HL-OutPaint: Coarse-to-Fine Video Outpainting for High-Resolution Long-Range Videos
Pith reviewed 2026-05-20 13:28 UTC · model grok-4.3
The pith
Separating global structure modeling from fine-grained synthesis enables stable coherent outpainting for large spatial expansions in long video sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
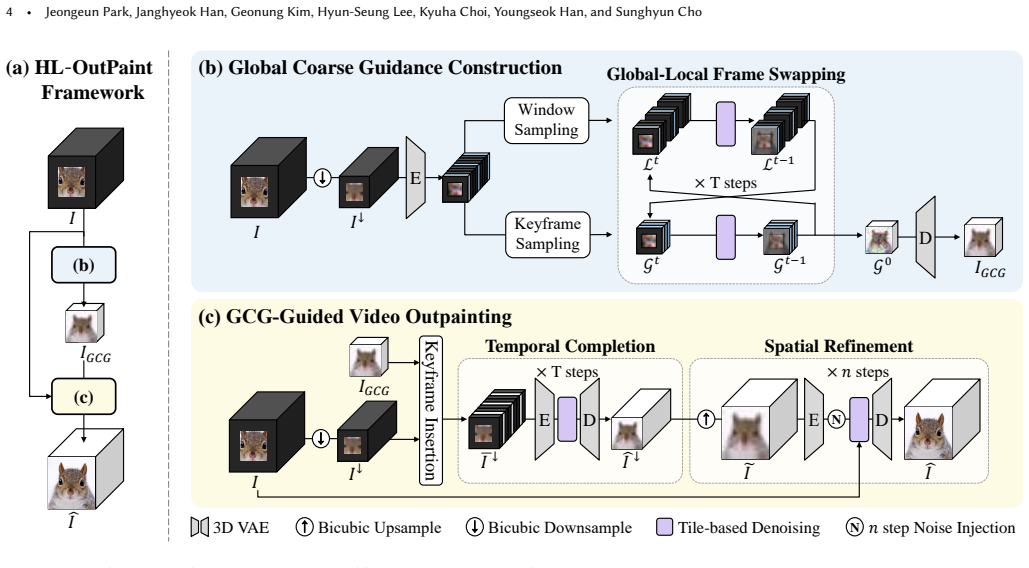
By constructing Global Coarse Guidance as a low-resolution representation through a novel global-local frame swapping mechanism that couples sparse global keyframes with local temporal windows, the method encodes both long-term structural consistency and short-term temporal dynamics in a unified way. This representation then guides the high-resolution outpainting stage to produce spatially detailed and temporally consistent content, achieving stable generation for large spatial expansion and long video sequences.
What carries the argument
Global Coarse Guidance (GCG), a low-resolution video representation constructed via global-local frame swapping that couples sparse global keyframes with local temporal windows to encode structure and motion for guiding later synthesis.
If this is right
- The two-stage separation supports coherent results even when spatial expansion is large and sequences are long.
- GCG provides a unified low-resolution encoding that maintains both distant structural consistency and nearby motion continuity.
- High-resolution synthesis guided by GCG avoids the global inconsistency problems seen in direct high-resolution approaches.
