD forms a KL-aware double-sided whitening space for model weights. Using a second-order expansion of the KL loss over the top-K token probabilities, it constructs an output-side metric that captures predictive sensitivity, while input whitening captures activation statistics. It further introduces an efficient heterogeneous rank-allocation strategy that scores whitened singular components using first-order calibration loss estimates and prunes the least sensitive components under a global budget. The same sensitivity estimates also guide loss-aware remapping when combining the low-rank factors with 8-bit quantization.
What carries the argument
The KL-aware double-sided whitening space that combines input activation statistics with an output metric derived from second-order KL expansion over top token probabilities.
If this is right
- Models retain higher task performance at the same compression ratio compared with input-only whitening.
- Inference speed increases because the resulting low-rank matrices require fewer operations during forward passes.
- Hybrid low-rank plus quantization achieves better quality by using the loss estimates to decide which factors to quantize to 8 bits.
- The same construction applies to both pure language models and vision-language models with only minor changes to the calibration data.
Where Pith is reading between the lines
- The whitening construction could be tested with other divergence measures or with full-sequence losses instead of top-K tokens.
- The global budget for rank allocation might be replaced by per-layer hardware constraints to target specific latency targets.
- Sensitivity scores computed once could be reused to guide further compression steps such as pruning or distillation.
Load-bearing premise
The second-order expansion of the KL loss over the top-K token probabilities accurately captures predictive sensitivity for the output-side metric.
What would settle it
Apply the chosen ranks and factors to a held-out calibration set, then measure the actual change in KL divergence or downstream accuracy and check whether it matches the first-order and second-order estimates used to select the components.
Figures



read the original abstract
Large language models deliver strong performance across language and reasoning tasks, but their storage and compute costs remain major barriers to deployment in resource-constrained and latency-sensitive settings. SVD-based post-training compression offers a hardware-agnostic way to reduce model size and improve inference efficiency through low-rank factorization. However, existing methods often rely on input-only whitening spaces, homogeneous rank allocation, or loss-agnostic allocation heuristics, limiting their ability to preserve model quality under aggressive compression. We propose Input-Output Whitened SVD (IO-SVD), a post-training compression method that forms a KL-aware double-sided whitening space for model weights. Using a second-order expansion of the KL loss over the top-K token probabilities, IO-SVD constructs an output-side metric that captures predictive sensitivity, while input whitening captures activation statistics. We further introduce an efficient heterogeneous rank-allocation strategy that scores whitened singular components using first-order calibration loss estimates and prunes the least sensitive components under a global budget. Inspired by prior work that combines SVD truncation with quantization, we improve hybrid SVD-quantization compression through loss-aware remapping, which selects low-rank factor rows for 8-bit quantization based on the predicted loss change incurred by quantizing them. Extensive experiments across diverse LLM and VLM families, and inference-time analysis shows that IO-SVD compresses LLMs with minimal performance degradation while delivering practical inference speedups. Code is available at https://github.com/mint-vu/IO-SVD.git
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IO-SVD, a post-training SVD-based compression technique for LLMs and VLMs. It constructs a double-sided whitening space by combining input-side activation statistics with an output-side metric derived from a second-order Taylor expansion of the KL divergence over top-K token probabilities. This metric guides heterogeneous rank allocation via first-order calibration loss estimates under a global budget, and the method is extended to loss-aware remapping for hybrid SVD-quantization. Experiments across model families report minimal degradation alongside inference speedups, with code released.
Significance. If the core approximations and empirical results hold, IO-SVD would offer a hardware-agnostic, loss-aware approach to adaptive-rank compression that improves upon input-only or homogeneous baselines. The public code and cross-family evaluation strengthen reproducibility and practical utility for deployment.
major comments (2)
- [IO-SVD construction] IO-SVD construction section: the second-order expansion of KL divergence over top-K probabilities is used to define the output-side whitening metric and sensitivity scores for rank allocation. No explicit bound or empirical check is provided showing that higher-order terms remain negligible under the target compression ratios, where large singular-value truncation can produce non-local output shifts. This approximation is load-bearing for the central claim of minimal degradation.
- [rank allocation] Heterogeneous rank-allocation paragraph: first-order calibration loss estimates are computed in the whitened space to prune components. If these estimates reuse the same calibration data or whitening transform that defines the metric, the procedure risks circularity; an explicit statement of data separation or a reduction showing the estimates are independent of the fitted parameters is needed to support the allocation strategy.
minor comments (2)
- [Abstract] Abstract: the phrase 'minimal performance degradation' is repeated without quantitative qualifiers; adding a brief range of reported perplexity or accuracy drops would improve precision.
