Revisiting the Adam-SGD Gap in LLM Pre-Training: The Role of Large Effective Learning Rates
Pith reviewed 2026-05-20 13:28 UTC · model grok-4.3
The pith
Clipping mechanisms let plain SGD sustain large learning rates and close most of the gap to Adam in LLM pre-training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In LLM pre-training, small gradient norms and large weight-to-gradient ratios require high effective learning rates, yet uneven output-layer gradients and frequent spikes prevent plain SGD from using them safely. Simple clipping mechanisms stabilize SGD at these large rates, allowing it to recover most of Adam's performance. In experiments pre-training a 1B-parameter LLaMA model with 1M-token batches, the validation loss gap falls from more than 50% to roughly 3.5%.
What carries the argument
clipping mechanisms that stabilize SGD at large learning rates
Load-bearing premise
The identified problems of small gradient norms, high weight-to-gradient ratios, uneven output gradients, and spikes can be fixed by clipping without creating fresh instabilities or shifting the optimization path in unintended directions.
What would settle it
A controlled run in which the same clipping rules are applied yet the validation loss gap remains above 30% or new instabilities appear would show that the clipping approach does not actually let SGD recover most of Adam's performance.
Figures










read the original abstract
It is widely believed that stochastic gradient descent (SGD) performs significantly worse than adaptive optimizers such as Adam in pre-training Large Language Models (LLMs). Yet the underlying reason for this gap remains unclear. In this work, we attribute a large part of the discrepancy to SGD's inability to sustain learning rates comparable to Adam's much larger effective learning rates. Through empirical and theoretical analysis of LLM pre-training dynamics, we identify that training is characterized by small gradient norms and large weight-to-gradient ratios, an effect that becomes more pronounced with larger batch sizes typical in pre-training, necessitating such large effective learning rates. However, we find that output-layer gradient magnitudes become highly uneven across token classes, and that large gradient spikes frequently occur during training. Together, these effects severely restrict the admissible learning rate of SGD. Guided by this understanding, we show that simple clipping mechanisms that stabilize SGD at large learning rates enable it to recover most of Adam's performance. In our large-scale experiments, the validation loss gap between large-learning-rate SGD and Adam shrinks from more than 50% to only about 3.5% when pre-training a 1B-parameter LLaMA model with a 1M-token batch size.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript revisits the Adam-SGD performance gap in LLM pre-training. It attributes the gap primarily to SGD's inability to sustain large effective learning rates comparable to Adam's, caused by small gradient norms, high weight-to-gradient ratios (worsened at large batch sizes), highly uneven output-layer gradient magnitudes across token classes, and frequent gradient spikes. The authors argue that these dynamics restrict SGD's admissible learning rate and show that simple clipping mechanisms stabilize SGD at large learning rates, reducing the validation loss gap from over 50% to about 3.5% in a 1B-parameter LLaMA pre-training run with 1M-token batch size.
Significance. If the central attribution holds after clarification, the result would be significant for the field: it supplies a mechanistic account of why adaptive methods outperform SGD in large-scale LLM training and demonstrates that a lightweight stabilization technique can nearly close the gap. The large-scale 1B-model experiment with realistic batch size is a concrete strength, as are the direct measurements of gradient norms, spikes, and output-layer unevenness. These elements could influence practical optimizer choices and future theoretical analyses of training dynamics.
major comments (2)
- [Abstract] Abstract: The central claim that clipping 'stabilize[s] SGD at large learning rates' and thereby recovers most of Adam's performance does not separate the contribution of the increased learning rate from the side-effect of clipping on the very phenomena identified earlier (uneven output-layer gradients and spikes). Because any form of clipping necessarily rescales or suppresses the largest components, it can act as a crude coordinate-wise normalization that partially replicates Adam's adaptivity; without an ablation that holds the effective learning rate fixed while varying the clipping, the observed 3.5% gap closure cannot be attributed solely to the larger admissible LR.
