OmniSelect: Dynamic Modality-Aware Token Compression for Efficient Omni-modal Large Language Models
Pith reviewed 2026-05-20 11:40 UTC · model grok-4.3
The pith
OmniSelect dynamically selects among three token pruning regimes based on cross-modal relevance to compress inputs in omni-modal models without any training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OmniSelect is a modality-adaptive token pruning framework that leverages cross-modal relevance scores from a lightweight AudioCLIP model to categorize each multimodal input into one of three regimes—Audio-Centric, Video-Centric, or Uniform pruning—and then performs fine-grained token selection inside temporal groups by adaptively assigning pruning ratios to retain informative tokens across both modalities.
What carries the argument
The dynamic regime selector that maps relevance scores to one of three pruning strategies followed by adaptive ratio allocation inside temporal groups.
If this is right
- Multimodal token sequences can be shortened substantially while task performance remains comparable to the uncompressed model.
- The entire compression process runs without any extra training or fine-tuning of the target omni-modal model.
- One-size-fits-all pruning is avoided because the strategy changes with the query-dependent importance of each modality.
- Fine-grained allocation inside temporal groups keeps the most useful tokens rather than discarding them uniformly.
Where Pith is reading between the lines
- The same relevance-driven routing idea could be tested on other modality pairs such as text-image or video-text.
- If the three-regime categorization proves stable, it could support automatic scaling of context length for longer real-time streams.
- A direct comparison against learned pruning policies on the same benchmarks would show whether the training-free route is competitive on efficiency.
Load-bearing premise
Relevance scores from the lightweight AudioCLIP model are accurate enough to pick the pruning regime that actually preserves task accuracy for that specific input.
What would settle it
A set of audio-video queries where the chosen regime produces measurably lower accuracy than either no pruning or a fixed uniform baseline on the same downstream task.
Figures




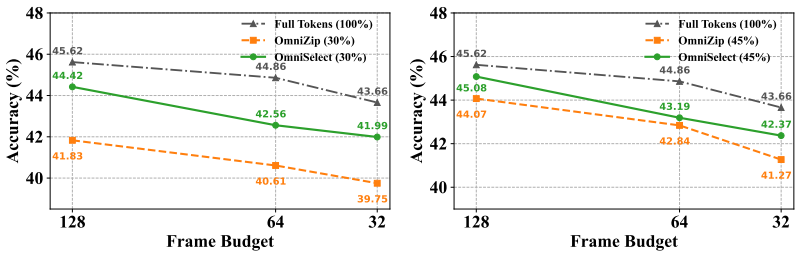





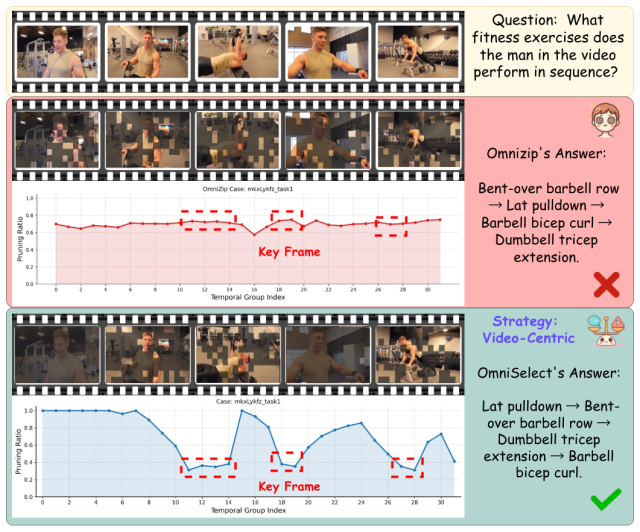


read the original abstract
Omnimodal large language models (OmniLLMs) have recently gained increasing attention for unified audio-video understanding. However, processing long multimodal token sequences introduces substantial computational overhead, making efficient token compression crucial. Existing methods typically rely on fixed, modality-specific guidance, which fails to account for the varying importance of modalities across different queries. To address this limitation, we propose $\textbf{OmniSelect}$, a training-free, modality-adaptive token pruning framework that dynamically selects appropriate compression strategies for multimodal inputs. Specifically, we leverage a lightweight AudioCLIP model to estimate cross-modal relevance and categorize each input into three pruning regimes: Audio-Centric, Video-Centric, and Uniform pruning. Based on these relevance scores, OmniSelect further performs fine-grained token pruning within each temporal group, adaptively allocating pruning ratios to preserve informative tokens across modalities. By explicitly modeling modality preference and enabling dynamic strategy selection, OmniSelect effectively avoids the pitfalls of one-size-fits-all compression. Extensive experiments demonstrate that our method achieves efficient multimodal token reduction while maintaining strong performance, without requiring any additional training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OmniSelect, a training-free token compression framework for omni-modal LLMs that uses a lightweight AudioCLIP model to compute cross-modal relevance scores and dynamically assign each input to one of three pruning regimes (Audio-Centric, Video-Centric, or Uniform). Within each temporal group the method then applies adaptive per-modality pruning ratios intended to retain informative tokens. The central claim is that this modality-aware selection achieves substantial token reduction while preserving downstream task performance without any additional training.
