RadGenome-Anatomy: A Large-Scale Anatomy-Labeled Chest Radiograph Dataset via Physically Grounded Volumetric Projection
Pith reviewed 2026-05-20 13:17 UTC · model grok-4.3
The pith
Projecting 3D CT anatomy masks into 2D creates over 10 million reliable chest radiograph labels across 210 structures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
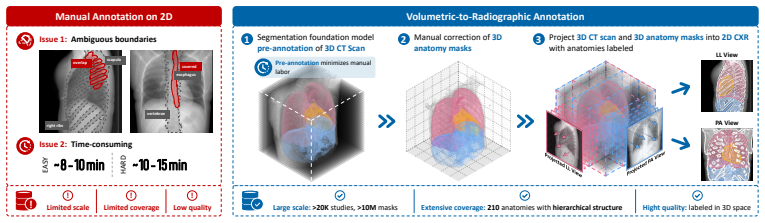
RadGenome-Anatomy is constructed by projecting large-scale 3D anatomical masks from CT volumes into 2D radiographic space through canonical radiographic geometry, resulting in over 10 million segmentation masks across 210 anatomical structures in 25,692 studies. Each 2D mask represents the physically grounded projected footprint of a volumetrically defined structure, allowing structures that overlap or become partially invisible in radiographs to remain spatially separable in the annotation process.
What carries the argument
Physically grounded volumetric projection of 3D anatomical masks from CT into 2D radiographic space, which allows annotation in volumetric space where overlapping structures stay separable and produces accurate 2D footprints.
If this is right
- The dataset enables research on geometric measurements as explicit evidence for chest radiograph interpretation.
- Models trained on it can predict structure-specific masks and derive clinical measurements.
- It supports high diagnostic accuracies such as 96.4% for cardiomegaly, 95.6% for kyphosis, and 89.2% for scoliosis.
- Labels cover structures that are overlapping, partially visible, or difficult to delineate directly on 2D images.
Where Pith is reading between the lines
- This projection technique might extend to other imaging modalities or body parts where 3D data is available to generate 2D labels.
- Large labeled datasets like this could accelerate development of automated diagnostic tools in radiology.
- Validation against independent expert annotations on projected images would strengthen confidence in the method's accuracy.
Load-bearing premise
The canonical radiographic geometry used for projection from CT volumes accurately reproduces the true 2D appearance of 3D anatomical structures in chest radiographs, including overlaps and partial visibilities.
What would settle it
A side-by-side comparison of the generated 2D masks with expert-drawn annotations on a held-out set of real chest radiographs, checking for mismatches in boundary placement or missed occluded structures.
Figures






read the original abstract
Anatomical structure labels for chest radiographs are essential for medical image segmentation and a broad range of downstream diagnostic tasks. However, annotating anatomy directly on 2D chest radiographs is labor-intensive and intrinsically ambiguous, as 3D anatomical structures are projected onto a single 2D plane where boundaries may overlap, be occluded, or appear only partially visible. Consequently, existing anatomy-labeled chest radiograph datasets remain limited in scale, anatomy coverage, and label reliability. To address these limitations, we introduce RadGenome-Anatomy, the largest anatomy-labeled chest radiograph dataset, containing over 10 million segmentation masks across 210 anatomical structures in 25,692 studies. It is constructed by projecting large-scale 3D anatomical masks from CT volumes into 2D radiographic space through canonical radiographic geometry. This shifts annotation from directly tracing uncertain 2D boundaries to defining anatomy in volumetric space, where structures that overlap or become partially invisible in radiographs remain spatially separable. As a result, each 2D mask represents the physically grounded projected footprint of a volumetrically defined structure. The scale and broad anatomical coverage of RadGenome-Anatomy, including structures that are overlapping, partially visible, or difficult to delineate directly, enable research on geometric measurements as explicit evidence for chest radiograph interpretation. We demonstrate this by training XAnatomy to predict structure-specific masks and derive clinically relevant measurements, achieving diagnostic accuracies of 96.4%, 95.6%, and 89.2% for cardiomegaly, kyphosis, and scoliosis, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RadGenome-Anatomy, the largest anatomy-labeled chest radiograph dataset, containing over 10 million segmentation masks across 210 anatomical structures in 25,692 studies. It is constructed by projecting large-scale 3D anatomical masks from CT volumes into 2D radiographic space through canonical radiographic geometry, shifting annotation to volumetric space to handle overlaps and partial visibility. The authors demonstrate utility by training XAnatomy to predict structure-specific masks and derive clinical measurements, reporting diagnostic accuracies of 96.4%, 95.6%, and 89.2% for cardiomegaly, kyphosis, and scoliosis respectively.
