SignMuon: Communication-Efficient Distributed Muon Optimization
Pith reviewed 2026-05-20 23:42 UTC · model grok-4.3
The pith
Sign-Muon combines majority-vote sign steps with local polar factorization to reach an O(1/sqrt(T)) nonconvex rate at 32x lower bandwidth than float32.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Sign-Muon forms each worker's update direction from the polar factor of its momentum buffer, transmits the signs of that direction, and recovers a global direction by majority vote; the resulting spectral-norm normalized sign step provably converges at O(1/sqrt(T)) to an l1-stationary point under spectral-norm smoothness, with the stochastic term shrinking by 1/sqrt(M) under unimodal symmetric noise.
What carries the argument
The spectral-norm normalized sign step obtained by taking signs of a locally computed polar factor, aggregated by majority vote across workers.
If this is right
- Only one integer all-reduce is required per iteration while all polar factorization occurs locally.
- The method inherits the 1/sqrt(M) noise reduction of signSGD when noise is unimodal and symmetric.
- Bandwidth drops to one bit per parameter plus a small integer sum, yielding a 32x reduction relative to float32.
- The same framework supports an optional local polar step that further enforces orthogonality without extra communication.
Where Pith is reading between the lines
- The local-only orthogonalization pattern may extend to other matrix-aware first-order methods that currently pay communication cost for global QR or SVD steps.
- Because the majority vote operates entrywise on signs, the scheme could be combined with additional compression such as quantization of the integer counts without changing the core analysis.
- Weak scaling to larger worker counts should remain favorable as long as the unimodal-symmetric noise assumption continues to hold in practice.
Load-bearing premise
The proof requires spectral-norm smoothness of the loss together with bounded-variance stochastic gradients and unimodal symmetric noise for the majority-vote noise reduction.
What would settle it
A run on a spectral-norm smooth objective with bounded-variance gradients in which the observed stationarity measure fails to decay at rate O(1/sqrt(T)) would falsify the claimed convergence guarantee.
Figures







read the original abstract
Distributed training of large neural networks is bottlenecked by full-precision gradient communication and by coordinatewise optimizers that ignore the matrix structure of weight tensors. We propose Sign-Muon, a 1-bit, matrix-aware optimizer that combines majority-vote sign aggregation from signSGD with the polar-step framework of Muon. Each worker forms a Muon-style direction by taking the polar factor of its momentum via a Newton--Schulz iteration, transmits only the entrywise signs, and aggregates by majority vote; an optional local polar step further enforces orthogonality at no extra communication cost. Under spectral-norm smoothness and bounded-variance stochastic gradients, the spectral-norm normalized sign step yields an $\mathcal{O}(1/\sqrt{T})$ nonconvex rate for an $\ell_1$-based stationarity measure. With unimodal symmetric noise, majority vote across $M$ workers cuts the stochastic term by $1/\sqrt{M}$, matching signSGD. In the $\alpha$-$\beta$ model, distributed Sign-Muon needs only one integer sum-allreduce per iteration; all orthogonalization is local, giving a $32\times$ bandwidth reduction over float32 ($4\times$ for int8). Across 330 CIFAR-10/ResNet-50 configurations Sign-Muon attains the best validation accuracy (92.15\%); its 4-GPU majority-vote variant reaches 92.02\% with 37\% less training time at matched effective batch. On nanoGPT, Sign-Muon achieves lower perplexity and better anytime performance than other sign-based baselines, with favorable weak-scaling up to 16 GPUs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Sign-Muon, a 1-bit distributed optimizer that applies majority-vote sign aggregation to the polar factor of local momentum (computed via Newton-Schulz iterations) while keeping all orthogonalization local. Under spectral-norm smoothness and bounded-variance stochastic gradients it claims an O(1/sqrt(T)) rate to an ℓ1 stationarity measure; under unimodal symmetric noise the majority vote yields an additional 1/sqrt(M) reduction in the stochastic term. The method requires only a single integer all-reduce per iteration, delivering a 32× bandwidth saving relative to float32. Experiments across 330 CIFAR-10/ResNet-50 runs and nanoGPT training report competitive or superior validation accuracy and perplexity together with favorable weak scaling to 16 GPUs.
