AOT-POT: Adaptive Operator Transformation for Large-Scale PDE Pre-training
Pith reviewed 2026-05-20 20:56 UTC · model grok-4.3
The pith
Transforming diverse PDE solution operators into a unified form allows one neural operator to pre-train effectively across many equation types.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AOT-POT expands hidden representations into multiple parallel streams, adaptively aggregates and redistributes them before and after each sub-layer, and mixes the streams using Sinkhorn-projected doubly stochastic matrices; these steps together convert structurally different PDE solution operators into aligned forms that a single neural operator can model jointly during large-scale pre-training.
What carries the argument
Adaptive operator transformation that expands representations into parallel streams, performs input-dependent aggregation and redistribution around sub-layers, and mixes streams via Sinkhorn-projected doubly stochastic matrices to align diverse solution operators.
If this is right
- State-of-the-art results on 12 PDE benchmarks using only 3 percent extra parameters.
- Relative L2 error drops by up to 77.6 percent and 40.9 percent on average compared with prior methods.
- Fine-tuning the pre-trained model cuts L2 error by as much as 92 percent on in-domain PDEs and 89 percent on out-of-domain PDEs.
- The same architecture works for both pre-training on mixed PDE data and quick adaptation to unseen equation types.
Where Pith is reading between the lines
- Operator alignment through input-dependent reshaping may prove useful for other families of scientific operators beyond PDEs, such as integral equations or stochastic processes.
- This direction complements capacity scaling and could lower the parameter count needed for capable scientific foundation models.
- Extending the stream-mixing mechanism to handle time-evolving or multi-scale PDEs would test whether the unification benefit holds for more complex dynamics.
Load-bearing premise
The best transformation that aligns solution operators changes with each PDE type and must be chosen adaptively from the input itself.
What would settle it
Training the same base architecture on the 12 PDE benchmarks but replacing the adaptive stream mixing and aggregation with a single fixed non-adaptive transformation, then checking whether relative L2 error reductions remain close to the reported 40.9 percent average.
Figures























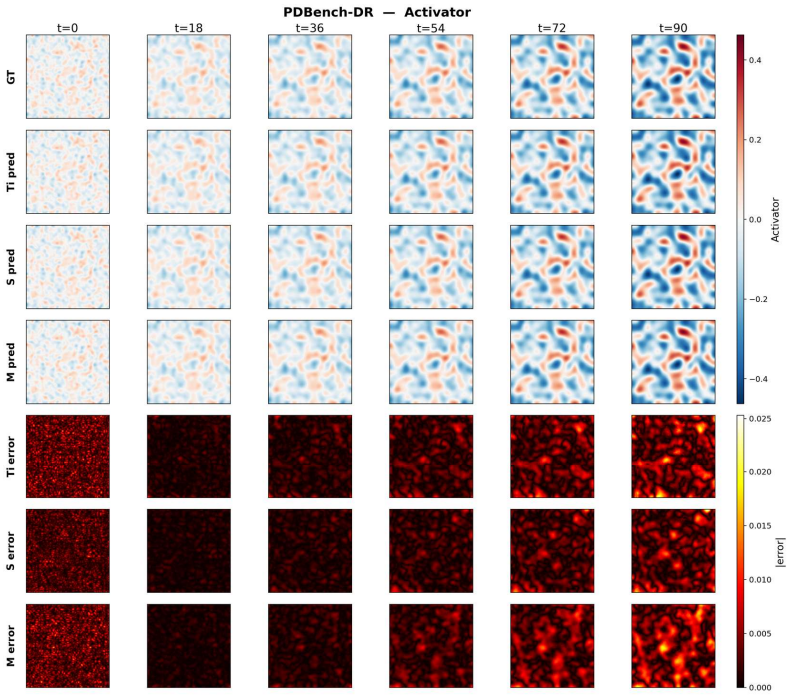




read the original abstract
Pre-training neural operators on diverse partial differential equation (PDE) datasets has emerged as a promising direction for building general-purpose surrogate models in scientific machine learning. However, the inherent complexity and structural diversity of PDE solution operators make multi-PDE pre-training fundamentally challenging. Existing methods mainly address this by increasing model capacity, while leaving the target solution operators unchanged. Inspired by classical numerical analysis, we instead propose to transform complex and diverse solution operators into simpler, better-aligned forms that are easier to model jointly. Since the optimal transformation varies across PDE types, it must be adaptive and input-dependent, allowing a single neural operator to approximate an entire family of operators. We instantiate this idea as AOT-POT (adaptive operator-transformation for pre-training operator transformer), which expands hidden representations into multiple parallel streams, adaptively aggregates and redistributes them before and after each sub-layer, and mixes streams through Sinkhorn-projected doubly stochastic matrices for stable training. These mechanisms together reshape diverse solution operators into a unified form that can be effectively modeled by a single architecture. Empirically, AOT-POT achieves state-of-the-art performance on 12 PDE benchmarks with only 3\% additional parameters, reducing relative L2 error by up to 77.6\% (40.9\% on average). Fine-tuning AOT-POT further reduces L2 error by up to 92\% on in-domain PDEs and 89\% on out-of-domain PDEs (unseen types during pre-training), demonstrating that adaptive operator transformation is an effective and complementary direction for advancing PDE foundation models beyond simply scaling model capacity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AOT-POT for pre-training neural operators across diverse PDE datasets. It introduces adaptive operator transformation via parallel streams, input-dependent aggregation before/after sub-layers, and Sinkhorn-projected doubly stochastic matrices to reshape varied solution operators into a unified form amenable to a single architecture. The central empirical claim is state-of-the-art performance on 12 PDE benchmarks using only 3% extra parameters, with relative L2 error reductions up to 77.6% (40.9% average), plus further gains from fine-tuning (up to 92% in-domain, 89% out-of-domain).
