Evidence-Grounded Frontier Mapping and Agentic Hypothesis Generation in Nanomedicine
Pith reviewed 2026-05-20 10:34 UTC · model grok-4.3
The pith
pArticleMap maps low-density bridge regions in nanomedicine literature and generates citation-grounded hypotheses via agentic language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
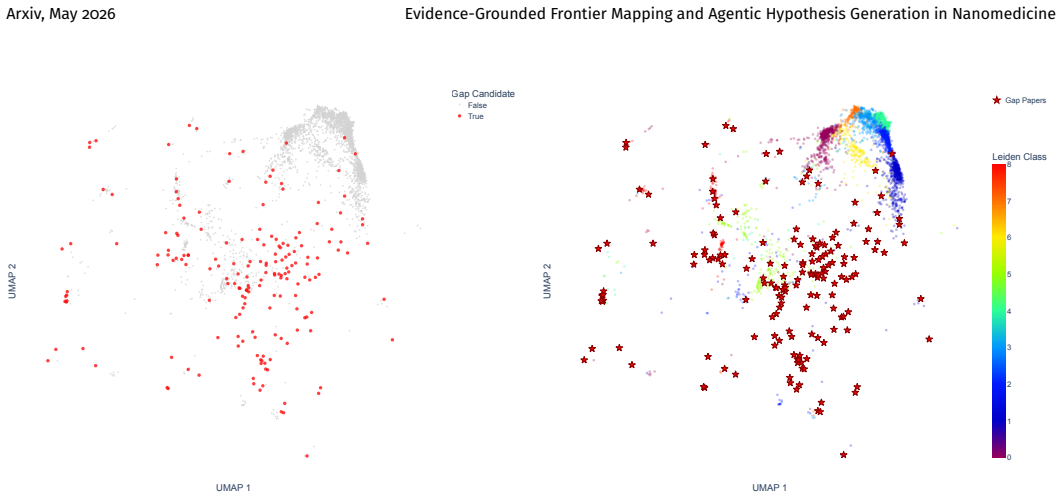
Rather than forecasting future concept co-occurrence, pArticleMap targets low-density article-level bridge regions and cluster interfaces, then generates and scores citation-grounded hypotheses with large language