Significance. If the stated rate and noise-reduction claims hold under the listed assumptions, the work supplies a theoretically grounded route to combine matrix-aware directions with extreme quantization in the distributed setting. The explicit sufficient conditions, the local polar step that avoids extra communication, and the concrete 32× bandwidth figure are clear strengths. The scale of the CIFAR sweep and the reported anytime performance on nanoGPT add practical weight to the efficiency claims.
major comments (1)
- [§4] §4 (Convergence analysis), statement of the main theorem: the O(1/sqrt(T)) bound is asserted for an ℓ1-based stationarity measure after the spectral-norm normalized sign step; the proof sketch should explicitly identify the lemma or inequality that converts the spectral-norm smoothness assumption into a bound on this particular stationarity measure, because the abstract leaves the precise definition of the measure and the contraction step implicit.
minor comments (2)
- [Table 1] Table 1 or the communication-cost paragraph: an explicit column or row comparing total bits per iteration for Sign-Muon versus signSGD, Muon, and Adam would make the 32× claim immediately verifiable.
- [§5.2] Experimental protocol for the 4-GPU majority-vote variant: the text states that effective batch size is matched, yet the precise per-worker batch size, momentum buffer handling, and how the local Newton-Schulz iterations are synchronized should be stated in one additional sentence to aid reproduction.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, the recommendation of minor revision, and the constructive comment on the convergence analysis. We address the major comment below and will incorporate the requested clarification.
read point-by-point responses
-
Referee: [§4] §4 (Convergence analysis), statement of the main theorem: the O(1/sqrt(T)) bound is asserted for an ℓ1-based stationarity measure after the spectral-norm normalized sign step; the proof sketch should explicitly identify the lemma or inequality that converts the spectral-norm smoothness assumption into a bound on this particular stationarity measure, because the abstract leaves the precise definition of the measure and the contraction step implicit.
Authors: We agree that the proof sketch would be clearer with an explicit pointer to the supporting inequality. The current analysis in Section 4 proceeds from spectral-norm smoothness to a bound on the expected inner product after the sign step, which in turn controls the ℓ1 stationarity measure via the relation ||G||_1 ≤ rank(W)·||G||_2 together with the contraction property of the normalized sign operator. In the revised manuscript we will insert a single sentence in the proof of Theorem 4.1 that directly cites the relevant supporting result (Lemma A.2 in the appendix) and states the precise contraction step used to obtain the ℓ1 measure. This change affects only the exposition of the proof sketch and does not alter assumptions, theorem statement, or conclusions. revision: yes
Circularity Check
No significant circularity; derivation self-contained under explicit assumptions
full rationale
The paper states an O(1/sqrt(T)) nonconvex convergence rate to an l1 stationarity measure under the explicit sufficient conditions of spectral-norm smoothness and bounded-variance stochastic gradients, together with a 1/sqrt(M) noise reduction under unimodal symmetric noise for majority vote. These are presented as standard assumptions under which the spectral-norm normalized sign step yields the stated rate, without any reduction of the theorem to a fitted parameter, self-definition, or load-bearing self-citation. The communication protocol (local Newton-Schulz iterations plus integer all-reduce) is described separately from the rate analysis and introduces no internal definitional loop. No quoted step equates a derived quantity to its own input by construction, and the central claims remain independent of the present paper's fitted values or prior self-referential results.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption spectral-norm smoothness
