Chessformer: A Unified Architecture for Chess Modeling
Pith reviewed 2026-05-20 12:24 UTC · model grok-4.3
The pith
A single transformer architecture called Chessformer advances chess move prediction, engine strength, and interpretability at the same time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Chessformer is an encoder-only transformer that represents board squares as tokens, augments self-attention with a novel dynamic positional encoding called Geometric Attention Bias (GAB) that adapts to domain-specific geometry, and predicts actions with an attention-based source-destination policy head. On human move prediction it reaches 57.1 percent accuracy with fewer than a quarter of the parameters of prior work. When integrated into Leela Chess Zero it adds over 100 Elo and secures tournament victories over Stockfish. Its square-token design makes attention patterns and activations directly attributable to individual board squares, supporting granular interpretability analyses.
What carries the argument
Geometric Attention Bias (GAB), a dynamic positional encoding added to self-attention that adapts to the specific geometry and relationships among chessboard squares.
If this is right
- Human move prediction accuracy reaches 57.1 percent while using substantially fewer parameters than previous leading models.
- Integration into a leading open-source engine produces more than 100 Elo of additional strength and tournament wins against top engines.
- Square-token tokenization allows attention weights and activations to be traced directly to specific board squares for fine-grained analysis.
- Aligning tokenization, positional encoding, and output head with the board's spatial structure yields simultaneous improvements on performance, human compatibility, and transparency.
Where Pith is reading between the lines
- The same geometric bias approach may transfer to other grid-based or spatial decision domains such as Go or certain video games.
- Unified architectures could reduce the engineering cost of building separate systems for strength, prediction, and explanation in complex games.
- Direct square-level attributions may help researchers study which board features drive human-like or superhuman decisions.
Load-bearing premise
The gains across prediction accuracy, Elo strength, and interpretability are due to the architecture itself rather than differences in training data, compute, or evaluation setup compared with earlier models.
What would settle it
A controlled replication that trains the strongest prior models on exactly the same data and compute budget as Chessformer and finds no remaining gap in move-matching accuracy or Elo rating.
Figures














read the original abstract
Chess has long served as a canonical testbed for artificial intelligence, but modeling approaches for its central tasks have diverged. Maximizing playing strength, predicting human play, and enabling interpretability are typically solved with disparate architectures, and these designs are often misaligned with the geometry of the domain. This raises the natural question of whether these objectives require separate modeling paradigms, or if there exists a single architecture that supports them simultaneously. We introduce Chessformer, a unified architecture that advances the state of the art on all three central goals in chess modeling. Chessformer is an encoder-only transformer that represents board squares as tokens, augments self-attention with a novel dynamic positional encoding called Geometric Attention Bias (GAB) that adapts to domain-specific geometry, and predicts actions with an attention-based source-destination policy head. We evaluate Chessformer on each front. First, we develop \maiathree, a family of models for human move prediction that reaches 57.1\% move-matching accuracy, significantly surpassing the previous state of the art with fewer than a quarter of the parameters. Second, we integrate Chessformer into Leela Chess Zero, a leading open-source engine, adding over 100 Elo of playing strength and resulting in tournament victories over Stockfish in major computer chess competitions. Third, we show that Chessformer's square-token design makes attention patterns and activations directly attributable to board squares, enabling granular interpretability analyses that prior architectures do not naturally support. More broadly, our results demonstrate that aligning a model's tokenization, positional encoding, and output design with the underlying structure of a domain can yield simultaneous gains in performance, human compatibility, and interpretability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Chessformer, an encoder-only transformer for chess modeling that tokenizes board squares, augments self-attention with a novel Geometric Attention Bias (GAB), and employs an attention-based source-destination policy head. It claims this single architecture simultaneously advances the state of the art on human move prediction (57.1% accuracy with fewer than a quarter of prior parameters), playing strength (over 100 Elo gain when integrated into Leela Chess Zero, including tournament wins against Stockfish), and interpretability via direct square-level attribution.