Significance. If the projected 2D labels prove accurate, the dataset would represent a substantial advance by providing unprecedented scale and coverage for training segmentation models and enabling geometric measurements as evidence for radiograph interpretation. The volumetric-to-2D projection approach addresses a key limitation of direct 2D annotation for overlapping or partially visible structures.
major comments (3)
- [Abstract] Abstract and dataset construction description: The central claim that the 2D masks are 'physically grounded' and reliably represent structures (including overlaps and partial visibility) is not supported by any quantitative validation of projection accuracy, error metrics, or comparison to real 2D annotations or existing datasets.
- [Dataset construction] Dataset construction pipeline: The projection uses 'canonical radiographic geometry' without any described registration, pose normalization, or adjustment for systematic differences between CT acquisitions (typically supine) and chest X-ray protocols (upright PA, breathing phase, arm position, source-to-detector distance), which risks systematic boundary errors in the projected masks for structures whose 3D extent varies with viewpoint.
- [Experiments / Results] Demonstration experiments: The reported accuracies (96.4% for cardiomegaly etc.) are obtained by training on the projected labels, but without independent validation of label fidelity (e.g., against manual 2D annotations or multi-rater agreement), it is unclear whether performance reflects true anatomical correspondence or projection-induced artifacts.
minor comments (2)
- [Abstract] Clarify whether the 25,692 studies correspond to unique patients or include follow-up scans, and provide basic demographics or acquisition parameter statistics for the source CT volumes.
- Add a figure or diagram explicitly showing the projection geometry parameters and an example of how overlapping 3D structures map to 2D masks to improve readability of the method.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which highlight important aspects of validation and methodological detail. We address each major comment point by point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and dataset construction description: The central claim that the 2D masks are 'physically grounded' and reliably represent structures (including overlaps and partial visibility) is not supported by any quantitative validation of projection accuracy, error metrics, or comparison to real 2D annotations or existing datasets.
Authors: The physical grounding of the 2D masks follows directly from applying a standard radiographic projection model to 3D volumetric segmentations, which inherently encodes overlaps and partial visibility as the projected footprint of each structure. We acknowledge that the current manuscript does not include quantitative error metrics or direct comparisons to manual 2D annotations. In the revised version we will add a dedicated validation subsection that reports projection accuracy on a subset of cases with available expert 2D annotations, including Dice coefficients and boundary error statistics. revision: yes
-
Referee: [Dataset construction] Dataset construction pipeline: The projection uses 'canonical radiographic geometry' without any described registration, pose normalization, or adjustment for systematic differences between CT acquisitions (typically supine) and chest X-ray protocols (upright PA, breathing phase, arm position, source-to-detector distance), which risks systematic boundary errors in the projected masks for structures whose 3D extent varies with viewpoint.
Authors: The pipeline employs a canonical radiographic geometry with standard source-to-detector distance and projection parameters as described in the methods. We agree that unaccounted differences in patient pose and breathing phase between CT and upright chest radiographs represent a potential source of systematic error. We will expand the dataset construction section with explicit parameter values and add a limitations paragraph discussing these acquisition differences and their possible impact on boundary accuracy for deformable structures. revision: partial
-
Referee: [Experiments / Results] Demonstration experiments: The reported accuracies (96.4% for cardiomegaly etc.) are obtained by training on the projected labels, but without independent validation of label fidelity (e.g., against manual 2D annotations or multi-rater agreement), it is unclear whether performance reflects true anatomical correspondence or projection-induced artifacts.