- domain assumption bounded-variance stochastic gradients
- domain assumption unimodal symmetric noise
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Under spectral-norm smoothness and bounded-variance stochastic gradients, the spectral-norm normalized sign step yields an O(1/√T) nonconvex rate for an ℓ1-based stationarity measure.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Polar decomposition via Newton-Schulz iteration to obtain matrix-aware update directions.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
QSGD: Communication- efficient SGD via gradient quantization and encoding
Dan Alistarh, Demjan Grubic, Jerry Li, Ryota Tomioka, and Milan Vojnovic. QSGD: Communication- efficient SGD via gradient quantization and encoding. InAdvances in Neural Information Processing Systems, 2017
work page 2017
-
[2]
signSGD with Majority Vote is Communication Efficient And Fault Tolerant
Jeremy Bernstein, Jiawei Zhao, Kamyar Azizzadenesheli, and Anima Anandkumar. signSGD with majority vote is communication efficient and fault tolerant.CoRR, abs/1810.05291, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
˚Ake Bj¨orck and Clyde Bowie. An iterative algorithm for computing the best estimate of an orthogonal matrix.SIAM Journal on Numerical Analysis, 8(2):358–364, 1971
work page 1971
-
[4]
Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang, Hieu Pham, Xuanyi Dong, Thang Luong, Cho-Jui Hsieh, Yifeng Lu, and Quoc V. Le. Symbolic discovery of optimization algorithms. InAdvances in Neural Information Processing Systems 36, 2023
work page 2023
-
[5]
Adaptive consensus optimization method for gans, 2023
Sachin Kumar Danisetty, Santhosh Reddy Mylaram, and Pawan Kumar. Adaptive consensus optimization method for gans, 2023. arXiv:2304.10317
-
[6]
Shampoo: Preconditioned stochastic tensor optimization,
Vineet Gupta, Tomer Koren, and Yoram Singer. Shampoo: Preconditioned stochastic tensor optimization,
-
[7]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[8]
Nicholas J. Higham. Computing the polar decomposition—with applications.SIAM Journal on Scientific and Statistical Computing, 7(4):1160–1174, 1986
work page 1986
-
[9]
Higham.Functions of Matrices: Theory and Computation
Nicholas J. Higham.Functions of Matrices: Theory and Computation. SIAM, Philadelphia, PA, 2008
work page 2008
-
[10]
Characterizing the influence of system noise on large-scale applications by simulation
Torsten Hoefler, Timo Schneider, and Andrew Lumsdaine. Characterizing the influence of system noise on large-scale applications by simulation. InProceedings of the 2010 ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis (SC), pages 1–11, 2010
work page 2010
-
[11]
Muon: An optimizer for hidden layers in neural networks
Keller Jordan. Muon: An optimizer for hidden layers in neural networks. https://kellerjordan.github.io/ posts/muon/, 2024. Blog post. Accessed: 2025-12-26
work page 2024
-
[12]
Andrej Karpathy. nanogpt. https://github.com/karpathy/nanoGPT, 2022. Accessed: 2025-12-26
work page 2022
-
[13]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[14]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
work page 2009
-
[15]
Communication optimal least squares solver
Pawan Kumar. Communication optimal least squares solver. In2014 IEEE Intl Conf on High Performance Computing and Communications, 2014 IEEE 6th Intl Symp on Cyberspace Safety and Security, 2014 IEEE 11th Intl Conf on Embedded Software and Syst (HPCC,CSS,ICESS), pages 316–319, 2014