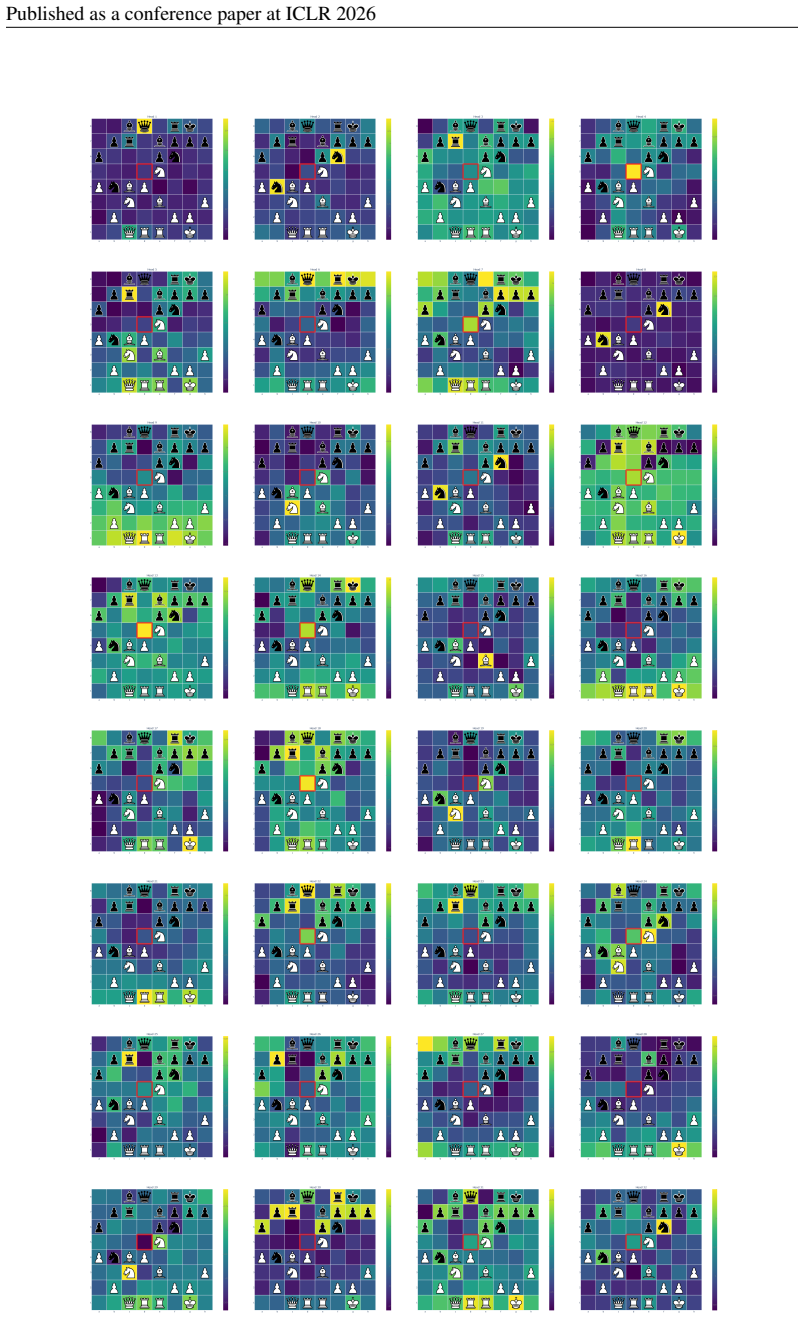
Significance. If the results hold under transparent and matched experimental conditions, the work is significant for demonstrating that domain-aligned tokenization and positional encodings can yield joint gains across performance, human compatibility, and interpretability in a structured domain. The parameter efficiency and successful engine integration provide concrete, reproducible-style evidence that could guide similar unified modeling efforts elsewhere.
major comments (2)
- [§4] §4 (Human Move Prediction): the 57.1% move-matching accuracy is presented as surpassing prior SOTA, yet the section provides no explicit comparison table or text detailing prior accuracies, training game counts, or compute budgets relative to the cited baselines; without these controls the attribution of gains to the unified architecture and GAB remains provisional.
