Trust or Abstain? A Self-Aware RAG Approach
Pith reviewed 2026-05-20 22:58 UTC · model grok-4.3
The pith
SABER lets RAG systems judge whether to trust their own knowledge, the retrieved context, or abstain when the two conflict.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
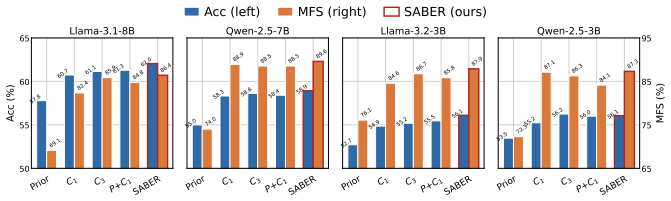
SABER is a Self-Aware Belief Estimator for RAG that requires no LLM fine-tuning. It combines a self-prior with PK-side and CK-side conditional reasoning representations from multi-trace inference, then estimates reliability beliefs with two lightweight predictors to drive a 4-cell decision over trust PK, trust CK, trust either, or abstain. Across four LLM backbones, SABER improves end-to-end accuracy and conflict-specific faithfulness over ten inference-time and fine-tuning baselines, with the largest gains on conflict-heavy datasets. Under abstention, SABER's risk-coverage curve Pareto-dominates every prompt-based abstainer.
What carries the argument
The four-cell decision rule driven by reliability beliefs that are estimated from multi-trace conditional reasoning representations using two lightweight predictors.
If this is right
- End-to-end accuracy rises most on datasets where knowledge conflicts are frequent.
- Conflict-specific faithfulness improves over both inference-time and fine-tuning baselines.
- Abstention provides a tunable coverage-risk trade-off that Pareto-dominates prompt-based abstainers.
- The same gains appear across four different LLM backbones without retraining them.
Where Pith is reading between the lines
- The same lightweight-predictor idea could be tested on non-RAG tasks where an LLM must decide whether to answer from memory or decline.
- If the predictors remain accurate when the underlying LLM is updated, the method could reduce repeated fine-tuning costs in production RAG pipelines.
- The benchmark construction process itself offers a reusable way to measure self-awareness on any new set of conflict datasets.
Load-bearing premise
Multi-trace inference must produce conditional reasoning representations that the two lightweight predictors can turn into accurate reliability beliefs without any fine-tuning of the base LLM.
What would settle it
A direct test in which the reliability scores output by the predictors show little or no correlation with actual answer correctness on held-out conflict instances would show that the four-cell rule cannot deliver the reported accuracy and faithfulness gains.
Figures






read the original abstract
Retrieval-augmented generation (RAG) improves large language models (LLMs) by incorporating external evidence, but it also introduces knowledge conflicts when retrieved contextual knowledge (CK) and parametric knowledge (PK) disagree or are both unreliable. Existing approaches mainly coordinate which source to use, without explicitly asking whether each answer path is correct. We argue that faithful RAG requires LLM self-awareness, namely the ability to recognize the limits of its own knowledge and reasoning. To ground this problem, we construct a model-specific, ground-truth-aligned knowledge-conflict benchmark by evaluating LLM backbones on PK-only and CK-conditioned answer paths over approximately 69K query-context instances per backbone, drawn from five conflict-QA datasets. We then introduce SABER, a Self-Aware Belief Estimator for RAG that requires no LLM fine-tuning. SABER combines a self-prior with PK-side and CK-side conditional reasoning representations from multi-trace inference, then estimates reliability beliefs with two lightweight predictors to drive a 4-cell decision over trust PK, trust CK, trust either, or abstain. Across four LLM backbones, SABER improves end-to-end accuracy and conflict-specific faithfulness over ten inference-time and fine-tuning baselines, with the largest gains on conflict-heavy datasets. Under abstention, SABER's risk-coverage curve Pareto-dominates every prompt-based abstainer, providing a tunable balance between coverage and answer risk. Our code is available at https://github.com/xizhu1022/SABER.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SABER, a Self-Aware Belief Estimator for RAG that performs multi-trace inference on parametric-knowledge-only and contextual-knowledge-conditioned paths, combines these representations with a self-prior, and feeds them to two lightweight predictors to produce reliability beliefs. These beliefs drive a 4-cell decision rule (trust PK, trust CK, trust either, or abstain) without any LLM fine-tuning. The authors construct a model-specific benchmark of approximately 69K query-context instances per backbone from five conflict-QA datasets, evaluate on four LLM backbones, and claim higher end-to-end accuracy and conflict-specific faithfulness than ten inference-time and fine-tuning baselines, with the largest gains on conflict-heavy data; under abstention, SABER's risk-coverage curve Pareto-dominates prompt-based abstainers.