models in an agentic setup, obtaining a pooled gold recovery rate of 10.8%, recall@10 of 15.9%, and future-neighborhood rate of 61.0% across retrospective bundles.
What carries the argument
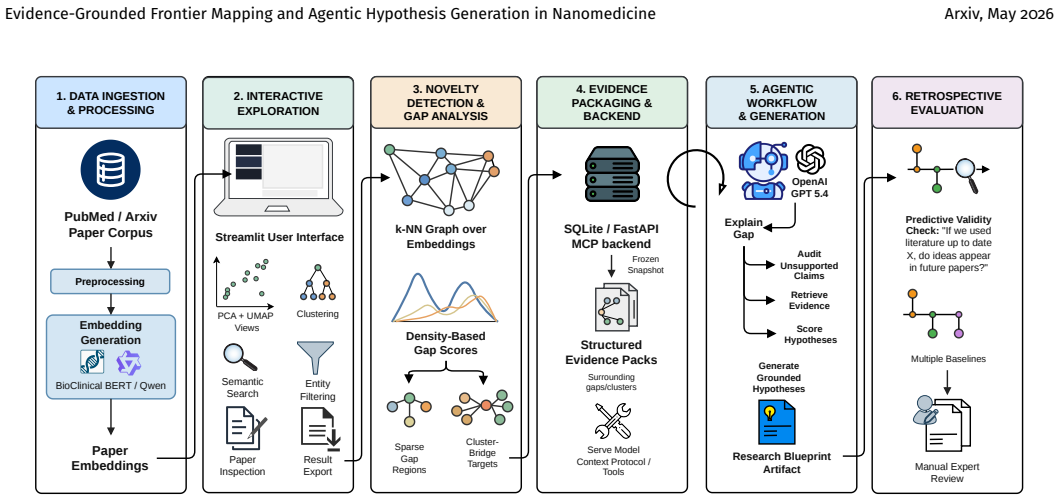
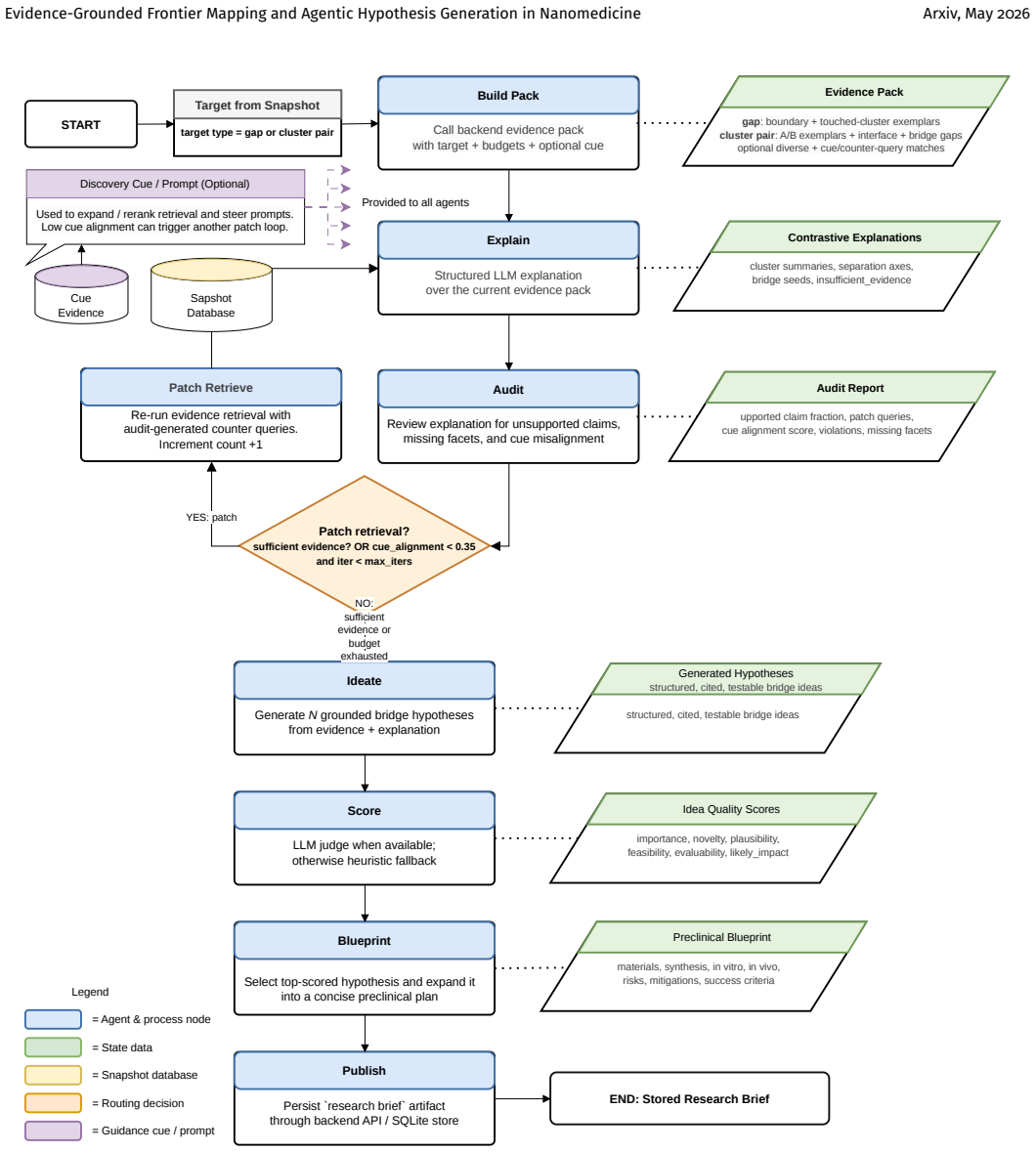
The pArticleMap pipeline of article embeddings, similarity-graph frontier extraction, evidence-pack retrieval, and audited agentic LLM hypothesis generation and scoring.
If this is right
- The system reaches the correct future research neighborhood in 61 percent of cases even when exact paper recovery is lower.
