The impact of observation density on Bayesian inversion of latent dynamics in shock-dominated flows
Pith reviewed 2026-05-20 11:34 UTC · model grok-4.3
The pith
Increasing the density of observations in Bayesian inversion of shock-tube initial states contracts posterior uncertainty by roughly three-quarters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors show that, within their autoencoder-based latent dynamical model of the Sod shock tube, denser sets of final-time observations drive a large contraction in the posterior uncertainty of the recovered left and right density and pressure values. The framework recovers the rarefaction wave, contact discontinuity, and shock front with good fidelity once the latent dimension reaches 32 and roughly 250 training trajectories are available, and the NUTS sampler then yields well-calibrated uncertainty estimates whose spread shrinks sharply as more observation locations are added.
What carries the argument
A convolutional autoencoder that compresses flow snapshots into a 32-dimensional nonlinear latent representation, combined with a learned latent-space forward operator that predicts the final-time latent state from an encoded initial state.
If this is right
- The surrogate enables thousands of forward evaluations inside the sampler at a cost that full-order models cannot sustain.
- A latent dimension of 32 supplies enough capacity to reconstruct the main shock-tube features while keeping the inverse problem tractable.
- Two hundred fifty high-fidelity trajectories are already sufficient to train an accurate reconstruction.
- The same workflow can be applied to other initial-state recovery tasks once the autoencoder is retrained on the target flow family.
Where Pith is reading between the lines
- Sensor networks for compressible-flow experiments could be designed by placing new probes where they most reduce the remaining posterior variance.
- The same latent-dynamics approach may transfer to inverse problems in other nonlinear wave systems such as detonations or supersonic inlets.
- If the latent dimension is increased beyond 32, the extra cost of sampling must be weighed against any further uncertainty reduction.
Load-bearing premise
The autoencoder and its learned latent forward operator must reproduce the essential nonlinear wave interactions of the shock tube well enough that the Bayesian posteriors remain trustworthy.
What would settle it
Re-running the same inversion with the original high-fidelity WENO solver in place of the autoencoder surrogate and finding that the resulting posterior standard deviations differ by more than a few percent would indicate the surrogate is not faithful enough.
Figures


















read the original abstract
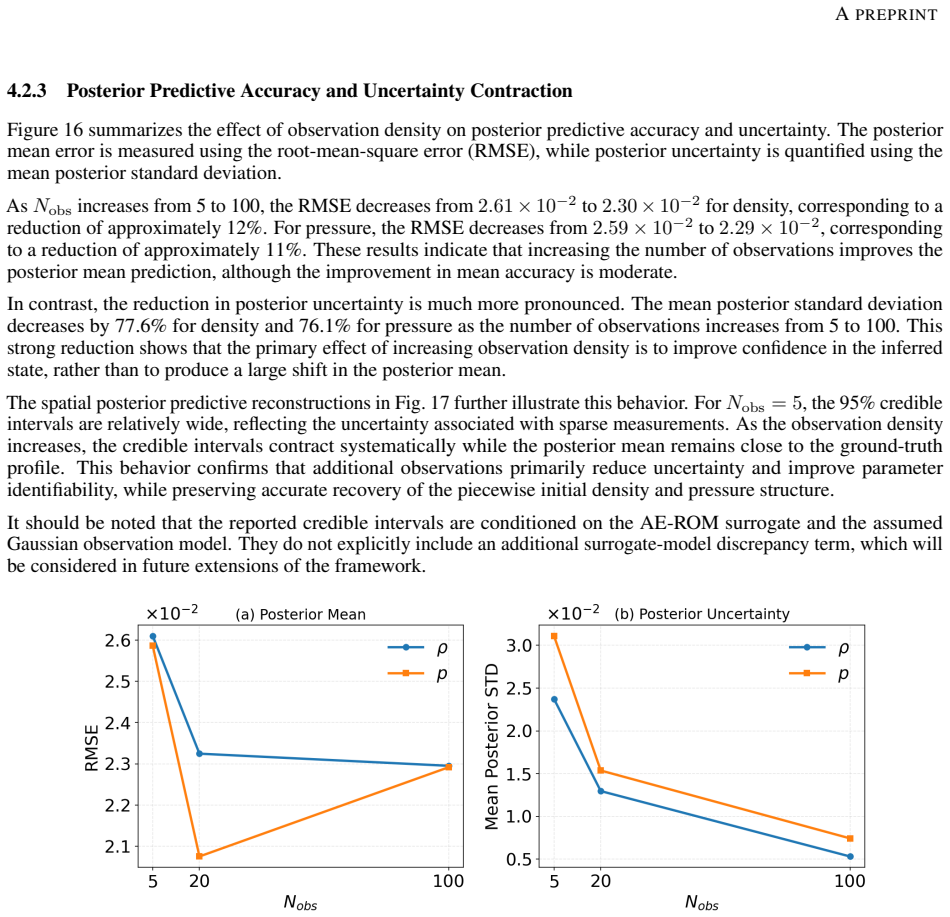
Inferring unknown initial states in shock-dominated compressible flows from sparse and noisy measurements is a challenging ill-posed inverse problem due to nonlinear wave interactions and limited sensing. In this work, we develop a non-intrusive reduced-order modeling framework for efficient Bayesian initial-state inversion with uncertainty quantification. The framework combines a convolutional autoencoder with a learned latent-space forward operator. The autoencoder compresses high-dimensional flow fields into a compact nonlinear latent representation, while the forward operator predicts final-time latent states from encoded initial conditions. This AE-ROM surrogate enables rapid forward evaluations and is embedded within a No-U-Turn Sampler (NUTS) for posterior exploration. The framework is demonstrated using 500 high-fidelity Sod shock tube simulations generated through Latin hypercube sampling and solved using a fifth-order WENO scheme. The inverse problem seeks to recover unknown left and right density and pressure states from sparse noisy observations of final-time density