- Notation: the input and output whitening matrices are introduced without an explicit equation linking them to the final low-rank factors; a single displayed equation would clarify the double-sided construction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the IO-SVD method, particularly regarding the validity of the second-order KL approximation and the independence of the rank-allocation estimates. We address each major comment below and will revise the manuscript to incorporate additional validation and clarifications.
read point-by-point responses
-
Referee: [IO-SVD construction] IO-SVD construction section: the second-order expansion of KL divergence over top-K probabilities is used to define the output-side whitening metric and sensitivity scores for rank allocation. No explicit bound or empirical check is provided showing that higher-order terms remain negligible under the target compression ratios, where large singular-value truncation can produce non-local output shifts. This approximation is load-bearing for the central claim of minimal degradation.
Authors: We acknowledge the importance of validating the second-order Taylor expansion of the KL divergence. In the revised manuscript, we will add an empirical section that compares the approximated output-side metric against the exact KL divergence computed on a held-out calibration set for compression ratios ranging from 2x to 4x. We will also include a brief analysis referencing approximation bounds from loss landscape literature to discuss when higher-order terms remain small, thereby supporting the claim of minimal degradation under the evaluated settings. revision: yes
-
Referee: [rank allocation] Heterogeneous rank-allocation paragraph: first-order calibration loss estimates are computed in the whitened space to prune components. If these estimates reuse the same calibration data or whitening transform that defines the metric, the procedure risks circularity; an explicit statement of data separation or a reduction showing the estimates are independent of the fitted parameters is needed to support the allocation strategy.
Authors: We agree that explicit separation is necessary to avoid any appearance of circularity. The input whitening transform is computed solely from activation statistics on a first calibration subset, while the first-order loss estimates for heterogeneous rank allocation are performed on a disjoint second calibration subset that does not influence the whitening matrix. In the revision, we will add an explicit statement of this data separation protocol along with a short empirical check confirming that the sensitivity scores remain stable when the whitening transform is held fixed from the first subset. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper constructs the output-side metric via an explicit second-order Taylor expansion of KL divergence over top-K probabilities (abstract and IO-SVD construction), which is an independent approximation rather than a self-definition or fitted input renamed as prediction. Heterogeneous rank allocation scores components using first-order calibration loss estimates on separate calibration data, a standard post-training technique that does not reduce by construction to the whitening space or target performance metrics. No load-bearing self-citations, uniqueness theorems imported from authors, or ansatzes smuggled via prior work are present in the core steps; the hybrid SVD-quantization remapping similarly relies on predicted loss change computed from the same expansion without circular re-use of fitted values. The derivation remains self-contained against external benchmarks and does not equate outputs to inputs by definition.
Axiom & Free-Parameter Ledger
free parameters (1)
- global rank budget
axioms (1)
- domain assumption Second-order Taylor expansion of KL divergence over top-K token probabilities approximates output sensitivity
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Using a second-order expansion of the KL loss over the top-K token probabilities, IO-SVD constructs an output-side metric... ΔJℓ ≈ ½‖Cℓ^{1/2}(Wℓ − Ŵℓ)Rℓ^{1/2}‖_F² (abstract, §3.1, Eq. 4)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_high_calibrated_iff unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
KL(pt ∥ softmax(zt + δzt)) = ½ δz_t^T H_t δz_t + O(‖δz‖³), H_t = Diag(pt) − pt pt^T (Eq. 2)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Zero sum svd: Balancing loss sensitivity for low rank llm compression, 2026
Ali Abbasi, Chayne Thrash, Haoran Qin, Shansita Sharma, Sepehr Seifi, and Soheil Kolouri. Zero sum svd: Balancing loss sensitivity for low rank llm compression, 2026. URLhttps://arxiv.org/abs/2602.02848
-
[2]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[3]
MathQA: Towards interpretable math word problem solving with operation-based formalisms
Aida Amini, Saadia Gabriel, Shanchuan Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. MathQA: Towards interpretable math word problem solving with operation-based formalisms. In Jill Burstein, Christy Doran, and Thamar Solorio, editors,Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Li...