- Internal scoring functions as a useful but imperfect support signal that does not replace human expert assessment.
- Task-retained hypotheses can be produced under the benchmark protocol across multiple nanomedicine sub-areas.
- The approach emphasizes conservative, citation-grounded ideation over direct prediction of concept co-occurrences.
Where Pith is reading between the lines
- If the retrospective benchmark generalizes, the same bridge-region mapping could surface overlooked connections between subfields such as biomaterials and disease-specific applications.
- Researchers in other domains with large heterogeneous literatures might adapt the frontier-extraction step to prioritize interface areas for new experiments.
- Adding loops that incorporate fresh experimental outcomes back into the evidence packs could tighten the scoring over successive cycles.
- The method could help allocate limited lab resources toward interfaces that already show partial evidence in neighboring clusters.
Load-bearing premise
That the retrospective realization benchmark of generating later literature under a historical cutoff serves as a valid proxy for producing useful forward-looking hypotheses in real research settings.
What would settle it
A prospective trial in which pArticleMap generates hypotheses from current literature cutoffs, experts pursue a subset in the lab, and the rate at which those specific ideas lead to new publications or validations is compared against control sets of expert-only or random ideas.
Figures









read the original abstract
Nanomedicine research spans delivery chemistry, immunology, imaging, biomaterials, and disease-specific translational science, yet its conceptual design space remains fragmented across a large and heterogeneous literature. To date, artificial intelligence in nanomedicine has focused primarily on property prediction and formulation optimization, with much less attention to evidence-grounded discovery support at the level of research direction selection. We introduce pArticleMap, a literature-mapping and research-hypothesis-generation system that combines article embeddings, similarity-graph analysis, sparse frontier extraction, structured evidence-pack retrieval, and an audited large-language-model (LLM) workflow for grounded ideation. Rather than forecasting future concept co-occurrence, pArticleMap targets low-density article-level bridge regions and cluster interfaces, then generates and scores citation-grounded hypotheses with large language models in an agentic setup. We evaluate the system with a retrospective realization benchmark (generate later literature under a historical cutoff) and a blinded human reader assessment layer across cue-conditioned nanomedicine tasks. Across 4 selected retrospective bundles, pArticleMap generated ideas and selected task-retained hypotheses (winner ideas) under the benchmark protocol. For task-level retained hypotheses, a pooled gold recovery rate of 10.8% was obtained, with a recall@10 of 15.9% and a future-neighborhood rate of 61.0%, indicating that the system often reached the correct forward-looking neighborhood (paper ideas) even without exact paper-level recovery. Human-agent agreement is modest overall, indicating that internal scoring is useful as a support signal but does not replace expert judgment. These results position pArticleMap as a conservative, evidence-grounded research assistant for nanomedicine.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces pArticleMap, a literature-mapping and hypothesis-generation system for nanomedicine that uses article embeddings, similarity-graph analysis, sparse frontier extraction to target low-density bridge regions and cluster interfaces, followed by structured evidence-pack retrieval and an audited agentic LLM workflow to generate and score citation-grounded hypotheses. Evaluation uses a retrospective realization benchmark (generating hypotheses from pre-cutoff literature and scoring against later papers) across 4 bundles, yielding a pooled gold recovery rate of 10.8%, recall@10 of 15.9%, and future-neighborhood rate of 61.0%, plus a blinded human reader assessment layer showing modest human-agent agreement.
Significance. If the retrospective metrics hold as a proxy for forward utility, the work offers a conservative, evidence-grounded assistant for research direction selection in a fragmented domain, extending AI in nanomedicine beyond property prediction. The concrete retrospective metrics and emphasis on citation-grounded, audited LLM use are strengths that position the system as a support tool rather than an autonomous discoverer.
major comments (2)
- [Evaluation section / retrospective benchmark protocol] The retrospective realization benchmark (described in the evaluation section and abstract) is load-bearing for the central claim that pArticleMap produces useful forward-looking hypotheses. Alignment with later published papers (gold recovery 10.8%, future-neighborhood 61.0%) assumes published outcomes reliably signal intrinsic promise, yet published literature is filtered by funding, feasibility, and trends; this risks the system rediscovering latent embedding-space patterns rather than generating novel bridges. A concrete test against expert-proposed directions or controlled forward experiments is needed to validate the proxy.
