GRASP: Graph Agentic Search over Propositions for Multi-hop Question Answering
Pith reviewed 2026-05-19 20:44 UTC · model grok-4.3
The pith
GRASP achieves top accuracy on multi-hop QA benchmarks while using 40 to 50 percent fewer tokens through hierarchical graph search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
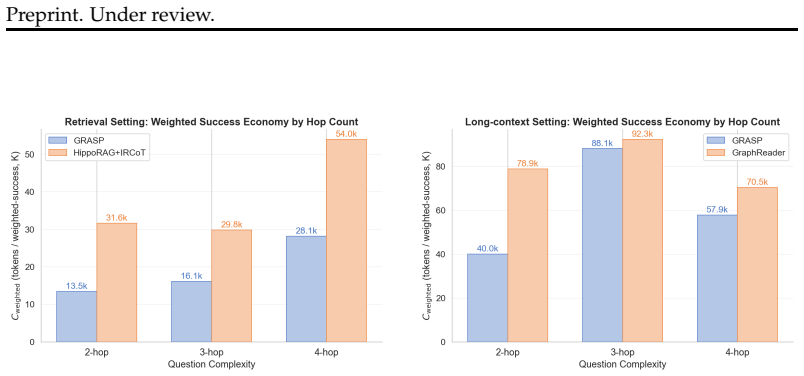
GRASP coordinates retrieval by decomposing multi-hop queries into dependency-aware plans that dynamically scale the number of sub-agents. Each sub-agent explores a three-layer hierarchical graph of entities, propositions, and passages, using entities for targeted traversal and propositions for high-recall passage retrieval via reciprocal-rank voting. In evaluations on MuSiQue, 2WikiMultihopQA, and HotpotQA, this yields the highest accuracy in open retrieval settings on two datasets with 40-50 percent fewer tokens than the leading baseline, and leads on exact match and F1 in the LongBench setting with 30 percent fewer tokens.
What carries the argument
The three-layer hierarchical graph of entities, propositions, and passages, combined with dynamic sub-agent scaling based on query complexity.
If this is right
- Achieves highest QA accuracy on MuSiQue and 2Wiki in open retrieval while using 40-50 percent fewer tokens than the prior leading approach.
- Leads on EM and F1 across all three datasets in the LongBench setting while using 30 percent fewer tokens than the next most accurate method.
- Introduces success economy as a metric for amortized token cost per correct answer weighted by difficulty.
- Shows that agentic retrieval can dynamically scale sub-agents according to query complexity for better efficiency.
Where Pith is reading between the lines
- The hierarchical approach could be extended to other domains requiring chained evidence, such as legal document analysis or medical diagnosis support.
- Reciprocal-rank voting on propositions may offer a general technique for balancing precision and recall in retrieval without additional model calls.
- Adopting success economy in evaluations could shift research focus toward methods that deliver correct answers at lower cumulative cost rather than maximizing accuracy alone.
Load-bearing premise
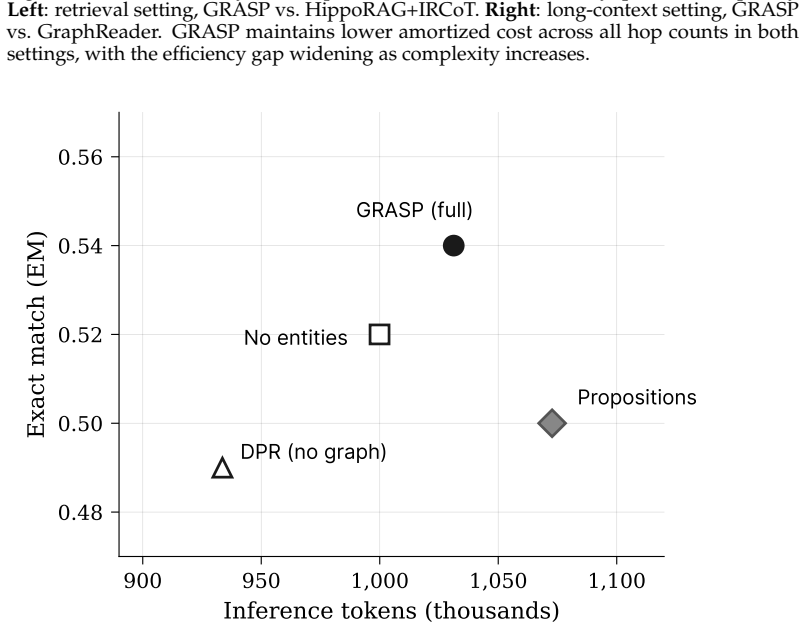
Building and traversing the three-layer graph at index and inference time does not introduce costs or noise that erase the reported token savings.