Significance. If the empirical claims hold, the work offers a practical route to more reliable RAG by adding explicit self-awareness at inference time only. The construction of a large, model-specific, ground-truth-aligned conflict benchmark and the release of code are clear strengths that support reproducibility and further research on tunable abstention.
major comments (2)
- [Section 4 and Section 5] Section 4 (Method) and Section 5 (Experiments): the central claim that the two lightweight predictors produce accurate reliability beliefs from multi-trace representations rests on the assumption that these representations capture genuine conflict signals rather than surface artifacts. No calibration plots, precision-recall curves, or feature-importance analysis for the predictors are reported, even though the method explicitly avoids LLM fine-tuning and places the entire burden on this mapping. This omission is load-bearing for attributing the reported accuracy and faithfulness gains to self-awareness.
- [Section 5.3] Section 5.3 (Results): while the paper states that SABER improves accuracy and faithfulness across four backbones and Pareto-dominates risk-coverage curves, the abstract and main results lack error bars, statistical significance tests, or detailed descriptions of how the ten baselines were implemented and tuned. Without these, it is difficult to verify that the observed gains are robust and not artifacts of implementation choices.
minor comments (2)
- [Abstract] Abstract: the summary of results mentions accuracy and faithfulness gains but supplies no concrete numbers, dataset breakdowns, or confidence intervals, which reduces immediate clarity.
- [Section 3] Notation in Section 3: the precise feature vectors passed to the PK-side and CK-side predictors should be defined more explicitly, including how the self-prior is combined with the conditional representations.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the presentation of our empirical results. We address each major comment below, indicating the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Section 4 and Section 5] Section 4 (Method) and Section 5 (Experiments): the central claim that the two lightweight predictors produce accurate reliability beliefs from multi-trace representations rests on the assumption that these representations capture genuine conflict signals rather than surface artifacts. No calibration plots, precision-recall curves, or feature-importance analysis for the predictors are reported, even though the method explicitly avoids LLM fine-tuning and places the entire burden on this mapping. This omission is load-bearing for attributing the reported accuracy and faithfulness gains to self-awareness.
Authors: We agree that providing additional diagnostic analyses would better substantiate that the multi-trace PK and CK representations capture genuine conflict signals. In the revised version, we will add calibration plots for the reliability belief predictors, precision-recall curves evaluating their performance on held-out data, and a feature importance analysis (e.g., via permutation importance or coefficient inspection for the lightweight models) to demonstrate that the predictors rely on conflict-relevant features rather than superficial patterns. These additions will directly address the attribution of gains to the self-awareness mechanism. revision: yes
-
Referee: [Section 5.3] Section 5.3 (Results): while the paper states that SABER improves accuracy and faithfulness across four backbones and Pareto-dominates risk-coverage curves, the abstract and main results lack error bars, statistical significance tests, or detailed descriptions of how the ten baselines were implemented and tuned. Without these, it is difficult to verify that the observed gains are robust and not artifacts of implementation choices.