- [Human reader assessment layer] Modest human-agent agreement (noted in the abstract and human assessment layer) indicates that the internal scoring driving the benchmark numbers diverges from expert judgment. This weakens the claim that the system provides reliable support signals; further breakdown of disagreement cases by task type or bundle would clarify whether the 61.0% neighborhood rate reflects genuine utility or benchmark artifacts.
minor comments (2)
- [Abstract and evaluation setup] Specify the exact selection criteria and characteristics of the 4 retrospective bundles to allow reproducibility and assessment of generalizability.
- [Sparse frontier extraction description] Clarify quantitative thresholds used for low-density bridge regions and cluster interfaces in the similarity-graph analysis.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address the major concerns regarding the retrospective benchmark and the human assessment layer below, making revisions to improve clarity and transparency where possible.
read point-by-point responses
-
Referee: [Evaluation section / retrospective benchmark protocol] The retrospective realization benchmark (described in the evaluation section and abstract) is load-bearing for the central claim that pArticleMap produces useful forward-looking hypotheses. Alignment with later published papers (gold recovery 10.8%, future-neighborhood 61.0%) assumes published outcomes reliably signal intrinsic promise, yet published literature is filtered by funding, feasibility, and trends; this risks the system rediscovering latent embedding-space patterns rather than generating novel bridges. A concrete test against expert-proposed directions or controlled forward experiments is needed to validate the proxy.
Authors: We agree that the retrospective benchmark serves as a proxy and is subject to the biases inherent in published literature, including influences from funding, feasibility, and prevailing trends. This limitation is common to literature-based discovery approaches and does not claim to identify 'intrinsic promise' independent of publication filters. Instead, it measures the system's ability to surface directions that were subsequently realized in the literature. To strengthen the manuscript, we have revised the evaluation section to explicitly discuss these proxy limitations and the potential for rediscovering embedding patterns. We have also added text noting that direct validation against expert-proposed directions or controlled forward experiments would require prospective studies, which we identify as an important avenue for future work. revision: partial
-
Referee: [Human reader assessment layer] Modest human-agent agreement (noted in the abstract and human assessment layer) indicates that the internal scoring driving the benchmark numbers diverges from expert judgment. This weakens the claim that the system provides reliable support signals; further breakdown of disagreement cases by task type or bundle would clarify whether the 61.0% neighborhood rate reflects genuine utility or benchmark artifacts.
Authors: We concur that the modest agreement highlights the complementary nature of the system's scoring to expert judgment. In response, we have expanded the human assessment section with a breakdown of disagreement cases, stratified by task type and bundle. This additional analysis reveals that disagreements are more prevalent in bundles involving highly interdisciplinary topics, where expert opinions themselves may vary. We believe this supports the interpretation of the 61.0% future-neighborhood rate as indicating utility in identifying relevant neighborhoods, while acknowledging that the system is intended as a support tool rather than a definitive judge. revision: yes
- A full prospective validation with controlled forward experiments or direct expert-proposed direction comparisons cannot be addressed within the scope of this revision, as it would necessitate new experimental designs and data collection beyond the current retrospective and human assessment framework.