- [Experimental section (1B-model results)] The experimental section (large-scale 1B LLaMA run): The reported validation-loss comparison between large-LR clipped SGD and Adam lacks controls that isolate the clipping mechanism from the learning-rate increase. A direct comparison of (i) clipped SGD at the large LR, (ii) unclipped SGD at its maximal stable LR, and (iii) Adam would be required to confirm that the gap reduction is driven by the admissible LR rather than by the clipping-induced gradient modification.
minor comments (2)
- [Methods / Analysis] The definition and measurement protocol for 'effective learning rate' and 'weight-to-gradient ratio' should be stated explicitly with equations in the methods or analysis section to allow replication.
- [Figures] Figure captions for the gradient-norm and spike plots should include the exact batch size, model scale, and number of runs used to generate the statistics.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. The points raised about isolating the contributions of learning rate and clipping are well taken, and we outline revisions below to strengthen the experimental controls while preserving the core mechanistic analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that clipping 'stabilize[s] SGD at large learning rates' and thereby recovers most of Adam's performance does not separate the contribution of the increased learning rate from the side-effect of clipping on the very phenomena identified earlier (uneven output-layer gradients and spikes). Because any form of clipping necessarily rescales or suppresses the largest components, it can act as a crude coordinate-wise normalization that partially replicates Adam's adaptivity; without an ablation that holds the effective learning rate fixed while varying the clipping, the observed 3.5% gap closure cannot be attributed solely to the larger admissible LR.
Authors: We agree that a clearer separation between the learning-rate increase and clipping-induced modifications is needed. In the manuscript we show that unclipped SGD is limited to much smaller learning rates by gradient spikes and output-layer unevenness, while clipping mitigates spikes to permit larger rates comparable to Adam's effective rates. To address the specific concern, we will add an ablation that applies clipping at the maximal stable learning rate of unclipped SGD (holding the rate fixed) and compare it to both unclipped SGD and to clipped SGD at the larger rate. This will demonstrate that clipping at the smaller rate yields only modest improvement, whereas enabling the larger rate accounts for most of the gap closure. revision: yes
-
Referee: [Experimental section (1B-model results)] The experimental section (large-scale 1B LLaMA run): The reported validation-loss comparison between large-LR clipped SGD and Adam lacks controls that isolate the clipping mechanism from the learning-rate increase. A direct comparison of (i) clipped SGD at the large LR, (ii) unclipped SGD at its maximal stable LR, and (iii) Adam would be required to confirm that the gap reduction is driven by the admissible LR rather than by the clipping-induced gradient modification.
Authors: We thank the referee for this concrete suggestion. The current results already include unclipped SGD at its maximal stable learning rate (showing a large gap to Adam) and clipped SGD at a substantially larger learning rate (closing most of the gap). To further isolate the mechanisms, we will add the requested control of clipped SGD run at the same smaller maximal stable learning rate used for unclipped SGD. This will allow direct comparison of the three conditions and confirm that the primary benefit arises from the admissible larger learning rate rather than from clipping's gradient modification alone. revision: yes
Circularity Check
No circularity: claims rest on direct empirical measurements and large-scale experiments
full rationale
The paper attributes the Adam-SGD gap to observed training dynamics (small gradient norms, large weight-to-gradient ratios, uneven output gradients, and spikes) identified via direct measurements during LLM pre-training runs. It then demonstrates via experiments that clipping enables SGD to use larger learning rates and closes most of the validation loss gap. No equations, fitted parameters renamed as predictions, or self-citation chains are present in the abstract or described chain that reduce the central result to its own inputs by construction. The analysis is self-contained against external benchmarks (actual training runs on 1B LLaMA models) and does not invoke uniqueness theorems or ansatzes from prior self-work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Training dynamics are characterized by small gradient norms and large weight-to-gradient ratios that become more pronounced with larger batch sizes.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We attribute a large part of the discrepancy to SGD’s inability to sustain learning rates comparable to Adam’s much larger effective learning rates... small gradient norms and large weight-to-gradient ratios
