PERL: Parameter Efficient Reasoning in CLIP Latent Space
Pith reviewed 2026-05-20 11:41 UTC · model grok-4.3
The pith
A recurrent reasoning module with roughly 6K parameters adapts frozen CLIP models for few-shot tasks while keeping open-vocabulary performance intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PERL augments a frozen CLIP model with a compact shared reasoning module applied recurrently across refinement steps. At each step the module produces a latent reasoning token conditioned on the current representation and injects it into an intermediate encoder layer, progressively refining higher-level semantic representations while preserving the pretrained multimodal structure.
What carries the argument
a compact shared reasoning module applied recurrently across refinement steps that generates a latent reasoning token and injects it into an intermediate encoder layer
If this is right
- Strong accuracy on novel classes alongside competitive transfer to new datasets
- Only about 6K trainable parameters required under few-shot fast adaptation
- Up to 817 times fewer parameters than the largest compared adaptation methods
- Best overall parameter-performance trade-off across 15 benchmarks including out-of-distribution ImageNet variants
- Iterative latent reasoning acts as a complementary mechanism to simply scaling parameter count
Where Pith is reading between the lines
- The same recurrent-injection pattern could be tested on other frozen multimodal encoders to check whether the low-parameter benefit generalizes beyond CLIP
- Because the module is shared and small, the approach may allow on-device adaptation where memory for extra weights is limited
- Future work could measure how many refinement steps are needed before returns diminish, turning the number of iterations into a controllable hyperparameter
Load-bearing premise
Repeated application of the shared reasoning module improves task-specific representations without eroding the frozen CLIP model's original multimodal alignment or creating instability in the latent space.
What would settle it
A measurable drop in zero-shot accuracy on standard CLIP evaluation sets after several refinement steps would show that the recurrent injection harms the pretrained alignment.
Figures








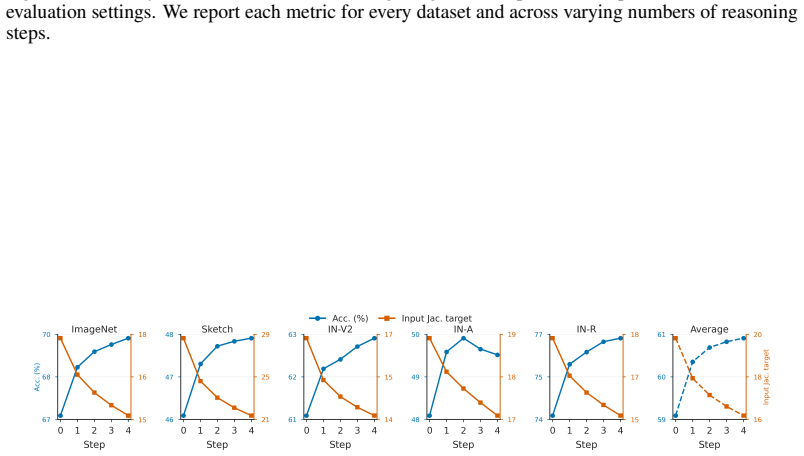







read the original abstract
Contrastively trained vision-language models such as CLIP provide strong zero-shot transfer by aligning images and text in a shared embedding space. However, adapting these models to downstream tasks without degrading their open-vocabulary generalization remains challenging. Existing parameter-efficient adaptation methods typically improve task specialization through learned prompts, adapters, or multimodal transformations, where adaptation capacity is primarily expressed through additional trainable parameters. Inspired by recent latent reasoning methods in language models, we investigate a complementary perspective: can adaptation emerge from iterative reasoning on latent representations rather than from increasing parameter count alone? We introduce PERL (Parameter-Efficient Reasoning in CLIP Latent Space), a lightweight adaptation framework that augments a frozen CLIP model with a compact shared reasoning module applied recurrently across refinement steps. At each step, PERL generates a latent reasoning token conditioned on the current representation and injects it into an intermediate encoder layer, progressively refining higher-level semantic representations while preserving CLIP's pretrained multimodal structure. Across 15 benchmarks spanning base-to-novel generalization, cross-dataset transfer, and out-of-distribution ImageNet variants, PERL achieves the best parameter-performance trade-off among the compared methods under a fast-adaptation few-shot setting, combining strong novel-class accuracy and competitive transfer performance with only about 6K trainable parameters, up to 817x fewer than the largest compared approach. Overall, our results suggest that iterative latent reasoning provides a complementary adaptation mechanism to parameter scaling in discriminative vision-language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PERL, a parameter-efficient adaptation framework for frozen CLIP vision-language models. It augments the model with a compact shared reasoning module (~6K trainable parameters) that is applied recurrently: at each refinement step the module generates a latent reasoning token conditioned on the current representation and injects it into an intermediate encoder layer, with the goal of progressively refining higher-level semantics while preserving the pretrained multimodal alignment. The central empirical claim is that this approach achieves the best parameter-performance trade-off across 15 benchmarks (base-to-novel generalization, cross-dataset transfer, and ImageNet OOD variants) in a fast-adaptation few-shot setting, outperforming or matching prior methods while using up to 817× fewer parameters.
