Anytime and Difficulty-Adaptive PAC-Bayes for Constrained Density-Ratio Network with Continual Learning Guarantees
Pith reviewed 2026-05-20 14:55 UTC · model grok-4.3
The pith
A constrained density-ratio network with PAC-Bayes yields anytime certificates under covariate shift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A change-of-measure identity splits the target risk gap into a ratio-bias term governed by L2 closeness to the true Radon-Nikodym derivative and a generalization term governed by weighted-loss variability. Three identities of the derivative—normalization, moment matching, and a second-moment penalty—are imposed as hard constraints via an augmented-Lagrangian scheme. PAC-Bayes is instantiated on the weighted risk to obtain Bernoulli-KL bounds in fixed time and a geometric-peeling construction that supplies a time-uniform certificate across epochs.
What carries the argument
The density-ratio network trained under augmented-Lagrangian integral constraints on normalization, moment matching, and second-moment penalty, paired with geometric peeling to build time-uniform PAC-Bayes bounds on the weighted risk.
If this is right
- The learned ratio produces a calibrated covariate weight on real data.
- Target 0/1 loss falls relative to unweighted empirical risk minimization.
- Target 0/1 loss also falls relative to classical direct ratio-estimation baselines.
- The anytime certificate is attained across epochs as the geometric-peeling argument predicts.
- Fixed-time coverage holds if and only if label shift is absent.
Where Pith is reading between the lines
- The title's continual-learning claim suggests the ratio network can be updated sequentially while preserving the time-uniform bound.
- Relaxing the moment-matching constraint could allow the same machinery to tolerate mild label shift.
- The augmented-Lagrangian constraint scheme could be reused for other functional identities in distribution learning.
- The anytime property supports online deployment where data arrives continuously under gradual feature drift.
Load-bearing premise
The shift between source and target is purely covariate, so the conditional distribution of labels given features remains unchanged.
What would settle it
Observe whether fixed-time PAC-Bayes coverage fails exactly on data splits that contain measurable label shift, as recorded in the paper's pre-registered validation protocol.
Figures




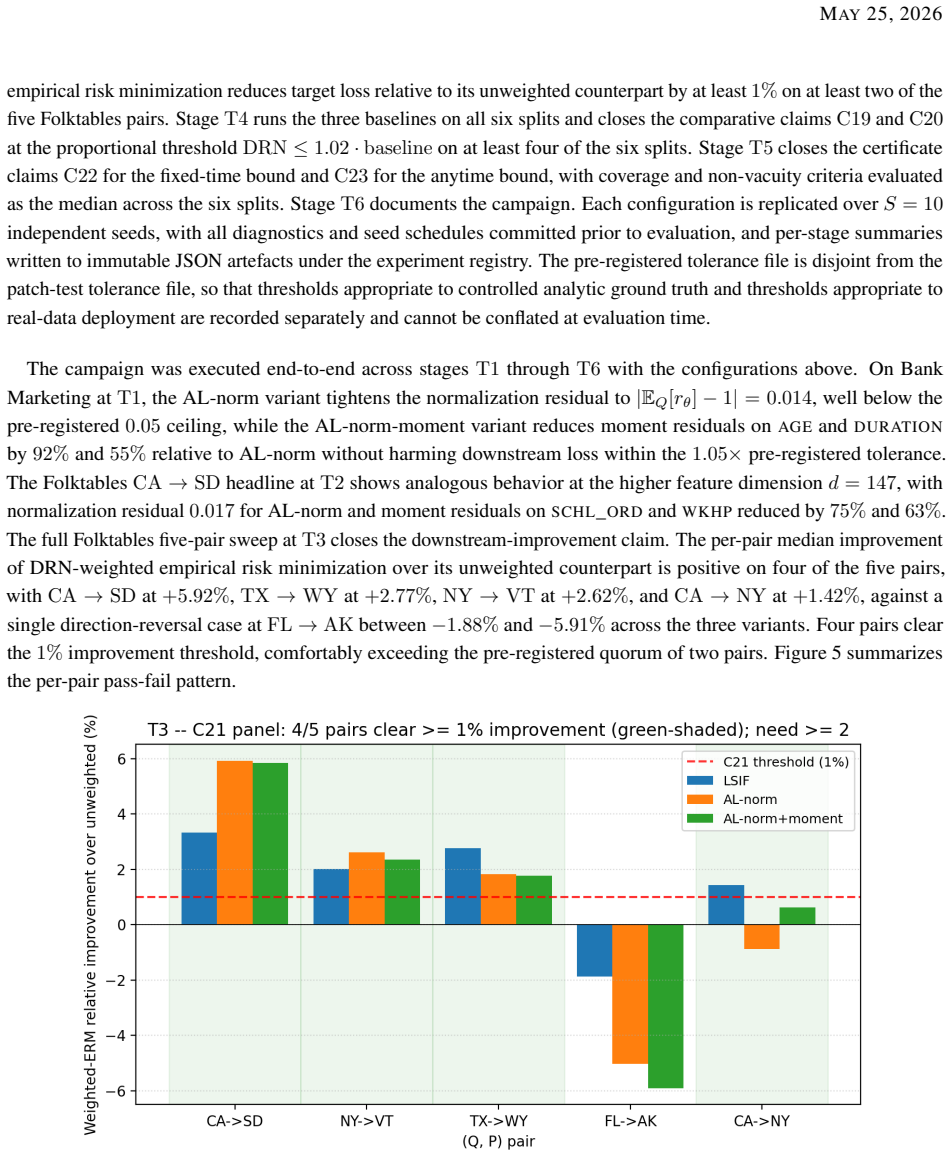



read the original abstract