work page 2014
-
[16]
Multilevel communication optimal least squares.Procedia Computer Science, 51:1838– 1847, 2015
Pawan Kumar. Multilevel communication optimal least squares.Procedia Computer Science, 51:1838– 1847, 2015. International Conference On Computational Science, ICCS 2015. 13
work page 2015
-
[17]
Pawan Kumar, Stefano Markidis, Giovanni Lapenta, Karl Meerbergen, and Dirk Roose. High performance solvers for implicit particle in cell simulation.Procedia Computer Science, 18:2251–2258,
-
[18]
2013 International Conference on Computational Science
work page 2013
- [19]
-
[20]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.CoRR, abs/1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Hybrid tokenization and datasets for solving mathematics and science problems using transformers
Pratik Mandlecha, Snehith Kumar Chatakonda, Neeraj Kollepara, and Pawan Kumar. Hybrid tokenization and datasets for solving mathematics and science problems using transformers. In Proceedings of the 2022 SIAM International Conference on Data Mining (SDM), pages 289–297. SIAM, 2022
work page 2022
-
[22]
Optimizing neural networks with kronecker-factored approximate curvature
James Martens and Roger Grosse. Optimizing neural networks with kronecker-factored approximate curvature. InProceedings of the 32nd International Conference on Machine Learning, volume 37 of Proceedings of Machine Learning Research, pages 2408–2417. PMLR, 2015
work page 2015
-
[23]
Effects of spectral normalization in multi-agent reinforcement learning, 2023
Kinal Mehta, Anuj Mahajan, and Pawan Kumar. Effects of spectral normalization in multi-agent reinforcement learning, 2023. arXiv:2212.05331
-
[24]
On the byzantine fault tolerance of signSGD with majority vote.CoRR, abs/2502.19170, 2025
Emanuele Mengoli, Luzius Moll, Virgilio Strozzi, and El-Mahdi El-Mhamdi. On the byzantine fault tolerance of signSGD with majority vote.CoRR, abs/2502.19170, 2025
-
[25]
Light-weight deep extreme multilabel classification, 2023
Istasis Mishra, Arpan Dasgupta, Pratik Jawanpuria, Bamdev Mishra, and Pawan Kumar. Light-weight deep extreme multilabel classification, 2023. arXiv:2304.11045
-
[26]
Angle based dynamic learning rate for gradient descent, 2023
Neel Mishra and Pawan Kumar. Angle based dynamic learning rate for gradient descent, 2023. arXiv:2304.10457
-
[27]
A gauss-newton approach for min-max optimization in generative adversarial networks, 2024
Neel Mishra, Bamdev Mishra, Pratik Jawanpuria, and Pawan Kumar. A gauss-newton approach for min-max optimization in generative adversarial networks, 2024. arXiv:2404.07172
-
[28]
Springer Optimization and Its Applications
Yurii Nesterov.Lectures on Convex Optimization. Springer Optimization and Its Applications. Springer Cham, Cham, Switzerland, 2 edition, 2018
work page 2018
-
[29]
Joshua Peterson, Stephan Meylan, and David Bourgin. Openwebtext corpus. https://github.com/ jcpeterson/openwebtext, 2019. Accessed: 2025-12-26
work page 2019
-
[30]
B. T. Polyak. Some methods of speeding up the convergence of iteration methods.USSR Computational Mathematics and Mathematical Physics, 4(5):1–17, 1964
work page 1964
-
[31]
Optimization of collective reduction operations
Rolf Rabenseifner. Optimization of collective reduction operations. InInternational Conference on Computational Science (ICCS), pages 1–9, 2004
work page 2004
-
[32]
On the Convergence Analysis of Muon
Wei Shen, Ruichuan Huang, Minhui Huang, Cong Shen, and Jiawei Zhang. On the convergence analysis of muon, 2025. arXiv:2505.23737
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Sparsified sgd with memory.Advances in neural information processing systems, 31, 2018
