Contrastive-SDXL: Annotation-Preserving Night-Time Augmentation for Pedestrian Detection
Pith reviewed 2026-05-20 21:26 UTC · model grok-4.3
The pith
Contrastive-SDXL translates daytime images to night-time while preserving pedestrian annotations and semantics for better detection training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
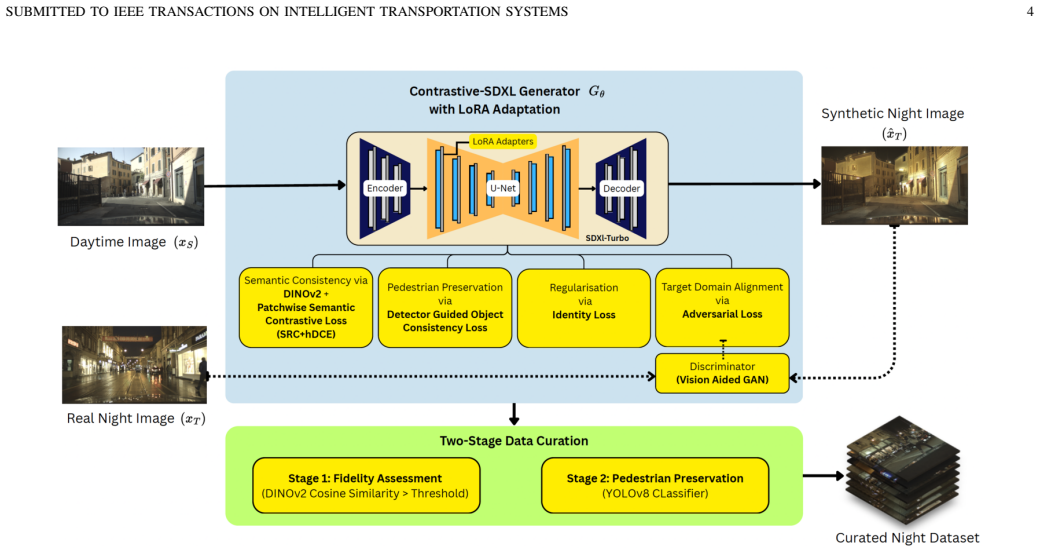
Contrastive-SDXL fine-tunes SDXL-Turbo using Low-Rank Adaptation and adds a patch-wise semantic contrastive loss driven by a pretrained DINOv2 encoder's self-attention maps at multiple levels together with an object consistency loss to translate daytime images into night-time versions while preserving semantic structure and pedestrian objects, generating images with FID 22.5 that allow pedestrian detectors to achieve 6-7% miss-rate reduction over daytime baselines and approach the performance of real night-time data.
What carries the argument
Patch-wise semantic contrastive loss guided by pretrained DINOv2 self-attention maps, which enforces local and global semantic consistency between daytime inputs and translated night-time outputs.
Load-bearing premise
That the patch-wise semantic contrastive loss guided by pretrained DINOv2 self-attention maps will preserve detector-relevant object boundaries and local semantics during domain translation without introducing artifacts that hurt downstream detection.
What would settle it
Train a pedestrian detector on daytime images plus the generated synthetic night-time images, then measure miss rate on a held-out real night-time test set; absence of the claimed 6-7% reduction relative to a daytime-only baseline, or visible boundary distortions and semantic shifts in the translated images, would falsify the central claim.