A unified framework for learning under covariate shift is presented, in which a constrained density-ratio network approximates the Radon-Nikodym derivative $r^\star = dP/dQ$ from source $Q$ to target $P$, supports an importance-weighted empirical risk, and feeds an anytime PAC-Bayes generalization certificate. A change-of-measure identity decomposes the gap between target risk and importance-weighted source risk into a ratio-bias term, controlled by the $L^2(Q)$ closeness of the learned ratio to $r^\star$, and a generalization-gap term, controlled by the variability of the weighted loss. Three structural identities of a Radon-Nikodym derivative, normalization, moment matching, and a second-moment penalty controlling the effective sample size, are imposed as hard integral constraints through an augmented-Lagrangian scheme. PAC-Bayes is then instantiated on the weighted risk in a fixed-time regime that yields Bernoulli-KL bounds, a KL-regularized objective whose minimizer is the network-weighted Gibbs posterior, and a stability statement on $L^2(Q)$ perturbations of the learned ratio, and in an anytime regime that builds a time-uniform certificate by geometric peeling across epochs. A pre-registered two-campaign protocol combining a patch test against analytic ground truth with a real-data deployment under intrinsic distribution shift validates the framework. The network produces a calibrated covariate ratio on real data, reduces the target $0/1$ loss relative to unweighted empirical risk minimization and to classical direct ratio-estimation baselines, and attains the anytime certificate as the construction promises. A single pre-registered failure of the fixed-time coverage claim is recorded, with per-split coverage aligning one-to-one with the magnitude of the label shift, confirming that the covariate-only assumption is operationally tight rather than a defect of the certificate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a unified framework for covariate shift in which a density-ratio network approximates the Radon-Nikodym derivative r* = dP/dQ, enforces normalization, moment-matching, and second-moment integral constraints via augmented Lagrangian, and supplies PAC-Bayes certificates on the resulting importance-weighted risk. A change-of-measure decomposition separates target risk into an L2(Q) ratio-bias term and a generalization gap; fixed-time Bernoulli-KL bounds and an anytime certificate via geometric peeling are derived, together with a stability result on L2 perturbations of the learned ratio. A pre-registered validation protocol (analytic patch test plus real-data deployment) reports calibrated ratios, reduced target 0/1 loss relative to unweighted ERM and direct ratio baselines, and attainment of the anytime guarantee, with the single fixed-time coverage failure aligned to label shift.