Authors: We acknowledge the importance of statistical rigor and detailed baseline descriptions for verifying the robustness of our results. In the revision, we will include error bars (standard deviation across multiple runs or seeds) in the main results tables and figures. We will also report statistical significance tests, such as paired t-tests or Wilcoxon signed-rank tests, for the accuracy and faithfulness improvements over baselines. Furthermore, we will expand Section 5.3 and the appendix with detailed descriptions of each baseline's implementation, including hyperparameter tuning procedures, prompt templates, and any model-specific adaptations to ensure full reproducibility. revision: yes
Circularity Check
No significant circularity; SABER uses trained lightweight predictors on a constructed benchmark without reducing claims to self-definition or tautological fits
full rationale
The paper constructs a model-specific benchmark (~69K instances per backbone) by running LLM evaluations on PK-only and CK-conditioned paths to obtain ground-truth correctness labels. It then feeds multi-trace inference representations into two lightweight predictors (combined with a self-prior) to produce reliability beliefs that drive the 4-cell trust/abstain decision. This is a standard supervised learning pipeline rather than any self-definitional loop, fitted input renamed as prediction, or load-bearing self-citation. The reported end-to-end accuracy gains and risk-coverage Pareto dominance are measured against external baselines on the same benchmark data; the method introduces independent components (multi-trace representations and predictors) whose mapping is not equivalent to the inputs by construction. No equations or ansatzes reduce the central claim to prior fitted quantities or author-specific uniqueness theorems. The derivation remains self-contained as an empirical RAG technique.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-trace inference on PK-only and CK-conditioned paths produces representations that support accurate reliability belief estimation via lightweight predictors
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SABER combines a self-prior with PK-side and CK-side conditional reasoning representations from multi-trace inference, then estimates reliability beliefs with two lightweight predictors to drive a 4-cell decision over trust PK, trust CK, trust either, or abstain.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We sample K independent reasoning traces per side and mean-pool their per-trace vectors into a robust per-side conditional state
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Self-rag: Learning to retrieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learning to retrieve, generate, and critique through self-reflection. InInternational Conference on Learning Representations, 2024
work page 2024
-
[2]
The Internal State of an LLM Knows When It's Lying
Amos Azaria and Tom Mitchell. The internal state of an llm knows when it’s lying.arXiv preprint arXiv:2304.13734, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Context-DPO: Aligning language models for context-faithfulness.arXiv preprint arXiv:2412.15280, 2024
Baolong Bi, Shenghua Huang, Yiwei Wang, Tianchi Yang, Zhongyu Zhang, Haizhou Huang, Lijie Mei, Junfeng Fang, Zehao Li, Furu Wei, et al. Context-DPO: Aligning language models for context-faithfulness.arXiv preprint arXiv:2412.15280, 2024
-
[4]
Discovering Latent Knowledge in Language Models Without Supervision
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision.arXiv preprint arXiv:2212.03827, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
INSIDE: LLMs’ internal states retain the power of hallucination detection
Chao Chen, Kai Liu, Ze Chen, Yi Gu, Yue Wu, Mingyuan Tao, Zhihang Fu, and Jieping Ye. INSIDE: LLMs’ internal states retain the power of hallucination detection. InInternational Conference on Learning Representations, 2024
work page 2024
-
[6]
