Generation Navigator: A State-Aware Agentic Framework for Image Generation
Pith reviewed 2026-05-20 12:37 UTC · model grok-4.3
The pith
A state-aware agent learns to steer multi-turn image generation with a trajectory-level objective that rewards quality peaks, retention of gains, and turn efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Generation Navigator reformulates image generation as a state-conditioned action-making problem in which an agent learns to output the next steering action based on the evolving image. Standard reinforcement learning fails here because a single end-of-trajectory reward gives equal credit to every prior action and cannot tell improving moves from degrading or wasteful ones. PRE-GRPO resolves the issue by explicitly scoring trajectories on three axes: discovery of a high-quality image (Peak), preservation of that quality in subsequent turns (Retention), and avoidance of unnecessary steps (Efficiency). The resulting agent produces higher-quality and more faithful outputs than rule-driven or non
What carries the argument
PRE-GRPO, a trajectory-level reinforcement learning objective that rewards discovery of a high-quality image (Peak), preservation of quality across later turns (Retention), and reduction of superfluous turns (Efficiency).
If this is right
- The agent can adapt its next action to the actual quality trajectory instead of following static rewriting rules.
- Early high-quality outputs are protected from later degradation rather than being overwritten.
- Unproductive turns are reduced while final image quality stays high or improves.
- Benchmark scores rise on both general image quality measures and specialized reasoning tests.
Where Pith is reading between the lines
- The same reward decomposition could be tested in other sequential generative domains such as video or 3D asset creation.
- Better state representations might further improve the agent's ability to detect when quality has peaked.
- Trajectory-aware objectives of this kind may lower the amount of human feedback needed to train reliable generative agents.
Load-bearing premise
The three explicit components of Peak, Retention, and Efficiency supply the correct credit signals for individual actions inside multi-turn rollouts without missing other dynamics or adding new biases.
What would settle it
A controlled ablation that removes one or more of the Peak, Retention, or Efficiency terms from the objective and still matches or exceeds the reported WISE and reasoning scores on the same benchmarks would show the decomposition is not required.
Figures












read the original abstract
Despite rapid advances in text-to-image generation, faithfully realizing user intent remains challenging, often requiring manual multi-turn trial and error. To automate this process, existing systems rely on either simple prompt rewriting or closed-loop agents driven by hand-crafted rules, rather than learning to adapt actions to the evolving generation process. In this paper, we reformulate image generation as a state-conditioned action-making problem and propose Generation Navigator, a multi-turn T2I agent that learns to dynamically steer the generation trajectory and output the next action. However, training this agent via reinforcement learning introduces a critical credit assignment challenge: naively rewarding a trajectory based solely on a single state assigns equal credit to all actions in the rollout, ignores the quality dynamics across turns, and fails to distinguish actions that improve the trajectory from those that degrade it or waste turns without progress. We resolve this with PRE-GRPO (Peak-Retention-Efficiency Group Relative Policy Optimization), a trajectory-level reinforcement learning objective that explicitly rewards discovering a high-quality image (Peak), avoiding subsequent quality degradation across turns (Retention), and minimizing unnecessary turns (Efficiency). Experiments show substantial improvements across benchmarks, reaching a WISE score of 0.90 and 79.06% reasoning accuracy on T2I-ReasonBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to address challenges in faithfully realizing user intent in text-to-image generation by proposing Generation Navigator, a multi-turn agent that learns to dynamically steer the generation process. It introduces PRE-GRPO, a trajectory-level RL objective that rewards Peak (discovering high-quality image), Retention (avoiding quality degradation), and Efficiency (minimizing unnecessary turns) to solve credit assignment issues in multi-turn rollouts. The approach is evaluated on benchmarks, achieving a WISE score of 0.90 and 79.06% reasoning accuracy on T2I-ReasonBench.