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Token-level fitting issues of seq2seq models.arXiv preprint arXiv:2305.04493,
Guangsheng Bao, Zhiyang Teng, and Yue Zhang. Token-level fitting issues of seq2seq models.arXiv preprint arXiv:2305.04493,
-
[2]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
work page 1901
-
[3]
Woojin Chung and Jeonghoon Kim. Exploiting vocabulary frequency imbalance in language model pre-training.arXiv preprint arXiv:2508.15390,
-
[4]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models (2022).arXiv preprint arXiv:2203.15556,
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Improving Generalization Performance by Switching from Adam to SGD
Nitish Shirish Keskar and Richard Socher. Improving generalization performance by switching from adam to sgd.arXiv preprint arXiv:1712.07628,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Martin Marek, Sanae Lotfi, Aditya Somasundaram, Andrew Gordon Wilson, and Micah Goldblum. Small batch size training for language models: When vanilla sgd works, and why gradient accumulation is wasteful.arXiv preprint arXiv:2507.07101,
-
[7]
Yan Pan and Yuanzhi Li. Toward understanding why adam converges faster than sgd for transformers. arXiv preprint arXiv:2306.00204,
-
[8]
On Information and Sufficiency
doi: 10.1214/aoms/1177729586. URL https: //doi.org/10.1214/aoms/1177729586. Andrei Semenov, Matteo Pagliardini, and Martin Jaggi. Benchmarking optimizers for large language model pretraining.arXiv preprint arXiv:2509.01440,
-
[9]
Is your batch size the problem? revisiting the adam-sgd gap in language modeling
Teodora Sre´ckovi´c, Jonas Geiping, and Antonio Orvieto. Is your batch size the problem? revisiting the adam-sgd gap in language modeling.arXiv preprint arXiv:2506.12543,
-
[10]
Sho Takase, Shun Kiyono, Sosuke Kobayashi, and Jun Suzuki. Spike no more: Stabilizing the pre-training of large language models.arXiv preprint arXiv:2312.16903,
-
[11]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023a. Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay B...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Large Batch Training of Convolutional Networks
Yang You, Igor Gitman, and Boris Ginsburg. Large batch training of convolutional networks.arXiv preprint arXiv:1708.03888,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
B Experimental Settings For our main analysis we pre-train the LLaMA Touvron et al
11 A Additional Experimental Figures 0.0 0.5 1.0 1.5 2.0 T okens Accessed 1e9 102 103 (maxi gi )/(V 1 V i = 1 gi ) Output Layer T oken-wise Variation (Adam) B = 64 B = 65536 Figure 7: Measuring the token class gradient imbalance by the ratio between maximum token class gradient norm and average token-class gradient norm:(max i=1,...,V ∥gi∥2)/(V −1PV i=1 ∥...
work page 2020
-
[14]
with a vocabulary of 32,000 tokens. We use a data-parallel setup with batch size 2048 (unless stated otherwise in the text) and sequence length 256, giving a token batch size of 524,288 tokens. We train for a total of 5,000 steps, such that the model sees roughly the Chinchilla compute-optimal Hoffmann et al
work page 2048
-
[15]
number of tokens (2.6B, i.e., 20 tokens per model parameter). We train using Pytorch’s Automatic Mixed Precision (AMP, BF16/FP32) and use the typical cosine learning rate scheduler with linear warm-up for the first 10% of the iterations. For our large scale experiments, we scale up-to the 1B LLaMA model, doubling the batch size to 4096 tokens (resulting i...
work page 2020
-
[16]
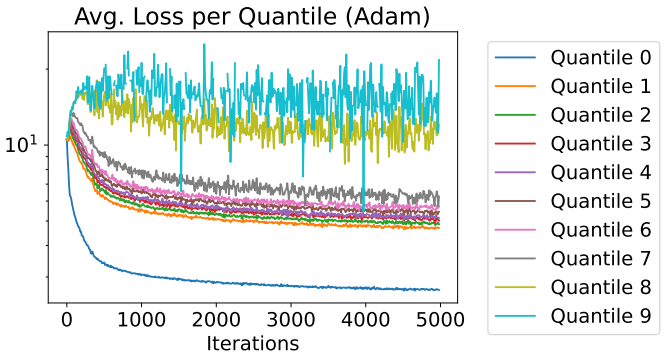
The large weight-SG norm ratio implies that a small choice of learning rate would limit the optimiza- tion algorithm’s solution space ofwt to a small neighborhood around the initialization state w0. It is evident that the usual learning rate choice of SGD in the large batch setting will leave a significant 14 0 1000 2000 3000 4000 5000 Iterations 101 Avg....
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.