Figures






read the original abstract
Night-time pedestrian detection remains challenging because labelled night-time data are limited and large illumination differences make daytime-only trained detectors unreliable. Latent diffusion models (LDMs) provide a powerful basis for image-to-image translation and cross-domain augmentation, but their effectiveness in safety-critical perception depends on whether detector-relevant objects and local semantic structure are preserved when translating between source and target domains. In this work, we present Contrastive-SDXL, a day-to-night augmentation framework for night-time pedestrian detection built on SDXL-Turbo and fine-tuned using Low-Rank Adaptation (LoRA). To preserve semantic correspondence between daytime inputs and translated night-time images, we introduce a patch-wise semantic contrastive loss guided by a pretrained DINOv2 encoder rather than generator encoder features. Multi-level DINOv2 self-attention maps enforce both local and global semantic consistency, while an object consistency loss explicitly encourages pedestrian preservation. Contrastive-SDXL produces realistic night-time images, achieving a Frechet Inception Distance (FID) of 22.5. Detectors trained with our synthetic images obtain a 6-7% reduction in miss rate compared with a daytime-only baseline, approaching the performance of detectors trained on real night-time data. These results demonstrate that consistency-driven diffusion augmentation can effectively support safety-critical night-time pedestrian detection.Specific
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Contrastive-SDXL, a day-to-night image augmentation framework for pedestrian detection. Built on SDXL-Turbo fine-tuned via LoRA, it adds a patch-wise semantic contrastive loss driven by pretrained DINOv2 self-attention maps (multi-level local and global) plus an explicit object consistency loss to maintain pedestrian locations and semantics during translation. Reported outcomes include an FID of 22.5 on generated night-time images and a 6-7% miss-rate reduction for detectors trained on the augmented set versus a daytime-only baseline, approaching real night-time training performance.
Significance. If the empirical gains are robust, the work offers a practical route to address labeled night-time data scarcity in safety-critical perception without sacrificing annotation fidelity. The choice of external DINOv2 guidance over internal generator features is a concrete methodological contribution that could transfer to other domain-translation settings in computer vision.
major comments (1)
- [§3.2] §3.2: The central claim that the DINOv2-guided patch-wise contrastive loss preserves detector-relevant boundaries rests on the assumption that self-attention maps from a pretrained encoder avoid artifacts better than generator features; however, the manuscript provides no direct ablation replacing DINOv2 with the diffusion model's own encoder features, leaving open whether this design choice is load-bearing for the 6-7% miss-rate improvement.
minor comments (2)
- [Table 3] Table 3: The ablation rows for loss-component combinations report miss-rate deltas but omit standard deviations across random seeds or cross-validation folds, which would help assess stability of the reported gains.
- [Figure 5] Figure 5: The qualitative night-time translations would be clearer with explicit bounding-box overlays on both source and output to visually confirm pedestrian preservation.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation for minor revision. The single major comment raises a valid point about experimental validation, which we address directly below.
read point-by-point responses
-
Referee: [§3.2] §3.2: The central claim that the DINOv2-guided patch-wise contrastive loss preserves detector-relevant boundaries rests on the assumption that self-attention maps from a pretrained encoder avoid artifacts better than generator features; however, the manuscript provides no direct ablation replacing DINOv2 with the diffusion model's own encoder features, leaving open whether this design choice is load-bearing for the 6-7% miss-rate improvement.