Circularity Check
No significant circularity; retrospective benchmark is external validation
full rationale
The paper's claimed chain proceeds from article embeddings and similarity-graph analysis to sparse frontier extraction, evidence-pack retrieval, and LLM-based hypothesis generation, then evaluates via retrospective realization against actual later literature. This benchmark compares system outputs to independently published future papers under a historical cutoff and is not equivalent to the inputs by construction, nor does it rely on fitted parameters renamed as predictions or load-bearing self-citations. No equations or steps reduce the output to the input definitions; the evaluation uses external gold-standard literature as an independent check. The derivation remains self-contained against this external benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Article embeddings and similarity graphs can reliably identify low-density bridge regions that correspond to promising research frontiers.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
pArticleMap targets low-density article-level bridge regions and cluster interfaces, then generates and scores citation-grounded hypotheses with large language models in an agentic setup
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
retrospective realization benchmark (generate later literature under a historical cutoff)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Fishoil,raynaud’ssyndrome,andundiscov- eredpublicknowledge
D.R.Swanson,“Fishoil,raynaud’ssyndrome,andundiscov- eredpublicknowledge”,PerspectivesinBiologyandMedicine, vol.30,no.1,pp.7–18,1986.doi:10.1353/pbm.1986.0087
-
[2]
Using arrowsmith: A computer-assisted approach to formulating and assessing scientific hypotheses
N. R. Smalheiser and D. R. Swanson, “Using arrowsmith: A computer-assisted approach to formulating and assessing scientific hypotheses”,Computer Methods and Programs in Biomedicine,vol.57,no.3,pp.149–153,1998,issn:0169-2607. doi:https://doi.org/10.1016/S0169-2607(98)00033-9[Online]. Available:https://www.sciencedirect.com/science/article/pii/ S0169260798000339
-
[3]
Usingliterature-baseddiscoverytoidentifydiseasecandidate genes
D.Hristovski,B.Peterlin,J.A.Mitchell,andS.M.Humphrey, “Usingliterature-baseddiscoverytoidentifydiseasecandidate genes”,International Journal of Medical Informatics, vol. 74, no.2,pp.289–298,2005,MIE2003,issn:1386-5056.doi:https: //doi.org/10.1016/j.ijmedinf.2004.04.024 [Online]. Avail- able: https://www.sciencedirect.com/science/article/pii/ S1386505604001650
-
[4]
Citespace ii: Detecting and visualizing emerging trendsandtransientpatternsinscientificliterature
C. Chen, “Citespace ii: Detecting and visualizing emerging trendsandtransientpatternsinscientificliterature”,Journalof theAmericanSocietyforInformationScienceandTechnology, vol.57,no.3,pp.359–377,2006.doi:https://doi.org/10.1002/ asi.20317eprint:https://onlinelibrary.wiley.com/doi/pdf/10. 1002/asi.20317.[Online].Available:https://onlinelibrary.wiley. com/...
-
[5]
S.Lloyd,“Leastsquaresquantizationinpcm”,IEEETrans.Inf. Theor.,vol.28,no.2,pp.129–137,Sep.2006,issn:0018-9448. doi: 10.1109/TIT.1982.1056489 [Online]. Available: https: //doi.org/10.1109/TIT.1982.1056489
-
[6]
Softwaresurvey:Vosviewer,a computerprogramforbibliometricmapping
N.J.vanEckandL.Waltman,“Softwaresurvey:Vosviewer,a computerprogramforbibliometricmapping”,Scientometrics, vol.84,no.2,pp.523–538,2010.doi:10.1007/s11192-009-0146- 3
-
[7]
Textminingandvisualization usingvosviewer
N.J.vanEckandL.Waltman,“Textminingandvisualization usingvosviewer”,ISSINewsletter,vol.7,no.3,pp.50–54,2011
work page 2011
-
[8]
Context-drivenautomatic subgraphcreationforliterature-baseddiscovery
D. Cameron, R. Kavuluru, T. C. Rindflesch, A. P. Sheth, K. Thirunarayan,andO.Bodenreider,“Context-drivenautomatic subgraphcreationforliterature-baseddiscovery”,en,J.Biomed. Inform.,vol.54,pp.141–157,Apr.2015.doi:10.1016/j.jbi.2015. 01.014
-
[9]
Moliere: Automatic biomedical hypothesis generation system
J. Sybrandt, M. Shtutman, and I. Safro, “Moliere: Automatic biomedical hypothesis generation system”, inProceedings of the23rdACMSIGKDDInternationalConferenceonKnowledge DiscoveryandDataMining,ser.KDD’17,Halifax,NS,Canada: Association for Computing Machinery, 2017, pp. 1633–1642, isbn:9781450348874.doi:10.1145/3097983.3098057[Online]. Available:https://do...