Significance. The proposed framework and PRE-GRPO objective have the potential to significantly improve automated multi-turn image generation by learning adaptive behaviors rather than using fixed rules. If the quality metric used in the reward terms reliably tracks progress toward user intent, this could lead to more effective agentic systems. The reported performance gains suggest practical benefits, but the significance hinges on providing more details on the implementation and validation of the core components.
major comments (2)
- Method section, PRE-GRPO formulation: The PRE-GRPO objective relies on a scalar quality score computed at each turn to define the Peak, Retention, and Efficiency terms, but the manuscript provides no explicit definition of this quality function (e.g., specific VLM, CLIP variant, or learned model, and whether it is frozen or trained). This is load-bearing for the central claim that PRE-GRPO solves credit assignment without introducing new biases, as poor correlation with user intent would undermine the decomposition.
- Experiments section: The reported gains (WISE score of 0.90 and 79.06% on T2I-ReasonBench) are presented without details on baselines, statistical tests, or ablations isolating the contribution of each PRE-GRPO component. This makes it difficult to confirm that improvements stem directly from the proposed objective rather than implementation choices.
minor comments (2)
- Abstract: The claim of 'substantial improvements across benchmarks' would be strengthened by briefly naming the base T2I model and primary comparison methods.
- Notation and figures: The state-conditioned action space and trajectory dynamics could be clarified with a diagram or pseudocode to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript to incorporate the requested clarifications.
read point-by-point responses
-
Referee: Method section, PRE-GRPO formulation: The PRE-GRPO objective relies on a scalar quality score computed at each turn to define the Peak, Retention, and Efficiency terms, but the manuscript provides no explicit definition of this quality function (e.g., specific VLM, CLIP variant, or learned model, and whether it is frozen or trained). This is load-bearing for the central claim that PRE-GRPO solves credit assignment without introducing new biases, as poor correlation with user intent would undermine the decomposition.
Authors: We agree that the manuscript lacks an explicit definition of the quality function, which is necessary to evaluate the central claims. We will revise the method section to provide a full specification of this function, including the model architecture, training status (frozen or otherwise), and any supporting validation of its alignment with user intent. revision: yes
-
Referee: Experiments section: The reported gains (WISE score of 0.90 and 79.06% on T2I-ReasonBench) are presented without details on baselines, statistical tests, or ablations isolating the contribution of each PRE-GRPO component. This makes it difficult to confirm that improvements stem directly from the proposed objective rather than implementation choices.
Authors: We agree that the experiments section would be strengthened by additional details. We will revise to include explicit baseline comparisons, results from statistical significance tests across multiple runs, and ablations that isolate the individual contributions of the Peak, Retention, and Efficiency terms. revision: yes
Circularity Check
PRE-GRPO is a proposed RL objective addressing an identified credit-assignment issue; no reduction to inputs by construction
full rationale
The paper describes a credit assignment problem in naive trajectory-level RL for multi-turn T2I agents (equal credit to all actions, ignoring quality dynamics across turns) and introduces PRE-GRPO as an explicit decomposition into Peak, Retention, and Efficiency terms. This is a design choice for the reward structure rather than a derivation that reduces to prior equations, fitted parameters, or self-citations. The central claim is supported by empirical results on WISE and T2I-ReasonBench rather than by algebraic equivalence or load-bearing self-reference. No self-definitional, fitted-input, or uniqueness-imported steps appear in the provided abstract or description.
Axiom & Free-Parameter Ledger
free parameters (1)
- Balancing coefficients among Peak, Retention, and Efficiency terms
axioms (1)
- domain assumption Text-to-image generation can be usefully reformulated as a state-conditioned sequential decision process.
invented entities (2)
-
Generation Navigator agent
no independent evidence
-
PRE-GRPO objective
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
PRE-GRPO ... explicitly rewards discovering a high-quality image (Peak), avoiding subsequent quality degradation across turns (Retention), and minimizing unnecessary turns (Efficiency). ... R(τi) = Pi + α·Ri − β·Ei + γ·Fi
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and embed_strictMono unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
trajectory-level reinforcement learning objective
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Pilot study details.Appendix B expands the setup behind the introductory pilot study, including the three-turn workflow and the fixed-action versus preference-reference compari- son
-
[2]
Data pipeline and distribution.Appendix C describes the construction of the 103K struc- tured trajectories, including prompt-pool scoring, targeted prompt augmentation, branch- and-select exploration, and trajectory filtering. This section supports the training-data claims in Section 4.1 and clarifies how action-trajectory supervision differs from ordinar...
