SEED: Targeted Data Selection by Weighted Independent Set
Pith reviewed 2026-05-20 20:24 UTC · model grok-4.3
The pith
SEED selects high-quality diverse training data by solving a weighted independent set problem on a calibrated similarity graph.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By modeling data selection as the search for a maximum weighted independent set on a similarity graph, and by refining node weights through restriction to the bilateral salient subspace together with local scale normalization of edge thresholds, the resulting SEED pipeline yields subsets that are simultaneously high in task-relevant influence and low in semantic redundancy, and these subsets deliver consistent gains over prior selection methods when used for instruction tuning, visual instruction tuning, and semantic segmentation.
What carries the argument
Weighted Independent Set formulation on a similarity graph, refined by bilateral salient subspace node calibration and local scale normalization of edge thresholds.
If this is right
- Produces subsets that simultaneously maximize quality and diversity without separate quality and diversity stages.
- Yields a compact multimodal dataset, Honeybee-Remake-SEED-200K, that supports strong downstream performance.
- Generalizes across instruction tuning, visual instruction tuning, and semantic segmentation for multiple model families.
- Scales to large heterogeneous corpora by operating directly on a graph representation of semantic similarity.
Where Pith is reading between the lines
- The same graph refinement steps could be applied to select demonstration data for in-context learning or to curate preference pairs for alignment.
- Local density normalization may offer a general remedy for selection bias whenever training distributions contain multiple distinct domains.
- If the salient-subspace idea proves robust, it could be combined with cheaper proxy models to reduce the cost of influence estimation itself.
Load-bearing premise
That restricting influence estimation to the bilateral salient subspace and scaling edge thresholds to local density will reliably separate task-relevant signals from noise and correct structural imbalance caused by cross-domain shifts.
What would settle it
An experiment in which models trained on a SEED-selected subset perform no better than models trained on subsets chosen by random sampling or by existing influence-function baselines on the same tasks and model families.
Figures







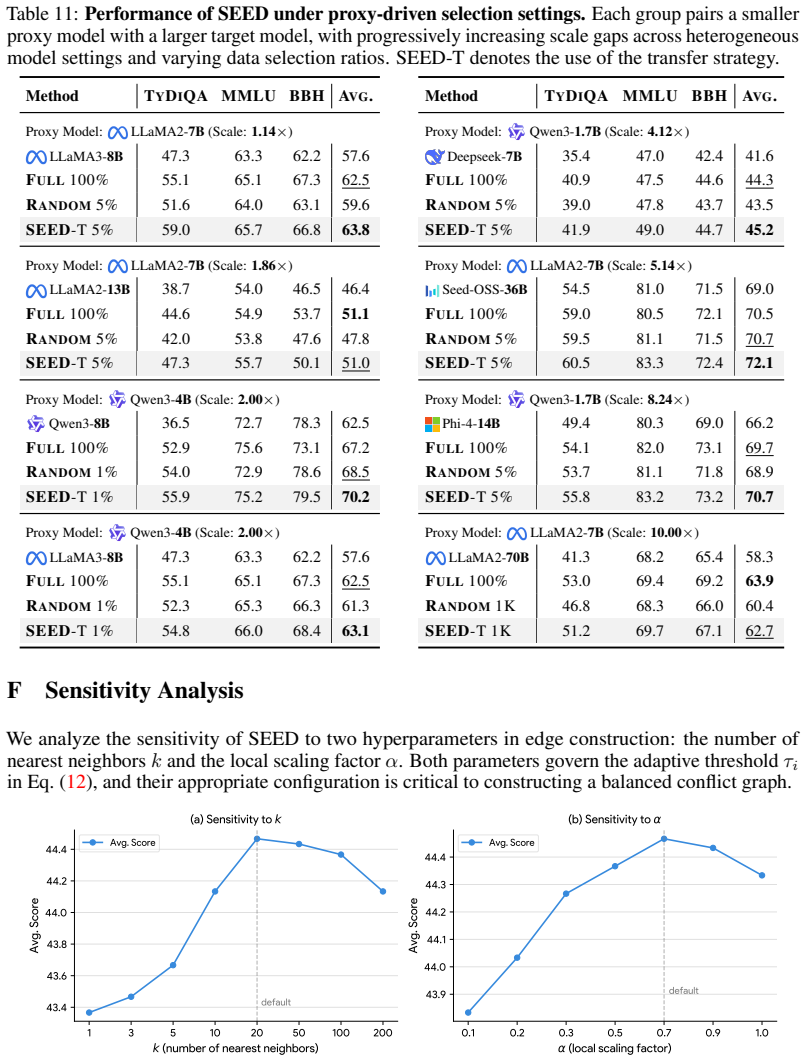
read the original abstract
Data selection seeks to identify a compact yet informative subset from large-scale training corpora, balancing sample quality against collection diversity. We formulate this problem as a Weighted Independent Set (WIS) on a similarity graph, where nodes represent data samples weighted by influence, and edges connect semantically redundant pairs. This formulation naturally yields subsets that are simultaneously high-quality and diverse. However, two challenges arise in practice: naive node weights fail to distinguish informative signals from gradient noise, and edge construction under heterogeneous domain distributions produces structurally imbalanced graphs that bias selection toward sparse regions. To address these issues, we introduce two principled refinements from a unified graph perspective: (1) \textit{node value calibration} that restricts influence estimation to the bilateral salient subspace to ground node importance in task-relevant signals rather than surface-level statistics; (2) \textit{local scale normalization} that adapts edge thresholds to local neighborhood density, mitigating graph imbalance induced by cross-domain distribution shifts. Together, these components yield a robust and scalable data selection pipeline dubbed SEED. We further construct \texttt{Honeybee-Remake-SEED-200K}, a compact multimodal dataset curated by SEED. Extensive experiments show that SEED consistently outperforms state-of-the-art methods on instruction tuning, visual instruction tuning, and semantic segmentation across diverse model families.