Significance. If the performance claims and the preservation of alignment are substantiated, the work would demonstrate that iterative latent-space reasoning can serve as a complementary adaptation mechanism to parameter scaling in discriminative vision-language models, enabling strong generalization with extremely low parameter budgets.
major comments (2)
- [Method] Method section (description of recurrent injection): the claim that recurrent application of the shared reasoning module 'progressively refines higher-level semantic representations while preserving CLIP's pretrained multimodal structure' is load-bearing for the central contribution, yet the manuscript provides no direct verification (pre/post cosine similarities between image and text embeddings, or zero-shot transfer ablations before and after refinement steps). Downstream accuracy numbers alone cannot distinguish true reasoning from task-specific drift.
- [Experiments] Experiments section (benchmark results): the reported best parameter-performance trade-off rests on comparisons with prior methods, but without an ablation that isolates the effect of the number of recurrent steps (e.g., 1-step vs. 3-step vs. 5-step) on both novel-class accuracy and zero-shot transfer capability, it remains unclear whether additional steps improve or erode the pretrained alignment.
minor comments (2)
- [Method] The notation for the latent reasoning token and its injection point should be formalized with an equation or pseudocode block to make the recurrent update rule unambiguous.
- [Experiments] Table captions and axis labels in the main results figure should explicitly state the number of shots and the exact parameter counts for each baseline to facilitate direct comparison.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback on our manuscript. We address each of the major comments below, providing clarifications and indicating where we will incorporate revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Method] Method section (description of recurrent injection): the claim that recurrent application of the shared reasoning module 'progressively refines higher-level semantic representations while preserving CLIP's pretrained multimodal structure' is load-bearing for the central contribution, yet the manuscript provides no direct verification (pre/post cosine similarities between image and text embeddings, or zero-shot transfer ablations before and after refinement steps). Downstream accuracy numbers alone cannot distinguish true reasoning from task-specific drift.
Authors: We agree that direct verification of alignment preservation would strengthen the central claim. Although our competitive zero-shot transfer results across multiple benchmarks provide indirect evidence that the pretrained multimodal structure is largely maintained, we acknowledge that explicit metrics such as pre- and post-refinement cosine similarities between image and text embeddings, as well as zero-shot ablations at different refinement steps, would more convincingly distinguish iterative reasoning from potential task-specific drift. We will add these analyses to the revised manuscript, including quantitative measurements of embedding similarities and corresponding zero-shot performance evaluations. revision: yes
-
Referee: [Experiments] Experiments section (benchmark results): the reported best parameter-performance trade-off rests on comparisons with prior methods, but without an ablation that isolates the effect of the number of recurrent steps (e.g., 1-step vs. 3-step vs. 5-step) on both novel-class accuracy and zero-shot transfer capability, it remains unclear whether additional steps improve or erode the pretrained alignment.