-
[3]
Agent prompts.Appendix D gives the complete reviewer and navigator prompt templates
-
[4]
6, the turn budget Tmax, and representative reward-scale examples
Hyperparameter studies.Appendix E analyzes the reward weights α and β in Eq. 6, the turn budget Tmax, and representative reward-scale examples. These studies explain why the default PRE-GRPO configuration balances candidate discovery, terminal retention, and turn efficiency
-
[5]
Controlled sampling-budget comparison.Appendix F compares one-shot generation, best-of-3 selection, prompt enhancement, fixed-workflow agents, and trained action-policy variants under a single T2I-ReasonBench view. This isolates the net contribution of state- conditioned action making from gains caused by extra sampling budget
-
[6]
Best-score versus final-score selection.Appendix G ablates the interaction between trajectory-level reward choice and inference-time output selection, explaining why Genera- tion Navigator returns the highest-scored candidate along the trajectory
-
[7]
Average generation turns.Appendix H reports the average number of generation turns on GenEval as an indirect signal of action calibration on simple compositional prompts
-
[8]
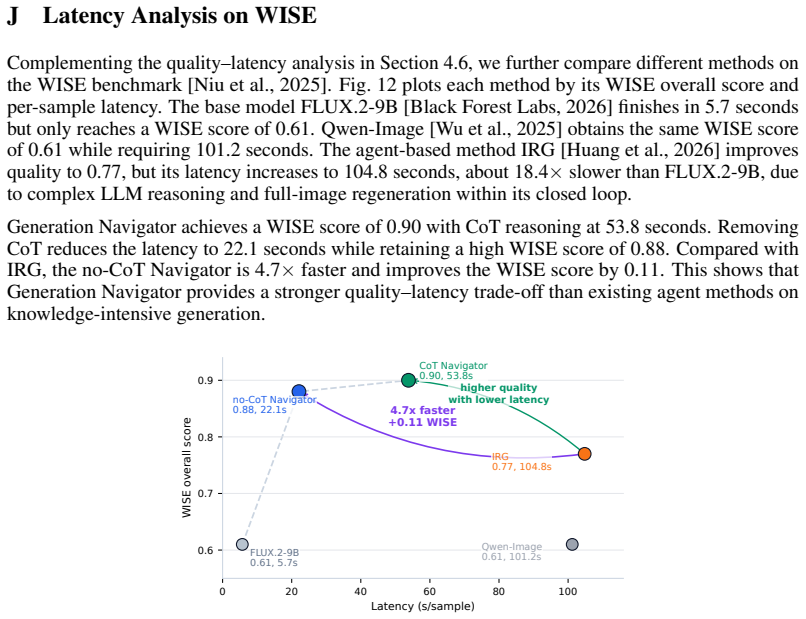
Quality–latency trade-off.Appendix I studies how the maximum turn budget affects accuracy and latency for the no-CoT Navigator
-
[9]
WISE latency analysis.Appendix J compares the quality–latency trade-off on WISE against generator-only and agent baselines
-
[10]
Qualitative visualizations.Appendix K presents representative multi-turn cases across textual image design, counting, spatial relations, scientific reasoning, and two-object gener- ation. The examples expose the actual prompts, reviewer feedback, actions, and selected images behind the aggregate results
-
[11]
Human evaluation.Appendix L reports a pairwise human study comparing human prefer- ences with reviewer-induced preferences, providing an empirical check that the automatic reviewer is a useful signal for PRE-GRPO trajectory optimization
-
[12]
Limitations and future directions.Appendix M discusses computational trade-offs, and the use of reviewers as environment signals. B Pilot Study Details Pilot study details (Section 1).We construct a three-turn workflow on T2I-ReasonBench to compare action strategies. In the first turn, each prompt is rewritten by Doubao-Seed1.5 and then fed to FLUX.2-Klei...