What would settle it
An experiment showing that the total tokens used to build the graph plus inference tokens for GRASP exceed those of the baseline methods on the same datasets, or that accuracy drops below baselines when graph construction is noisy.
Figures





read the original abstract
Agentic retrieval improves multi-hop question answering by giving language models autonomy to iteratively gather evidence. Recent work augments these systems with knowledge graphs for structured traversal, but this combination introduces significant cost: expensive graph construction at index time and compounding token usage at inference time. We introduce Graph Agentic Search over Propositions (GRASP), an agentic system that simultaneously optimizes for high accuracy and minimal token usage in multi-hop question answering. Rather than executing a rigid, singular query, GRASP actively coordinates its retrieval strategy by decomposing multi-hop queries into dependency-aware plans. This enables GRASP to dynamically scale the number of sub-agents according to the complexity of the problem. Each sub-agent resolves its single-hop query by exploring a novel three-layer hierarchical graph of entities, propositions, and passages, using the entity layer for targeted traversal and the proposition layer for high-recall passage retrieval via reciprocal-rank voting. We evaluate GRASP on MuSiQue, 2WikiMultihopQA, and HotpotQA under two settings: open-corpus retrieval and extended context reasoning (LongBench). GRASP achieves the highest QA accuracy in the open retrieval setting on MuSiQue and 2Wiki while using 40-50 percent fewer tokens than IRCoT+HippoRAG2. Furthermore, GRASP leads on EM and F1 across all three datasets in the LongBench setting while using 30 percent fewer tokens than the next most accurate method. Finally, we introduce success economy - the amortized token cost per correct answer, weighted by difficulty - and advocate for efficiency-aware evaluation as a standard practice for agentic QA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GRASP, an agentic retrieval system for multi-hop QA that decomposes queries into dependency-aware plans, dynamically scales sub-agents, and traverses a novel three-layer hierarchical graph (entities for targeted traversal, propositions for high-recall via reciprocal-rank voting, and passages). It reports leading accuracy on MuSiQue and 2WikiMultihopQA in open retrieval with 40-50% fewer tokens than IRCoT+HippoRAG2, leads EM/F1 on all three datasets in the LongBench setting with 30% fewer tokens than the next-best method, and proposes 'success economy' as an amortized efficiency metric.
Significance. If the efficiency claims survive rigorous cost accounting, the work would advance efficient agentic QA by showing how a structured three-layer graph plus voting can deliver accuracy gains alongside substantial token reductions. The dynamic sub-agent scaling and success-economy metric are useful contributions that could influence evaluation standards. The hierarchical design offers a concrete mechanism for trading recall and precision that merits further study.
major comments (2)
- [§4] §4 (Experiments) and associated tables: the 40-50% token reduction versus IRCoT+HippoRAG2 on MuSiQue/2Wiki is reported without any ablation or amortized breakdown of index-time three-layer graph construction costs or inference-time traversal overhead; this directly affects whether the headline efficiency claim holds once construction and noise are included.
- [§3.2] §3.2 (Graph Construction and Traversal): the reciprocal-rank voting mechanism on the proposition layer is described as providing high-recall retrieval, yet no quantitative analysis of retrieval noise introduced by the entity-proposition-passage hierarchy or its effect on downstream sub-agent accuracy is supplied, leaving the accuracy-plus-efficiency result vulnerable.
minor comments (2)
- [Abstract] The abstract introduces 'success economy' without a one-sentence definition; a brief parenthetical would improve standalone readability.
- [§3] Notation for sub-agent scaling and dependency-aware plans could be formalized with a short pseudocode block or equation to clarify the coordination logic.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important aspects of our efficiency claims and the supporting analysis for the hierarchical graph. We respond to each major comment below and commit to revisions that directly address the concerns raised.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and associated tables: the 40-50% token reduction versus IRCoT+HippoRAG2 on MuSiQue/2Wiki is reported without any ablation or amortized breakdown of index-time three-layer graph construction costs or inference-time traversal overhead; this directly affects whether the headline efficiency claim holds once construction and noise are included.