Significance. If the unification mechanism and performance claims hold under scrutiny, the work offers a promising complementary direction to capacity scaling for PDE foundation models. Grounding the approach in classical numerical analysis and demonstrating out-of-domain generalization are strengths; the modest parameter overhead and reported error reductions on multiple benchmarks could influence future multi-PDE pre-training designs if the latent operations are shown to meaningfully align operators rather than simply expand expressivity.
major comments (2)
- [Method] Method section (description of AOT-POT mechanisms): The core claim that parallel streams, adaptive aggregation, and Sinkhorn mixing 'reshape diverse solution operators into a unified form' is load-bearing yet unsupported by any direct evidence. No operator-norm distances, kernel alignments, or consistency metrics between input-to-output maps of different PDEs are provided before versus after the latent transformations; all operations act exclusively on hidden representations, leaving open whether gains stem from unification or incidental capacity increase.
- [Experiments] Experiments section (benchmark results): The reported SOTA performance and error reductions on 12 PDEs cannot be fully assessed without explicit data splits, verification steps, or ablations that isolate the adaptive transformation from the added parallel-stream capacity. This directly affects attribution of the 40.9% average improvement and the out-of-domain fine-tuning gains.
minor comments (2)
- [Abstract] Abstract: The baseline model against which the 'up to 77.6% (40.9% on average)' relative L2 reductions are measured should be stated explicitly for immediate clarity.
- Notation and figures: Introduce the definition of the doubly stochastic matrices and the aggregation weights earlier in the text; some figure captions would benefit from additional detail on what the parallel streams represent visually.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our contributions. We address each major point below and outline targeted revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method] Method section (description of AOT-POT mechanisms): The core claim that parallel streams, adaptive aggregation, and Sinkhorn mixing 'reshape diverse solution operators into a unified form' is load-bearing yet unsupported by any direct evidence. No operator-norm distances, kernel alignments, or consistency metrics between input-to-output maps of different PDEs are provided before versus after the latent transformations; all operations act exclusively on hidden representations, leaving open whether gains stem from unification or incidental capacity increase.
Authors: We acknowledge that the manuscript does not include direct quantitative metrics such as operator-norm distances or kernel alignments computed on the input-to-output maps before and after the transformations. All operations indeed occur on hidden representations, consistent with standard neural operator designs. The unification claim is grounded in the input-dependent adaptive aggregation and Sinkhorn-projected mixing, which are motivated by classical operator preconditioning techniques to simplify and align diverse operators in latent space. To address the concern, we will add a dedicated discussion subsection in the revised manuscript that elaborates on this motivation with references to numerical analysis literature and includes proxy empirical analyses, such as pairwise representation similarities across PDE types with and without the adaptive components. These additions will help clarify attribution beyond the modest 3% parameter overhead. revision: partial
-
Referee: [Experiments] Experiments section (benchmark results): The reported SOTA performance and error reductions on 12 PDEs cannot be fully assessed without explicit data splits, verification steps, or ablations that isolate the adaptive transformation from the added parallel-stream capacity. This directly affects attribution of the 40.9% average improvement and the out-of-domain fine-tuning gains.