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SEED, a data selection method formulated as a Weighted Independent Set (WIS) on a similarity graph, with nodes representing samples weighted by influence and edges connecting semantically redundant pairs. Two refinements are proposed from a graph perspective: node value calibration restricting influence estimation to the bilateral salient subspace, and local scale normalization adapting edge thresholds to local neighborhood density. The approach is shown to outperform state-of-the-art methods on instruction tuning, visual instruction tuning, and semantic segmentation across model families, while also releasing the Honeybee-Remake-SEED-200K multimodal dataset.
Significance. If the empirical results hold, this work provides a principled graph-based framework for balancing quality and diversity in data selection, with targeted fixes for gradient noise and cross-domain imbalance. Strengths include the unified WIS formulation, algorithmic detail sufficient for the pipeline, experiments that control for data volume while reporting consistent gains across tasks and models, and the public release of the curated 200K dataset which supports reproducibility. These elements position the method as a practical tool for curating training subsets for large-scale models.
minor comments (3)
- Abstract: the phrase 'restricts influence estimation to the bilateral salient subspace' would benefit from a one-sentence gloss on the subspace construction to aid readers before the technical sections.
- The experimental section should explicitly list the values or ranges used for the local scale normalization threshold and bilateral salient subspace parameters to ensure full reproducibility of the reported gains.
- A brief complexity analysis of the WIS solver employed would help assess scalability claims for very large corpora.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our work and the recommendation for minor revision. We appreciate the recognition of the unified WIS formulation, the algorithmic details, the controlled experiments, and the release of the Honeybee-Remake-SEED-200K dataset as practical contributions to data selection for large-scale models.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper formulates data selection as a Weighted Independent Set on a similarity graph and introduces two refinements (bilateral salient subspace calibration and local scale normalization) as independent algorithmic steps grounded in the stated assumptions about influence estimation and cross-domain graph imbalance. No equation or claim reduces a prediction or result to a quantity fitted inside the same pipeline, nor does any load-bearing step rely on a self-citation that itself collapses to the target result. The central pipeline is described with explicit algorithmic detail and evaluated empirically against baselines while controlling for data volume, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- local scale normalization threshold
- bilateral salient subspace restriction parameters
axioms (1)
- domain assumption A similarity graph can be built such that edges reliably connect semantically redundant samples
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
node value calibration that restricts influence estimation to the bilateral salient subspace... local scale normalization that adapts edge thresholds to local neighborhood density
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
S∗ = arg max ∑ w_i s.t. (u,v)∉E
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
SemDeDup: Data-efficient learning at web-scale through semantic deduplication
A. Abbas, K. Tirumala, D. Simig, S. Ganguli, and A. S. Morcos. Semdedup: Data-efficient learning at web-scale through semantic deduplication.arXiv preprint arXiv:2303.09540, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
M. Abdin, J. Aneja, H. Behl, S. Bubeck, R. Eldan, S. Gunasekar, M. Harrison, R. J. Hewett, M. Javaheripi, P. Kauffmann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024. 1, 2, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