Authors: We agree that the manuscript would be strengthened by an explicit amortized breakdown. The reported token savings focus on inference-time usage during agentic traversal, which is the dominant cost in repeated deployment scenarios. In the revised version we will add a dedicated analysis subsection that reports (1) one-time index construction costs for the three-layer graph, (2) per-query inference-time traversal overhead, and (3) amortized token cost per query when the index is reused across a realistic query workload. We will also include an ablation isolating traversal overhead from the baseline comparison. revision: yes
-
Referee: [§3.2] §3.2 (Graph Construction and Traversal): the reciprocal-rank voting mechanism on the proposition layer is described as providing high-recall retrieval, yet no quantitative analysis of retrieval noise introduced by the entity-proposition-passage hierarchy or its effect on downstream sub-agent accuracy is supplied, leaving the accuracy-plus-efficiency result vulnerable.
Authors: We acknowledge that isolating the contribution of retrieval noise would make the accuracy-efficiency trade-off more transparent. While end-to-end QA metrics already reflect the net effect of the hierarchy, we will add quantitative retrieval diagnostics in the revision: precision and recall at the proposition layer, an ablation comparing sub-agent accuracy with and without reciprocal-rank voting, and a breakdown of how noise at each layer propagates to final answer quality. These additions will directly quantify the noise introduced by the hierarchy. revision: yes
Circularity Check
No circularity: empirical claims rest on external benchmarks rather than internal reductions
full rationale
The paper introduces GRASP as a novel agentic system with a three-layer hierarchical graph and dynamic sub-agent scaling, then reports empirical results on MuSiQue, 2WikiMultihopQA, and HotpotQA under open-retrieval and LongBench settings. All load-bearing claims (highest accuracy, 40-50% token reduction vs. IRCoT+HippoRAG2, 30% token reduction in LongBench, and the new success-economy metric) are presented as direct experimental outcomes against named external baselines. No equations, fitted parameters, or first-principles derivations appear that would reduce reported accuracy or token counts back to quantities defined inside the paper itself. The abstract and description contain no self-citations that serve as load-bearing uniqueness theorems, no ansatz smuggling, and no renaming of known results as new derivations. The evaluation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.lean, Cost/FunctionalEquation.leanreality_from_one_distinction, washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GRASP builds a hierarchical graph with three layers: typed entities for agentic traversal, propositions for retrieval, and source passages for post-retrieval context.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection, RCLCombiner_isCoupling_iff unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Passages are scored using the RankVote of their constituent propositions... score(D) = ∑ wj where wj = 1/(1+R(pj))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Understanding Dataset Design Choices for Multi-hop Reasoning
URLhttps://arxiv.org/abs/1904.12106. Sihao Chen, Senaka Buthpitiya, Alex Fabrikant, Dan Roth, and Tal Schuster. PropSegmEnt: A large-scale corpus for proposition-level segmentation and entailment recognition. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.),Findings of the Association for Computational Linguistics: ACL 2023, pp. 8874–8893, To...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2023.findings-acl.565 1904
-
[2]
Lost in the Middle: How Language Models Use Long Contexts
URLhttps://arxiv.org/abs/2408.08172. Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. Lightrag: Simple and fast retrieval-augmented generation, 2025. URLhttps://arxiv.org/abs/2410.05779. Bernal Jim´enez Guti´errez, Yiheng Shu, Weijian Qi, Sizhe Zhou, and Yu Su. From RAG to memory: Non-parametric continual learning for large language models. InFo...
work page internal anchor Pith review doi:10.1162/tacl 2025
-
[3]
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions
URLhttps://arxiv.org/abs/2212.10509. Yu Wang, Nedim Lipka, Ryan A. Rossi, Alexa Siu, Ruiyi Zhang, and Tyler Derr. Knowledge graph prompting for multi-document question answering, 2023. URL https://arxiv. org/abs/2308.11730. Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, and Zhen-Hua Ling. Corrective retrieval augmented generation, 2024. URLhttps://arxiv.org/abs/2401.1...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Write arational plan--- a 1--3 sentence outline of the reasoning chain and key facts needed
-
[5]
Each will be answered by a research agent searching the knowledge graph
Produce anordered list of sub-questions. Each will be answered by a research agent searching the knowledge graph. Rules -No assumptions:Never name or assume entities not explicitly stated in the question. Your sub-questions must find them. -No redundant steps:Every sub-question must retrieve new information from the knowledge graph. Do not create a step w...
-
[6]
Who was the first President of Namibia?
-
[7]
Who succeeded #1? Question:‘‘What is the population of the city where the architect of the Sydney Opera House was born?’’ Rational Plan:I need to identify the architect of the Sydney Opera House, find their birth city, then retrieve that city’s population. Sub-questions:
-
[8]
Who was the architect of the Sydney Opera House?
-
[9]
In which city was #1 born?