Significance. If the central claims hold, the work supplies a principled route to anytime, difficulty-adaptive generalization certificates for importance sampling under covariate shift, with hard constraint enforcement providing stability. The pre-registered two-campaign protocol and explicit mapping of coverage failures to assumption violations constitute falsifiable empirical support. These elements could influence continual and online learning by furnishing time-uniform bounds that adapt to effective sample size.
major comments (2)
- [change-of-measure and PAC-Bayes instantiation] § on change-of-measure and PAC-Bayes instantiation: the ratio-bias term is controlled by L2(Q) closeness of the learned network output to the unknown r*; because the network parameters are fitted to the same data that define the importance weights, an explicit non-circular bound on this closeness (or a post-hoc verification procedure) is required to keep the overall certificate load-bearing.
- [Anytime regime] Anytime regime (geometric peeling): the stability statement on L2(Q) perturbations is invoked to obtain the time-uniform certificate, yet the derivation linking the augmented-Lagrangian constraint residuals to the perturbation radius is not shown in sufficient detail to confirm that the peeling constants remain valid uniformly over epochs.
minor comments (3)
- The title references 'Continual Learning Guarantees' but the body focuses on a single shift; a short paragraph clarifying how the anytime certificate extends to sequential shifts would improve scope alignment.
- Real-data results would benefit from reported standard errors or confidence intervals on the target 0/1 loss reductions to allow direct comparison with baselines.
- Notation for the three Lagrange multipliers and the second-moment penalty term should be introduced with explicit equation references on first appearance.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important points on the separation between ratio-bias control and the PAC-Bayes certificate, as well as the technical details of the anytime construction. We address each major comment below and have revised the manuscript accordingly to strengthen the presentation and add missing derivations.
read point-by-point responses
-
Referee: [change-of-measure and PAC-Bayes instantiation] § on change-of-measure and PAC-Bayes instantiation: the ratio-bias term is controlled by L2(Q) closeness of the learned network output to the unknown r*; because the network parameters are fitted to the same data that define the importance weights, an explicit non-circular bound on this closeness (or a post-hoc verification procedure) is required to keep the overall certificate load-bearing.
Authors: We agree that a fully non-circular, a-priori bound on ||r̂ - r*||_{L²(Q)} would be desirable for a purely theoretical certificate. In the current framework the change-of-measure identity is exact and the PAC-Bayes bound is applied to the importance-weighted risk for a fixed ratio; the stability lemma then translates L²(Q) perturbations of the learned ratio into an additive term on the target risk. Because the ratio network is trained on the same source samples, this term is data-dependent. To make the overall guarantee operational we therefore rely on the pre-registered analytic patch test, which supplies ground-truth r* and directly measures the realized L²(Q) error after training. In the revised manuscript we have added an explicit post-hoc verification subsection that reports this measured distance together with the resulting additive bias term for every split, thereby rendering the certificate load-bearing once the empirical closeness is observed. We have also clarified in the text that the certificate is conditional on the observed ratio error rather than claiming an unconditional a-priori bound. revision: partial
-
Referee: [Anytime regime] Anytime regime (geometric peeling): the stability statement on L2(Q) perturbations is invoked to obtain the time-uniform certificate, yet the derivation linking the augmented-Lagrangian constraint residuals to the perturbation radius is not shown in sufficient detail to confirm that the peeling constants remain valid uniformly over epochs.