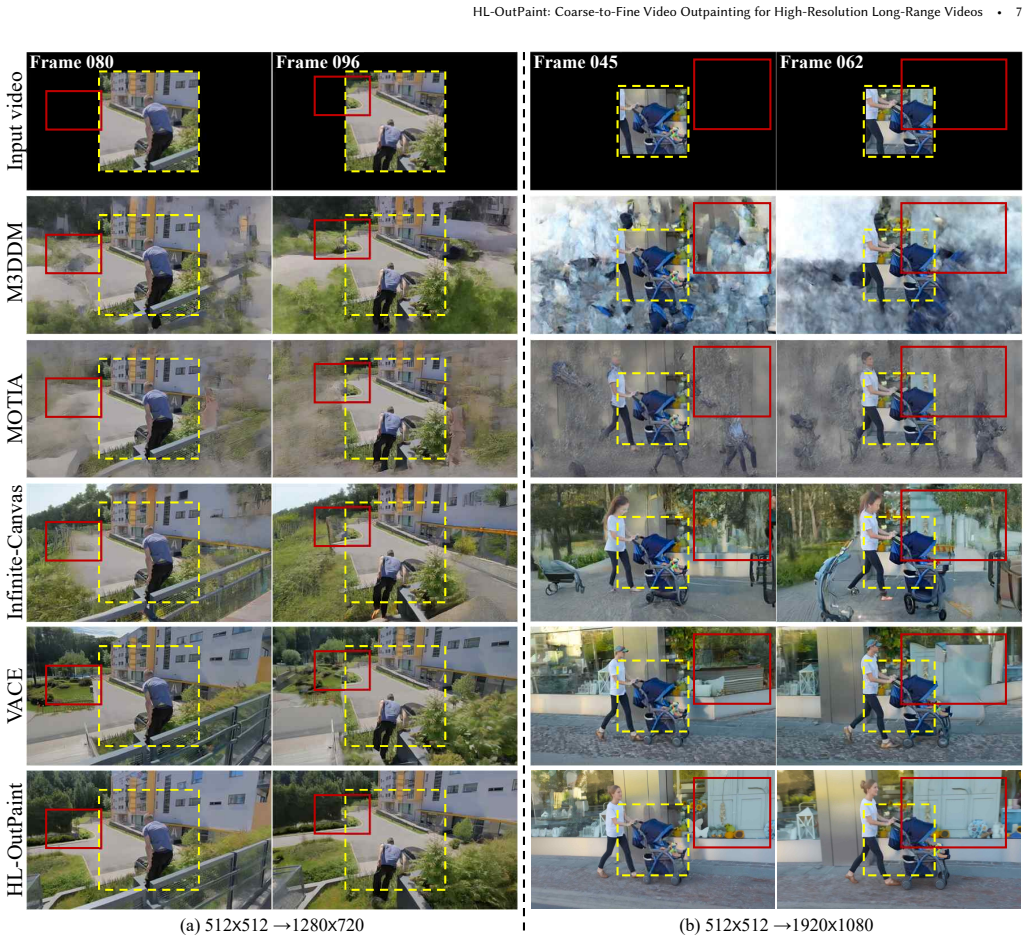
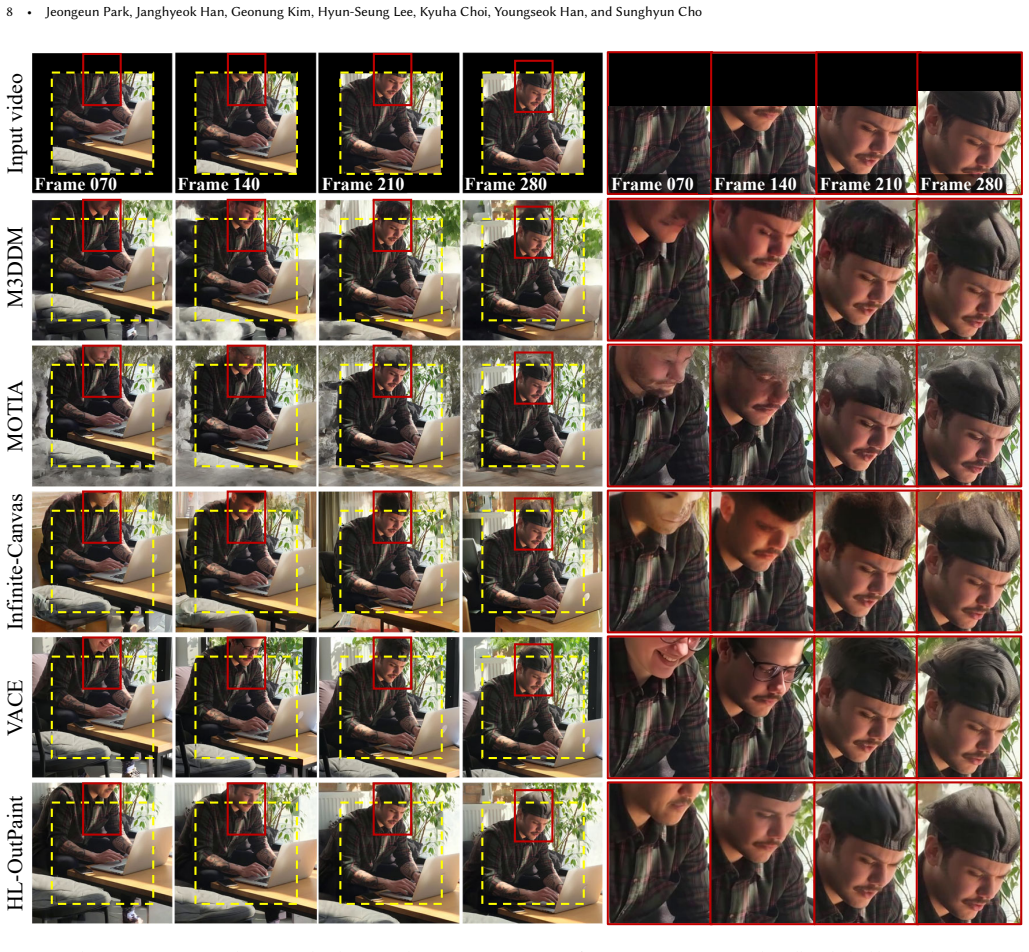
- The framework outperforms prior methods on challenging cases that combine wide extrapolation with extended video lengths.