-
[10]
R.vanderMeel,E.Sulheim,Y.Shi,F.Kiessling,W.J.M.Mul- der, and T. Lammers, “Smart cancer nanomedicine”,Nature Nanotechnology,vol.14,no.11,pp.1007–1017,Nov.2019,issn: 1748-3395.doi:10.1038/s41565-019-0567-y[Online].Available: https://doi.org/10.1038/s41565-019-0567-y
-
[11]
Fromlouvainto leiden:Guaranteeingwell-connectedcommunities
V.A.Traag,L.Waltman,andN.J.vanEck,“Fromlouvainto leiden:Guaranteeingwell-connectedcommunities”,Scientific Reports,vol.9,no.1,Mar.2019,issn:2045-2322.doi:10.1038/ s41598-019-41695-z[Online].Available:http://dx.doi.org/10. 1038/s41598-019-41695-z
work page 2019
-
[12]
Retrieval-augmentedgenerationforknowledge- intensive nlp tasks
P.Lewisetal.,“Retrieval-augmentedgenerationforknowledge- intensive nlp tasks”, inAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33, Curran Associates, Inc., 2020, pp. 9459–9474. [Online]. Available: https : / / proceedings.neurips.cc/paper_files/paper/2020/file/ 6b493230205f780e1...
work page 2020
-
[13]
A hybrid approach to hierarchical density-based cluster selection
C. Malzer and M. Baum, “A hybrid approach to hierarchical density-based cluster selection”, in2020 IEEE International ConferenceonMultisensorFusionandIntegrationforIntelligent Systems (MFI), IEEE, Sep. 2020, pp. 223–228.doi: 10.1109/ mfi49285.2020.9235263[Online].Available:http://dx.doi.org/ 10.1109/MFI49285.2020.9235263
-
[14]
Agatha: Automatic graph mining and transformer based hypothesis generationapproach
J. Sybrandt, I. Tyagin, M. Shtutman, and I. Safro, “Agatha: Automatic graph mining and transformer based hypothesis generationapproach”,inProceedingsofthe29thACMInterna- tional Conference on Information & Knowledge Management, ser.CIKM’20,VirtualEvent,Ireland:AssociationforComput- ingMachinery,2020,pp.2757–2764,isbn:9781450368599.doi: 10.1145/3340531.3412...
-
[15]
Development of pharmaceutical nanomedicines: From the bench to the market
A. A. Halwani, “Development of pharmaceutical nanomedicines: From the bench to the market”,Phar- maceutics, vol. 14, no. 1, 2022,issn: 1999-4923.doi: 10 . 3390 / pharmaceutics14010106 [Online]. Available: https://www.mdpi.com/1999-4923/14/1/106
work page 2022
-
[16]
Artificial intelligence to bring nanomedicine to life
N. Serov and V. Vinogradov, “Artificial intelligence to bring nanomedicine to life”, en,Adv. Drug Deliv. Rev., vol. 184, no.114194,p.114194,May2022
-
[17]
M.Krennetal.,“Forecastingthefutureofartificialintelligence with machine learning-based link prediction in an exponen- tially growing knowledge network”,Nature Machine Intelli- gence,vol.5,no.11,pp.1326–1335,2023,issn:2522-5839.doi: 10.1038/s42256-023-00735-0[Online].Available:https://doi. org/10.1038/s42256-023-00735-0
-
[18]
arXiv preprint arXiv:2312.07559 , year=
J.Lála,O.O’Donoghue,A.Shtedritski,S.Cox,S.G.Rodriques, and A. D. White, “Paperqa: Retrieval-augmented generative agentforscientificresearch”,arXivpreprintarXiv:2312.07559, 2023.doi: 10.48550/arXiv.2312.07559 [Online]. Available: https://arxiv.org/abs/2312.07559
-
[19]
Mechanisms and barriers in nanomedicine: Progress in the field and future directions
T. Anchordoquy et al., “Mechanisms and barriers in nanomedicine: Progress in the field and future directions”, en,ACS Nano, vol. 18, no. 22, pp. 13983–13999, 2024.doi: 10.1021/acsnano.4c00182
-
[20]
anthropic.com/news/model-context-protocol,Accessed:2026- 04-12,2024
