TabH2O: A Unified Foundation Model for Tabular Prediction
Pith reviewed 2026-05-20 13:08 UTC · model grok-4.3
The pith
A unified foundation model handles both classification and regression for tabular data in a single forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
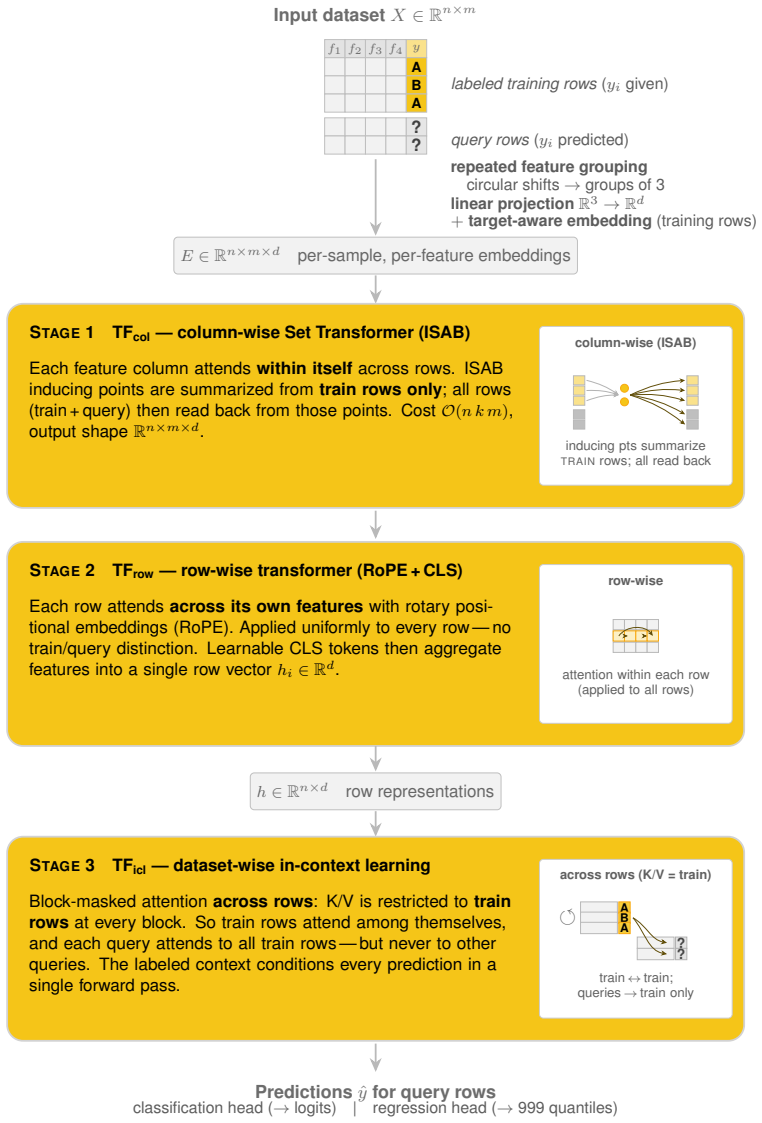
TabH2O demonstrates that a foundation model for tabular prediction can perform classification and regression via in-context learning in one pass. This is achieved through unified dual-head training that eliminates separate models, single-stage pretraining supported by stability improvements like bounded scalable softmax and logit soft-capping, and noise-aware pretraining that adds explicit noise dimensions to teach robustness to irrelevant features.
What carries the argument
The dual-head architecture for handling multiple task types together with stability enhancements for single-stage pretraining and noise dimensions added to synthetic pretraining data.
Load-bearing premise
Performance benefits result from the specific changes in unified training, single-stage pretraining, and noise-aware data rather than from differences in compute budget or exact dataset makeup.
What would settle it
An experiment that trains the model without the added noise dimensions and measures if it loses robustness on datasets containing many irrelevant features would test the value of that component.