Where Pith is reading between the lines
- The same coarse guidance idea could be tested on video tasks such as future frame prediction where long-range consistency is also needed.
- Removing the swapping mechanism and measuring the rise in artifacts would quantify how much of the performance depends on that specific construction step.
- Applying the global-local exchange idea to image outpainting might help with large single-frame extrapolations that lack temporal cues.
Load-bearing premise
The global-local frame swapping mechanism in building Global Coarse Guidance encodes long-term structural consistency and short-term temporal dynamics without introducing artifacts that propagate into the high-resolution stage.
What would settle it
Outpainting the same long sequences with large spatial expansion both with and without the frame swapping step in GCG construction, then checking whether the no-swapping version produces visibly more temporal drift or structural inconsistencies, would test whether that mechanism is necessary for the claimed stability.
Figures






read the original abstract
Video outpainting generates plausible visual content beyond the original spatial extent of a video, playing a key role in adapting videos to diverse display formats. To support such use cases, it must enable large spatial extrapolation over long sequences. However, most existing methods address only one of these challenges or lack explicit mechanisms for ensuring global spatio-temporal consistency, leading to notable limitations. In this paper, we propose HL-OutPaint, a high-resolution video outpainting framework for long sequences. Our approach follows a coarse-to-fine strategy with a two-stage pipeline. We first construct Global Coarse Guidance (GCG), a low-resolution representation that captures global structure and dominant motion across the video. Unlike naive downsampling, GCG is built via a novel global-local frame swapping mechanism that couples sparse global keyframes with local temporal windows and exchanges information during sampling. This enables GCG to encode both long-term structural consistency and short-term temporal dynamics in a unified representation. Guided by this representation, HL-OutPaint then performs high-resolution outpainting to generate spatially detailed and temporally consistent content. By separating global structure modeling from fine-grained synthesis, our framework achieves stable, coherent generation for large spatial expansion and long video sequences. Extensive experiments show that HL-OutPaint outperforms existing methods in challenging scenarios involving wide spatial extrapolation and long video sequences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HL-OutPaint, a coarse-to-fine two-stage framework for high-resolution video outpainting on long sequences. It first builds Global Coarse Guidance (GCG) via a novel global-local frame swapping mechanism that couples sparse global keyframes with local temporal windows during sampling, then uses this low-resolution representation to guide spatially detailed and temporally coherent high-resolution synthesis. The central claim is that separating global structure modeling from fine-grained synthesis enables stable outpainting for large spatial expansions and extended video lengths, outperforming prior methods.
Significance. If the GCG construction and separation premise hold under empirical scrutiny, the work could meaningfully advance video outpainting by addressing the combined challenges of wide spatial extrapolation and long-range temporal consistency that most existing approaches handle only partially. The coarse-to-fine strategy is a clear conceptual strength; credit is given for the explicit mechanism to encode both long-term structure and short-term dynamics in a unified low-res representation.
major comments (2)
- [Abstract and §3] Abstract and §3 (GCG construction): The claim that the global-local frame swapping successfully encodes long-term structural consistency and short-term temporal dynamics without residual inconsistencies that propagate to the high-resolution stage is load-bearing for the separation premise. The manuscript should provide a concrete analysis (e.g., via temporal alignment metrics or drift measurements) showing that information exchange during sampling is symmetric and constrained enough to prevent uncorrectable artifacts, as any drift would directly undermine the fine stage's ability to resolve it.
