Federated Learning by Utility-Constrained Stochastic Aggregation for Improving Rational Participation
Pith reviewed 2026-05-20 12:29 UTC · model grok-4.3
The pith
FedUCA improves federated learning by using utility-constrained stochastic aggregation to sustain rational client participation
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
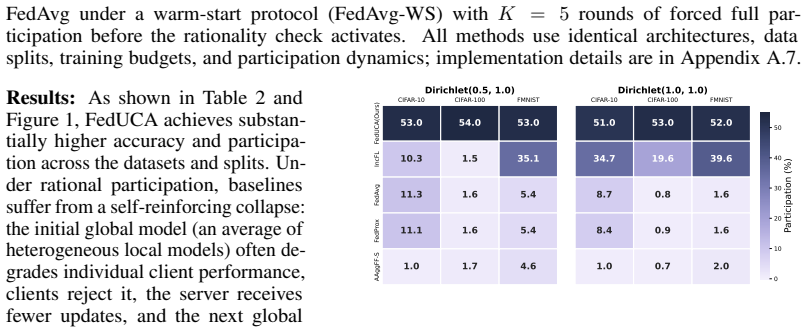
FedUCA formalizes the server's role as an optimizer that maximizes global model performance by sustaining client participation, implemented through utility-constrained stochastic aggregation that adjusts the process to keep each client's perceived local benefit above its dropout threshold in statistically heterogeneous environments.
What carries the argument
Utility-Constrained Stochastic Aggregation: the server's mechanism for selecting aggregation weights or participants stochastically while enforcing constraints derived from modeled client local performance thresholds to encourage continued involvement.
If this is right
- Client retention rates rise in heterogeneous cross-silo settings.
- Global model performance improves from the sustained diversity of participating clients.
- The risk of federated training collapsing due to mass withdrawals decreases.
- Server aggregation decisions become a direct lever for shaping client participation behavior.
Where Pith is reading between the lines
- The same utility-modeling approach could be adapted to design explicit participation incentives in other decentralized training systems.
- Explicitly tracking client rationality may prove necessary when scaling federated methods to production environments with independent actors.
- Future work could test whether relaxing the rationality assumption still preserves the retention gains observed here.
Load-bearing premise
Clients behave as rational utility maximizers whose local performance thresholds can be accurately modeled and influenced by the server's aggregation choices.
What would settle it
A controlled experiment that records actual client opt-out decisions across rounds and checks whether the observed dropout rates align with predictions from the utility model under FedUCA versus standard aggregation.
Figures






read the original abstract
Federated Learning (FL) algorithms implicitly assume that clients passively comply with server-side orchestration by sharing local model updates upon server request. However, this overlooks an important aspect in real-world cross-silo environments: clients are often rational agents who may prioritize their utilities such as local model performance over that of the global model. In settings with significant statistical heterogeneity, rational clients may opt out of the federation if the perceived benefits of collaboration fail to meet their local utility thresholds. Such attrition degrades the global model performance and can lead to the collapse of the federated training process. In this work, we introduce FedUCA, (Federated Learning by Utility-Constrained Stochastic Aggregation for Improving Rational Participation), a framework that formalizes the server's role as an optimizer seeking to maximize global model performance by sustaining client participation. We substantiate our framework through extensive experiments on standard datasets demonstrating that by prioritizing participation feasibility, FedUCA achieves significantly higher client retention and, consequently, a superior global model performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FedUCA, a framework that models clients in federated learning as rational utility maximizers who may drop out if local performance thresholds are not met. It proposes utility-constrained stochastic aggregation at the server to maximize global model performance by sustaining participation, and reports experiments on standard datasets showing higher client retention and improved global accuracy as a result.
Significance. If the causal attribution to participation holds, the work addresses a practically relevant gap in cross-silo FL where statistical heterogeneity can cause rational attrition and training collapse. The emphasis on explicit participation modeling and the reported retention gains would be a useful contribution to incentive-aware FL literature.
major comments (2)
- [§4] §4 (Experiments) and the associated figures: the central claim that superior global performance is 'consequently' due to higher client retention is not isolated from the change in aggregation operator. No ablation is reported that holds the stochastic aggregation rule fixed while varying only the utility constraint (or vice versa), leaving open the possibility that performance differences arise from altered update statistics rather than retention.
- [§3] §3 (Framework formulation): the optimization objective that trades off global loss against participation feasibility is stated at a high level, but the precise functional form of the utility constraint and how it enters the stochastic aggregation weights is not derived or shown to be parameter-free; this makes it difficult to assess whether the reported improvements are robust to modeling choices for client utilities.
minor comments (2)
- [Abstract] Abstract and §1: the claim of 'extensive experiments' is not accompanied by details on number of clients, heterogeneity levels, or statistical significance of retention and accuracy differences; these should be summarized early for clarity.