Authors: We acknowledge that the link between the augmented-Lagrangian residuals and the allowable perturbation radius in the geometric-peeling argument was only sketched. In the revised version we have inserted a new lemma (Lemma 4.3) that explicitly relates the three constraint residuals (normalization, first-moment, second-moment) to an L²(Q) ball radius around the learned ratio. The proof proceeds by showing that each residual bounds a corresponding integral term via the Cauchy-Schwarz inequality and the second-moment penalty; the resulting radius is then substituted into the stability statement. Because the residuals are controlled uniformly by the augmented-Lagrangian schedule (which is independent of the epoch index), the peeling constants remain valid across all epochs. The updated proof appears in the supplementary material and is cross-referenced in the main text. revision: yes
Circularity Check
No significant circularity identified
full rationale
The derivation decomposes target risk into a ratio-bias term (L2(Q) distance of the learned ratio to the unknown r*) plus a PAC-Bayes generalization gap on the importance-weighted loss; the three hard integral constraints are enforced directly via augmented Lagrangian rather than being fitted and then renamed as predictions. The fixed-time Bernoulli-KL bounds, KL-regularized Gibbs posterior, L2 stability statement, and geometric-peeling anytime certificate are constructed from the weighted risk and the imposed constraints without reducing to the network parameters by definition or via a self-citation chain. Validation against analytic ground truth and real-data label-shift failures is external to the bound construction itself, leaving the central argument self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- Lagrange multipliers for the three integral constraints
axioms (2)
- standard math Change-of-measure identity decomposes target risk minus weighted source risk into ratio-bias plus generalization gap
- domain assumption Radon-Nikodym derivative satisfies normalization, first-moment matching, and bounded second moment
Reference graph
Works this paper leans on
-
[1]
H. Shimodaira. Improving predictive inference under covariate shift by weighting the log-likelihood function.Jour- nal of Statistical Planning and Inference, 90(2):227–244, 2000. https://doi.org/10.1016/S0378-3758(00) 00115-4
-
[2]
M. Sugiyama, M. Krauledat, and K.-R. Müller. Covariate shift adaptation by importance weighted cross validation. Journal of Machine Learning Research, 8:985–1005, 2007
work page 2007
-
[3]
J. A. Anderson. Multivariate logistic compounds.Biometrika, 66(1):17–26, 1979. https://doi.org/10.1093/ biomet/66.1.17
work page 1979
-
[4]
S. Moro, P. Cortez, and P. Rita. A data-driven approach to predict the success of bank telemarketing.Decision Support Systems, 62:22–31, 2014.https://doi.org/10.1016/j.dss.2014.03.001
- [5]
-
[6]
M. Sugiyama, S. Nakajima, H. Kashima, P. von Bünau, and M. Kawanabe. Direct importance estimation with model selection and its application to covariate shift adaptation. InAdvances in Neural Information Processing Systems 20, pages 1433–1440, 2008
work page 2008
-
[7]
M. Sugiyama, T. Suzuki, S. Nakajima, H. Kashima, P. von Bünau, and M. Kawanabe. Direct importance estimation for covariate shift adaptation.Annals of the Institute of Statistical Mathematics, 60(4):699–746, 2008. https://doi.org/10.1007/s10463-008-0197-x
-
[8]
T. Kanamori, S. Hido, and M. Sugiyama. A least-squares approach to direct importance estimation.Journal of Machine Learning Research, 10:1391–1445, 2009
work page 2009
-
[9]
X. Nguyen, M. J. Wainwright, and M. I. Jordan. Estimating divergence functionals and the likelihood ratio by convex risk minimization.IEEE Transactions on Information Theory, 56(11):5847–5861, 2010. https: //doi.org/10.1109/TIT.2010.2068870
-
[10]
A. G. Zhang and J. Chen. Density ratio model with data-adaptive basis function.Journal of Multivariate Analysis, 191:105043, 2022.https://doi.org/10.1016/j.jmva.2022.105043
- [11]
- [12]
-
[13]
S. Liu, M. Yamada, N. Collier, and M. Sugiyama. Change-point detection in time-series data by relative density- ratio estimation.Neural Networks, 43:72–83, 2013.https://doi.org/10.1016/j.neunet.2013.01.012