- [§4] §4 (Experiments): The abstract asserts outperformance in wide spatial extrapolation and long sequences, yet the provided description contains no quantitative results, ablation studies on the frame-swapping component, or error analysis. Tables reporting metrics across varying expansion ratios and sequence lengths are needed to substantiate that the GCG stage does not introduce uncorrectable inconsistencies.
minor comments (1)
- A diagram or pseudocode for the global-local frame swapping process would improve clarity of the information exchange during sampling.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the presentation of the GCG mechanism and the supporting experiments.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (GCG construction): The claim that the global-local frame swapping successfully encodes long-term structural consistency and short-term temporal dynamics without residual inconsistencies that propagate to the high-resolution stage is load-bearing for the separation premise. The manuscript should provide a concrete analysis (e.g., via temporal alignment metrics or drift measurements) showing that information exchange during sampling is symmetric and constrained enough to prevent uncorrectable artifacts, as any drift would directly undermine the fine stage's ability to resolve it.
Authors: We agree that explicit quantitative validation of the symmetry and bounded drift in the global-local frame swapping is important to support the separation premise. The mechanism alternates information exchange between sparse global keyframes and local temporal windows in a balanced, iterative manner during sampling, which is intended to keep inconsistencies minimal and correctable. In the revised manuscript we will add a dedicated analysis subsection in §3 that reports temporal alignment metrics (optical-flow consistency and keyframe drift) and drift measurements over extended sequences, confirming that residual inconsistencies remain within bounds that the high-resolution stage can resolve. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract asserts outperformance in wide spatial extrapolation and long sequences, yet the provided description contains no quantitative results, ablation studies on the frame-swapping component, or error analysis. Tables reporting metrics across varying expansion ratios and sequence lengths are needed to substantiate that the GCG stage does not introduce uncorrectable inconsistencies.
Authors: We acknowledge that the experimental section must more clearly demonstrate the benefits of the GCG stage across the claimed regimes. The current manuscript contains quantitative comparisons, but we will expand §4 with additional tables that report PSNR, SSIM, and temporal consistency scores for multiple spatial expansion ratios (2×, 4×, 8×) and sequence lengths (up to several hundred frames). We will also include targeted ablations isolating the frame-swapping component together with error analysis showing how GCG-guided synthesis reduces drift relative to baselines. revision: yes
Circularity Check
No circularity; proposed two-stage mechanism is self-contained architectural design
full rationale
The paper describes a coarse-to-fine pipeline that first builds Global Coarse Guidance via a novel global-local frame swapping mechanism to capture long-term structure and short-term dynamics, then uses it to guide high-resolution outpainting. No equations, fitted parameters, or self-citations appear in the provided text that would reduce any claimed result to its own inputs by construction. The separation of global modeling from fine synthesis is presented as an explicit design choice rather than a derived equivalence or renamed empirical pattern, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We first construct Global Coarse Guidance (GCG), a low-resolution representation that captures global structure and dominant motion across the video... via a novel global-local frame swapping mechanism that couples sparse global keyframes with local temporal windows
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By separating global structure modeling from fine-grained synthesis, our framework achieves stable, coherent generation for large spatial expansion and long video sequences.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Sdedit: Guided image synthesis and editing with stochastic differential equations , author=. arXiv preprint arXiv:2108.01073 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [2]