- [§2] Notation in §2: the definition of client utility threshold and its relation to local model performance should be made explicit with an equation, as the current prose description leaves the mapping from model quality to participation decision ambiguous.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and have revised the manuscript to strengthen the presentation and empirical support where appropriate.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and the associated figures: the central claim that superior global performance is 'consequently' due to higher client retention is not isolated from the change in aggregation operator. No ablation is reported that holds the stochastic aggregation rule fixed while varying only the utility constraint (or vice versa), leaving open the possibility that performance differences arise from altered update statistics rather than retention.
Authors: We agree that an explicit ablation isolating the utility constraint from the stochastic aggregation operator would strengthen the causal attribution. In the revised manuscript we have added such an ablation: we fix the stochastic aggregation rule and vary only the utility-constraint threshold, reporting the resulting changes in retention and global accuracy. This new experiment supports that the observed gains are driven by sustained participation rather than solely by altered update statistics. revision: yes
-
Referee: [§3] §3 (Framework formulation): the optimization objective that trades off global loss against participation feasibility is stated at a high level, but the precise functional form of the utility constraint and how it enters the stochastic aggregation weights is not derived or shown to be parameter-free; this makes it difficult to assess whether the reported improvements are robust to modeling choices for client utilities.
Authors: We have expanded the derivation in Section 3. The utility constraint is expressed as a per-client feasibility condition on expected local utility gain; this condition directly modulates the sampling probabilities inside the stochastic aggregation weights via a normalized, closed-form reweighting that uses only quantities already computed during local training. The resulting procedure introduces no additional free parameters beyond the original FL hyperparameters. We also added a short sensitivity study confirming robustness to reasonable variations in the client utility model. revision: yes
Circularity Check
No circularity detected; framework description lacks explicit derivations or equations that reduce to inputs by construction.
full rationale
The provided abstract and description introduce FedUCA as a framework that formalizes the server as an optimizer maximizing global performance by sustaining participation, substantiated via experiments on standard datasets showing higher retention and superior performance. No equations, optimization formulations, self-citations, or ansatzes are quoted or described that would allow reduction of any prediction or result to fitted parameters or prior self-referential definitions. The central claim rests on empirical outcomes rather than a closed mathematical chain, making the derivation self-contained against external benchmarks with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Federated learning based on dynamic regularization
Durmus Alp Emre Acar, Yue Zhao, Ramon Matas, Matthew Mattina, Paul Whatmough, and Venkatesh Saligrama. Federated learning based on dynamic regularization. InInternational Conference on Learning Representations, 2021. URL https://openreview.net/forum? id=B7v4QMR6Z9w
work page 2021
-
[2]
Akshay Agrawal, Robin Verschueren, Steven Diamond, and Stephen Boyd. A rewriting system for convex optimization problems.Journal of Control and Decision, 5(1):42–60, 2018
work page 2018
-
[3]
C.D. Aliprantis and K.C. Border.Infinite Dimensional Analysis: A Hitchhiker’s Guide. Studies in Economic Theory. Springer, 1999. ISBN 9783540658542. URL https://books.google. co.in/books?id=6jjY2Vi3aDEC
work page 1999
-
[4]
Hongliu Cao. Towards more sustainable enterprise data and application management with cross silo federated learning and analytics.arXiv preprint arXiv:2312.14628, 2023
-
[5]
To federate or not to federate: Incentivizing client participation in federated learning
Yae Jee Cho, Divyansh Jhunjhunwala, Tian Li, Virginia Smith, and Gauri Joshi. To federate or not to federate: Incentivizing client participation in federated learning. InWorkshop on Federated Learning: Recent Advances and New Challenges (in Conjunction with NeurIPS 2022), 2022. URLhttps://openreview.net/forum?id=pG08eM0CQba
work page 2022
-
[6]
Fed- biomed: Open, transparent and trusted federated learning for real-world healthcare applications
Francesco Cremonesi, Marc Vesin, Sergen Cansiz, Yannick Bouillard, Irene Balelli, Lucia Innocenti, Riccardo Taiello, Santiago Silva, Samy-Safwan Ayed, Melek Önen, et al. Fed- biomed: Open, transparent and trusted federated learning for real-world healthcare applications. 10 InFederated Learning Systems: Towards Privacy-Preserving Distributed AI, pages 19–...