- [§5] §5 (Engine Integration): the >100 Elo claim and tournament victories over Stockfish are load-bearing for the playing-strength advance, but the manuscript does not report the exact LC0 version/patch, time controls, game counts, or implementation differences versus the baseline engine; this leaves open whether the improvement stems from Chessformer or from unstated experimental variations.
minor comments (2)
- [Abstract] The abstract and §3 could more precisely quantify the parameter reduction (e.g., exact prior model sizes) rather than stating 'fewer than a quarter.'
- [Interpretability Analysis] Figure captions in the interpretability section would benefit from explicit labels indicating which attention heads or layers are visualized.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and have revised the paper to incorporate additional experimental details for improved transparency and reproducibility.
read point-by-point responses
-
Referee: [§4] §4 (Human Move Prediction): the 57.1% move-matching accuracy is presented as surpassing prior SOTA, yet the section provides no explicit comparison table or text detailing prior accuracies, training game counts, or compute budgets relative to the cited baselines; without these controls the attribution of gains to the unified architecture and GAB remains provisional.
Authors: We agree that an explicit side-by-side comparison strengthens the presentation. In the revised manuscript we have added a new table in Section 4 that reports move-prediction accuracies, training-game counts, and parameter counts for all cited baselines alongside our results. While hardware-specific compute budgets are not uniformly reported in prior work and therefore cannot be matched exactly, we now discuss parameter count and training data volume as the most comparable efficiency metrics and note that Chessformer achieves its accuracy with substantially fewer parameters. revision: yes
-
Referee: [§5] §5 (Engine Integration): the >100 Elo claim and tournament victories over Stockfish are load-bearing for the playing-strength advance, but the manuscript does not report the exact LC0 version/patch, time controls, game counts, or implementation differences versus the baseline engine; this leaves open whether the improvement stems from Chessformer or from unstated experimental variations.
Authors: We appreciate the request for precise experimental controls. The revised Section 5 now specifies the exact Leela Chess Zero version and patch, the time controls used for both training and evaluation matches, the total number of games played in the reported tournaments, and a clear description of the integration (only the policy network was replaced; all other engine components remained unchanged). These additions confirm that the Elo gains and tournament results are attributable to the Chessformer policy head. revision: yes
Circularity Check
No significant circularity: claims rest on empirical evaluations rather than self-referential derivations
full rationale
The paper introduces Chessformer as a new architecture (encoder-only transformer with square-token representation, Geometric Attention Bias, and attention-based policy head) and reports three separate empirical results: 57.1% human-move accuracy, >100 Elo gain when integrated into LC0, and improved interpretability via direct square attribution. None of these outcomes are derived from equations that reduce by construction to fitted parameters, self-defined quantities, or prior self-citations. The work contains no mathematical derivation chain, uniqueness theorems, or ansatzes smuggled via self-reference; performance numbers come from standard training and benchmarking procedures. This is the normal case of an empirical ML paper whose central claims are falsifiable against external data and baselines.
Axiom & Free-Parameter Ledger
free parameters (1)
- Transformer hyperparameters and GAB scaling factors
axioms (1)
- domain assumption Self-attention mechanisms can be effectively augmented with domain-specific geometric biases to capture chessboard structure
invented entities (1)
-
Geometric Attention Bias (GAB)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Chessformer is an encoder-only transformer that represents board squares as tokens, augments self-attention with a novel dynamic positional encoding called Geometric Attention Bias (GAB) ... and predicts actions with an attention-based source-destination policy head.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce Chessformer, a unified architecture that advances the state of the art on all three central goals in chess modeling.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
https://transformer- circuits.pub/2023/monosemantic-features/index.html. Murray Campbell, A. Joseph Hoane Jr., and Feng-hsiung Hsu. Deep blue.Artificial Intelligence, 134(1–2):57–83,
work page 2023
-
[2]
Joseph Hoane, and Feng-hsiung Hsu
doi: 10.1016/S0004-3702(01)00129-1. R´emi Coulom. Whole-history rating: A bayesian rating system for players of time-varying strength. InComputers and Games,
-
[3]
doi: 10.52202/ 079017-0768. URLhttps://proceedings.neurips.cc/paper_files/paper/ 2024/file/2b8f4db0464cc5b6e9d5e6bea4b9f308-Paper-Conference.pdf. Steven J. Edwards. Standard: Portable game notation specification and implementation guide,
work page 2024
-
[4]
URLhttps://ia802908.us.archive.org/26/items/ pgn-standard-1994-03-12/PGN_standard_1994-03-12.txt. Jesse Farebrother, Jordi Orbay, Quan Vuong, Adrien Ali Taiga, Yevgen Chebotar, Ted Xiao, Alex Irpan, Sergey Levine, Pablo Samuel Castro, Aleksandra Faust, Aviral Kumar, and Rishabh Agarwal. Stop regressing: Training value functions via classification for scal...