-
[3]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[4]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Dino: Detr with improved denoising anchor boxes for end-to-end object detection , author=. arXiv preprint arXiv:2203.03605 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2411.16375 , year=
Ca2-vdm: Efficient autoregressive video diffusion model with causal generation and cache sharing , author=. arXiv preprint arXiv:2411.16375 , year=
-
[6]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
From slow bidirectional to fast autoregressive video diffusion models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[7]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion , author=. arXiv preprint arXiv:2506.08009 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
arXiv preprint arXiv:2505.07344 , year=
Generative pre-trained autoregressive diffusion transformer , author=. arXiv preprint arXiv:2505.07344 , year=
-
[9]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Progressive autoregressive video diffusion models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[10]
Advances in Neural Information Processing Systems , volume=
Nuwa-infinity: Autoregressive over autoregressive generation for infinite visual synthesis , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
International Conference on Machine Learning , pages=
Video pixel networks , author=. International Conference on Machine Learning , pages=. 2017 , organization=
work page 2017
-
[12]
VideoGPT: Video Generation using VQ-VAE and Transformers
Videogpt: Video generation using vq-vae and transformers , author=. arXiv preprint arXiv:2104.10157 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Phenaki: Variable Length Video Generation From Open Domain Textual Description
Phenaki: Variable length video generation from open domain textual description , author=. arXiv preprint arXiv:2210.02399 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
IEEE Journal of Selected Topics in Signal Processing , volume=
Ultrawide foveated video extrapolation , author=. IEEE Journal of Selected Topics in Signal Processing , volume=. 2010 , publisher=
work page 2010
-
[15]
2011 IEEE International Conference on Computational Photography (ICCP) , pages=
Multiscale ultrawide foveated video extrapolation , author=. 2011 IEEE International Conference on Computational Photography (ICCP) , pages=. 2011 , organization=
work page 2011
-
[16]
International Journal of Computer Vision , volume=
Exploiting diffusion prior for real-world image super-resolution , author=. International Journal of Computer Vision , volume=. 2024 , publisher=
work page 2024
-
[17]
Advances in neural information processing systems , volume=
Conditional image generation with pixelcnn decoders , author=. Advances in neural information processing systems , volume=
-
[18]
Complete and temporally consistent video outpainting , year=
Dehan, Loïc and Van Ranst, Wiebe and Vandewalle, Patrick and Goedemé, Toon , booktitle=. Complete and temporally consistent video outpainting , year=
-
[19]
Proceedings of the 31st ACM International Conference on Multimedia , pages=
Hierarchical Masked 3D Diffusion Model for Video Outpainting , author=. Proceedings of the 31st ACM International Conference on Multimedia , pages=
-
[20]
Wang, Fu-Yun and Wu, Xiaoshi and Huang, Zhaoyang and Shi, Xiaoyu and Shen, Dazhong and Song, Guanglu and Liu, Yu and Li, Hongsheng , title =. 2024 , isbn =. doi:10.1007/978-3-031-72784-9_9 , booktitle =
-
[21]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Infinite-Canvas: Higher-Resolution Video Outpainting with Extensive Content Generation , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2025 , month=. doi:10.1609/aaai.v39i2.32213 , number=
-
[22]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
VACE: All-in-One Video Creation and Editing , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
-
[23]
and Djelouah, Abdelaziz , booktitle=
Yu, Zhongrui and Megaro-Boldini, Martina and Sumner, Robert W. and Djelouah, Abdelaziz , booktitle=. Unboxed: Geometrically and Temporally Consistent Video Outpainting , year=
-
[24]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
Progressive Artwork Outpainting via Latent Diffusion Models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
-
[25]
OutDreamer: Video Outpainting with a Diffusion Transformer , author=. 2025 , eprint=
work page 2025
-
[26]
Unified Long Video Inpainting and Outpainting via Overlapping High-Order Co-Denoising , doi =