-
[4]
PIQA: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. PIQA: Reasoning about physical commonsense in natural language. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 7432–7439, 2020. doi: 10.1609/aaai.v34i05.6239
-
[5]
QuIP: 2-bit quantization of large language models with guarantees
Jerry Chee, Yaohui Cai, V olodymyr Kuleshov, and Christopher De Sa. QuIP: 2-bit quantization of large language models with guarantees. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=xrk9g5vcXR
work page 2023
-
[6]
Viktoriia Chekalina, Daniil Moskovskiy, Daria Cherniuk, Maxim Kurkin, Andrey Kuznetsov, and Evgeny Frolov. Generalized fisher-weighted svd: Scalable kronecker-factored fisher approximation for compressing large language models, 2025. URLhttps://arxiv.org/abs/2505.17974
-
[7]
Hongrong Cheng, Miao Zhang, and Javen Qinfeng Shi. A survey on deep neural network pruning: Taxonomy, comparison, analysis, and recommendations.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10558–10578, 2024
work page 2024
-
[8]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018. URL https: //arxiv.org/abs/1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
Llm.int8(): 8-bit matrix multiplication for transformers at scale
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Llm.int8(): 8-bit matrix multiplication for transformers at scale. InProceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY , USA, 2022. Curran Associates Inc. ISBN 9781713871088
work page 2022
-
[10]
The approximation of one matrix by another of lower rank.Psychometrika, 1(3): 211–218, 1936
Carl Eckart and Gale Young. The approximation of one matrix by another of lower rank.Psychometrika, 1(3): 211–218, 1936
work page 1936
-
[11]
Sparsegpt: massive language models can be accurately pruned in one-shot
Elias Frantar and Dan Alistarh. Sparsegpt: massive language models can be accurately pruned in one-shot. In Proceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
work page 2023
-
[12]
Optimal brain compression: a framework for accurate post- training quantization and pruning
Elias Frantar, Sidak Pal Singh, and Dan Alistarh. Optimal brain compression: a framework for accurate post- training quantization and pruning. InProceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY , USA, 2022. Curran Associates Inc. ISBN 9781713871088
work page 2022
-
[13]
OPTQ: Accurate quantization for generative pre-trained transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. OPTQ: Accurate quantization for generative pre-trained transformers. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=tcbBPnfwxS
work page 2023
-
[14]
Marlin: Mixed-precision auto- regressive parallel inference on large language models
Elias Frantar, Roberto L Castro, Jiale Chen, Torsten Hoefler, and Dan Alistarh. Marlin: Mixed-precision auto- regressive parallel inference on large language models. InProceedings of the 30th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, pages 239–251, 2025
work page 2025
-
[15]
Minillm: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: Knowledge distillation of large language models. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[16]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[17]
Language model compression with weighted low-rank factorization
Yen-Chang Hsu, Ting Hua, Sungen Chang, Qian Lou, Yilin Shen, and Hongxia Jin. Language model compression with weighted low-rank factorization. InInternational Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=uPv9Y3gmAI5
work page 2022
-
[18]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Represen- tations, 2022. URLhttps://openreview.net/forum?id=nZeVKeeFYf9. 10 IO-SVD: Input-Output Whitened SVD for Adaptive-Rank LLM CompressionA PREPRINT
work page 2022
-
[19]
Seed-bench: Benchmarking multimodal large language models
Bohao Li, Yuying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan. Seed-bench: Benchmarking multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13299–13308, 2024
work page 2024
-
[20]
Yuhang Li, Donghyun Lee, Ruokai Yin, and Priyadarshini Panda. Optimal brain decomposition for accurate llm low-rank approximation.arXiv preprint arXiv:2604.00821, 2026
-
[21]
Yujun Lin, Haotian Tang, Shang Yang, Zhekai Zhang, Guangxuan Xiao, Chuang Gan, and Song Han. Qserve: W4a8kv4 quantization and system co-design for efficient llm serving.arXiv preprint arXiv:2405.04532, 2024
-
[22]
Learn to explain: Multimodal reasoning via thought chains for science question answering
Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. InThe 36th Conference on Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[23]
LLM-Pruner: On the structural pruning of large language models
Xinyin Ma, Gongfan Fang, and Xinchao Wang. LLM-Pruner: On the structural pruning of large language models. Advances in Neural Information Processing Systems, 36:21702–21720, 2023
work page 2023
-
[24]
Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz
Mitchell P. Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. Building a large annotated corpus of English: The Penn Treebank.Computational Linguistics, 19(2):313–330, 1993. URL https://aclanthology. org/J93-2004/
work page 1993
-
[25]
Pointer sentinel mixture models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. In International Conference on Learning Representations, 2017. URL https://openreview.net/forum?id= Byj72udxe
work page 2017
-
[26]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors,Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2381–2391, Brussels, Belgium, O...