Authors: The reported diagnostic accuracies demonstrate downstream utility of the projected labels for deriving geometric measurements. We concur that an independent check against manual 2D annotations would help separate true anatomical fidelity from projection artifacts. In the revision we will include a limited validation experiment on a held-out subset, comparing model predictions and projected labels against radiologist-drawn 2D masks and reporting agreement metrics. revision: yes
Circularity Check
Dataset construction via external CT projection is self-contained with no circular reduction
full rationale
The paper's central claim is the generation of 2D anatomy masks by projecting 3D CT-derived masks into radiographic space using canonical geometry. This is a direct forward transformation from independent volumetric inputs; no equations, fitted parameters, or self-citations are shown that would make the output equivalent to the inputs by construction. The method relies on external CT volumes and standard projection operators rather than any self-referential definition or renamed empirical fit. The derivation chain is therefore non-circular and externally grounded.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Canonical radiographic geometry accurately maps 3D CT structures to 2D projections while preserving separability for overlapping anatomy.
Reference graph
Works this paper leans on
-
[1]
Hybrid intelligence in medical image segmentation.Scientific Reports, 15(1):41200, 2025
Namia Mohamed Ali, Solomon Sunday Oyelere, Nitya Jitani, Rosy Sarmah, and Simon Andrew. Hybrid intelligence in medical image segmentation.Scientific Reports, 15(1):41200, 2025
work page 2025
-
[2]
MAIRA-2: grounded radiology report generation.arXiv preprint arXiv:2406.04449,
Shruthi Bannur, Kenza Bouzid, Daniel C Castro, Anton Schwaighofer, Anja Thieme, Sam Bond-Taylor, Maximilian Ilse, Fernando Pérez-García, Valentina Salvatelli, Harshita Sharma, et al. Maira-2: Grounded radiology report generation.arXiv preprint arXiv:2406.04449, 2024
-
[3]
Towards robust computation of cardiothoracic ratio from chest x-ray
Matilde Bodritti, Adriyana Danudibroto, and Jan Aelterman. Towards robust computation of cardiothoracic ratio from chest x-ray. InMedical Imaging with Deep Learning (MIDL), 2023
work page 2023
-
[4]
Swin-unet: Unet-like pure transformer for medical image segmentation
Hu Cao, Yueyue Wang, Joy Chen, Dongsheng Jiang, Xiaopeng Zhang, Qi Tian, and Manning Wang. Swin-unet: Unet-like pure transformer for medical image segmentation. InEuropean conference on computer vision, pages 205–218. Springer, 2022
work page 2022
-
[5]
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
Jieneng Chen, Yongyi Lu, Qihang Yu, Xiangde Luo, Ehsan Adeli, Yan Wang, Le Lu, Alan L Yuille, and Yuyin Zhou. Transunet: Transformers make strong encoders for medical image segmentation.arXiv preprint arXiv:2102.04306, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, Jianye Hou, and Benyou Wang. Huatuogpt-o1, towards medical complex reasoning with llms.arXiv preprint arXiv:2412.18925, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Encoder-decoder with atrous separable convolution for semantic image segmentation
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), pages 801–818, 2018
work page 2018
-
[8]
Masked-attention mask transformer for universal image segmentation
Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexander Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1290–1299, 2022
work page 2022
-
[9]