Authors: We agree that more explicit documentation is warranted for full reproducibility and attribution. In the revised manuscript we will expand the experimental section to include detailed data splits (train/validation/test ratios and any preprocessing steps) for each of the 12 benchmarks, along with verification procedures such as multiple random seeds and statistical significance tests. We will also incorporate new ablation experiments that disable the adaptive aggregation and Sinkhorn mechanisms while retaining equivalent parallel-stream capacity, allowing direct isolation of their contribution to the reported error reductions. For the fine-tuning results, we will add details on the selection of out-of-domain PDE types and the fine-tuning protocol to better support the generalization claims. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper defines AOT-POT mechanisms (parallel streams, adaptive aggregation, Sinkhorn mixing) explicitly as operations on latent hidden representations inside the neural operator. These are presented as architectural choices whose effect on unifying solution operators is then tested empirically on external PDE benchmarks. No equation reduces the claimed unification to a fitted parameter renamed as prediction, nor does any load-bearing step rely on a self-citation whose content is itself unverified or tautological. The performance numbers (L2 error reductions) are reported against held-out test sets and are therefore independent of the definitional steps. This is the normal case of a self-contained empirical architecture paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural operators can approximate families of solution operators when inputs are transformed into aligned forms.
invented entities (1)
-
parallel streams with Sinkhorn-projected doubly stochastic matrices
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We instantiate this idea as AOT-POT ... expands hidden representations into multiple parallel streams, adaptively aggregates and redistributes them before and after each sub-layer, and mixes streams through Sinkhorn-projected doubly stochastic matrices
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
operator transformation ... mimics an operator transformation, so that the backbone is effectively trained against a simpler equivalent ˜G rather than G itself
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
E. C. Zachmanoglou and Dale W. Thoe.Introduction to Partial Differential Equations with Applications. Dover Publications, New York, 1986
work page 1986
-
[2]
Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
George Em Karniadakis, Ioannis G Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
work page 2021
-
[3]
Fourier neural operator for parametric partial differential equations
Zongyi Li, Nikola Borislavov Kovachki, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, Anima Anandkumar, et al. Fourier neural operator for parametric partial differential equations. InProc. ICLR, Conference held virtually, 2021
work page 2021
-
[4]
Jaideep Pathak, Shashank Subramanian, Peter Harrington, Sanjeev Raja, Ashesh Chattopadhyay, Morteza Mardani, Thorsten Kurth, David Hall, Zongyi Li, Kamyar Azizzadenesheli, et al. Fourcastnet: A global data-driven high-resolution weather model using adaptive fourier neural operators.arXiv preprint arXiv:2202.11214, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Neural operators for accelerating scientific simulations and design
Kamyar Azizzadenesheli, Nikola Kovachki, Zongyi Li, Miguel Liu-Schiaffini, Jean Kossaifi, and Anima Anandkumar. Neural operators for accelerating scientific simulations and design. Nature Reviews Physics, 6(5):320–328, 2024
work page 2024
-
[6]
Learning nonlinear operators via deeponet based on the universal approximation theorem of operators
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators. Nature machine intelligence, 3(3):218–229, 2021
work page 2021
-
[7]
Zhijie Li, Wenhui Peng, Zelong Yuan, and Jianchun Wang. Fourier neural operator approach to large eddy simulation of three-dimensional turbulence.Theoretical and Applied Mechanics Letters, 12(6):100389, 2022