Anthropic,Introducingthemodelcontextprotocol,https://www. anthropic.com/news/model-context-protocol,Accessed:2026- 04-12,2024
work page 2026
-
[21]
AcceleratingionizablelipiddiscoveryformRNA deliveryusingmachinelearningandcombinatorialchemistry
B.Lietal.,“AcceleratingionizablelipiddiscoveryformRNA deliveryusingmachinelearningandcombinatorialchemistry”, NatureMaterials, vol. 23, no. 7, pp. 1002–1008, 2024.doi: 10. 1038/s41563-024-01867-3
work page 2024
-
[22]
Bran, A.; Cox, S.; Schilter, O.; Baldassari, C.; White, A
A.M.Bran,S.Cox,O.Schilter,C.Baldassari,A.D.White,andP. Schwaller,“Augmentinglargelanguagemodelswithchemistry tools”,NatureMachineIntelligence,vol.6,no.5,pp.525–535, 2024,issn: 2522-5839.doi: 10.1038/s42256-024-00832-8 [Online].Available:https://doi.org/10.1038/s42256-024-00832- 8
-
[23]
Machinelearning-guidedhighthroughput nanoparticledesign
A. Ortiz-Perez, D. van Tilborg, R. van der Meel, F. Grisoni, andL.Albertazzi,“Machinelearning-guidedhighthroughput nanoparticledesign”,DigitalDiscovery,vol.3,no.7,pp.1280– 1291,2024.doi:10.1039/D4DD00104D 11–21 Evidence-Grounded Frontier Mapping and Agentic Hypothesis Generation in Nanomedicine Arxiv, May 2026
-
[24]
M. D. Skarlinski et al., “Language agents achieve super- human synthesis of scientific knowledge”,arXiv preprint arXiv:2409.13740,2024.doi:10.48550/arXiv.2409.13740[On- line].Available:https://arxiv.org/abs/2409.13740
-
[25]
Wang, Iskandar Sitdikov, Ciro Salcedo, Alireza Seif, and Zlatko K
J. Yang et al., “Poisoning medical knowledge using large lan- guage models”,Nature Machine Intelligence, vol. 6, no. 10, pp.1156–1168,2024,issn:2522-5839.doi:10.1038/s42256-024- 00899-3[Online].Available:https://doi.org/10.1038/s42256- 024-00899-3
-
[26]
Asurveyonhypothesisgenerationforsci- entific discovery in the era of large language models
A.K.Alkanetal.,“Asurveyonhypothesisgenerationforsci- entific discovery in the era of large language models”,arXiv preprint arXiv:2504.05496, 2025.doi: 10.48550/arXiv.2504. 05496[Online].Available:https://arxiv.org/abs/2504.05496
-
[27]
Scientifichypothesisgenerationandvalida- tion:Methods,datasets,andfuturedirections
A.Kulkarnietal.,“Scientifichypothesisgenerationandvalida- tion:Methods,datasets,andfuturedirections”,arXivpreprint arXiv:2505.04651,2025.doi:10.48550/arXiv.2505.04651[On- line].Available:https://arxiv.org/abs/2505.04651
-
[28]
ModelContextProtocolContributors,Modelcontextprotocol specification, https://modelcontextprotocol.io/specification/ 2025-11-25,Accessed:2026-04-12,2025
work page 2025
-
[29]
S.Ren,P.Jian,Z.Ren,C.Leng,C.Xie,andJ.Zhang,“Towards scientificintelligence:Asurveyofllm-basedscientificagents”, arXiv preprint arXiv:2503.24047, 2025.doi: 10.48550/arXiv. 2503.24047 [Online]. Available: https://arxiv.org/abs/2503. 24047
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[30]
10896 [cs.CL].[Online].Available:https://arxiv.org/abs/2506
T.Sounacketal.,Bioclinicalmodernbert:Astate-of-the-artlong- contextencoderforbiomedicalandclinicalnlp,2025.arXiv:2506. 10896 [cs.CL].[Online].Available:https://arxiv.org/abs/2506. 10896
work page 2025
-
[31]
A neural symbolic model for space physics
J. Ying et al., “A neural symbolic model for space physics”, NatureMachineIntelligence,vol.7,no.10,pp.1726–1741,2025, issn: 2522-5839.doi: 10.1038/s42256-025-01126-3 [Online]. Available:https://doi.org/10.1038/s42256-025-01126-3