Andres Diaz-Pinto, Sachidanand Alle, Vishwesh Nath, Yucheng Tang, Alvin Ihsani, Muhammad Asad, Fernando Pérez-García, Pritesh Mehta, Wenqi Li, Mona Flores, et al. Monai label: A framework for ai-assisted interactive labeling of 3d medical images.Medical Image Analysis, 95:103207, 2024
work page 2024
-
[10]
Measures of the amount of ecologic association between species.Ecology, 26:297–302, 1945
Lee Raymond Dice. Measures of the amount of ecologic association between species.Ecology, 26:297–302, 1945. URLhttps://api.semanticscholar.org/CorpusID:53335638
work page 1945
-
[11]
Nicolás Gaggion, Candelaria Mosquera, Lucas Mansilla, Julia Mariel Saidman, Martina Aineseder, Diego H. Milone, and Enzo Ferrante. Chexmask: A large-scale dataset of anatomical segmentation masks for multi-center chest x-ray images.Scientific Data, 11(1):511, 2024. doi: 10.1038/s41597-024-03358-1
-
[12]
Nicolás Gaggion, Candelaria Mosquera, Lucas Mansilla, Julia Mariel Saidman, Martina Aineseder, Diego H Milone, and Enzo Ferrante. Chexmask: a large-scale dataset of anatomical segmentation masks for multi-center chest x-ray images.Scientific Data, 11(1):511, 2024
work page 2024
-
[13]
arXiv preprint arXiv:2403.17834 , year=
Ibrahim Ethem Hamamci, Sezgin Er, Chenyu Wang, Furkan Almas, Ayse Gulnihan Simsek, Sevval Nil Esirgun, Irem Dogan, Omer Faruk Durugol, Benjamin Hou, Suprosanna Shit, et al. Developing generalist foundation models from a multimodal dataset for 3d computed tomography.arXiv preprint arXiv:2403.17834, 2024
-
[14]
Laurens Hogeweg, Clara I. Sánchez, Pim A. de Jong, and Mathilde van Ginneken. Clavicle segmentation in chest radiographs.Medical Image Analysis, 16(8):1490–1502, 2012. doi: 10.1016/j.media.2012.06.009
-
[15]
Fabian Isensee, Paul F Jaeger, Simon AA Kohl, Jens Petersen, and Klaus H Maier-Hein. nnu-net: a self-configuring method for deep learning-based biomedical image segmentation.Nature methods, 18(2):203–211, 2021
work page 2021
-
[16]
Paul Jaccard. Distribution de la flore alpine dans le bassin des dranses et dans quelques régions voisines.Bull Soc Vaudoise Sci Nat, 37:241–272, 1901. 10
work page 1901
-
[17]
Two public chest x-ray datasets for computer-aided screening of pulmonary diseases
Stefan Jaeger, Sema Candemir, Sameer Antani, Yì-Xiáng J Wáng, Pu-Xuan Lu, and George Thoma. Two public chest x-ray datasets for computer-aided screening of pulmonary diseases. Quantitative imaging in medicine and surgery, 4(6):475, 2014
work page 2014
-
[18]
Abbas Jafar, Muhammad Talha Hameed, Nadeem Akram, Umer Waqas, Hyung Seok Kim, and Rizwan Ali Naqvi. Cardionet: Automatic semantic segmentation to calculate the cardiothoracic ratio for cardiomegaly and other chest diseases.Journal of Personalized Medicine, 12(6):988,
-
[19]
doi: 10.3390/jpm12060988
-
[20]
Alistair E. W. Johnson, Tom J. Pollard, Nathaniel R. Greenbaum, Matthew P. Lungren, Chih ying Deng, Yifan Peng, Zhiyong Lu, Roger G. Mark, Seth J. Berkowitz, and Steven Horng. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports. Scientific Data, 6:317, 2019. doi: 10.1038/s41597-019-0322-0
-
[21]
Pointrend: Image segmentation as rendering
Alexander Kirillov, Yuxin Wu, Kaiming He, and Ross Girshick. Pointrend: Image segmentation as rendering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9799–9808, 2020
work page 2020
-
[22]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
work page 2023
-
[23]
Yuxiang Lai, Jike Zhong, Ming Li, Shitian Zhao, Yuheng Li, Konstantinos Psounis, and Xiaofeng Yang. Med-r1: Reinforcement learning for generalizable medical reasoning in vision-language models.IEEE Transactions on Medical Imaging, 2026
work page 2026
-
[24]
U-kan makes strong backbone for medical image segmentation and generation