Lyu, Shuangquan and Mao, Steven and Ma, Yue , year =. Unified Long Video Inpainting and Outpainting via Overlapping High-Order Co-Denoising , doi =
- [27]
- [28]
-
[29]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Flow straight and fast: Learning to generate and transfer data with rectified flow , author=. arXiv preprint arXiv:2209.03003 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Proceedings of the 38th International Conference on Machine Learning , pages =
Improved Denoising Diffusion Probabilistic Models , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
work page 2021
-
[31]
Score-Based Generative Modeling through Stochastic Differential Equations , author=. 2021 , eprint=
work page 2021
- [32]
-
[33]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. 2021 , eprint=
work page 2021
-
[34]
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
InOut: Diverse Image Outpainting via GAN Inversion , author=. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
work page 2022
-
[35]
A Picture is Worth More Than 77 Text Tokens: Evaluating CLIP-Style Models on Dense Captions
Yu, Hang and Li, Ruilin and Xie, Shaorong and Qiu, Jiayan , booktitle =. 2024 , volume =. doi:10.1109/CVPR52733.2024.00750 , url =
-
[36]
The Twelfth International Conference on Learning Representations , year=
Continuous-Multiple Image Outpainting in One-Step via Positional Query and A Diffusion-based Approach , author=. The Twelfth International Conference on Learning Representations , year=
-
[37]
The 2017 DAVIS Challenge on Video Object Segmentation
Jordi Pont. The 2017. CoRR , volume =. 2017 , url =. 1704.00675 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
Xu, Ning and Yang, Linjie and Fan, Yuchen and Yang, Jianchao and Yue, Dingcheng and Liang, Yuchen and Price, Brian and Cohen, Scott and Huang, Thomas , title =. 2018 , isbn =. doi:10.1007/978-3-030-01228-1_36 , booktitle =
- [39]
-
[40]
Towards Accurate Generative Models of Video: A New Metric & Challenges , author=. ArXiv , year=
-
[41]
Zhou Wang and Bovik, A.C. and Sheikh, H.R. and Simoncelli, E.P. , journal=. Image quality assessment: from error visibility to structural similarity , year=
-
[42]
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric , author=. CVPR , year=
-
[43]
Huang, Ziqi and He, Yinan and Yu, Jiashuo and Zhang, Fan and Si, Chenyang and Jiang, Yuming and Zhang, Yuanhan and Wu, Tianxing and Jin, Qingyang and Chanpaisit, Nattapol and Wang, Yaohui and Chen, Xinyuan and Wang, Limin and Lin, Dahua and Qiao, Yu and Liu, Ziwei , booktitle=
-
[44]
Edward J Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
work page 2022
-
[45]
Video extrapolation using neighboring frames
Sangwoo Lee and Jungjin Lee and Bumki Kim and Kyehyun Kim and Junyong Noh. Video extrapolation using neighboring frames. ACM Transactions on Graphics. 2019. doi:10.1145/3196492
-
[46]
International Journal of Computer Trends and Technology , year =
Bhadoriya, Shailendra and Aggarwal, Nainish and Jain, Udit and Jaiswal, Hrithik , title =. International Journal of Computer Trends and Technology , year =
-
[47]
The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
MaskGIT: Masked Generative Image Transformer , author=. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[48]
Lin, Han and Pagnucco, Maurice and Song, Yang , booktitle =. 2021 , volume =. doi:10.1109/CVPRW53098.2021.00090 , url =
-
[49]
Hierarchical Text-Conditional Image Generation with CLIP Latents , author=. 2022 , eprint=
work page 2022
-
[50]
ACM SIGGRAPH 2022 Conference Proceedings , year =
Palette: Image-to-Image Diffusion Models , author =. ACM SIGGRAPH 2022 Conference Proceedings , year =
work page 2022
-
[51]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan: Open and Advanced Large-Scale Video Generative Models , author=. arXiv preprint arXiv:2503.20314 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
SIGGRAPH Asia 2025 Conference Papers (SA Conference Papers '25) , year =
Geonung Kim and Janghyeok Han and Sunghyun Cho , title =. SIGGRAPH Asia 2025 Conference Papers (SA Conference Papers '25) , year =. doi:10.1145/3757377.3763871 , isbn =
-
[53]
Han, Janghyeok and Sim, Gyujin and Kim, Geonung and Lee, Hyun-Seung and Choi, Kyuha and Han, Youngseok and Cho, Sunghyun , title =. 2025 , isbn =. doi:10.1145/3721238.3730719 , booktitle =
-
[54]
Ryu, Nuri and Won, Jiyun and Son, Jooeun and Gong, Minsu and Lee, Joo-Haeng and Cho, Sunghyun , title =. 2025 , isbn =. doi:10.1145/3721238.3730701 , booktitle =