arXiv preprint arXiv:2402.16827
A. Albalak, Y . Elazar, S. M. Xie, S. Longpre, N. Lambert, X. Wang, N. Muennighoff, B. Hou, L. Pan, H. Jeong, et al. A survey on data selection for language models.arXiv preprint arXiv:2402.16827, 2024. 1
-
[4]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [5]
-
[6]
X. Bi, D. Chen, G. Chen, S. Chen, D. Dai, C. Deng, H. Ding, K. Dong, Q. Du, Z. Fu, et al. Deepseek llm: Scaling open-source language models with longtermism.arXiv preprint arXiv:2401.02954, 2024. 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
L.-C. Chen, G. Papandreou, F. Schroff, and H. Adam. Rethinking atrous convolution for semantic image segmentation.arXiv preprint arXiv:1706.05587, 2017. 2, 7
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
X. Chen, J. Wu, S. Yang, R. Zhan, Z. Wu, M. Yang, S. Huang, L. S. Chao, and D. F. Wong. Neuron-aware data selection in instruction tuning for large language models. InInternational Conference on Learning Representations (ICLR), 2026. 1, 6, 7
work page 2026
-
[10]
X. Cheng, W. Zhang, S. Zhang, J. Yang, X. Guan, X. Wu, X. Li, G. Zhang, J. Liu, Y . Mai, Y . Zeng, Z. Wen, K. Jin, B. Wang, W. Zhou, Y . Lu, T. Li, W. Huang, and Z. Li. Simplevqa: Multimodal factuality evaluation for multimodal large language models.arXiv preprint arXiv:2502.13059, 2025. 3
-
[11]
J. H. Clark, E. Choi, M. Collins, D. Garrette, T. Kwiatkowski, V . Nikolaev, and J. Palomaki. TyDi QA: A benchmark for information-seeking question answering in typologically diverse languages.Transactions of the Association for Computational Linguistics, 2020. 2, 6
work page 2020
-
[12]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021. 4
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
B. Colling and M. van de Wiel. corrselect: An r package for correlation-constrained variable selection using maximal independent sets.Journal of Statistical Software, 2025. 2
work page 2025
-
[14]
M. Conover, M. Hayes, A. Mathur, J. Xie, J. Wan, S. Shah, A. Ghodsi, P. Wendell, M. Zaharia, and R. Xin. Free Dolly: Introducing the world’s first truly open instruction-tuned LLM, 2023. 5, 6
work page 2023
- [15]
-
[16]
Q. Dai, D. Zhang, J. W. Ma, and H. Peng. Improving influence-based instruction tuning data selection for balanced learning of diverse capabilities. InICLR 2025 Workshop on Navigating and Addressing Data Problems for Foundation Models, 2025. 1
work page 2025
-
[17]
H. Duan, J. Yang, Y . Qiao, X. Fang, L. Chen, Y . Liu, X. Dong, Y . Zang, P. Zhang, J. Wang, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. InProceedings of the 32nd ACM International Conference on Multimedia, pages 11198–11201, 2024. 3
work page 2024
- [18]
-
[19]
L. Engstrom, A. Feldmann, and A. Madry. Dsdm: Model-aware dataset selection with datamodels.arXiv preprint arXiv:2401.12926, 2024. 1
-
[20]
M. Fahrbach, T. Fu, and M. Gholami. Gist: Greedy independent set thresholding for diverse data summarization. InInternational Conference on Learning Representations (ICLR), 2025. 2 10
work page 2025
-
[21]
L. Feng, F. Nie, Y . Liu, and A. Alahi. TAROT: Targeted data selection via optimal transport. InInternational Conference on Machine Learning, 2025. 1, 6, 7, 4
work page 2025
-
[22]
C. Fu, P. Chen, Y . Shen, Y . Qin, M. Zhang, X. Lin, J. Yang, X. Zheng, K. Li, X. Sun, Y . Wu, R. Ji, C. Shan, and R. He. Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
M. R. Garey and D. S. Johnson.Computers and Intractability: A Guide to the Theory of NP-Completeness. W. H. Freeman and Company, 1979. 3
work page 1979
-
[24]
T. Guan, F. Liu, X. Wu, R. Xian, Z. Li, X. Liu, X. Wang, L. Chen, F. Huang, Y . Yacoob, D. Manocha, and T. Zhou. Hallusionbench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. 3
work page 2024
-
[25]
D. Guo, F. Wu, F. Zhu, F. Leng, G. Shi, H. Chen, H. Fan, J. Wang, J. Jiang, J. Wang, et al. Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062, 2025. 6, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