Lihu Chen, Gerard de Melo, Fabian M. Suchanek, and Gaël Varoquaux. Query-level uncertainty in large language models. InInternational Conference on Learning Representations, 2026
work page 2026
-
[7]
Beyond Black-Box Interventions: Latent Probing for Faithful Retrieval-Augmented Generation
Linfeng Gao, Qinggang Zhang, Baolong Bi, Bo Zeng, Zheng Yuan, Zerui Chen, Zhimin Wei, Shenghua Liu, Linlong Xu, Longyue Wang, Weihua Luo, and Jinsong Su. Beyond black- box interventions: Latent probing for faithful retrieval-augmented generation.arXiv preprint arXiv:2510.12460, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Selective classification for deep neural networks
Yonatan Geifman and Ran El-Yaniv. Selective classification for deep neural networks. In Advances in Neural Information Processing Systems, 2017
work page 2017
-
[9]
Amirhosein Ghasemabadi and Di Niu. Can llms predict their own failures? self-awareness via internal circuits.arXiv preprint arXiv:2512.20578, 2026
-
[10]
DeepSieve: Information sieving via LLM-as-a-knowledge-router
Minghao Guo, Qingcheng Zeng, Xujiang Zhao, Yanchi Liu, Wenchao Yu, Mengnan Du, Haifeng Chen, and Wei Cheng. DeepSieve: Information sieving via LLM-as-a-knowledge-router. In Findings of the Association for Computational Linguistics: EACL 2026, 2026
work page 2026
-
[11]
WikiContradict: A benchmark for evaluating LLMs on real-world knowledge conflicts from Wikipedia
Yufang Hou, Alessandra Pascale, Javier Carnerero-Cano, Tigran Tchrakian, Radu Marinescu, Elizabeth Daly, Inkit Padhi, and Prasanna Sattigeri. WikiContradict: A benchmark for evaluating LLMs on real-world knowledge conflicts from Wikipedia. InAdvances in Neural Information Processing Systems, 2024. Datasets and Benchmarks Track
work page 2024
-
[12]
Yukun Huang, Sanxing Chen, Hongyi Cai, and Bhuwan Dhingra. To trust or not to trust? enhancing large language models’ situated faithfulness to external contexts. InInternational Conference on Learning Representations, 2025
work page 2025
-
[13]
Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong C. Park. Adaptive-rag: Learning to adapt retrieval-augmented large language models through question complexity. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics, 2024
work page 2024
-
[14]
Massive values in self-attention modules are the key to contextual knowledge understanding
Mingyu Jin, Kai Mei, Wujiang Xu, Mingjie Sun, Ruixiang Tang, Mengnan Du, Zirui Liu, and Yongfeng Zhang. Massive values in self-attention modules are the key to contextual knowledge understanding. InInternational Conference on Machine Learning, 2025
work page 2025
-
[15]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Retrieval-augmented generation for knowledge-intensive nlp tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks. InAdvances in Neural Information Processing Systems, 2020. 10
work page 2020
-
[17]
Teaching Models to Express Their Uncertainty in Words
Stephanie Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words.arXiv preprint arXiv:2205.14334, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Entity-based knowledge conflicts in question answering.arXiv preprint arXiv:2109.05052, 2021
Shayne Longpre, Kartik Perisetla, Anthony Chen, Nikhil Ramesh, Chris DuBois, and Sameer Singh. Entity-based knowledge conflicts in question answering.arXiv preprint arXiv:2109.05052, 2021
-
[19]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Ha- jishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics, 2023
work page 2023
-
[20]
R-WoM: Retrieval-augmented world model for computer-use agents.arXiv preprint arXiv:2510.11892, 2025
Kai Mei, Jiang Guo, Shuaichen Chang, Mingwen Dong, Dongkyu Lee, Xing Niu, and Jiarong Jiang. R-WoM: Retrieval-augmented world model for computer-use agents.arXiv preprint arXiv:2510.11892, 2025
-
[21]