work page 2022
-
[8]
Xiaoyu Zhao, Xiaoqian Chen, Zhiqiang Gong, Weien Zhou, Wen Yao, and Yunyang Zhang. RecFNO: A resolution-invariant flow and heat field reconstruction method from sparse obser- vations via fourier neural operator.International Journal of Thermal Sciences, 195:108619, 2024
work page 2024
-
[9]
GNOT: A general neural operator transformer for operator learning
Zhongkai Hao, Zhengyi Wang, Hang Su, Chengyang Ying, Yinpeng Dong, Songming Liu, Ze Cheng, Jian Song, and Jun Zhu. GNOT: A general neural operator transformer for operator learning. InProc. ICML, pages 12556–12569, Honolulu, 2023
work page 2023
-
[10]
Khemraj Shukla, Vivek Oommen, Ahmad Peyvan, Michael Penwarden, Nicholas Plewacki, Luis Bravo, Anindya Ghoshal, Robert M Kirby, and George Em Karniadakis. Deep neural operators as accurate surrogates for shape optimization.Engineering Applications of Artificial Intelligence, 129:107615, 2024
work page 2024
-
[11]
DPOT: Auto-regressive denoising operator transformer for large-scale pde pre-training
Zhongkai Hao, Chang Su, Songming Liu, Julius Berner, Chengyang Ying, Hang Su, Anima Anandkumar, Jian Song, and Jun Zhu. DPOT: Auto-regressive denoising operator transformer for large-scale pde pre-training. InProc. ICML, pages 17616–17635, Vienna, 2024
work page 2024
-
[12]
Mixture-of-Experts operator transformer for large-scale pde pre-training
Hong Wang, Haiyang Xin, Jie Wang, Xuanze Yang, Fei Zha, Huanshuo Dong, and Yan Jiang. Mixture-of-Experts operator transformer for large-scale pde pre-training. InProc. NeurIPS, San Diego, 2025
work page 2025
-
[13]
POSEIDON: Efficient foundation models for pdes
Maximilian Herde, Bogdan Raoni ´c, Tobias Rohner, Roger Käppeli, Roberto Molinaro, Em- manuel De Bezenac, and Siddhartha Mishra. POSEIDON: Efficient foundation models for pdes. InProc. NeurIPS, pages 72525–72624, Vancouver, 2024
work page 2024
-
[14]
Yousef Saad.Iterative Methods for Sparse Linear Systems. SIAM, Philadelphia, PA, 2003
work page 2003
-
[15]
American Mathematical Society, Providence, RI, 2022
Lawrence C Evans.Partial Differential Equations, volume 19. American Mathematical Society, Providence, RI, 2022
work page 2022
-
[16]
Yannick Augenstein, Taavi Repan, and Carsten Rockstuhl. Neural operator-based surrogate solver for free-form electromagnetic inverse design.Acs Photonics, 10(5):1547–1557, 2023. 11
work page 2023
-
[17]
NUNO: A general framework for learning parametric pdes with non-uniform data
Songming Liu, Zhongkai Hao, Chengyang Ying, Hang Su, Ze Cheng, and Jun Zhu. NUNO: A general framework for learning parametric pdes with non-uniform data. InProc. ICML, pages 21658–21671, Honolulu, 2023
work page 2023
-
[18]
Geometry-informed neural operator for large-scale 3D PDEs
Zongyi Li, Nikola Kovachki, Chris Choy, Boyi Li, Jean Kossaifi, Shourya Otta, Moham- mad Amin Nabian, Maximilian Stadler, Christian Hundt, Kamyar Azizzadenesheli, et al. Geometry-informed neural operator for large-scale 3D PDEs. InProc. NeurIPS, pages 35836– 35854, New Orleans, 2023
work page 2023
-
[19]
Zongyi Li, Hongkai Zheng, Nikola Kovachki, David Jin, Haoxuan Chen, Burigede Liu, Kamyar Azizzadenesheli, and Anima Anandkumar. Physics-informed neural operator for learning partial differential equations.ACM/IMS Journal of Data Science, 1(3):1–27, 2024
work page 2024
-
[20]
Sifan Wang, Hanwen Wang, and Paris Perdikaris. Learning the solution operator of paramet- ric partial differential equations with physics-informed deeponets.Science advances, 7(40): eabi8605, 2021
work page 2021
-
[21]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational physics, 378:686–707, 2019
work page 2019
-
[22]
Message passing neural pde solvers
Johannes Brandstetter, Daniel E Worrall, and Max Welling. Message passing neural pde solvers. InProc. ICLR, Conference held virtually, 2022
work page 2022
-
[23]
Katarzyna Michałowska, Somdatta Goswami, George Em Karniadakis, and Signe Riemer- Sørensen. Neural operator learning for long-time integration in dynamical systems with recurrent neural networks. InProc. IJCNN, pages 1–8, Yokohama, 2024
work page 2024
-
[24]
Choose a transformer: Fourier or Galerkin