-
[13]
This captures paraphrase-level semantic overlap
Embedding cosine similarity.We encode each benchmark prompt and each training prompt with the sentence-transformers/all-MiniLM-L6-v2 encoder [Reimers and Gurevych, 2019, Wang et al., 2020] and report the maximum cosine similarity between each benchmark prompt and its nearest neighbor in the training pool. This captures paraphrase-level semantic overlap. 2...
work page 2019
-
[14]
5-gram containment.Measures the fraction of a benchmark prompt’s 5-grams that appear in its nearest training prompt, capturing asymmetric substring inclusion
-
[15]
8-gram containment.Following the contamination protocol used in PaLM [Chowdhery et al., 2023], we flag a benchmark sample as potentially contaminated if ≥70% of its 8-grams are contained in any training prompt
work page 2023
-
[16]
13-gram collision.Following GPT-3 [Brown et al., 2020], we check for exact 13-gram matches between benchmark and training prompts. 0.0 0.2 0.4 0.6 0.8 1.0 max similarity to prompt pool 0% 20% 40% 60% 80% 100%cumulative percent Embedding cosine (ECDF) benchmark GenEval T2I-ReasonBench WISE 0.0 0.2 0.4 0.6 0.8 1.0 max similarity to prompt pool 0 20 40 60 80...
work page 2020
-
[17]
Keep the thinking process concise (within 512 tokens)
Analyze the **Current Image** strictly against the **User Request**. Keep the thinking process concise (within 512 tokens)
-
[18]
Provide a detailed diagnosis of flaws. **Inputs**: - **User Request**: {user_request} - **Current Image**: (Visual Input) **Evaluation Criteria**: **1. Aesthetic Quality**: **Aesthetic & Technical Quality Scoring Rules (0.0-5.0)**: Evaluate the overall aesthetic appeal of the image and provide a score: Assess the image for technical flaws (artifacts, anat...
-
[19]
**Rephrase**: Describe the subject using different adjectives or synonyms
-
[20]
**Reorder**: Move the missing or distorted elements mentioned in the ‘diagnosis‘ to the **very beginning** of the prompt
-
[21]
**Simplify vs. Enrich**: - If diagnosis says "garbled/messy" -> **Simplify** details, focus on main subject. - If diagnosis says "boring/wrong style" -> **Enrich** with style modifiers (e.g., "cinematic lighting", "concept art"). 17 0.02 0.2 0.5 1.0 α 76.0 76.5 77.0 77.5 78.0 78.5Reasoning SFT Terminal-retention weight 0.01 0.02 0.03 0.04 β 75.5 76.0 76.5...
- [22]
-
[23]
**Specificity**: Explicitly state the target. AVOID "it/him/her". Use "the panda", "the red car"
-
[24]
**Single Focus**: Target **ONLY ONE** specific area mentioned in the ‘diagnosis‘. Do not fix everything at once
-
[25]
**Avoid Anatomy**: Do NOT try to fix eyes/gaze via I2I. Use REGENERATE for that
-
[26]
Make the tall warrior wear a red cape
**Example**: "Make the tall warrior wear a red cape." (NOT "Change clothes"). **Task 3: Output** Only provide a valid JSON object. ‘‘‘json { "decision": "STOP" | "REGENERATE" | "REFINE", "reasoning": "Explain why you chose this action based on the diagnosis.", "revised_prompt": "String OR null. If STOP, null. If REGENERATE, the full new T2I prompt. If REF...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.