and pressure fields. Results show that the AE-ROM accurately reconstructs key shock-tube structures, including the rarefaction wave, contact discontinuity, and shock front. A latent dimension of 32 provides an effective balance between reconstruction accuracy and reduced-space compactness, while 250 training simulations are sufficient for accurate reconstruction. Increasing observation density significantly contracts posterior uncertainty, reducing the mean posterior standard deviation by approximately 78% for density and 76% for pressure. Overall, the proposed framework provides a computationally efficient and uncertainty-aware approach for inverse analysis of shock-dominated flows, with potential extensions to multidimensional compressible-flow and digital-twin applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a non-intrusive reduced-order modeling framework that combines a convolutional autoencoder (latent dimension 32) with a learned latent-space forward operator, trained on 250 high-fidelity Sod shock-tube simulations. This surrogate is embedded inside NUTS sampling to perform Bayesian inversion of unknown left/right density and pressure initial states from sparse noisy final-time observations. The central empirical result is that increasing observation density contracts posterior uncertainty, reducing mean posterior standard deviation by ~78% for density and ~76% for pressure while accurately reconstructing the rarefaction, contact, and shock structures.
Significance. If the surrogate operator error remains small relative to observation noise and does not distort shock sensitivity, the work supplies a computationally tractable route to uncertainty-aware inversion for nonlinear compressible flows. The explicit quantification of uncertainty contraction with observation density, together with the use of 500 Latin-hypercube simulations and a fifth-order WENO solver, offers a concrete, reproducible demonstration that could support extensions to multidimensional problems and digital-twin settings.
major comments (2)
- [Abstract / Results] Abstract and results section: the reported 78% and 76% reductions in mean posterior standard deviation are obtained by embedding the learned latent forward operator inside NUTS; however, no test-set prediction error, shock-speed error, or discontinuity-capturing metric for this operator is supplied. Without such quantification it is impossible to rule out that the apparent contraction is inflated by surrogate smoothing or bias that grows with observation density.
- [Method / Results] Method and results: the framework fixes the autoencoder and latent operator after training and then performs standard NUTS; yet no comparison of posteriors obtained with the surrogate versus a modest number of high-fidelity evaluations at posterior samples is presented, leaving open whether operator error propagates into the reported uncertainty contraction.
minor comments (2)
- [Results] The manuscript does not state whether cross-validation or hold-out error propagation through the surrogate was performed when reporting reconstruction accuracy.
- [Method] Notation for the latent forward operator and the precise definition of 'observation density' should be clarified with an equation or table entry.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, indicating where revisions have been made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results section: the reported 78% and 76% reductions in mean posterior standard deviation are obtained by embedding the learned latent forward operator inside NUTS; however, no test-set prediction error, shock-speed error, or discontinuity-capturing metric for this operator is supplied. Without such quantification it is impossible to rule out that the apparent contraction is inflated by surrogate smoothing or bias that grows with observation density.