Shuhao Cao. Choose a transformer: Fourier or Galerkin. InProc. NeurIPS, volume 34, pages 24924–24940, Conference held virtually, 2021
work page 2021
-
[25]
Transformer for partial differential equations’ operator learning
Zijie Li, Kazem Meidani, and Amir Barati Farimani. Transformer for partial differential equations’ operator learning.arXiv preprint arXiv:2205.13671, 2022
-
[26]
Solving high- dimensional PDEs with latent spectral models
Haixu Wu, Tengge Hu, Huakun Luo, Jianmin Wang, and Mingsheng Long. Solving high- dimensional PDEs with latent spectral models. InProc. ICML, pages 37417–37438, Honolulu, 2023
work page 2023
-
[27]
John Guibas, Morteza Mardani, Zongyi Li, Andrew Tao, Anima Anandkumar, and Bryan Catanzaro. Adaptive fourier neural operators: Efficient token mixers for transformers.arXiv preprint arXiv:2111.13587, 2021
-
[28]
MLP-mixer: An all-MLP architecture for vision
Ilya O Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, et al. MLP-mixer: An all-MLP architecture for vision. InProc. NeurIPS, pages 24261–24272, Conference held virtually, 2021
work page 2021
-
[29]
Acceler- ating data generation for neural operators via krylov subspace recycling
Hong Wang, Zhongkai Hao, Jie Wang, Zijie Geng, Zhen Wang, Bin Li, and Feng Wu. Acceler- ating data generation for neural operators via krylov subspace recycling. InProc. ICLR, Vienna, 2024
work page 2024
-
[30]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
work page 2019
-
[31]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InProc. NeurIPS, volume 33, pages 1877–1901, Conference held virtually, 2020
work page 1901
-
[32]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProc. CVPR, pages 16000–16009, New Orleans, 2022. 12
work page 2022
-
[33]
Highly accurate protein structure prediction with alphafold.Nature, 596(7873):583–589, 2021
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ron- neberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Žídek, Anna Potapenko, et al. Highly accurate protein structure prediction with alphafold.Nature, 596(7873):583–589, 2021
work page 2021
-
[34]
Uni-Mol: A universal 3d molecular representation learning framework
Gengmo Zhou, Zhifeng Gao, Qiankun Ding, Hang Zheng, Hongteng Xu, Zhewei Wei, Linfeng Zhang, and Guolin Ke. Uni-Mol: A universal 3d molecular representation learning framework. InProc. ICLR, Kigali, 2023
work page 2023
-
[35]
ClimaX: A foundation model for weather and climate
Tung Nguyen, Johannes Brandstetter, Ashish Kapoor, Jayesh K Gupta, and Aditya Grover. ClimaX: A foundation model for weather and climate. InProc. ICML, pages 25904–25938, Honolulu, 2023
work page 2023
-
[36]
Self-supervised learning with lie symmetries for partial differential equations
Grégoire Mialon, Quentin Garrido, Hannah Lawrence, Danyal Rehman, Yann LeCun, and Bobak Kiani. Self-supervised learning with lie symmetries for partial differential equations. In Proc. NeurIPS, pages 28973–29004, New Orleans, 2023
work page 2023
-
[37]
Shashank Subramanian, Peter Harrington, Kurt Keutzer, Wahid Bhimji, Dmitriy Morozov, Michael W Mahoney, and Amir Gholami. Towards foundation models for scientific machine learning: Characterizing scaling and transfer behavior. InProc. NeurIPS, volume 36, pages 71242–71262, New Orleans, 2023
work page 2023
-
[38]
In-context operator learning with data prompts for differential equation problems
Liu Yang, Siting Liu, Tingwei Meng, and Stanley J Osher. In-context operator learning with data prompts for differential equation problems. InProc. NeurIPS, page e2310142120, New Orleans, 2023
work page 2023
-
[39]
Multiple physics pretraining for physical surrogate models.arXiv preprint arXiv:2310.02994, 2023
Michael McCabe, Bruno Régaldo-Saint Blancard, Liam Holden Parker, Ruben Ohana, Miles Cranmer, Alberto Bietti, Michael Eickenberg, Siavash Golkar, Geraud Krawezik, Francois Lanusse, et al. Multiple physics pretraining for physical surrogate models.arXiv preprint arXiv:2310.02994, 2023
-
[40]
Walrus: A cross-domain foundation model for continuum dynamics.arXiv preprint arXiv:2511.15684, 2025