M. Halldórsson and J. Radhakrishnan. Greed is good: Approximating independent sets in sparse and bounded-degree graphs. InProceedings of the twenty-sixth annual ACM symposium on Theory of computing, pages 439–448, 1994. 3
work page 1994
-
[27]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, 2016. 7
work page 2016
-
[28]
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations, 2020. 6
work page 2020
-
[29]
A. A. Ismail, H. Corrada Bravo, and S. Feizi. Improving deep learning interpretability by saliency guided training.Advances in Neural Information Processing Systems, 2021. 2
work page 2021
-
[30]
J. Johnson, M. Douze, and H. Jégou. Billion-scale similarity search with gpus.IEEE transactions on big data, 7(3):535–547, 2019. 3, 2
work page 2019
-
[31]
F. Kang, H. A. Just, A. K. Sahu, and R. Jia. Performance scaling via optimal transport: Enabling data selection from partially revealed sources.Advances in Neural Information Processing Systems, 2024. 1
work page 2024
- [32]
-
[33]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, et al. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023. 1
work page 2023
-
[34]
P. W. Koh and P. Liang. Understanding black-box predictions via influence functions. InInternational conference on machine learning, 2017. 3, 1
work page 2017
-
[35]
A. Köpf, Y . Kilcher, D. V on Rütte, S. Anagnostidis, Z. R. Tam, K. Stevens, A. Barhoum, D. Nguyen, O. Stanley, R. Nagyfi, et al. Openassistant conversations-democratizing large language model alignment. Advances in neural information processing systems, 2023. 5, 6
work page 2023
-
[36]
W. Liu, W. Zeng, K. He, Y . Jiang, and J. He. What makes good data for alignment? A comprehensive study of automatic data selection in instruction tuning. InInternational Conference on Learning Representations (ICLR), 2024. 1
work page 2024
-
[37]
Z. Liu, A. Karbasi, and T. Rekatsinas. Tsds: Data selection for task-specific model finetuning.Advances in Neural Information Processing Systems, 37:10117–10147, 2024. 4
work page 2024
- [38]
-
[39]
S. Longpre, L. Hou, T. Vu, A. Webson, H. W. Chung, Y . Tay, D. Zhou, Q. V . Le, B. Zoph, J. Wei, et al. The flan collection: Designing data and methods for effective instruction tuning. InInternational Conference on Machine Learning, 2023. 5, 6
work page 2023
-
[40]
P. Lu, H. Bansal, T. Xia, J. Liu, C. Li, H. Hajishirzi, H. Cheng, K.-W. Chang, M. Galley, and J. Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. InInternational Conference on Learning Representations, 2024. 3 11
work page 2024
-
[41]
D. Ma, G. Shang, Z. Chen, L. Qin, Y . LUO, H. Xu, L. Pan, S. Fan, K. Yu, and L. Chen. Task-specific data selection for instruction tuning via monosemantic neuronal activations. InNeural Information Processing Systems, 2025. 1, 6, 7
work page 2025
-
[42]
A. Maharana, P. Yadav, and M. Bansal. D2 pruning: Message passing for balancing diversity and difficulty in data pruning. InInternational Conference on Learning Representations, 2024. 1, 7
work page 2024
-
[43]
W. Mai, Z. Zhang, K. Li, Y . Xue, and F. Li. Dynamic graph construction framework for multimodal named entity recognition in social media.IEEE Transactions on Computational Social Systems, 11(2):2513–2522,
-
[44]
L. McInnes, J. Healy, N. Saul, and L. Großberger. Umap: Uniform manifold approximation and projection. Journal of Open Source Software, 3(29), 2018. 9
work page 2018
-
[45]
B. McKinzie, Z. Gan, J.-P. Fauconnier, S. Dodge, B. Zhang, P. Dufter, D. Shah, X. Du, F. Peng, A. Belyi, et al. Mm1: methods, analysis and insights from multimodal llm pre-training. InEuropean Conference on Computer Vision, pages 304–323. Springer, 2024. 7
work page 2024
- [46]
-
[47]
M. Paul, S. Ganguli, and G. K. Dziugaite. Deep learning on a data diet: Finding important examples early in training. InAdvances in Neural Information Processing Systems (NeurIPS), 2021. 1
work page 2021
- [48]
-
[49]
S. R. Richter, V . Vineet, S. Roth, and V . Koltun. Playing for data: Ground truth from computer games. In European conference on computer vision, 2016. 7