Significance. If the AudioCLIP-derived regime selection reliably preserves accuracy, the approach would provide a practical, zero-shot efficiency technique for long-context omni-modal models. The training-free design and explicit handling of modality preference are clear strengths that distinguish it from fixed-ratio baselines.
major comments (2)
- The central claim rests on the unvalidated assumption that AudioCLIP relevance scores correctly assign inputs to Audio-Centric / Video-Centric / Uniform regimes whose pruning ratios preserve the target OmniLLM’s task accuracy. Because AudioCLIP is a lightweight audio-text model with no task-specific calibration or comparison to the OmniLLM’s attention/gradient signals, mis-categorization would apply the wrong per-modality ratios; the manuscript provides no empirical check of this mapping against downstream accuracy.
- Abstract and experimental section: the claim that “extensive experiments demonstrate … maintaining strong performance” is stated without any reported metrics, baselines, datasets, or ablation tables in the supplied text, preventing evaluation of whether the dynamic regime selection actually outperforms fixed pruning under realistic query distributions.
minor comments (1)
- Notation for relevance-score thresholds and temporal-group boundaries should be defined explicitly with equations rather than prose descriptions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below with clarifications and proposed revisions where appropriate.
read point-by-point responses
-
Referee: The central claim rests on the unvalidated assumption that AudioCLIP relevance scores correctly assign inputs to Audio-Centric / Video-Centric / Uniform regimes whose pruning ratios preserve the target OmniLLM’s task accuracy. Because AudioCLIP is a lightweight audio-text model with no task-specific calibration or comparison to the OmniLLM’s attention/gradient signals, mis-categorization would apply the wrong per-modality ratios; the manuscript provides no empirical check of this mapping against downstream accuracy.
Authors: We agree that a direct empirical mapping between AudioCLIP scores and the target OmniLLM’s internal signals (attention or gradients) is not provided in the current manuscript. The design intentionally uses AudioCLIP as a lightweight, training-free proxy for cross-modal relevance to enable zero-shot regime selection. Our experiments validate the overall approach by showing that the dynamic regime selection consistently outperforms fixed-ratio baselines on downstream tasks under varied query distributions, which provides indirect support for the quality of the assignments. To directly address the concern, we will add an ablation analysis in the revised version that correlates selected regimes with per-example accuracy preservation. revision: yes
-
Referee: Abstract and experimental section: the claim that “extensive experiments demonstrate … maintaining strong performance” is stated without any reported metrics, baselines, datasets, or ablation tables in the supplied text, preventing evaluation of whether the dynamic regime selection actually outperforms fixed pruning under realistic query distributions.
Authors: We apologize that the experimental details may not have been fully visible in the excerpt provided for review. The complete manuscript includes a dedicated Experiments section reporting results on standard omni-modal benchmarks (e.g., audio-visual QA and captioning datasets), with quantitative comparisons against fixed pruning baselines, other compression methods, and ablations on regime selection. These show substantial token reduction (typically 40-60%) with minimal accuracy degradation. We will revise the abstract and main text to explicitly reference the key tables and metrics for clarity. revision: partial
Circularity Check
No circularity in the OmniSelect heuristic pipeline
full rationale