Michael McCabe, Payel Mukhopadhyay, Tanya Marwah, Bruno Regaldo-Saint Blancard, Fran- cois Rozet, Cristiana Diaconu, Lucas Meyer, Kaze WK Wong, Hadi Sotoudeh, Alberto Bietti, et al. Walrus: A cross-domain foundation model for continuum dynamics.arXiv preprint arXiv:2511.15684, 2025
-
[41]
The Well: A large-scale collection of diverse physics simulations for machine learning
Ruben Ohana, Michael McCabe, Lucas Meyer, Rudy Morel, Fruzsina J Agocs, Miguel Beneitez, Marsha Berger, Blakesley Burkhart, Stuart B Dalziel, Drummond B Fielding, et al. The Well: A large-scale collection of diverse physics simulations for machine learning. InProc. NeurIPS, pages 44989–45037, Vancouver, 2024
work page 2024
-
[42]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. InProc. ICLR, Conference held virtually, 2021
work page 2021
-
[43]
David Ha, Andrew M Dai, and Quoc V Le. HyperNetworks. InProc. ICLR, Toulon, 2017
work page 2017
-
[44]
mHC: Manifold-Constrained Hyper-Connections
Zhenda Xie, Yixuan Wei, Huanqi Cao, Chenggang Zhao, Chengqi Deng, Jiashi Li, Damai Dai, Huazuo Gao, Jiang Chang, Kuai Yu, et al. mHC: Manifold-constrained hyper-connections. arXiv preprint arXiv:2512.24880, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Richard Sinkhorn and Paul Knopp. Concerning nonnegative matrices and doubly stochastic matrices.Pacific Journal of Mathematics, 21(2):343–348, 1967
work page 1967
-
[46]
PDEBench: An extensive benchmark for scientific machine learning
Makoto Takamoto, Timothy Praditia, Raphael Leiteritz, Daniel MacKinlay, Francesco Alesiani, Dirk Pflüger, and Mathias Niepert. PDEBench: An extensive benchmark for scientific machine learning. InProc. NeurIPS, pages 1596–1611, New Orleans, 2022
work page 2022
-
[47]
Gupta and Johannes Brandstetter
Jayesh K. Gupta and Johannes Brandstetter. Towards multi-spatiotemporal-scale generalized PDE modeling.Trans. Mach. Learn. Res., 2023, 2023
work page 2023
-
[48]
arXiv preprint arXiv:2310.05963 , year =
Yining Luo, Yingfa Chen, and Zhen Zhang. CFDBench: A comprehensive benchmark for machine learning methods in fluid dynamics.arXiv preprint arXiv:2310.05963, 2023. 13
-
[49]
U-Net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional networks for biomedical image segmentation. InProc. MICCAI, pages 234–241, Munich, 2015
work page 2015
-
[50]
Factorized fourier neural operators
Alasdair Tran, Alexander Mathews, Lexing Xie, and Cheng Soon Ong. Factorized fourier neural operators. InProc. ICLR, Kigali, 2023
work page 2023
-
[51]
Convolutional neural operators.SAM Research Report, 2023, 2023
Bogdan Raoni ´c, Roberto Molinaro, Tobias Rohner, Siddhartha Mishra, and Emmanuel de Bézenac. Convolutional neural operators.SAM Research Report, 2023, 2023
work page 2023
-
[52]
Multitask learning.Machine learning, 28(1):41–75, 1997
Rich Caruana. Multitask learning.Machine learning, 28(1):41–75, 1997
work page 1997
-
[53]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProc. CVPR, pages 770–778, Las Vegas, 2016
work page 2016
-
[54]
Identity mappings in deep residual networks
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. InProc. ECCV, pages 630–645, Amsterdam, 2016
work page 2016
-
[55]
Densely connected convolutional networks
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. InProc. CVPR, pages 4700–4708, Honolulu, 2017
work page 2017
-
[56]
FractalNet: Ultra-deep neural networks without residuals
Gustav Larsson, Michael Maire, and Gregory Shakhnarovich. FractalNet: Ultra-deep neural networks without residuals. InProc. ICLR, Toulon, 2017
work page 2017
-
[57]
Fisher Yu, Dequan Wang, Evan Shelhamer, and Trevor Darrell. Deep layer aggregation. In Proc. CVPR, pages 2403–2412, Salt Lake City, 2018
work page 2018
-
[58]
Highway transformer: Self-gating enhanced self- attentive networks
Yekun Chai, Shuo Jin, and Xinwen Hou. Highway transformer: Self-gating enhanced self- attentive networks. InProc. ACL, pages 6887–6900, Conference held virtually, 2020
work page 2020
-
[59]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
H., Menezes, A., Qin, T., and Yan, R
Shufang Xie, Huishuai Zhang, Junliang Guo, Xu Tan, Jiang Bian, Hany Hassan Awadalla, Arul Menezes, Tao Qin, and Rui Yan. ResiDual: Transformer with dual residual connections.arXiv preprint arXiv:2304.14802, 2023