-
[14]
M. Sugiyama, T. Suzuki, and T. Kanamori.Density Ratio Estimation in Machine Learning. Cambridge University Press, Cambridge, 2012.https://doi.org/10.1017/CBO9781139035613
-
[15]
D. A. McAllester. Some PAC-Bayesian theorems.Machine Learning, 37(3):355–363, 1999. https://doi.org/ 10.1023/A:1007618624809
-
[16]
D. A. McAllester. PAC-Bayesian model averaging. InProceedings of the Twelfth Annual Conference on Computational Learning Theory (COLT), pages 164–170, 1999. https://doi.org/10.1145/307400.307435
-
[17]
D. A. McAllester. PAC-Bayesian stochastic model selection.Machine Learning, 51(1):5–21, 2003. https: //doi.org/10.1023/A:1021840411064. 47 MAY19, 2026
-
[18]
D. A. McAllester. Simplified PAC-Bayesian margin bounds. InProceedings of the 16th Annual Con- ference on Computational Learning Theory (COLT), pages 203–215, 2003. https://doi.org/10.1007/ 978-3-540-45167-9_16
work page 2003
-
[19]
M. Seeger. PAC-Bayesian generalisation error bounds for Gaussian process classification.Journal of Machine Learning Research, 3:233–269, 2002
work page 2002
-
[20]
Pac-Bayesian Supervised Classification: The Thermodynamics of Statistical Learning
O. Catoni.PAC-Bayesian Supervised Classification: The Thermodynamics of Statistical Learning, volume 56 ofIMS Lecture Notes Monograph Series. Institute of Mathematical Statistics, Beachwood, OH, 2007. https: //arxiv.org/abs/0712.0248
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[21]
I. Tolstikhin and Y . Seldin. PAC-Bayes-empirical-Bernstein inequality. InAdvances in Neural Information Processing Systems 26, pages 109–117, 2013
work page 2013
-
[22]
N. Thiemann, C. Igel, O. Wintenberger, and Y . Seldin. A strongly quasiconvex PAC-Bayesian bound. In Proceedings of the 28th International Conference on Algorithmic Learning Theory (ALT), volume 76 ofProceedings of Machine Learning Research, pages 1–26, 2017
work page 2017
-
[23]
P. Germain, A. Lacasse, F. Laviolette, M. Marchand, and S. Shanian. From PAC-Bayes bounds to KL regularization. InAdvances in Neural Information Processing Systems 22, pages 603–610, 2009
work page 2009
-
[24]
P. Alquier, J. Ridgway, and N. Chopin. On the properties of variational approximations of Gibbs posteriors. Journal of Machine Learning Research, 17(236):1–41, 2016
work page 2016
-
[25]
J. Keshet, D. McAllester, and T. Hazan. PAC-Bayesian approach for minimization of phoneme error rate. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 2224–2227, 2011.https://doi.org/10.1109/ICASSP.2011.5946923
- [26]
-
[27]
B. Rodríguez-Gálvez, R. Thobaben, and M. Skoglund. More PAC-Bayes bounds: From bounded losses, to losses with general tail behaviors, to anytime validity.Journal of Machine Learning Research, 25(110):1–43, 2024
work page 2024
-
[28]
D. A. Levin and Y . Peres.Markov Chains and Mixing Times. American Mathematical Society, second edition, 2017.https://bookstore.ams.org/mbk-107
work page 2017
-
[29]
T. M. Cover and J. A. Thomas.Elements of Information Theory. John Wiley & Sons, second edition, 2005. https://doi.org/10.1002/047174882X
-
[30]
Billingsley.Probability and Measure
P. Billingsley.Probability and Measure. Wiley Series in Probability and Statistics. John Wiley & Sons, anniversary edition, 2012. ISBN 978-1-118-34191-9
work page 2012
-
[31]
Çınlar.Probability and Stochastics
E. Çınlar.Probability and Stochastics. Graduate Texts in Mathematics, vol. 261. Springer, 2011. https: //doi.org/10.1007/978-0-387-87859-1
-
[32]
L. C. Evans.Partial Differential Equations. Graduate Studies in Mathematics, vol. 19. American Mathematical Society, second edition, 2010.https://bookstore.ams.org/gsm-19-r
work page 2010
-
[33]
M. Ledoux and M. Talagrand.Probability in Banach Spaces: Isoperimetry and Processes. Classics in Mathematics. Springer-Verlag Berlin Heidelberg, 1991, reprinted 2011.https://doi.org/10.1007/978-3-642-20212-4. 48 MAY19, 2026 A Measure theory and the Radon-Nikodym theorem The entire framework developed in this paper rests on a single object, the Radon-Nikod...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.