-
[27]
Leon Mirsky. Symmetric gauge functions and unitarily invariant norms.The Quarterly Journal of Mathematics, 11(1):50–59, 1960
work page 1960
-
[28]
Ctpd: Cross tokenizer preference distillation.arXiv preprint arXiv:2601.11865, 2026
Truong Nguyen, Phi Van Dat, Ngan Nguyen, Linh Ngo Van, Trung Le, and Thanh Hong Nguyen. Ctpd: Cross tokenizer preference distillation.arXiv preprint arXiv:2601.11865, 2026
-
[29]
Gunho Park, Baeseong Park, Minsub Kim, Sungjae Lee, Jeonghoon Kim, Beomseok Kwon, Se Jung Kwon, Byeongwook Kim, Youngjoo Lee, and Dongsoo Lee. Lut-gemm: Quantized matrix multiplication based on luts for efficient inference in large-scale generative language models.arXiv preprint arXiv:2206.09557, 2022
-
[30]
Dobi-SVD: Differentiable SVD for LLM compression and some new perspectives
Wang Qinsi, Jinghan Ke, Masayoshi Tomizuka, Kurt Keutzer, and Chenfeng Xu. Dobi-SVD: Differentiable SVD for LLM compression and some new perspectives. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=kws76i5XB8
work page 2025
-
[31]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.J. Mach. Learn. Res., 21(1), January 2020. ISSN 1532-4435
work page 2020
-
[32]
Jun Rao, Xv Meng, Liang Ding, Shuhan Qi, Xuebo Liu, Min Zhang, and Dacheng Tao. Parameter-efficient and student-friendly knowledge distillation.IEEE Transactions on Multimedia, 26:4230–4241, 2023
work page 2023
-
[33]
Winogrande: an adversarial winograd schema challenge at scale.Commun
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: an adversarial winograd schema challenge at scale.Commun. ACM, 64(9):99–106, August 2021. ISSN 0001-0782. doi: 10.1145/3474381. URLhttps://doi.org/10.1145/3474381
-
[34]
Omniquant: Omnidirectionally calibrated quantization for large language models
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. Omniquant: Omnidirectionally calibrated quantization for large language models. InThe Twelfth International Conference on Learning Representations
-
[35]
Overcoming vocabulary mismatch: V ocabulary-agnostic teacher guided language modeling
Haebin Shin, Lei Ji, Xiao Liu, and Yeyun Gong. Overcoming vocabulary mismatch: V ocabulary-agnostic teacher guided language modeling. InForty-second International Conference on Machine Learning
-
[36]
A simple and effective pruning approach for large language models
Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter. A simple and effective pruning approach for large language models. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=PxoFut3dWW
work page 2024
-
[37]
Quip#: even better llm quantization with hadamard incoherence and lattice codebooks
Albert Tseng, Jerry Chee, Qingyao Sun, V olodymyr Kuleshov, and Christopher De Sa. Quip#: even better llm quantization with hadamard incoherence and lattice codebooks. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024. 11 IO-SVD: Input-Output Whitened SVD for Adaptive-Rank LLM CompressionA PREPRINT
work page 2024
-
[38]
Model-preserving adaptive rounding, 2025
Albert Tseng, Zhaofeng Sun, and Christopher De Sa. Model-preserving adaptive rounding, 2025. URL https: //arxiv.org/abs/2505.22988
-
[39]
Haiyu Wang, Yutong Wang, Jack Jiang, and Sai Qian Zhang. Wsvd: Weighted low-rank approximation for fast and efficient execution of low-precision vision-language models. InThe Fourteenth International Conference on Learning Representations,
-
[40]
Shaowen Wang, Linxi Yu, and Jian Li. Lora-ga: Low-rank adaptation with gradient approximation.Advances in Neural Information Processing Systems, 37:54905–54931, 2024
work page 2024
-
[41]
Large language models help humans verify truthfulness – except when they are convincingly wrong
Xin Wang, Samiul Alam, Zhongwei Wan, Hui Shen, and Mi Zhang. SVD-LLM v2: Optimizing singular value truncation for large language model compression. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors, Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Vol...
-
[42]
SVD-LLM: Truncation-aware singular value decomposition for large language model compression
Xin Wang, Yu Zheng, Zhongwei Wan, and Mi Zhang. SVD-LLM: Truncation-aware singular value decomposition for large language model compression. InThe Thirteenth International Conference on Learning Representations,
-
[43]
URLhttps://openreview.net/forum?id=LNYIUouhdt
-
[44]
Yutong Wang, Haiyu Wang, and Sai Qian Zhang. Qsvd: Efficient low-rank approximation for unified query-key- value weight compression in low-precision vision-language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
-
[45]
Smoothquant: accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: accurate and efficient post-training quantization for large language models. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
work page 2023
-
[46]
ASVD: Activation-aware Singular Value Decomposition for Compressing Large Language Models
Zhihang Yuan, Yuzhang Shang, Yue Song, Dawei Yang, Qiang Wu, Yan Yan, and Guangyu Sun. Asvd: Activation- aware singular value decomposition for compressing large language models, 2025. URL https://arxiv.org/ abs/2312.05821
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? In Anna Korhonen, David Traum, and Lluís Màrquez, editors,Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, Florence, Italy, July 2019. Association for Computational Linguisti...
-
[48]
Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, and Baris Kasikci. Atom: Low-bit quantization for efficient and accurate llm serving.Proceedings of Machine Learning and Systems, 6:196–209, 2024. 12 IO-SVD: Input-Output Whitened SVD for Adaptive-Rank LLM CompressionA PREPRINT Appendix A Ad...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.