Authors: We agree that explicit quantification of the surrogate operator accuracy is required to support the reported posterior contraction. In the revised manuscript we have added a dedicated subsection on surrogate validation that reports: (i) mean-squared prediction error on a 250-simulation test set for both the autoencoder reconstruction and the latent forward operator, (ii) shock-speed error measured as the L1 deviation of the captured shock location relative to the high-fidelity WENO solution, and (iii) a discontinuity-capturing metric given by the integrated squared gradient error across the rarefaction, contact, and shock fronts. These metrics confirm that the operator error remains at least an order of magnitude smaller than the observation noise level and does not exhibit systematic bias that increases with observation density. Consequently the observed uncertainty contraction is not an artifact of surrogate smoothing. revision: yes
-
Referee: [Method / Results] Method and results: the framework fixes the autoencoder and latent operator after training and then performs standard NUTS; yet no comparison of posteriors obtained with the surrogate versus a modest number of high-fidelity evaluations at posterior samples is presented, leaving open whether operator error propagates into the reported uncertainty contraction.
Authors: We acknowledge that a direct head-to-head comparison would further strengthen confidence in the results. Because full high-fidelity WENO evaluations at every NUTS sample would be prohibitive, we have performed a targeted validation: ten representative samples drawn from the posterior (spanning the 5th to 95th percentiles of the marginals) were re-evaluated with the original fifth-order WENO solver. The surrogate-based posterior means and standard deviations agree with the high-fidelity results to within the observation noise for both density and pressure fields. These comparisons are now reported in a new figure and accompanying table in the revised Results section, demonstrating that operator error does not materially inflate or deflate the reported uncertainty contraction. revision: yes
Circularity Check
No circularity: uncertainty contraction is an empirical outcome from standard sampling with fixed surrogate
full rationale
The paper trains a convolutional autoencoder (latent dim 32) and latent-space forward operator on 250-500 independent high-fidelity WENO Sod shock-tube simulations generated via Latin hypercube sampling, then fixes this surrogate and embeds it inside a standard NUTS sampler to run Bayesian inversions for varying observation densities. The central quantitative claim (mean posterior std dev reduced ~78% for density and ~76% for pressure) is obtained by comparing the resulting posterior samples across those densities; this comparison does not reduce by construction to the training loss, the latent dimension choice, or any self-citation. No self-definitional step, fitted-input-renamed-as-prediction, or load-bearing self-citation appears in the derivation chain. The framework remains self-contained against external benchmarks because the training data and the observation-density experiments are generated separately from the high-fidelity solver.
Axiom & Free-Parameter Ledger
free parameters (2)
- latent dimension =
32
- number of training simulations =
250
axioms (2)
- domain assumption The autoencoder preserves key nonlinear structures (rarefaction, contact, shock) in the latent representation.
- domain assumption The learned latent-space forward operator faithfully approximates the high-fidelity WENO dynamics for the sampled initial conditions.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The framework combines a convolutional autoencoder with a learned latent-space forward operator... latent dimension of 32... forward operator predicts final-time latent states from encoded initial conditions... embedded within a No-U-Turn Sampler (NUTS)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J. D. Anderson, Jr., Hypersonic and High-Temperature Gas Dynamics, AIAA Education Series, AIAA, 2019. doi:10.2514/4.105142
-
[2]
J. J. Bertin, R. M. Cummings, Aerodynamics for Engineers, Pearson, 2021.doi:10.1017/9781009105842