Chenxin Li, Xinyu Liu, Wuyang Li, Cheng Wang, Hengyu Liu, Yifan Liu, Zhen Chen, and Yixuan Yuan. U-kan makes strong backbone for medical image segmentation and generation. InProceedings of the AAAI conference on artificial intelligence, volume 39, pages 4652–4660, 2025
work page 2025
-
[25]
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36: 28541–28564, 2023
work page 2023
-
[26]
U-Mamba: Enhancing Long-range Dependency for Biomedical Image Segmentation
Jun Ma, Feifei Li, and Bo Wang. U-mamba: Enhancing long-range dependency for biomedical image segmentation.arXiv preprint arXiv:2401.04722, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Anatomy-driven pathology detection on chest x-rays
Philip Müller, Felix Meissen, Johannes Brandt, Georgios Kaissis, and Daniel Rueckert. Anatomy-driven pathology detection on chest x-rays. InMedical Image Computing and Computer Assisted Intervention – MICCAI 2023, pages 57–66, 2023
work page 2023
-
[28]
Hoang C Nguyen, Tung T Le, Hieu H Pham, and Ha Q Nguyen. Vindr-ribcxr: A benchmark dataset for automatic segmentation and labeling of individual ribs on chest x-rays.arXiv preprint arXiv:2107.01327, 2021
-
[29]
Error metrics for quantitative evaluation of medical image segmentation
Wiro J Niessen, Carolien J Bouma, Koen L Vincken, and Max A Viergever. Error metrics for quantitative evaluation of medical image segmentation. InPerformance characterization in computer vision, pages 275–284. Springer, 2000
work page 2000
-
[30]
Stanislav Nikolov, Sam Blackwell, Alexei Zverovitch, Ruheena Mendes, Michelle Livne, Jeffrey De Fauw, Yojan Patel, Clemens Meyer, Harry Askham, Bernardino Romera-Paredes, et al. Deep learning to achieve clinically applicable segmentation of head and neck anatomy for radiotherapy.arXiv preprint arXiv:1809.04430, 2018
-
[31]
Ilze Oshina and Janis Spigulis. Beer–lambert law for optical tissue diagnostics: current state of the art and the main limitations.Journal of biomedical optics, 26(10):100901–100901, 2021
work page 2021
-
[32]
S-sam: Svd-based fine-tuning of segment anything model for medical image segmentation
Jay N Paranjape, Shameema Sikder, S Swaroop Vedula, and Vishal M Patel. S-sam: Svd-based fine-tuning of segment anything model for medical image segmentation. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 720–730. Springer, 2024. 11
work page 2024
-
[33]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
work page 2015
-
[34]
Jiacheng Ruan, Jincheng Li, and Suncheng Xiang. Vm-unet: Vision mamba unet for medical image segmentation.ACM Transactions on Multimedia Computing, Communications and Applications, 2024
work page 2024
-
[35]
Constantin Seibold, Simon Reiss, M. Saquib Sarfraz, Matthias A. Fink, Victoria Mayer, Jan Sellner, Moon Sung Kim, Klaus H. Maier-Hein, Jens Kleesiek, and Rainer Stiefelhagen. De- tailed annotations of chest x-rays via ct projection for report understanding.arXiv preprint arXiv:2210.03416, 2022
-
[36]
Fink, Moon Kim, Simon Reiss, Ken Herrmann, Jens Kleesiek, and Rainer Stiefelhagen
Constantin Seibold, Alexander Jaus, Matthias A. Fink, Moon Kim, Simon Reiss, Ken Herrmann, Jens Kleesiek, and Rainer Stiefelhagen. Accurate fine-grained segmentation of human anatomy in radiographs via volumetric pseudo-labeling.arXiv preprint arXiv:2306.03934, 2023
-
[37]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Junji Shiraishi, Shigehiko Katsuragawa, Junpei Ikezoe, Tsuneo Matsumoto, Takeshi Kobayashi, Ken-ichi Komatsu, Mitate Matsui, Hiroshi Fujita, Yoshie Kodera, and Kunio Doi. Development of a digital image database for chest radiographs with and without a lung nodule: receiver operating characteristic analysis of radiologists’ detection of pulmonary nodules.A...