Authors: We appreciate the referee's observation that a direct ablation would more conclusively demonstrate the contribution of the DINOv2 guidance. Our choice of DINOv2 was motivated by its strong semantic representations learned from large-scale pretraining, which we expected to yield cleaner self-attention maps for preserving object boundaries than the internal features of SDXL-Turbo (which can be influenced by the diffusion process itself). We agree, however, that this remains an assumption without explicit comparison. In the revised manuscript we will add an ablation that replaces the DINOv2 encoder with features from the diffusion model's own encoder, reporting the resulting FID scores and pedestrian-detection miss rates to quantify the impact on the observed 6-7% improvement. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The manuscript describes an empirical augmentation pipeline built on SDXL-Turbo with LoRA fine-tuning, a patch-wise contrastive loss driven by an external pretrained DINOv2 encoder, and an explicit object-consistency term. All reported outcomes (FID = 22.5, 6–7 % miss-rate reduction) are presented as measured experimental results on held-out detection benchmarks rather than as quantities derived from the method’s own fitted parameters or self-referential equations. No load-bearing step reduces by construction to a fitted input, and the cited components (DINOv2, SDXL-Turbo) are independent pretrained models whose behavior is not defined inside the present work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption DINOv2 features provide semantic representations suitable for enforcing consistency between day and night images for pedestrian detection
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a patch-wise semantic contrastive loss guided by a pretrained DINOv2 encoder... Multi-level DINOv2 self-attention maps enforce both local and global semantic consistency, while an object consistency loss explicitly encourages pedestrian preservation.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Contrastive-SDXL produces realistic night-time images, achieving a Frechet Inception Distance (FID) of 22.5. Detectors trained with our synthetic images obtain a 6-7% reduction in miss rate...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Palette: Image-to-image diffusion models,
C. Saharia, W. Chan, H. Chang, C. Lee, J. Ho, T. Salimans, D. Fleet, and M. Norouzi, “Palette: Image-to-image diffusion models,” inACM SIGGRAPH 2022 conference proceedings, 2022, pp. 1–10
work page 2022
-
[2]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
C. Meng, Y . He, Y . Song, J. Song, J. Wu, J.-Y . Zhu, and S. Ermon, “Sdedit: Guided image synthesis and editing with stochastic differential equations,”arXiv preprint arXiv:2108.01073, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Adversarial diffusion distillation,
A. Sauer, D. Lorenz, A. Blattmann, and R. Rombach, “Adversarial diffusion distillation,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 87–103
work page 2024
-
[4]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Exploring patch-wise semantic relation for contrastive learning in image-to-image translation tasks,
C. Jung, G. Kwon, and J. C. Ye, “Exploring patch-wise semantic relation for contrastive learning in image-to-image translation tasks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 18 260–18 269
work page 2022
-
[6]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Citypersons: A diverse dataset for pedestrian detection,
S. Zhang, R. Benenson, and B. Schiele, “Citypersons: A diverse dataset for pedestrian detection,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 3213–3221
work page 2017
-
[8]
The EuroCity Persons Dataset: A Novel Benchmark for Object Detection
M. Braun, S. Krebs, F. Flohr, and D. M. Gavrila, “The eurocity persons dataset: A novel benchmark for object detection,”arXiv preprint arXiv:1805.07193, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
J. Li, B. Li, Z. Tu, X. Liu, Q. Guo, F. Juefei-Xu, R. Xu, and H. Yu, “Light the night: A multi-condition diffusion framework for unpaired low-light enhancement in autonomous driving,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15 205–15 215
work page 2024
-
[10]
Unpaired image-to-image translation using cycle-consistent adversarial networks,
J.-Y . Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 2223–2232
work page 2017
-
[11]
Night-to-day image translation for retrieval-based localization,
A. Anoosheh, T. Sattler, R. Timofte, M. Pollefeys, and L. Van Gool, “Night-to-day image translation for retrieval-based localization,” in2019 International conference on robotics and automation (ICRA). IEEE, 2019, pp. 5958–5964
work page 2019
-
[12]
Semantic and geometric-aware day-to-night image translation network,
G. Bang, J. Lee, Y . Endo, T. Nishimori, K. Nakao, and S. Kamijo, “Semantic and geometric-aware day-to-night image translation network,” Sensors, vol. 24, no. 4, 2024. [Online]. Available: https://www.mdpi. com/1424-8220/24/4/1339
work page 2024
-
[13]
One-step image translation with text-to-image models,
G. Parmar, T. Park, S. Narasimhan, and J.-Y . Zhu, “One-step image translation with text-to-image models,”arXiv preprint arXiv:2403.12036, 2024
-
[14]
Seed-to-seed: Image translation in diffusion seed space,
O. Greenberg, E. Kishon, and D. Lischinski, “Seed-to-seed: Image translation in diffusion seed space,”arXiv preprint arXiv:2409.00654, 2024
-
[15]
Gan-based day-to-night image style transfer for nighttime vehicle detection,