work page 2025
-
[7]
Ittai Dayan, Holger R Roth, Aoxiao Zhong, Ahmed Harouni, Amilcare Gentili, Anas Z Abidin, Andrew Liu, Anthony Beardsworth Costa, Bradford J Wood, Chien-Sung Tsai, et al. Federated learning for predicting clinical outcomes in patients with covid-19.Nature medicine, 27(10): 1735–1743, 2021
work page 2021
-
[8]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. doi: 10.1109/CVPR.2009.5206848
-
[9]
Steven Diamond and Stephen Boyd. CVXPY: A Python-embedded modeling language for convex optimization.Journal of Machine Learning Research, 17(83):1–5, 2016
work page 2016
-
[10]
Timur Garipov, Pavel Izmailov, Dmitrii Podoprikhin, Dmitry P Vetrov, and Andrew G Wilson. Loss surfaces, mode connectivity, and fast ensembling of dnns.Advances in neural information processing systems, 31, 2018
work page 2018
-
[11]
Data shapley: Equitable valuation of data for machine learning
Amirata Ghorbani and James Zou. Data shapley: Equitable valuation of data for machine learning. InInternational Conference on Machine Learning (ICML), 2019
work page 2019
-
[12]
Pursuing overall welfare in federated learning through sequential decision making, 2024
Seok-Ju Hahn, Gi-Soo Kim, and Junghye Lee. Pursuing overall welfare in federated learning through sequential decision making, 2024. URLhttps://arxiv.org/abs/2405.20821
-
[13]
Federated Learning for Mobile Keyboard Prediction
Andrew Hard, Kanishka Rao, Rajiv Mathews, Swaroop Ramaswamy, Françoise Beaufays, Sean Augenstein, Hubert Eichner, Chloé Kiddon, and Daniel Ramage. Federated learning for mobile keyboard prediction, 2019. URLhttps://arxiv.org/abs/1811.03604
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[14]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[15]
Fedvarp: Tack- ling the variance due to partial client participation in federated learning
Divyansh Jhunjhunwala, Pranay Sharma, Aushim Nagarkatti, and Gauri Joshi. Fedvarp: Tack- ling the variance due to partial client participation in federated learning. InUncertainty in Artificial Intelligence, pages 906–916. PMLR, 2022
work page 2022
-
[16]
Jiawen Kang, Zehui Xiong, Dusit Niyato, et al. Incentive mechanism for reliable federated learning: A joint optimization approach to combining reputation and contract theory. InIEEE Internet of Things Journal, 2019
work page 2019
-
[17]
Scaffold: Stochastic controlled averaging for federated learning
Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank Reddi, Sebastian Stich, and Ananda Theertha Suresh. Scaffold: Stochastic controlled averaging for federated learning. In International conference on machine learning, pages 5132–5143. PMLR, 2020
work page 2020
-
[18]
Mechanisms that incentivize data sharing in federated learning
Sai Praneeth Karimireddy, Wenshuo Guo, and Michael Jordan. Mechanisms that incentivize data sharing in federated learning. InWorkshop on Federated Learning: Recent Advances and New Challenges (in Conjunction with NeurIPS 2022), 2022. URL https://openreview. net/forum?id=Bx4Sz-N5K3J
work page 2022
-
[19]
Understanding black-box predictions via influence functions
Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. InInternational conference on machine learning, pages 1885–1894. PMLR, 2017
work page 2017
-
[20]
Incentivizing federated learning.arXiv preprint arXiv:2205.10951, 2022
Shuyu Kong, You Li, and Hai Zhou. Incentivizing federated learning.arXiv preprint arXiv:2205.10951, 2022
-
[21]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
work page 2009
-
[22]
Hao Li, Zheng Xu, Gavin Taylor, Christoph Studer, and Tom Goldstein. Visualizing the loss landscape of neural nets.Advances in neural information processing systems, 31, 2018
work page 2018
-
[23]
Tian Li, Anit Kumar Sahu, Ameet Talwalkar, and Virginia Smith. Fair resource allocation in federated learning.International Conference on Learning Representations (ICLR), 2020. 11
work page 2020
-
[24]
Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith. Federated optimization in heterogeneous networks.Proceedings of Machine learning and systems, 2:429–450, 2020
work page 2020
-
[25]
Incentive mechanism design for unbiased federated learning with randomized client participation