work page 2000
-
[39]
Abdel Aziz Taha and Allan Hanbury. Metrics for evaluating 3d medical image segmentation: analysis, selection, and tool.BMC medical imaging, 15(1):29, 2015
work page 2015
-
[40]
Interactive and explainable region-guided radiology report generation
Tim Tanida, Philip Müller, Georgios Kaissis, and Daniel Rueckert. Interactive and explainable region-guided radiology report generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[41]
Unext: Mlp-based rapid medical image segmentation network
Jeya Maria Jose Valanarasu and Vishal M Patel. Unext: Mlp-based rapid medical image segmentation network. InInternational conference on medical image computing and computer- assisted intervention, pages 23–33. Springer, 2022
work page 2022
-
[42]
Bram van Ginneken, Mikkel B. Stegmann, and Marco Loog. Segmentation of anatomical structures in chest radiographs using supervised methods: A comparative study on a public database.Medical Image Analysis, 10(1):19–40, 2006. doi: 10.1016/j.media.2005.02.002
-
[43]
Seaformer: Squeeze-enhanced axial transformer for mobile semantic segmentation
Qiang Wan, Zilong Huang, Jiachen Lu, Gang Yu, and Li Zhang. Seaformer: Squeeze-enhanced axial transformer for mobile semantic segmentation. InThe eleventh international conference on learning representations, 2023
work page 2023
-
[44]
Medical sam adapter: Adapting segment anything model for medical image segmentation
Junde Wu, Ziyue Wang, Mingxuan Hong, Wei Ji, Huazhu Fu, Yanwu Xu, Min Xu, and Yueming Jin. Medical sam adapter: Adapting segment anything model for medical image segmentation. Medical image analysis, 102:103547, 2025
work page 2025
-
[45]
Unified perceptual parsing for scene understanding
Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, and Jian Sun. Unified perceptual parsing for scene understanding. InProceedings of the European conference on computer vision (ECCV), pages 418–434, 2018
work page 2018
-
[46]
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transformers.Advances in neural information processing systems, 34:12077–12090, 2021
work page 2021
-
[47]
Pidnet: A real-time semantic segmentation network inspired by pid controllers
Jiacong Xu, Zixiang Xiong, and Shankar P Bhattacharyya. Pidnet: A real-time semantic segmentation network inspired by pid controllers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19529–19539, 2023. 12
work page 2023
-
[48]
Topformer: Token pyramid transformer for mobile semantic segmentation
Wenqiang Zhang, Zilong Huang, Guozhong Luo, Tao Chen, Xinggang Wang, Wenyu Liu, Gang Yu, and Chunhua Shen. Topformer: Token pyramid transformer for mobile semantic segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12083–12093, 2022
work page 2022
-
[49]
Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Jiayu Lei, Ya Zhang, Yanfeng Wang, and Weidi Xie. Radgenome-chest ct: A grounded vision-language dataset for chest ct analysis.arXiv preprint arXiv:2404.16754, 2024
-
[50]
Ziheng Zhao, Yao Zhang, Chaoyi Wu, Xiaoman Zhang, Xiao Zhou, Ya Zhang, Yanfeng Wang, and Weidi Xie. Large-vocabulary segmentation for medical images with text prompts.NPJ Digital Medicine, 8(1):566, 2025
work page 2025
-
[51]
Zongwei Zhou, Md Mahfuzur Rahman Siddiquee, Nima Tajbakhsh, and Jianming Liang. Unet++: A nested u-net architecture for medical image segmentation. InInternational workshop on deep learning in medical image analysis, pages 3–11. Springer, 2018. 13 A Radiographic Transferability and Label Quality We assess whether anatomy supervision fromRadGenome-Anatomyt...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.