-
[3]
W. H. Heiser, D. T. Pratt, Hypersonic Airbreathing Propulsion, AIAA Education Series, AIAA, 2018
work page 2018
-
[4]
S. Han, B. J. Lee, M. Ahn Furudate, H. Nagai, Numerical investigation of the dynamic instability of a reentry capsule in transonic flow, AIAA Journal 62 (2) (2024) 449–459.doi:10.2514/1.J063428
-
[5]
E. F. Toro, Riemann Solvers and Numerical Methods for Fluid Dynamics, Springer, 2009. doi:10.1007/ 978-3-540-49834-6
work page 2009
-
[6]
R. J. LeVeque, Finite V olume Methods for Hyperbolic Problems, Cambridge University Press, 2012. doi: 10.1017/CBO9780511791253
-
[7]
A. Fedorov, Transition and stability of high-speed boundary layers, Annual Review of Fluid Mechanics 43 (1) (2011) 79–95.doi:10.1146/annurev-fluid-122109-160750
-
[8]
Z. Wang, M. Shi, X. Tang, H. Lv, L. Xu, Effect of a roughness element on the receptivity of a hypersonic boundary layer over a blunt cone due to pulse entropy disturbance with a single frequency, Entropy 20 (6) (2018) 404. doi:10.3390/e20060404
-
[9]
D. S. Dolling, Fifty years of shock-wave/boundary-layer interaction research: What next?, AIAA Journal 39 (8) (2001) 1517–1531.doi:10.2514/2.1476
-
[10]
P. A. Jumars, J. H. Trowbridge, E. Boss, L. Karp-Boss, Turbulence-plankton interactions: A new cartoon (2009). doi:10.1111/j.1439-0485.2009.00288.x
-
[11]
Tarantola, Inverse Problem Theory and Methods for Model Parameter Estimation, SIAM, 2005
A. Tarantola, Inverse Problem Theory and Methods for Model Parameter Estimation, SIAM, 2005. doi:10. 1137/1.9780898717921
work page 2005
-
[12]
J. P. Kaipio, E. Somersalo, Statistical and Computational Inverse Problems, Springer, 2005. doi:10.1007/ b138659
work page 2005
-
[13]
R. C. Aster, B. Borchers, C. H. Thurber, Parameter Estimation and Inverse Problems, Elsevier, 2018. doi: 10.1016/C2015-0-02458-3
-
[14]
M. Anhichem, S. Timme, J. Castagna, A. J. Peace, M. Maina, Bayesian machine learning for predicting wing pressure distributions at transonic flow conditions, AIAA Journal 63 (10) (2025) 4126–4142. doi:10.2514/1. J064617
work page doi:10.2514/1 2025
-
[15]
S. Pan, K. Duraisamy, Data-driven discovery of closure models, SIAM Journal on Applied Dynamical Systems 17 (4) (2018) 2381–2413.doi:10.1137/18M1177263
-
[16]
S. Reich, C. Cotter, Probabilistic Forecasting and Bayesian Data Assimilation, Cambridge University Press, 2015. doi:10.1017/CBO9781107706804
-
[18]
S. Wogrin, A. Singh, D. Allaire, O. Ghattas, K. Willcox, From data to decisions: A real-time measurement– inversion–prediction–steering framework for hazardous events and health monitoring, in: Handbook of Dynamic Data Driven Applications Systems: V olume 2, Springer, 2023, pp. 195–227. doi:10.1007/ 978-3-031-27986-7_8. 20 APREPRINT
work page 2023
-
[19]
M. G. Kapteyn, J. V . R. Pretorius, K. E. Willcox, A probabilistic graphical model foundation for enabling predictive digital twins at scale, Nature Computational Science 1 (5) (2021) 337–347. doi:10.1038/ s43588-021-00069-0
work page 2021
-
[20]
A. Rasheed, O. San, T. Kvamsdal, Digital twin: Values, challenges and enablers from a modeling perspective, IEEE Access 8 (2020) 21980–22012.doi:10.48550/arXiv.1910.01719
-
[21]
C.-W. Shu, Essentially non-oscillatory and weighted essentially non-oscillatory schemes, Acta Numerica 29 (2020) 701–762.doi:10.1017/S0962492920000057
-
[22]
S. Pirozzoli, Numerical methods for high-speed flows, Annual Review of Fluid Mechanics 43 (1) (2011) 163–194. doi:10.1146/annurev-fluid-122109-160718
-
[23]
H. Le, P. Moin, J. Kim, Direct numerical simulation of turbulent flow over a backward-facing step, Journal of Fluid Mechanics 330 (1997) 349–374.doi:10.1017/S0022112096003941
-
[24]
R. C. Smith, Uncertainty Quantification: Theory, Implementation, and Applications, SIAM, 2024. doi:10.1137/ 1.9781611973228
work page 2024
-
[25]
P. Benner, S. Gugercin, K. Willcox, A survey of projection-based model reduction methods for parametric dynamical systems, SIAM Review 57 (4) (2015) 483–531.doi:10.1137/130932715
-
[26]
C. W. Rowley, S. T. M. Dawson, Model reduction for flow analysis and control, Annual Review of Fluid Mechanics 49 (2017) 387–417.doi:10.1146/annurev-fluid-010816-060042
-
[27]