Bing Luo, Yutong Feng, Shiqiang Wang, Jianwei Huang, and Leandros Tassiulas. Incentive mechanism design for unbiased federated learning with randomized client participation. In 2023 IEEE 43rd International Conference on Distributed Computing Systems (ICDCS), pages 545–555. IEEE, 2023
work page 2023
-
[26]
Communication-efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. InArtificial intelligence and statistics, pages 1273–1282. PMLR, 2017
work page 2017
- [27]
-
[28]
Roger B. Myerson. Optimal auction design.Mathematics of Operations Research, 6(1):58–73,
-
[29]
URLhttp://www.jstor.org/stable/3689266
ISSN 0364765X, 15265471. URLhttp://www.jstor.org/stable/3689266
-
[30]
Federated learning with buffered asynchronous aggregation
John Nguyen, Kshitiz Malik, Hongyuan Zhan, Ashkan Yousefpour, Mike Rabbat, Mani Malek, and Dzmitry Huba. Federated learning with buffered asynchronous aggregation. InInternational conference on artificial intelligence and statistics, pages 3581–3607. PMLR, 2022
work page 2022
-
[31]
Valentin V . Petrov. On lower bounds for tail probabilities.Journal of Statistical Plan- ning and Inference, 137(8):2703–2705, 2007. ISSN 0378-3758. doi: https://doi.org/ 10.1016/j.jspi.2006.02.015. URL https://www.sciencedirect.com/science/article/ pii/S0378375807000213. 5th St. Petersburg Workshop on Simulation
-
[32]
John W. Pratt. Risk aversion in the small and in the large.Econometrica, 32(1/2):122–136,
-
[33]
URLhttp://www.jstor.org/stable/1913738
ISSN 00129682, 14680262. URLhttp://www.jstor.org/stable/1913738
-
[34]
Motivating workers in federated learning: A stackelberg game perspective, 2019
Yunus Sarikaya and Ozgur Ercetin. Motivating workers in federated learning: A stackelberg game perspective, 2019. URLhttps://arxiv.org/abs/1908.03092
-
[35]
Patrick W. Schmitz.Journal of Institutional and Theoretical Economics (JITE) / Zeitschrift für die gesamte Staatswissenschaft, 162(3):535–540, 2006. ISSN 09324569. URL http: //www.jstor.org/stable/40752600
-
[36]
A principled approach to data valuation for federated learning
Tianhao Wang, Johannes Rausch, Ce Zhang, Ruoxi Jia, and Dawn Song. A principled approach to data valuation for federated learning. pages 153–167, 2020
work page 2020
-
[37]
Hongyi Wu, Xiaoying Tang, Ying-Jun Angela Zhang, and Lin Gao. Incentive mechanism for federated learning with random client selection.IEEE Transactions on Network Science and Engineering, 11(2):1922–1933, 2024. doi: 10.1109/TNSE.2023.3334476
-
[38]
Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms, 2017
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms, 2017. URL https://arxiv.org/abs/1708. 07747
work page 2017
-
[39]
Yun Xin, Jianfeng Lu, Shuqin Cao, Gang Li, Haozhao Wang, and Guanghui Wen. Daringfed: a dynamic bayesian persuasion pricing for online federated learning under two-sided incomplete information. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pages 6687–6695, 2025
work page 2025
-
[40]
Contract-based incentive mechanism for federated learning in edge computing system
Lu Yu, Zheng Chang, and Zhiwei Zhao. Contract-based incentive mechanism for federated learning in edge computing system. In2024 IEEE Wireless Communications and Networking Conference (WCNC), pages 1–6, 2024. doi: 10.1109/WCNC57260.2024.10570831
-
[41]
A comprehensive survey of incentive mechanism for federated learning, 2021
Rongfei Zeng, Chao Zeng, Xingwei Wang, Bo Li, and Xiaowen Chu. A comprehensive survey of incentive mechanism for federated learning, 2021. URLhttps://arxiv.org/abs/2106. 15406
work page 2021
-
[42]
Ning Zhang, Xiaoqing Xu, Liuyihui Qian, Xiaojun Liu, Juan Wu, and Hong Tang. Auction- based incentive mechanism in federated learning considering communication path finding.IEEE Access, 12:139336–139345, 2024. doi: 10.1109/ACCESS.2024.3425948. 12 A Technical appendices and supplementary material A.1 Notation Table 4: Summary of notation used in the paper....
-
[43]
NX k=1 αt kI t k ht k − ∇fk(θ(t,0)) 2 # | {z } F1 +3E
using the inequality||A|| 2 2 ≤ ||A||1||A||∞: •||R T ||1 = maxj P i Ri,j = max(row sums ofR) = 1. •||R T ||∞ = maxi P j Ri,j = max(col sums ofR) = ns N . Therefore, foranyfeasible optimization outcome, the spectral norm is deterministically bounded by ||RT ||2 2 ≤ ns N . Taking the expectation over the Dirichlet distributions: Es|| 1 N 1N −α t||2 2 ≤ ns N...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.