The paper describes a training-free heuristic method that invokes an external AudioCLIP model to produce cross-modal relevance scores, uses those scores to assign each input to one of three fixed pruning regimes (Audio-Centric, Video-Centric, Uniform), and then applies rule-based token allocation inside temporal groups. No equations, fitted parameters, or derivations are presented in which any claimed output is defined in terms of itself or reduces by construction to the inputs. The central logic rests on independent external components and explicit rules rather than self-referential definitions, fitted-input predictions, or load-bearing self-citations. This is a standard heuristic pipeline whose correctness can be evaluated against external benchmarks without internal tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption AudioCLIP cross-modal relevance scores can be used to categorize inputs into effective Audio-Centric, Video-Centric, or Uniform pruning regimes
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
leverage a lightweight AudioCLIP model to estimate cross-modal relevance and categorize each input into three pruning regimes: Audio-Centric, Video-Centric, and Uniform pruning... adaptively allocating pruning ratios to preserve informative tokens across modalities
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TemporalGroupPruningPipeline (TGP2)... attention matrix... cosine similarity matrix within each temporal group
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Llava-onevision-1.5: Fully open framework for democratized multimodal training, 2025
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Didi Zhu, Chunsheng Wu, Huajie Tan, Chunyuan Li, Jing Yang, Jie Yu, Xiyao Wang, Bin Qin, Yumeng Wang, Zizhen Yan, Ziyong Feng, Ziwei Liu, Bo Li, and Jiankang Deng. Llava-onevision-1.5: Fully open framework for democratized multimodal training, 2025
work page 2025
-
[2]
Qwen2.5-vl technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2025
work page 2025
-
[3]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks, 2024
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks, 2024
work page 2024
-
[4]
Videollama 2: Advancing spatial- temporal modeling and audio understanding in video-llms, 2024
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, and Lidong Bing. Videollama 2: Advancing spatial- temporal modeling and audio understanding in video-llms, 2024
work page 2024
-
[5]
Omnisift: Modality-asymmetric token compression for efficient omni-modal large language models, 2026
Yue Ding, Yiyan Ji, Jungang Li, Xuyang Liu, Xinlong Chen, Junfei Wu, Bozhou Li, Bohan Zeng, Yang Shi, Yushuo Guan, Yuanxing Zhang, Jiaheng Liu, Qiang Liu, Pengfei Wan, and Liang Wang. Omnisift: Modality-asymmetric token compression for efficient omni-modal large language models, 2026
work page 2026
-
[6]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24118, 2025
work page 2025
-
[7]
Audioclip: Extending clip to image, text and audio
Andrey Guzhov, Federico Raue, Jörn Hees, and Andreas Dengel. Audioclip: Extending clip to image, text and audio. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 976–980. IEEE, 2022
work page 2022
-
[8]
Worldsense: Evaluating real-world omnimodal understanding for multimodal llms, 2026
Jack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie. Worldsense: Evaluating real-world omnimodal understanding for multimodal llms, 2026
work page 2026
-
[9]
From specific-mllms to omni-mllms: A survey on mllms aligned with multi-modalities, 2025
Shixin Jiang, Jiafeng Liang, Jiyuan Wang, Xuan Dong, Heng Chang, Weijiang Yu, Jinhua Du, Ming Liu, and Bing Qin. From specific-mllms to omni-mllms: A survey on mllms aligned with multi-modalities, 2025
work page 2025
-
[10]
Omnivideobench: Towards audio-visual understanding evaluation for omni mllms,
Caorui Li, Yu Chen, Yiyan Ji, Jin Xu, Zhenyu Cui, Shihao Li, Yuanxing Zhang, Wentao Wang, Zhenghao Song, Dingling Zhang, et al. Omnivideobench: Towards audio-visual understanding evaluation for omni mllms.arXiv preprint arXiv:2510.10689, 2025
-
[11]
Baichuan-omni-1.5 technical report, 2025
Yadong Li, Jun Liu, Tao Zhang, Tao Zhang, Song Chen, Tianpeng Li, Zehuan Li, Lijun Liu, Lingfeng Ming, Guosheng Dong, Da Pan, Chong Li, Yuanbo Fang, Dongdong Kuang, Mingrui Wang, Chenglin Zhu, Youwei Zhang, Hongyu Guo, Fengyu Zhang, Yuran Wang, Bowen Ding, Wei Song, Xu Li, Yuqi Huo, Zheng Liang, Shusen Zhang, Xin Wu, Shuai Zhao, Linchu Xiong, Yozhen Wu, J...