-
[10]
The chain is linear with four hops
What is the population of #2? Question:‘‘When did Napoleon occupy the city where the mother of the woman who brought Louis XVI style to the court died?’’ Rational Plan:I need to find who brought Louis XVI style to court, find that person’s mother, find the city where the mother died, then find when Napoleon occupied that city. The chain is linear with fou...
-
[11]
Who brought Louis XVI style to the court?
-
[12]
Who was the mother of #1?
-
[13]
In what city did #2 die?
-
[14]
When did Napoleon occupy #3? Question:‘‘When did the people who captured Malakoff come to the region where Philipsburg is located?’’ Rational Plan:This requires two parallel branches --- finding the region where Philipsburg is located (via what it is capital of, then what terrain feature that is on) and who captured Malakoff --- before combining them in a...
-
[15]
What is Philipsburg capital of?
- [16]
-
[17]
Who captured Malakoff?
-
[18]
When did #3 come to #2? Question:‘‘Which People’s Republic of China city is at a higher level of government, Dehui or Karamay?’’ Rational Plan:I need to find the government level of each city independently and then compare them. Both lookups are parallel. Sub-questions:
-
[19]
What level of government is the city of Dehui?
-
[20]
What level of government is the city of Karamay? Question:‘‘Where did Kent Patterson play his home games until he became a free agent?’’ Rational Plan:I need to find which team Kent Patterson played for before becoming a free agent, then find where that team plays its home games. Sub-questions:
-
[21]
Which team did Kent Patterson play for before becoming a free agent?
-
[22]
Where does #1 play its home games? Question:‘‘Which film has the director who is older, God’s Gift to Women or Aldri Annet Enn Br˚ak?’’ Rational Plan:I need to find the director of each film, then their birth dates, and compare. The two director lookups are independent but each requires a bridge through the film to the director’s birth date. Sub-questions:
-
[23]
Who directed God’s Gift to Women?
-
[24]
Who directed Aldri Annet Enn Br˚ak?
-
[25]
When was #3 born? Query rewriting prompt (§3.3).The sub-question is reformulated into a declarative search statement optimized for cosine similarity against propositions, along with keywords for BM25 sparse retrieval. This produces the inputs to step❶in Figure 2. You are a dense retrieval query optimizer. Rewrite the sub-question into a short declarative ...
work page 1981
- [26]
-
[27]
Entities: [Name]|[Type]|[proposition indices]
[proposition text] ... Entities: [Name]|[Type]|[proposition indices] ... Repeat for each passage. Proposition indices are 0-based and reset per passage. Example Input: Passage [0]: Document Title: Easter Hare Content: The earliest evidence for the Easter Hare (Osterhase) was recorded in south-west Germany in 1678 by the professor of medicine Georg Franck ...
-
[28]
The earliest evidence for the Easter Hare was recorded in south-west Germany in 1678 by Georg Franck von Franckenau
-
[29]
Georg Franck von Franckenau was a professor of medicine
-
[30]
The Easter Hare remained unknown in other parts of Germany until the 18th century
-
[31]
Richard Sermon was a scholar
-
[32]
Richard Sermon writes that hares were frequently seen in gardens in spring
-
[33]
The Easter Hare is also known as Osterhase. Entities: Easter Hare|Folklore Figure|0 2 5 Germany|Country|0 2 1678|Year|0 Georg Franck von Franckenau|Professor of Medicine|0 1 Richard Sermon|Scholar|3 4 Osterhase|Folklore Figure|5 LLM judge prompts.We adopt the LLM-as-judge evaluation from (Li et al., 2024; Lee et al., 2024). LR-1 performs strict binary agr...
work page 2024
-
[34]
In which region is Perdiguera located?
-
[35]
Who is the person named Martin from#1and in which city did he die?
-
[36]
When was the Palau de la Generalitat in#2constructed? Subagent 1 —In which region is Perdiguera located? Given sub-question:In which region is Perdiguera located? Rewritten query:The administrative region or autonomous community where the munic- ipality of Perdiguera is located. traversal(iteration 1) Search statement:The administrative region or autonomo...
work page 2009
-
[37]
Perdiguera is located in the autonomous community ofAragon.(Subagent 1)
-
[38]
The person named Martin from Aragon isMartin the Humane, who died in the city ofBarcelona.(Subagent 2)
-
[39]
The Palau de la Generalitat, located in Barcelona, was constructed in the15th century. (Subagent 3) Prediction:15th century (Exact match) Total duration:22.8 sLLM calls:13 Input tokens:9,620Output tokens:1,373Total tokens:10,993 27
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.