work page 1994
-
[6]
URLhttps://arxiv.org/abs/2305.01610. Karim Hamade, Reid McIlroy-Young, Siddhartha Sen, Jon Kleinberg, and Ashton Anderson. Designing skill-compatible AI: Methodologies and frameworks in chess. InThe Twelfth International Conference on Learning Representations,
-
[7]
Deep residual learning for im- age recognition
doi: 10.1109/CVPR.2016.90. Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7132–7141,
-
[8]
doi: 10.1109/CVPR.2018. 00745. 11 Published as a conference paper at ICLR 2026 Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. Averaging weights leads to wider optima and better generalization. In Ricardo Silva and Amir Globerson (eds.),34th Conference on Uncertainty in Artificial Intelligence 2018, UAI 2018, 3...
-
[9]
doi: 10.52202/ 079017-0987. URLhttps://proceedings.neurips.cc/paper_files/paper/ 2024/file/37d9f19150fce07bced2a81fc87d47a6-Paper-Conference.pdf. Adam Karvonen. Emergent world models and latent variable estimation in chess-playing language models. InFirst Conference on Language Modeling, August
work page 2024
-
[10]
Understanding how chess-playing language models compute linear board representations
Aaron Mei. Understanding how chess-playing language models compute linear board representations. InICML 2025 Workshop on Methods and Opportunities at Small Scale,
work page 2025
-
[11]
Accessed: 2025-11-29. Anian Ruoss, Gr ´egoire Del ´etang, Sourabh Medapati, Jordi Grau-Moya, Li Kevin Wenliang, Elliot Catt, John Reid, Cannada A. Lewis, Joel Veness, and Tim Genewein. Amortized planning with large-scale transformers: A case study on chess. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (eds.),Advance...
work page 2025
-
[12]
doi: 10.52202/ 079017-2102. URLhttps://proceedings.neurips.cc/paper_files/paper/ 2024/file/78f0db30c39c850de728c769f42fc903-Paper-Conference.pdf. David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, et al. A general reinforcement learning algorithm th...
work page 2024
-
[13]
Stockfish testing framework.https://tests.stockfishchess.org/ tests
12 Published as a conference paper at ICLR 2026 Stockfish Team. Stockfish testing framework.https://tests.stockfishchess.org/ tests. Accessed: 2025-11-22. Stockfish Team. Stockfish 15.https://stockfishchess.org/blog/2022/ stockfish-15/, April
work page 2026
-
[14]
Accessed: 2025-11-19. Stockfish Team. Stockfish 17.https://stockfishchess.org/blog/2024/ stockfish-17/, September
work page 2025
-
[15]
Accessed: 2025-11-19. Stockfish Team. Regression tests.https://github.com/official-stockfish/ Stockfish/wiki/Regression-Tests,
work page 2025
-
[16]
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu
Accessed: 2026-05-13. Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomput., 568(C), mar
work page 2026
-
[17]
ISSN 0925-2312. doi: 10.1016/j.neucom.2023.127063. URLhttps://doi.org/10.1016/j. neucom.2023.127063. Zhenwei Tang, Difan Jiao, Reid McIlroy-Young, Jon Kleinberg, Siddhartha Sen, and Ashton Anderson. Maia-2: A unified model for human-ai alignment in chess. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (eds.),Advances ...
-
[18]
doi: 10.52202/ 079017-0659. URLhttps://proceedings.neurips.cc/paper_files/paper/ 2024/file/250190819ff1dda47cd23cecc0c5a69b-Paper-Conference.pdf. Zhenwei Tang, Difan Jiao, Eric Xue, Reid McIlroy-Young, Jon Kleinberg, Siddhartha Sen, and Ashton Anderson. Learning to imitate with less: Efficient individual behavior modeling in chess. InInternational Confere...