work page 2016
-
[50]
S. Sanghavi, D. Shah, and A. S. Willsky. Message passing for maximum weight independent set.IEEE Transactions on Information Theory, 55(11), 2009. 1
work page 2009
-
[51]
M. Sap, H. Rashkin, D. Chen, R. Le Bras, and Y . Choi. Social iqa: Commonsense reasoning about social interactions. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 4463–4473, 2019. 4
work page 2019
-
[52]
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE international conference on computer vision, 2017. 2
work page 2017
-
[53]
O. Sener and S. Savarese. Active learning for convolutional neural networks: A core-set approach. In International Conference on Learning Representations (ICLR), 2018. 1
work page 2018
-
[54]
K. Sun, D. Yu, D. Yu, and C. Cardie. Investigating prior knowledge for challenging chinese machine reading comprehension.Transactions of the Association for Computational Linguistics, 8:141–155, 2020. 4
work page 2020
- [55]
-
[56]
H. Tan, S. Wu, W. Huang, S. Zhao, and X. QI. Data pruning by information maximization. InInternational Conference on Learning Representations, 2025. 1, 2, 6, 7
work page 2025
-
[57]
B. S. Team. Seed-oss open-source models. https://github.com/ByteDance-Seed/seed-oss, 2025. 8
work page 2025
-
[58]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
X. Wang, Y . Cui, J. Wang, F. Zhang, Y . Wang, X. Zhang, Z. Luo, Q. Sun, Z. Li, Y . Wang, et al. Multimodal learning with next-token prediction for large multimodal models.Nature, 2026. 1
work page 2026
- [60]
-
[61]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, 2022. 5, 6
work page 2022
-
[62]
K. Wei, R. Iyer, and J. Bilmes. Submodularity in data subset selection and active learning. InInternational Conference on Machine Learning (ICML), 2015. 1
work page 2015
-
[63]
Grok-1.5 vision preview.https://x.ai/news/grok-1.5v, 2024
xAI. Grok-1.5 vision preview.https://x.ai/news/grok-1.5v, 2024. 3
work page 2024
-
[64]
M. Xia, S. Malladi, S. Gururangan, S. Arora, and D. Chen. Less: Selecting influential data for targeted instruction tuning. InInternational Conference on Machine Learning, 2024. 1, 6, 7, 8, 3, 4, 5
work page 2024
-
[65]
S. M. Xie, S. Santurkar, T. Ma, and P. Liang. Data selection for language models via importance resampling. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. 1
work page 2023
-
[66]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 1, 2, 6, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Q. Yu, Z. Shen, Z. Yue, Y . Wu, B. Qin, W. Zhang, Y . Li, J. Li, S. Tang, and Y . Zhuang. Mastering collaborative multi-modal data selection: A focus on informativeness, uniqueness, and representativeness. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025. 7, 8, 5
work page 2025
-
[68]
L. Zelnik-Manor and P. Perona. Self-tuning spectral clustering.Advances in neural information processing systems, 17, 2004. 2
work page 2004
-
[69]
J. Zhang, C.-X. Zhang, Y . Liu, Y .-X. Jin, X.-W. Yang, B. Zheng, Y . Liu, and L.-Z. Guo. D3: diversity, difficulty, and dependability-aware data selection for sample-efficient llm instruction tuning. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, 2025. 1
work page 2025
- [70]
-
[71]
Y . Zhang, C.-K. Fan, T. Huang, M. Lu, S. Yu, J. Pan, K. Cheng, Q. She, and S. Zhang. Loss-oriented ranking for automated visual prompting in lvlms.arXiv preprint arXiv:2506.16112, 2025. 7
-
[72]
Y . Zhang, C.-K. Fan, J. Ma, W. Zheng, T. Huang, K. Cheng, D. A. Gudovskiy, T. Okuno, Y . Nakata, K. Keutzer, et al. Sparsevlm: Visual token sparsification for efficient vision-language model inference. In International Conference on Machine Learning, 2025. 1
work page 2025
-
[73]
Y . Zhang, F. Xiao, T. Huang, C.-K. Fan, H. Dong, J. Li, J. Wang, K. Cheng, S. Zhang, and H. Guo. Unveiling the tapestry of consistency in large vision-language models.Advances in Neural Information Processing Systems, 2024. 7 13 Contents A Related Work 1 A.1 Data Selection or Pruning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 A.2 Wei...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.