work page 2025
-
[12]
Accelerating transducers through adjacent token merging, 2023
Yuang Li, Yu Wu, Jinyu Li, and Shujie Liu. Accelerating transducers through adjacent token merging, 2023
work page 2023
-
[13]
Speechprune: Context-aware token pruning for speech information retrieval, 2025
Yueqian Lin, Yuzhe Fu, Jingyang Zhang, Yudong Liu, Jianyi Zhang, Jingwei Sun, Hai "Helen" Li, and Yiran Chen. Speechprune: Context-aware token pruning for speech information retrieval, 2025
work page 2025
-
[14]
Visual instruction tuning, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning, 2023
work page 2023
- [15]
-
[16]
Kim, Bilge Soran, Raghuraman Krishnamoorthi, Mohamed Elhoseiny, and Vikas Chandra
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Balakrishnan Varadarajan, Florian Bordes, Zhuang Liu, Hu Xu, Hyunwoo J. Kim, Bilge Soran, Raghuraman Krishnamoorthi, Mohamed Elhoseiny, and Vikas Chandra. Longvu: Spatiotemporal adaptive compression for long video-language understanding, 2024
work page 2024
-
[17]
Audio-visual llm for video understanding, 2023
Fangxun Shu, Lei Zhang, Hao Jiang, and Cihang Xie. Audio-visual llm for video understanding, 2023
work page 2023
-
[18]
video-salmonn 2: Caption-enhanced audio-visual large language models, 2025
Changli Tang, Yixuan Li, Yudong Yang, Jimin Zhuang, Guangzhi Sun, Wei Li, Zejun Ma, and Chao Zhang. video-salmonn 2: Caption-enhanced audio-visual large language models, 2025
work page 2025
-
[19]
Adaptive keyframe sampling for long video understanding, 2025
Xi Tang, Jihao Qiu, Lingxi Xie, Yunjie Tian, Jianbin Jiao, and Qixiang Ye. Adaptive keyframe sampling for long video understanding, 2025
work page 2025
-
[20]
Dycoke: Dynamic compression of tokens for fast video large language models, 2025
Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. Dycoke: Dynamic compression of tokens for fast video large language models, 2025
work page 2025
-
[21]
Dycoke: Dynamic compression of tokens for fast video large language models
Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. Dycoke: Dynamic compression of tokens for fast video large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18992–19001, 2025
work page 2025
-
[22]
Omnizip: Audio- guided dynamic token compression for fast omnimodal large language models, 2025
Keda Tao, Kele Shao, Bohan Yu, Weiqiang Wang, Jian liu, and Huan Wang. Omnizip: Audio- guided dynamic token compression for fast omnimodal large language models, 2025
work page 2025
-
[23]
Qwen3.5-omni: Scaling up, toward native omni-modal agi, March 2026
Qwen Team. Qwen3.5-omni: Scaling up, toward native omni-modal agi, March 2026
work page 2026
-
[24]
Interactiveomni: A unified omni-modal model for audio-visual multi-turn dialogue, 2025
Wenwen Tong, Hewei Guo, Dongchuan Ran, Jiangnan Chen, Jiefan Lu, Kaibin Wang, Keqiang Li, Xiaoxu Zhu, Jiakui Li, Kehan Li, Xueheng Li, Lumin Li, Chenxu Guo, Jiasheng Zhou, Jiandong Chen, Xianye Wu, Jiahao Wang, Silei Wu, Lei Chen, Hanming Deng, Yuxuan Song, Dinghao Zhou, Guiping Zhong, Ken Zheng, Shiyin Kang, and Lewei Lu. Interactiveomni: A unified omni-...
work page 2025
-
[25]
Qwen2-vl: Enhancing vision- language model’s perception of the world at any resolution, 2024
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision- language model’s perception of the world at any resolution, 2024
work page 2024
-
[26]
Qwen2.5-omni technical report, 2025
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-omni technical report, 2025
work page 2025
-
[27]
Qwen3-omni technical report, 2025
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, Yuanjun Lv, Yongqi Wang, Dake Guo, He Wang, Linhan Ma, Pei Zhang, Xinyu Zhang, Hongkun Hao, Zishan Guo, Baosong Yang, Bin Zhang, Ziyang Ma, Xipin Wei, Shuai Bai, Keqin Chen, Xuejing Liu, Peng Wang, Mingkun Yang, Dayiheng Liu, Xingzhang Ren, Bo ...
work page 2025
-
[28]
Humanomniv2: From understanding to omni-modal reasoning with context, 2025
Qize Yang, Shimin Yao, Weixuan Chen, Shenghao Fu, Detao Bai, Jiaxing Zhao, Boyuan Sun, Bowen Yin, Xihan Wei, and Jingren Zhou. Humanomniv2: From understanding to omni-modal reasoning with context, 2025. 11
work page 2025
-
[29]
Visionzip: Longer is better but not necessary in vision language models, 2026
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. Visionzip: Longer is better but not necessary in vision language models, 2026
work page 2026
-
[30]
Weihao Ye, Qiong Wu, Wenhao Lin, and Yiyi Zhou. Fit and prune: Fast and training-free visual token pruning for multi-modal large language models, 2024
work page 2024
-
[31]
Q-frame: Query-aware frame selection and multi-resolution adaptation for video-llms, 2025
Shaojie Zhang, Jiahui Yang, Jianqin Yin, Zhenbo Luo, and Jian Luan. Q-frame: Query-aware frame selection and multi-resolution adaptation for video-llms, 2025
work page 2025
-
[32]
What action did the singer perform as interaction at the end of the video?
Ziwei Zhou, Rui Wang, Zuxuan Wu, and Yu-Gang Jiang. Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities, 2026. 12 A Preliminary An OmniLLM [ 9] typically consists of a vision encoder Ev, an audio encoder Ea, and an LLM backbone. In the input pipeline, video, audio, and textual prompts are treated as raw data. Specifically,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.