Authors: We appreciate this suggestion for a more granular ablation study. The current experiments focus on the performance achieved with our selected number of recurrent steps, but to better isolate the contribution of iterative refinement, we will include an ablation varying the number of steps (specifically comparing 1, 3, and 5 steps) and report the impacts on novel-class accuracy as well as zero-shot transfer performance. This will help clarify whether additional steps enhance or potentially degrade the alignment. revision: yes
Circularity Check
No circularity: empirical method proposal with independent benchmark validation
full rationale
The paper introduces PERL as a lightweight recurrent reasoning module for adapting frozen CLIP models and supports its claims exclusively through empirical results on 15 benchmarks covering base-to-novel generalization, cross-dataset transfer, and OOD variants. No mathematical derivation, first-principles prediction, or uniqueness theorem is presented that reduces to fitted inputs or self-citations by construction. The recurrent injection mechanism is a design choice whose effectiveness is measured by downstream accuracy and parameter count, not by any self-referential loop where outputs are defined as inputs. This is a standard empirical contribution whose central claims remain independent of the paper's own definitions or prior self-citations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The base CLIP model remains frozen throughout adaptation to preserve its pretrained multimodal structure.
invented entities (1)
-
latent reasoning token
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deep equilibrium models.Advances in neural information processing systems, 32, 2019
Shaojie Bai, J Zico Kolter, and Vladlen Koltun. Deep equilibrium models.Advances in neural information processing systems, 32, 2019
work page 2019
-
[2]
Food-101–mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101–mining discriminative components with random forests. InEuropean conference on computer vision, pages 446–461. Springer, 2014
work page 2014
-
[3]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3606–3613, 2014
work page 2014
-
[4]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Lukasz Kaiser. Uni- versal transformers. InInternational Conference on Learning Representations
-
[5]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
work page 2009
-
[6]
Li Fei-Fei, Rob Fergus, and Pietro Perona. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. In2004 conference on computer vision and pattern recognition workshop, pages 178–178. IEEE, 2004
work page 2004
-
[7]
Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li, and Yu Qiao. Clip-adapter: Better vision-language models with feature adapters.International journal of computer vision, 132(2):581–595, 2024
work page 2024
-
[8]
Looped transformers as programmable computers
Angeliki Giannou, Shashank Rajput, Jy-yong Sohn, Kangwook Lee, Jason D Lee, and Dimitris Papailiopoulos. Looped transformers as programmable computers. InInternational Conference on Machine Learning, pages 11398–11442. PMLR, 2023
work page 2023
-
[9]
Mmrl: Multi-modal representation learning for vision- language models
Yuncheng Guo and Xiaodong Gu. Mmrl: Multi-modal representation learning for vision- language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 25015–25025, 2025
work page 2025
-
[10]
Yuncheng Guo and Xiaodong Gu. Mmrl++: Parameter-efficient and interaction-aware repre- sentation learning for vision-language models, 2025. URL https://arxiv.org/abs/2505. 10088
work page 2025
-
[11]
Training large language models to reason in a continuous latent space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason E Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space. InSecond Conference on Language Modeling
-
[12]
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12(7):2217–2226, 2019
work page 2019
-
[13]
The many faces of robustness: A critical analysis of out-of-distribution generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, et al. The many faces of robustness: A critical analysis of out-of-distribution generalization. InProceedings of the IEEE/CVF international conference on computer vision, pages 8340–8349, 2021
work page 2021
-
[14]
Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Steinhardt, and Dawn Song. Natural adversarial examples. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15262–15271, 2021
work page 2021
-
[15]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. InInternational conference on machine learning, pages 2790–2799. PMLR, 2019
work page 2019
-
[16]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022. 11
work page 2022
-
[17]
Fast quiet-star: Thinking without thought tokens.CoRR, abs/2505.17746, 2025
Wei Huang, Yizhe Xiong, Xin Ye, Zhijie Deng, Hui Chen, Zijia Lin, and Guiguang Ding. Fast quiet-star: Thinking without thought tokens.CoRR, abs/2505.17746, 2025
-
[18]
Maple: Multi-modal prompt learning
Muhammad Uzair Khattak, Hanoona Rasheed, Muhammad Maaz, Salman Khan, and Fa- had Shahbaz Khan. Maple: Multi-modal prompt learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19113–19122, June 2023
work page 2023
-
[19]
Self-regulating prompts: Foundational model adaptation without forgetting
Muhammad Uzair Khattak, Syed Talal Wasim, Muzammal Naseer, Salman Khan, Ming-Hsuan Yang, and Fahad Shahbaz Khan. Self-regulating prompts: Foundational model adaptation without forgetting. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15190–15200, October 2023
work page 2023
-
[20]
3d object representations for fine- grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine- grained categorization. InProceedings of the IEEE international conference on computer vision workshops, pages 554–561, 2013
work page 2013
-
[21]
Fine-Grained Visual Classification of Aircraft
Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. Fine- grained visual classification of aircraft.arXiv preprint arXiv:1306.5151, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[22]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In2008 Sixth Indian conference on computer vision, graphics & image processing, pages 722–729. IEEE, 2008
work page 2008
-
[23]
Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. In2012 IEEE conference on computer vision and pattern recognition, pages 3498–3505. IEEE, 2012
work page 2012
-
[24]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machin...