C.-T. Lin, S.-W. Huang, Y .-Y . Wu, and S.-H. Lai, “Gan-based day-to-night image style transfer for nighttime vehicle detection,”IEEE Transactions on Intelligent Transportation Systems, vol. 22, no. 2, pp. 951–963, 2021
work page 2021
-
[16]
Contrastive learning for unpaired image-to-image translation,
T. Park, A. A. Efros, R. Zhang, and J.-Y . Zhu, “Contrastive learning for unpaired image-to-image translation,” inEuropean conference on computer vision. Springer, 2020, pp. 319–345
work page 2020
-
[17]
The spatially-correlative loss for various image translation tasks,
C. Zheng, T.-J. Cham, and J. Cai, “The spatially-correlative loss for various image translation tasks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 16 407– 16 417
work page 2021
-
[18]
W. Wang, W. Zhou, J. Bao, D. Chen, and H. Li, “Instance-wise hard negative example generation for contrastive learning in unpaired image- to-image translation,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 14 020–14 029
work page 2021
-
[19]
Exploring negatives in contrastive learning for unpaired image-to-image translation,
Y . Lin, S. Zhang, T. Chen, Y . Lu, G. Li, and Y . Shi, “Exploring negatives in contrastive learning for unpaired image-to-image translation,” in Proceedings of the 30th ACM international conference on multimedia, 2022, pp. 1186–1194
work page 2022
-
[20]
Modulated contrast for versatile image synthesis,
F. Zhan, J. Zhang, Y . Yu, R. Wu, and S. Lu, “Modulated contrast for versatile image synthesis,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18 280–18 290. SUBMITTED TO IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS 12
work page 2022
-
[21]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 9650–9660
work page 2021
-
[22]
X. Li, W. Wang, L. Wu, S. Chen, X. Hu, J. Li, J. Tang, and J. Yang, “Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection,”Advances in neural information processing systems, vol. 33, pp. 21 002–21 012, 2020
work page 2020
-
[23]
Distance-iou loss: Faster and better learning for bounding box regression,
Z. Zheng, P. Wang, W. Liu, J. Li, R. Ye, and D. Ren, “Distance-iou loss: Faster and better learning for bounding box regression,” inProceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 12 993–13 000
work page 2020
-
[24]
Ensembling off- the-shelf models for gan training,
N. Kumari, R. Zhang, E. Shechtman, and J.-Y . Zhu, “Ensembling off- the-shelf models for gan training,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 651– 10 662
work page 2022
-
[25]
G. Jocher, A. Chaurasia, and J. Qiu, “Ultralytics YOLO,” Jan. 2023. [Online]. Available: https://github.com/ultralytics/ultralytics
work page 2023
-
[26]
Nightowls: A pedestrians at night dataset,
L. Neumann, M. Karg, S. Zhang, C. Scharfenberger, E. Piegert, S. Mistr, O. Prokofyeva, R. Thiel, A. Vedaldi, A. Zisserman, and B. Schiele, “Nightowls: A pedestrians at night dataset,” inComputer Vision – ACCV 2018, Lecture Notes in Computer Science, vol. 11361. Springer, Cham, 2019, pp. 691–705
work page 2018
-
[27]
Instructpix2pix: Learning to follow image editing instructions,
T. Brooks, A. Holynski, and A. A. Efros, “Instructpix2pix: Learning to follow image editing instructions,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 18 392–18 402
work page 2023
-
[28]
Generalizable pedestrian detection: The elephant in the room,
I. Hasan, S. Liao, J. Li, S. U. Akram, and L. Shao, “Generalizable pedestrian detection: The elephant in the room,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 11 328–11 337
work page 2021
-
[29]
G. Jocher and J. Qiu, “Ultralytics yolo26,” 2026. [Online]. Available: https://github.com/ultralytics/ultralytics
work page 2026
-
[30]
Cascade r-cnn: High quality object detection and instance segmentation,
Z. Cai and N. Vasconcelos, “Cascade r-cnn: High quality object detection and instance segmentation,”IEEE transactions on pattern analysis and machine intelligence, vol. 43, no. 5, pp. 1483–1498, 2019
work page 2019
-
[31]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” inAdvances in neural information processing systems, vol. 30, 2017
work page 2017
-
[32]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
L. McInnes, J. Healy, and J. Melville, “Umap: Uniform manifold approximation and projection for dimension reduction,”arXiv preprint arXiv:1802.03426, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
Tju-dhd: A diverse high-resolution dataset for object detection,
Y . Pang, J. Cao, Y . Li, J. Xie, H. Sun, and J. Gong, “Tju-dhd: A diverse high-resolution dataset for object detection,”IEEE Transactions on Image Processing, vol. 30, pp. 207–219, 2020. Franky GeorgeFranky George is currently pursuing the Ph.D. degree at the University of Hull, U.K. His research focuses on generative models, particularly diffusion-based...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.