-
[32]
Y.Zhangetal.,Qwen3embedding:Advancingtextembedding and reranking through foundation models, 2025. arXiv: 2506. 05176 [cs.CL].[Online].Available:https://arxiv.org/abs/2506. 05176
work page 2025
-
[33]
Acomprehensivelarge-scalebiomedicalknowl- edge graph for ai-powered data-driven biomedical research
Y.Zhangetal.,“Acomprehensivelarge-scalebiomedicalknowl- edge graph for ai-powered data-driven biomedical research”, Nature Machine Intelligence, vol. 7, no. 4, pp. 602–614, 2025, issn:2522-5839.doi:10.1038/s42256-025-01014-w [Online]. Available:https://doi.org/10.1038/s42256-025-01014-w
-
[34]
Fromautomationtoautonomy:Asurveyon largelanguagemodelsinscientificdiscovery
T.Zhengetal.,“Fromautomationtoautonomy:Asurveyon largelanguagemodelsinscientificdiscovery”,inProceedingsof the2025ConferenceonEmpiricalMethodsinNaturalLanguage Processing, Association for Computational Linguistics, 2025, pp. 17733–17750. [Online]. Available: https://aclanthology. org/2025.emnlp-main.895/
work page 2025
-
[35]
Largelanguagemodelsforscientificdiscovery inmolecularpropertyprediction
Y.Zhengetal.,“Largelanguagemodelsforscientificdiscovery inmolecularpropertyprediction”,NatureMachineIntelligence, vol.7,no.3,pp.437–447,2025,issn:2522-5839.doi:10.1038/ s42256-025-00994-z [Online]. Available: https://doi.org/10. 1038/s42256-025-00994-z
work page 2025
-
[36]
Nature (2026) https://doi.org/10.1038/s41586-025-10072-4
A.Asaietal.,“Synthesizingscientificliteraturewithretrieval- augmented language models”,Nature, vol. 650, pp. 857–863, 2026.doi: 10.1038/s41586-025-10072-4 [Online]. Available: https://doi.org/10.1038/s41586-025-10072-4
-
[37]
High- throughput platforms for machine learning-guided lipid nanoparticledesign
A. R. Hanna, D. A. Issadore, and M. J. Mitchell, “High- throughput platforms for machine learning-guided lipid nanoparticledesign”,NatureReviewsMaterials,vol.11,no.1, pp.50–64,Jan.2026,issn:2058-8437.doi:10.1038/s41578-025- 00831-0[Online].Available:https://doi.org/10.1038/s41578- 025-00831-0
-
[38]
Predictingnewresearchdirectionsinmate- rialsscienceusinglargelanguagemodelsandconceptgraphs
T.Marwitzetal.,“Predictingnewresearchdirectionsinmate- rialsscienceusinglargelanguagemodelsandconceptgraphs”, Nature Machine Intelligence, 2026,issn: 2522-5839.doi: 10. 1038/s42256-026-01206-y [Online].Available:https://doi.org/ 10.1038/s42256-026-01206-y
-
[39]
A large-scale randomized study of large language model feedback in peer review
N. Thakkar et al., “A large-scale randomized study of large language model feedback in peer review”,Nature Machine Intelligence, vol. 8, no. 3, pp. 326–336, 2026,issn: 2522-5839. doi: 10.1038/s42256-026-01188-x [Online]. Available: https: //doi.org/10.1038/s42256-026-01188-x
-
[40]
KG-Registry — kghub.org, https://kghub.org/kg-registry/ resource/semmeddb/semmeddb.html,[Accessed30-03-2026]
work page 2026
-
[41]
LangGraph: Agent Orchestration Framework for Reliable AI Agents — langchain.com, https://www.langchain.com/ langgraph,[Accessed27-03-2026]. 12–21 Arxiv, May 2026 Evidence-Grounded Frontier Mapping and Agentic Hypothesis Generation in Nanomedicine A. CORPUS-CONSTRUCTION FLOW Section3givestheformaldefinitionofcorpusassembly,representa- tion,graphconstructio...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.