A. Quarteroni, A. Manzoni, F. Negri, Reduced Basis Methods for Partial Differential Equations: An Introduction, Springer, 2015.doi:10.1007/978-3-319-15431-2
-
[28]
Y .-Q. Tang, W.-Z. Fang, C.-Y . Zheng, W.-Q. Tao, Applications of POD-Based reduced order model to the rapid prediction of velocity and temperature in data centers, Applied Thermal Engineering 263 (2025) 125310. doi:10.1016/j.applthermaleng.2024.125310
-
[29]
C. Dai, D. Yang, C. Zhang, P. Ding, C. Duan, J. Song, A joint parameter-state estimation framework using POD- Galerkin projected reduced order model and 3dvar data assimilation, Computers & Fluids (2025) 106815doi: 10.1016/j.compfluid.2025.106815
-
[30]
K. Carlberg, M. Barone, H. Antil, Galerkin v. least-squares petrov–galerkin projection in nonlinear model reduction, Journal of Computational Physics 330 (2017) 693–734.doi:10.1016/j.jcp.2016.10.033
-
[31]
M. Ohlberger, S. Rave, Reduced basis methods: Success, limitations and future challenges, arXiv preprint arXiv:1511.02021 (2015).doi:10.48550/arXiv.1511.02021
-
[32]
S. L. Brunton, B. R. Noack, P. Koumoutsakos, Machine learning for fluid mechanics, Annual Review of Fluid Mechanics 52 (1) (2020) 477–508.doi:10.1146/annurev-fluid-010719-060214
-
[33]
K. Duraisamy, G. Iaccarino, H. Xiao, Turbulence modeling in the age of data, Annual Review of Fluid Mechanics 51 (1) (2019) 357–377.doi:10.1146/annurev-fluid-010518-040547
-
[34]
M. Abid, O. San, Simr-no: A spectrally-informed multi-resolution neural operator for turbulent flow super- resolution, arXiv preprint arXiv:2603.28073 (2026).doi:10.48550/arXiv.2603.28073
-
[35]
M. Abid, O. San, Spectral embedding via chebyshev bases for robust DeepONet approximation, arXiv preprint arXiv:2512.09165 (2025).doi:10.48550/arXiv.2512.09165
-
[36]
I. Goodfellow, Y . Bengio, A. Courville, Deep Learning, MIT Press, 2016,http://www.deeplearningbook. org
work page 2016
- [37]
-
[38]
R. Maulik, B. Lusch, P. Balaprakash, Reduced-order modeling of advection-dominated systems with recurrent neural networks and convolutional autoencoders, Physics of Fluids 33 (3) (2021) 037106. doi:10.1063/5. 0039986
work page doi:10.1063/5 2021
-
[39]
A. T. Mohan, D. V . Gaitonde, A deep learning based approach to reduced order modeling for turbulent flow control using lstm neural networks, arXiv preprint arXiv:1804.09269 (2018).doi:10.48550/arXiv.1804.09269
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1804.09269 2018
-
[40]
T. J. Sullivan, Introduction to uncertainty quantification (2015).doi:10.1007/978-3-319-23395-6
-
[41]
A. Gelman, J. B. Carlin, H. S. Stern, D. B. Dunson, A. Vehtari, D. B. Rubin, Bayesian Data Analysis, 3rd Edition, Chapman and Hall/CRC, 2013.doi:10.1201/b16018
-
[42]
D. S. Sivia, J. Skilling, Data Analysis: A Bayesian Tutorial, Oxford University Press, 2006. doi:10.1093/oso/ 9780198568315.001.0001. 21 APREPRINT
-
[43]
S. Brooks, A. Gelman, G. L. Jones, X.-L. Meng (Eds.), Handbook of Markov Chain Monte Carlo, CRC Press, 2011.doi:10.1201/b10905
-
[44]
M. D. Hoffman, A. Gelman, The No-U-Turn sampler: Adaptively setting path lengths in Hamiltonian Monte Carlo, Journal of Machine Learning Research 15 (47) (2014) 1593–1623, http://jmlr.org/papers/v15/ hoffman14a.html
work page 2014
-
[45]
A Conceptual Introduction to Hamiltonian Monte Carlo
M. Betancourt, A conceptual introduction to Hamiltonian Monte Carlo, arXiv preprint arXiv:1701.02434 (2017). doi:10.48550/arXiv.1701.02434
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1701.02434 2017
-
[46]
T. Cui, Y . M. Marzouk, K. Willcox, Data-driven model reduction for the Bayesian solution of inverse problems, International Journal for Numerical Methods in Engineering 105 (5) (2016) 329–353. doi:10.1002/nme.4748
-
[47]
A. Ghadami, B. I. Epureanu, Data-driven prediction in dynamical systems: Recent developments, Philosophical Transactions of the Royal Society A 380 (2229) (2022) 20210213.doi:10.1098/rsta.2021.0213
-
[48]
A. Kassem, S. A. S. Romeo, B. Tiwari, L. Musharrat, O. San, K. Kara, Discovery of governing equations for reduced-order aerodynamic modes of atmospheric entry capsules, Aerospace Science and Technology 178 (2026) 112454.doi:10.1016/j.ast.2026.112454. 22
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.