Figures




read the original abstract
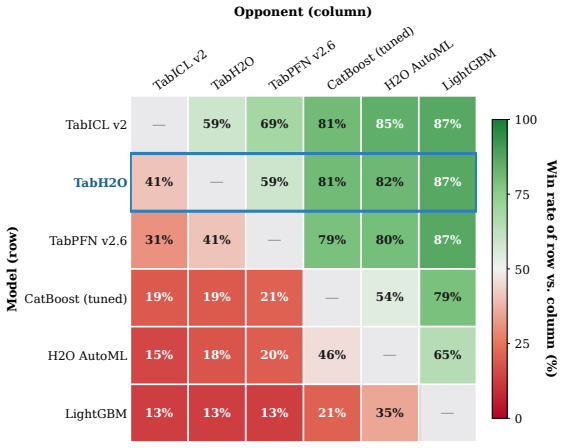
We present TabH2O, a foundation model for tabular data that performs classification and regression in a single forward pass via in-context learning. TabH2O builds on the TabICL architecture with several key modifications: (1) unified training, a single model handles both classification and regression via a dual-head architecture, eliminating the need for separate models and reducing total pretraining cost; (2) single-stage pretraining, training stability improvements (bounded scalable softmax, inter-stage normalization, learnable residual scaling, logit soft-capping) eliminate the need for multi-stage curriculum learning, enabling training with full-length sequences from the start; and (3) noise-aware pretraining, synthetic datasets include explicit noise dimensions to teach the model robustness to irrelevant features. We evaluate TabH2O v1 (29.2M parameters) on the TALENT benchmark (300 datasets), where it achieves an average rank of 2.55 out of 6 evaluated methods, outperforming tuned CatBoost (4.07), H2O AutoML (4.18), and LightGBM (5.08), competitive with TabPFN v2.6 (2.74), and behind TabICL v2 (2.12), while placing in the top-3 on 81% of the testing datasets across classification and regression tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. TabH2O is presented as a unified foundation model for tabular data that performs both classification and regression in a single forward pass via in-context learning. It modifies the TabICL architecture with three changes: (1) unified dual-head training to handle both tasks in one model, (2) single-stage pretraining enabled by stability tricks including bounded scalable softmax, inter-stage normalization, learnable residual scaling, and logit soft-capping, and (3) noise-aware synthetic data that includes explicit noise dimensions. On the TALENT benchmark of 300 datasets, TabH2O v1 (29.2M parameters) reports an average rank of 2.55 out of 6 methods, outperforming tuned CatBoost (4.07), H2O AutoML (4.18), and LightGBM (5.08), competitive with TabPFN v2.6 (2.74), behind TabICL v2 (2.12), and in the top-3 on 81% of datasets.
Significance. If the reported ranking holds under controlled conditions and the gains can be attributed to the three modifications, the work would offer a more compute-efficient unified tabular foundation model that avoids separate task-specific models and multi-stage curricula while adding robustness to irrelevant features. This could reduce pretraining overhead in the tabular domain and provide a practical alternative to existing in-context learners.
major comments (2)
- [Abstract] Abstract: The central claim that TabH2O achieves an average rank of 2.55 due to the three listed modifications (unified dual-head training, single-stage pretraining with stability tricks, and noise-aware synthetic data) is not supported by ablation studies, error bars, or statistical tests. Without matched-compute comparisons or isolation of each change, the ranking could arise from differences in total FLOPs, synthetic dataset scale, or hyperparameter effort rather than the modifications themselves.
- [Evaluation] Evaluation (implied by benchmark results): No details are provided on the number of runs, variance across datasets, or direct head-to-head re-runs of TabICL v2 and TabPFN v2.6 under identical pretraining resources, which is required to substantiate that the stability tricks enable single-stage training without performance loss.
minor comments (2)
- The 29.2M parameter count for TabH2O v1 is stated without corresponding counts or compute budgets for the compared baselines (TabICL v2, TabPFN v2.6), making efficiency claims harder to assess.
- The description of the stability tricks (bounded scalable softmax, inter-stage normalization, etc.) would benefit from a dedicated methods subsection with pseudocode or equations to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below and agree that strengthening the empirical support for our claims will improve the manuscript. We will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract] The central claim that TabH2O achieves an average rank of 2.55 due to the three listed modifications (unified dual-head training, single-stage pretraining with stability tricks, and noise-aware synthetic data) is not supported by ablation studies, error bars, or statistical tests. Without matched-compute comparisons or isolation of each change, the ranking could arise from differences in total FLOPs, synthetic dataset scale, or hyperparameter effort rather than the modifications themselves.
Authors: We acknowledge that the manuscript does not currently include ablation studies isolating each of the three modifications or associated error bars and statistical tests. The reported results reflect the full TabH2O model. In the revision we will add ablation experiments for the dual-head architecture, the stability tricks enabling single-stage pretraining, and the noise-aware synthetic data. We will also report variance where multiple runs are available and discuss compute budgets to address potential confounding factors such as FLOPs or dataset scale. Full matched-compute ablations against every baseline remain resource-intensive but will be included to the extent feasible. revision: yes
-
Referee: [Evaluation] No details are provided on the number of runs, variance across datasets, or direct head-to-head re-runs of TabICL v2 and TabPFN v2.6 under identical pretraining resources, which is required to substantiate that the stability tricks enable single-stage training without performance loss.
Authors: The current evaluation reports average ranks on the TALENT benchmark without specifying the number of runs or variance measures. We will add these details, including any standard deviations or evaluation protocol information, in the revised manuscript. Direct head-to-head re-runs of TabICL v2 and TabPFN v2.6 under identical pretraining resources are not feasible for us at present due to lack of access to their exact training configurations and compute allocations. We will instead provide full details on the resources used for TabH2O and note this limitation while explaining the necessity of the stability tricks based on our internal training observations. revision: partial
- Direct head-to-head re-runs of TabICL v2 and TabPFN v2.6 under identical pretraining resources due to lack of access to their exact setups and compute
Circularity Check
No circularity: empirical benchmark results are externally validated
full rationale
The paper reports empirical ranks on the fixed TALENT benchmark (300 datasets) against external baselines (CatBoost, H2O AutoML, LightGBM, TabPFN v2.6, TabICL v2). These comparisons are direct measurements on held-out data and do not reduce to any internal equation, fitted parameter, or self-citation chain. Architectural modifications (dual-head, stability tricks, noise dimensions) are presented as design choices whose effects are measured externally rather than derived by construction from the evaluation itself. No load-bearing step equates a prediction to its own input or relies on an unverified self-citation for uniqueness.