-
[62]
DenseFormer: Enhancing information flow in transformers via depth weighted averaging
Matteo Pagliardini, Amirkeivan Mohtashami, Francois Fleuret, and Martin Jaggi. DenseFormer: Enhancing information flow in transformers via depth weighted averaging. InProc. NeurIPS, pages 136479–136508, Vancouver, 2024
work page 2024
-
[63]
LAuRel: Learned augmented residual layer
Gaurav Menghani, Ravi Kumar, and Sanjiv Kumar. LAuRel: Learned augmented residual layer. InProc. ICML, pages 43826–43836, Vancouver, 2025
work page 2025
-
[64]
DeepCrossAttention: Supercharging transformer residual connections
Mike Heddes, Adel Javanmard, Kyriakos Axiotis, Gang Fu, Mohammadhossein Bateni, and Vahab Mirrokni. DeepCrossAttention: Supercharging transformer residual connections. In Proc. ICML, pages 22881–22903, Vancouver, 2025
work page 2025
-
[65]
Defa Zhu, Hongzhi Huang, Zihao Huang, Yutao Zeng, Yunyao Mao, Banggu Wu, Qiyang Min, and Xun Zhou. Hyper-Connections. InProc. ICLR, Singapore, 2025
work page 2025
-
[66]
Residual matrix transformers: Scaling the size of the residual stream
Brian Mak and Jeffrey Flanigan. Residual matrix transformers: Scaling the size of the residual stream. InProc. ICML, pages 42712–42729, Vancouver, 2025
work page 2025
-
[67]
MUDDFormer: Breaking residual bottlenecks in transformers via multiway dynamic dense connections
Da Xiao, Qingye Meng, Shengping Li, and Xingyuan Yuan. MUDDFormer: Breaking residual bottlenecks in transformers via multiway dynamic dense connections. InProc. ICML, pages 68440–68458, Vancouver, 2025
work page 2025
-
[68]
CogView: Mastering text-to-image generation via transformers
Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, et al. CogView: Mastering text-to-image generation via transformers. InProc. NeurIPS, pages 19822–19835, Conference held virtually, 2021
work page 2021
-
[69]
Springer Science & Business Media, New York, 2006
Eugene Seneta.Non-negative Matrices And Markov Chains. Springer Science & Business Media, New York, 2006
work page 2006
-
[70]
S Karthik Mukkavilli, Daniel Salles Civitarese, Johannes Schmude, Johannes Jakubik, Anne Jones, Nam Nguyen, Christopher Phillips, Sujit Roy, Shraddha Singh, Campbell Watson, et al. AI foundation models for weather and climate: Applications, design, and implementation.arXiv preprint arXiv:2309.10808, 2023
-
[71]
Neural general circulation models for weather and climate.Nature, 632(8027):1060–1066, 2024
Dmitrii Kochkov, Janni Yuval, Ian Langmore, Peter Norgaard, Jamie Smith, Griffin Mooers, Milan Klöwer, James Lottes, Stephan Rasp, Peter Düben, et al. Neural general circulation models for weather and climate.Nature, 632(8027):1060–1066, 2024
work page 2024
-
[72]
Exploiting edited large language models as general scientific optimizers
Qitan Lv, Tianyu Liu, and Hong Wang. Exploiting edited large language models as general scientific optimizers. InProc. NAACL, pages 5212–5237, New Mexico, 2025
work page 2025
-
[73]
Physics-informed machine learning: A survey on problems, methods and applications
Zhongkai Hao, Songming Liu, Yichi Zhang, Chengyang Ying, Yao Feng, Hang Su, and Jun Zhu. Physics-informed machine learning: A survey on problems, methods and applications. arXiv preprint arXiv:2211.08064, 2022
-
[74]
Steven L Brunton and J Nathan Kutz. Promising directions of machine learning for partial differential equations.Nature Computational Science, 4(7):483–494, 2024
work page 2024
-
[75]
Hanzhu Chen, Xu Shen, Qitan Lv, Jie Wang, Xiaoqi Ni, and Jieping Ye. SAC-KG: Exploiting large language models as skilled automatic constructors for domain knowledge graph. InProc. ACL, pages 4345–4360, Bangkok, 2024. 15
work page 2024
-
[76]
Intern-s1: A scientific multimodal foundation model.arXiv preprint arXiv:2508.15763, 2025
Lei Bai, Zhongrui Cai, Yuhang Cao, Maosong Cao, Weihan Cao, Chiyu Chen, Haojiong Chen, Kai Chen, Pengcheng Chen, Ying Chen, Yongkang Chen, Yu Cheng, Pei Chu, Tao Chu, Erfei Cui, Ganqu Cui, Long Cui, Ziyun Cui, Nianchen Deng, Ning Ding, Nanqing Dong, Peijie Dong, Shihan Dou, Sinan Du, Haodong Duan, Caihua Fan, Ben Gao, Changjiang Gao, Jianfei Gao, Songyang...