-
[55]
arXiv preprint arXiv:2302.08113 , year=
MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation , author=. arXiv preprint arXiv:2302.08113 , year=
-
[56]
Thirty-seventh Conference on Neural Information Processing Systems , year=
SyncDiffusion: Coherent Montage via Synchronized Joint Diffusions , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[57]
DemoFusion: Democratising High-Resolution Image Generation With No \ \ \ , author=. CVPR , year=
-
[58]
Zhou, Shangchen and Yang, Peiqing and Wang, Jianyi and Luo, Yihang and Loy, Chen Change , booktitle=
-
[59]
European Conference on Computer Vision (ECCV) , year=
Motion-Guided Latent Diffusion for Temporally Consistent Real-world Video Super-resolution , author=. European Conference on Computer Vision (ECCV) , year=
-
[60]
Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) , month =
Nguyen, Trong-Tung and Nguyen, Quang and Nguyen, Khoi and Tran, Anh and Pham, Cuong , title =. Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) , month =. 2025 , pages =
work page 2025
-
[61]
Proceedings of the Computer Vision and Pattern Recognition Conference , year=
Videodirector: Precise video editing via text-to-video models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , year=
-
[62]
arXiv preprint arXiv:2403.14773 , year=
StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text , author=. arXiv preprint arXiv:2403.14773 , year=
-
[63]
FramePainter: Endowing Interactive Image Editing with Video Diffusion Priors , author=. 2025 , eprint=
work page 2025
-
[64]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Li, Quanhao and Xing, Zhen and Wang, Rui and Zhang, Hui and Dai, Qi and Wu, Zuxuan , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
work page 2025
-
[65]
Li, Na and Li, Zihao and Tang, Zuoli and Yu, Yuqing and Zou, Lixin and Li, Chenliang , title =. 2025 , isbn =. doi:10.1145/3746027.3755278 , booktitle =
-
[66]
VIP: Versatile Image Outpainting Empowered by Multimodal Large Language Model , author=. 2024 , eprint=
work page 2024
-
[67]
Goodfellow, Ian J. and Pouget-Abadie, Jean and Mirza, Mehdi and Xu, Bing and Warde-Farley, David and Ozair, Sherjil and Courville, Aaron and Bengio, Yoshua , title =. Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 2 , pages =. 2014 , publisher =
work page 2014
-
[68]
Proceedings of the 37th International Conference on Machine Learning , articleno =
Chen, Mark and Radford, Alec and Child, Rewon and Wu, Jeff and Jun, Heewoo and Luan, David and Sutskever, Ilya , title =. Proceedings of the 37th International Conference on Machine Learning , articleno =. 2020 , publisher =
work page 2020
-
[69]
Bertalmio, Marcelo and Sapiro, Guillermo and Caselles, Vincent and Ballester, Coloma , title =. 2000 , isbn =. doi:10.1145/344779.344972 , booktitle =
-
[70]
Pathak, Deepak and Kr\"ahenb\"uhl, Philipp and Donahue, Jeff and Darrell, Trevor and Efros, Alexei , Title =
-
[71]
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation , author=. arXiv preprint arXiv:2407.02371 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
Nah, Seungjun and Baik, Sungyong and Hong, Seokil and Moon, Gyeongsik and Son, Sanghyun and Timofte, Radu and Lee, Kyoung Mu , title =. CVPR Workshops , month =
-
[73]
UltraGen: High-Resolution Video Generation with Hierarchical Attention , author=. 2025 , eprint=
work page 2025
-
[74]
SkyReels-V2: Infinite-length Film Generative Model , author=. 2025 , eprint=
work page 2025
-
[75]
Generative Pre-trained Autoregressive Diffusion Transformer , author=. 2025 , eprint=
work page 2025
-
[76]
Guilin Liu and Fitsum A. Reda and Kevin J. Shih and Ting-Chun Wang and Andrew Tao and Bryan Catanzaro , title =. The European Conference on Computer Vision (ECCV) , year =
-
[77]
Generative Image Inpainting with Contextual Attention
Generative Image Inpainting with Contextual Attention , author=. arXiv preprint arXiv:1801.07892 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
Free-Form Image Inpainting with Gated Convolution , author=. 2019 , eprint=
work page 2019
-
[79]
RePaint: Inpainting using Denoising Diffusion Probabilistic Models , year=
Lugmayr, Andreas and Danelljan, Martin and Romero, Andres and Yu, Fisher and Timofte, Radu and Van Gool, Luc , booktitle=. RePaint: Inpainting using Denoising Diffusion Probabilistic Models , year=
-
[80]
High-Resolution Image Synthesis with Latent Diffusion Models , author=. 2022 , eprint=
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.