-
[19]
Human- aligned chess with a bit of search
Yiming Zhang, Athul Jacob, Vivian Lai, Daniel Fried, and Daphne Ippolito. Human- aligned chess with a bit of search. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu (eds.),International Conference on Representation Learning, volume 2025, pp. 4815–4836,
work page 2025
-
[20]
URLhttps://proceedings.iclr.cc/paper_files/paper/2025/file/ 0ef1afa0daa888d695dcd5e9513bafa3-Paper-Conference.pdf. 13 Published as a conference paper at ICLR 2026 A IMPLEMENTATIONDETAILS A.1 HUMANEMULATION All human-prediction models were trained with the AdamW optimizer on the dataset described in Section
work page 2025
-
[21]
We organize the raw game data into chunks of 20,000 games
For each game, we compute the average Elo of the two players and assign the game to the corresponding bin. We organize the raw game data into chunks of 20,000 games. For each chunk, we iterate through games sequentially and distribute them into bins until each bin accumulates 10 games. The process terminates when either all games in the chunk are consumed...
work page 2025
-
[22]
Following the Leela Chess Zero setup, checkpoints were 14 Published as a conference paper at ICLR 2026 Table 4: Human Move-Matching Training Configuration for Reproducibility Parameter Value Training Setup batch size train 128 batch size val 16 gradient accumulation steps 4 num workers 8 Optimization lr5×10 −5 min lr1×10 −5 wd (weight decay)1×10 −6 grad c...
work page 2026
-
[23]
The 2.5M model has embedding dimension and MLP dimension 192, with all else held constant. Each was trained for 1.4 million steps on a single A100 GPU with a batch size of 2048 in approximately four days. The learning rate was held constant at5×10 −4. 15 Published as a conference paper at ICLR 2026 A.3 SPECIALMOVES A source and destination square are suff...
work page 2048
-
[24]
Figure 4: Torch-like pseudocode for GAB. A.4 TRANSCODERTRAINING For interpretability purposes, we train a cross-layer transcoder on MLP activations collected from layers 3 and 4 (in other words, the 4th and 5th layers) of an earlier checkpoint of MAIA-3. The transcoder consists of encoders for each layer and decoders going between the two layers (includin...
work page 2023
-
[25]
We use the same data to sample the top-activating tokens for each feature
For training data, we use blitz games from lichess played during July 2019, filtered in the exact same way as in our base model training pipeline. We use the same data to sample the top-activating tokens for each feature. At the end of training, our transcoder achieves a reconstruction MSE of 1.6% and a sparsity of 0.90. B IMPLEMENTATIONDETAILS FORTOURNAM...
work page 2019
-
[26]
The bias for querying square(i 1, j1) and key square(i 2, j2)is thusf (i2−i1,j2−j1), wheref a,b is defined for−7≤a, b≤7. This adds 15×15parameters per attention head. D TOKENIZATION A number of tokenization schemes have been proposed for chess. We review some of these and attempt to give insight into why our recipe, a square-based representation with a st...
work page 2025
-
[27]
The impact of scale on modeling performance is several times higher for strong play than it is for weak play. 18 Published as a conference paper at ICLR 2026 Table 7: Position encoding ablations for human emulation. Loss Accuracy (%) FLOPs #Params Policy Value Policy Value Absolute 1.418 0.75454.7±0.1 62.6±0.1268M 4.58M Relative bias 1.420 0.75454.6±0.1 6...
work page 2026
-
[28]
L3F0001: Active player’s knight, usually under attack
20 Published as a conference paper at ICLR 2026 F ADDITIONALRESULTS F.1 TOP-ACTIVATEDTOKENS FORTRANSCODER Figure 8:Annotations for features 0-9 of layer 3.L3F0000: Square that the active player can advance a pawn to in order to attack an enemy bishop. L3F0001: Active player’s knight, usually under attack. L3F0002: Square on the side of the board that is c...
work page 2026
-
[29]
26 Published as a conference paper at ICLR 2026 Figure 15: Additional Leela-CF DPA maps from layer
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.