work page 2021
-
[25]
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do imagenet classifiers generalize to imagenet? InInternational conference on machine learning, pages 5389–5400. PMLR, 2019
work page 2019
-
[26]
Reasoning with latent thoughts: On the power of looped transformers
Nikunj Saunshi, Nishanth Dikkala, Zhiyuan Li, Sanjiv Kumar, and Sashank J Reddi. Reasoning with latent thoughts: On the power of looped transformers. InThe Thirteenth International Conference on Learning Representations
-
[27]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[28]
Haohan Wang, Songwei Ge, Zachary Lipton, and Eric P Xing. Learning robust global repre- sentations by penalizing local predictive power.Advances in neural information processing systems, 32, 2019
work page 2019
-
[29]
Sun database: Large-scale scene recognition from abbey to zoo
Jianxiong Xiao, James Hays, Krista A Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recognition from abbey to zoo. In2010 IEEE computer society conference on computer vision and pattern recognition, pages 3485–3492. IEEE, 2010
work page 2010
-
[30]
Progressive visual prompt learning with contrastive feature re-formation,
Chen Xu, Yuhan Zhu, Haocheng Shen, Fengyuan Shi, Boheng Chen, Yixuan Liao, Xiaoxin Chen, and Limin Wang. Progressive visual prompt learning with contrastive feature re-formation,
- [31]
-
[32]
Mma: Multi-modal adapter for vision-language models
Lingxiao Yang, Ru-Yuan Zhang, Yanchen Wang, and Xiaohua Xie. Mma: Multi-modal adapter for vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 23826–23837, June 2024. 12
work page 2024
-
[33]
Visual-language prompt tuning with knowledge- guided context optimization
Hantao Yao, Rui Zhang, and Changsheng Xu. Visual-language prompt tuning with knowledge- guided context optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6757–6767, June 2023
work page 2023
-
[34]
Tcp:textual-based class-aware prompt tuning for visual-language model
Hantao Yao, Rui Zhang, and Changsheng Xu. Tcp:textual-based class-aware prompt tuning for visual-language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 23438–23448, June 2024
work page 2024
-
[35]
Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
Eric Zelikman, Georges Harik, Yijia Shao, Varuna Jayasiri, Nick Haber, and Noah D Goodman. Quiet-star: Language models can teach themselves to think before speaking.arXiv preprint arXiv:2403.09629, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Ji Zhang, Shihan Wu, Lianli Gao, Heng Tao Shen, and Jingkuan Song. Dept: Decoupled prompt tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12924–12933, 2024
work page 2024
-
[37]
Conditional prompt learning for vision-language models
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Conditional prompt learning for vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16816–16825, June 2022
work page 2022
-
[38]
International Journal of Computer Vision , author =
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.Int. J. Comput. Vis., 130(9):2337–2348, 2022. doi: 10.1007/ S11263-022-01653-1. URLhttps://doi.org/10.1007/s11263-022-01653-1
-
[39]
Scaling Latent Reasoning via Looped Language Models
Rui-Jie Zhu, Zixuan Wang, Kai Hua, Tianyu Zhang, Ziniu Li, Haoran Que, Boyi Wei, Zixin Wen, Fan Yin, He Xing, et al. Scaling latent reasoning via looped language models.arXiv preprint arXiv:2510.25741, 2025. 13 Technical appendices and supplementary material A Implementation Details We use OpenAI CLIP with a ViT-B/16 visual backbone (vision hiddendv =768,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.