Jingwei Ni, Ekaterina Fadeeva, Tianyi Wu, Mubashara Akhtar, Jiaheng Zhang, Elliott Ash, Markus Leippold, Timothy Baldwin, See-Kiong Ng, Artem Shelmanov, and Mrinmaya Sachan. Reprobe: Efficient test-time scaling of multi-step reasoning by probing internal states of large language models.arXiv preprint arXiv:2511.06209, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Weijia Shi, Xiaochuang Han, Mike Lewis, Yulia Tsvetkov, Luke Zettlemoyer, and Scott Yih. Trusting your evidence: Hallucinate less with context-aware decoding.arXiv preprint arXiv:2305.14739, 2024
-
[23]
Weihang Su, Yichen Tang, Qingyao Ai, Zhijing Wu, and Yiqun Liu. Dragin: Dynamic retrieval augmented generation based on the information needs of large language models.arXiv preprint arXiv:2403.10081, 2024
-
[24]
Zhaochen Su, Jun Zhang, Xiaoye Qu, Tong Zhu, Yanshu Li, Jiashuo Sun, Juntao Li, Min Zhang, and Yu Cheng. ConflictBank: A benchmark for evaluating knowledge conflicts in large language models.arXiv preprint arXiv:2408.12076, 2024
-
[25]
Han Wang, Akshat Shrivastava, Junyi Jessy Hu, Yash Lal, Manzil Zaheer, Mohammad Javad Hosseini, Sheng-Chieh Lin, Veselin Stoyanov, and Wen-tau Yih. AdaCAD: Adaptively de- coding to balance conflicts between contextual and parametric knowledge.arXiv preprint arXiv:2409.07394, 2025
- [26]
-
[27]
RAGRouter-Bench: A Dataset and Benchmark for Adaptive RAG Routing
Ziqi Wang, Xi Zhu, Shuhang Lin, Haochen Xue, Minghao Guo, and Yongfeng Zhang. RAGRouter-Bench: A dataset and benchmark for adaptive RAG routing.arXiv preprint arXiv:2602.00296, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Bingbing Wen, Jihan Yao, Shangbin Feng, Chenjun Xu, Yulia Tsvetkov, Bill Howe, and Lucy Lu Wang. Know your limits: A survey of abstention in large language models.arXiv preprint arXiv:2407.18418, 2025
-
[29]
Clasheval: Quantifying the tug-of-war between an llm’s internal prior and external evidence
Kevin Wu, Eric Wu, and James Zou. Clasheval: Quantifying the tug-of-war between an llm’s internal prior and external evidence. InAdvances in Neural Information Processing Systems,
-
[30]
Datasets and Benchmarks Track
-
[31]
Jian Xie, Kai Zhang, Jiangjie Chen, Renze Lou, and Yu Su. Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts. InInternational Conference on Learning Representations, 2024
work page 2024
-
[32]
Knowledge conflicts for LLMs: A survey
Rongwu Xu, Zehan Qi, Zhijiang Guo, Cunxiang Wang, Hongru Wang, Yue Zhang, and Wei Xu. Knowledge conflicts for LLMs: A survey. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024. 11
work page 2024
-
[33]
SeaKR: Self-aware knowledge retrieval for adaptive retrieval augmented generation
Zijun Yao, Weijian Qi, Liangming Pan, Shulin Cao, Linmei Hu, Weichuan Liu, Lei Hou, and Juanzi Li. SeaKR: Self-aware knowledge retrieval for adaptive retrieval augmented generation. arXiv preprint arXiv:2406.19215, 2025
-
[34]
Zhangyue Yin, Qiushi Sun, Qipeng Guo, Jiawen Wu, Xipeng Qiu, and Xuanjing Huang. Do large language models know what they don’t know? InFindings of the Association for Computational Linguistics: ACL 2023, 2023
work page 2023
-
[35]
Tian Yu, Shaolei Zhang, and Yang Feng. Truth-aware context selection: Mitigating hal- lucinations of large language models being misled by untruthful contexts.arXiv preprint arXiv:2403.07556, 2024
-
[36]
Fung, Qing Lian, Xingyao Wang, Yangyi Chen, Heng Ji, and Tong Zhang
Hanning Zhang, Shizhe Diao, Yong Lin, Yi R. Fung, Qing Lian, Xingyao Wang, Yangyi Chen, Heng Ji, and Tong Zhang. R-Tuning: Instructing large language models to say ‘I don’t know’. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics, 2024
work page 2024
-
[37]
Faithfulrag: Fact-level conflict modeling for context-faithful retrieval-augmented generation
Qinggang Zhang, Zhishang Xiang, Yilin Xiao, Le Wang, Junhui Li, Xinrun Wang, and Jinsong Su. Faithfulrag: Fact-level conflict modeling for context-faithful retrieval-augmented generation. arXiv preprint arXiv:2506.08938, 2025. 12 Appendix A Implementation Details A.1 Probe architecture and training The two side-specific reliability predictors fpred,PK and...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.