Axiom & Free-Parameter Ledger
free parameters (1)
- Model parameter count
axioms (1)
- domain assumption In-context learning can be applied directly to tabular inputs for both classification and regression without task-specific retraining.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TabH2O builds on the TabICL architecture with several key modifications: (1) unified training... (2) single-stage pretraining... stability improvements (bounded scalable softmax, inter-stage normalization, learnable residual scaling, logit soft-capping)... (3) noise-aware pretraining—synthetic datasets include explicit noise dimensions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, 33:1877–1901, 2020
work page 1901
-
[2]
XGBoost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. XGBoost: A scalable tree boosting system. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 785–794, 2016
work page 2016
-
[3]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of NAACL-HLT, pages 4171–4186, 2019
work page 2019
-
[4]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
work page 2021
-
[5]
AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
Nick Erickson, Jonas Mueller, Alexander Shirkov, Hang Zhang, Pedro Larroy, Mu Li, and Alexander Smola. AutoGluon-Tabular: Robust and accurate AutoML for structured data.arXiv preprint arXiv:2003.06505, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[6]
TabArena: A living benchmark for machine learning on tabular data
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Prateek Mutalik Desai, David Salinas, and Frank Hutter. TabArena: A living benchmark for machine learning on tabular data. In Advances in Neural Information Processing Systems, 2025. Spotlight
work page 2025
-
[7]
Extremely randomized trees.Machine Learning, 63(1):3–42, 2006
Pierre Geurts, Damien Ernst, and Louis Wehenkel. Extremely randomized trees.Machine Learning, 63(1):3–42, 2006
work page 2006
-
[8]
H2O.ai.H2O AutoML: Scalable automatic machine learning, 2024. Available at https://docs.h2o. ai/h2o/latest-stable/h2o-docs/automl.html
work page 2024
-
[9]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. TabPFN: A transformer that solves small tabular classification problems in a second.arXiv preprint arXiv:2207.01848, 2023. Published at ICLR 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
work page 2025
-
[11]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan, Yuchen Jin, Vlado Boza, You Jiacheng, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024
work page 2024
-
[12]
LightGBM: A highly efficient gradient boosting decision tree
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. LightGBM: A highly efficient gradient boosting decision tree. InAdvances in Neural Information Processing Systems, volume 30, 2017
work page 2017
-
[13]
Kosiorek, Seungjin Choi, and Yee Whye Teh
Juho Lee, Yoonho Lee, Jungtaek Kim, Adam R. Kosiorek, Seungjin Choi, and Yee Whye Teh. Set transformer: A framework for attention-based permutation-invariant neural networks. InInternational Conference on Machine Learning, pages 3744–3753, 2019
work page 2019
-
[14]
arXiv preprint arXiv:2407.04057 , year=
Si-Yang Liu, Hao-Run Cai, Qi-Le Zhou, and Han-Jia Ye. TALENT: A tabular analytics and learning toolbox.arXiv preprint arXiv:2407.04057, 2024
-
[15]
Cambridge University Press, 2nd edition, 2009
Judea Pearl.Causality: Models, Reasoning, and Inference. Cambridge University Press, 2nd edition, 2009
work page 2009
-
[16]
CatBoost: Unbiased boosting with categorical features
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr V orobev, Anna Veronika Dorogush, and Andrey Gulin. CatBoost: Unbiased boosting with categorical features. InAdvances in Neural Information Processing Systems, volume 31, 2018
work page 2018
-
[17]
TabICL: A Tabular Foundation Model for In-Context Learning on Large Data
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. TabICL: A tabular foundation model for in-context learning on large data.arXiv preprint arXiv:2502.05564, 2025. Published at ICML 2025
work page internal anchor Pith review arXiv 2025
-
[18]
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. TabICLv2: A better, faster, scalable, and open tabular foundation model.arXiv preprint arXiv:2602.11139, 2026
-
[19]
RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024. 11
work page 2024
-
[20]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30, 2017
work page 2017
-
[21]
Root mean square layer normalization
Biao Zhang and Rico Sennrich. Root mean square layer normalization. InAdvances in Neural Information Processing Systems, volume 32, 2019. A TALENT Benchmark Details The TALENT benchmark [14] consists of 300 tabular datasets covering three types of tasks: (i) Binary classificationwith 120 datasets, (ii)Multiclass classificationwith 80 datasets, and (iii) R...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.