-
[77]
Coarse-to-Fine highlighting: Reducing knowledge hallucination in large language models
Qitan Lv, Jie Wang, Hanzhu Chen, Bin Li, Yongdong Zhang, and Feng Wu. Coarse-to-Fine highlighting: Reducing knowledge hallucination in large language models. InProc. ICML, pages 33594–33623, Vienna, 2024
work page 2024
-
[78]
Knowledge graph finetuning enhances knowledge manipulation in large language models
Hanzhu Chen, Xu Shen, Jie Wang, Zehao Wang, Qitan Lv, Junjie He, Rong Wu, Feng Wu, and Jieping Ye. Knowledge graph finetuning enhances knowledge manipulation in large language models. InProc. ICLR, Singapore, 2025
work page 2025
-
[79]
Yuxin Wu and Kaiming He. Group normalization. InProc. ECCV, pages 3–19, Munich, 2018. 16 Appendix Table of Contents A Related Work 17 A.1 Neural Operators . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 A.2 Pre-training in Scientific Machine Learning . . . . . . . . . . . . . . . . . . . . . 18 B Details of Experiment Settings 18 ...
-
[80]
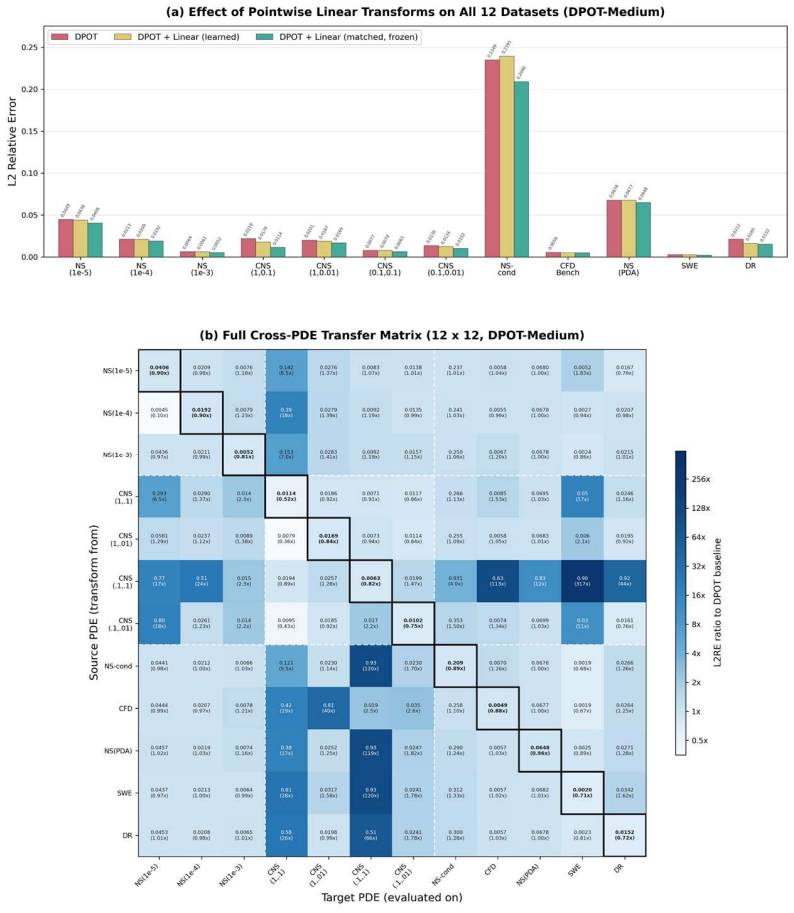
Jointly learned linear transforms universally help.Comparing the first two rows, DPOT+Linear improves over the DPOT baseline on all 12 datasets despite adding only 40 parameters (<0.001% of total). This confirms that even a minimal linear change of basis in the input/output function space can meaningfully reduce the effective complexity of the solution operator
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.