Sebastian U Stich, Jean-Baptiste Cordonnier, and Martin Jaggi. Sparsified sgd with memory.Advances in neural information processing systems, 31, 2018
work page 2018
-
[34]
On the importance of initialization and momentum in deep learning
Ilya Sutskever, James Martens, George Dahl, and Geoffrey Hinton. On the importance of initialization and momentum in deep learning. In Sanjoy Dasgupta and David McAllester, editors,Proceedings of the 30th International Conference on Machine Learning, volume 28 ofProceedings of Machine Learning Research, pages 1139–1147. PMLR, 2013
work page 2013
-
[35]
Rajeev Thakur, Rolf Rabenseifner, and William Gropp. Optimization of collective communication operations in MPICH.International Journal of High Performance Computing Applications, 19(1):49– 66, 2005. 14
work page 2005
-
[36]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2023. arXiv:1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
PowerSGD: Practical low-rank gradient compression for distributed optimization
Thijs Vogels, Sai Praneeth Karimireddy, and Martin Jaggi. PowerSGD: Practical low-rank gradient compression for distributed optimization. InAdvances in Neural Information Processing Systems, 2019
work page 2019
-
[38]
Spectral-Norm Normalized Sign Descent
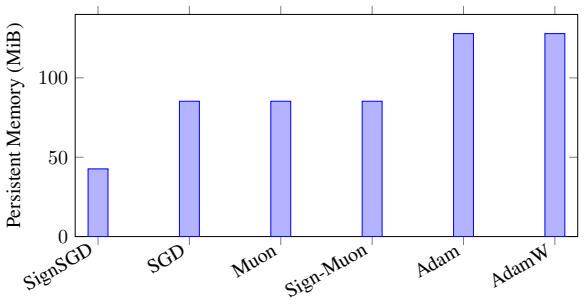
Wei Wen, Cong Xu, Feng Yan, Chunpeng Wu, Yandan Wang, Yiran Chen, and Hai Li. Terngrad: Ternary gradients to reduce communication in distributed deep learning.Advances in neural information processing systems, 30, 2017. 15 SignSGD SGD Muon Sign-Muon Adam AdamW 0 50 100 Persistent Memory (MiB) Figure 9: Persistent memory usage comparison for CIFAR-10 (ResN...
work page 2017
-
[39]
encodingS (m) ℓ,t ∈ {−1,+1} mℓ×nℓ as integers (e.g. int8),
-
[40]
performing an elementwiseSUMreduction across workers to obtain PM m=1 S(m) ℓ,t , and
-
[41]
sign of Newton–Schulz direction
applyingsign(·)elementwise locally. Proof. For each entry (i, j), ¯Sℓ,t[i, j] is by definition the sign of PM m=1 S(m) ℓ,t [i, j]. Since S(m) ℓ,t [i, j]∈ {−1,+1} , the sum is an integer in{−M,−M+2, . . . , M} and can be computed exactly by integer addition. Applying sign(·) yields the majority vote (up to tie-breaking at0). All steps after the reduction a...
-
[42]
and discussions in Muon [31]. C.8 Comparing full Muon vs Sign-Muon We now summarize what the theory implies about the advantages and limitations of Sign-Muon relative to (i) signSGD and (ii) full Muon. C.8.1 Stationarity measures and what improves Full Muon.The deterministic polar step (39) drives thenuclear normof the gradient to 0 at rate O(1/ √ T) (The...
-
[43]
This yields the clean descent ⟨gt,polar(g t)⟩=∥g t∥∗ and the nuclear-norm stationarity rate
Optimality of the polar direction in spectral geometry.Proposition 22 shows polar(gt) maximizes ⟨gt, D⟩ among all directions with ∥D∥op ≤1 . This yields the clean descent ⟨gt,polar(g t)⟩=∥g t∥∗ and the nuclear-norm stationarity rate
-
[44]
Practical orthogonalization with 1-bit communication.After majority vote, the server broadcasts ¯St ∈ {−1,+1} m×n (1-bit per entry). Each worker may compute Qt = polar( ¯St) locally (e.g. via Newton–Schulz) and step with Qt. This retains 1-bit communication and imports Muon-like orthogonalized steps. Theorems 18–19 already guarantee descent for Dt = ¯St/√...
-
[45]
SinceS >1/ √ Min this regime, the first term satisfies exp − M S2 6 ≤exp −1 6 <1
Thus, in all cases, 1 2 −q≥min S 2 √ 3 , 1 6 .(49) Plugging (49) into (48) yields qMV ≤exp −2M·min S2 12 , 1 36 = max exp − M S2 6 ,exp − M 18 . SinceS >1/ √ Min this regime, the first term satisfies exp − M S2 6 ≤exp −1 6 <1. Moreover, for anya >0and anyx >0, e−ax2 ≤ 1 2√a x, which follows by maximizingxe −ax2 overx >0. Applying this witha=M/6andx=Sgives...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.