i-DEQ: A stable inertial deep equilibrium model for image restoration
Pith reviewed 2026-05-20 04:27 UTC · model grok-4.3
The pith
An inertial deep equilibrium model halves inference time for image restoration while adding convergence guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By augmenting the fixed-point equation of a deep equilibrium model with an inertial momentum term, the formulation learns an explicit nonconvex regularization for image restoration tasks. The resulting iterations carry convergence guarantees and accelerated rates, training becomes significantly more stable than in ordinary DEQs, and the method delivers reconstruction quality comparable to state-of-the-art approaches at half the inference cost.
What carries the argument
The momentum-augmented fixed-point iteration inside the DEQ equilibrium equation, which accelerates convergence and stabilizes training of the learned regularization.
If this is right
- i-DEQ applies directly to both linear and nonlinear inverse problems with quality on par with current leading methods.
- Training requires less careful initialization and exhibits greater stability than standard DEQ training.
- The fixed-point iterations converge with provable acceleration from the inertial term.
- Inference cost drops by a factor of two with no reported drop in reconstruction quality.
Where Pith is reading between the lines
- The same inertial modification could be tested on other fixed-point or equilibrium architectures outside image restoration to check for similar stability gains.
- The learned nonconvex regularizer might transfer to new degradation models not seen during training, which could be checked by holding out certain inverse problems.
- Reduced training instability may allow deeper or wider equilibrium models to be trained without the usual divergence issues.
Load-bearing premise
Inserting momentum into the fixed-point iterations will simultaneously deliver convergence guarantees, accelerated rates, and improved training stability for the learned nonconvex regularization without introducing new instabilities or lowering solution quality.
What would settle it
A benchmark inverse problem on which the momentum term either causes the fixed-point iteration to diverge, slows convergence relative to plain DEQ, or yields visibly worse reconstructions while training remains unstable.
Figures








read the original abstract
Deep Equilibrium Models (DEQs) are an established framework for image restoration that learn a problem-adapted regularization by solving a fixed-point (i.e. equilibrium) problem. While flexible and expressive, DEQs are often hindered by high computational cost and training instability. We propose an inertial DEQ (i-DEQ) that learns an explicit nonconvex regularization within the DEQ formulation. By using momentum within the fixed-point iterations, i-DEQ has convergence guarantees and accelerated rates. Moreover, we observe that i-DEQ is significantly more stable during the training and robust to rough initialization than DEQs. Numerical experiments on various linear and nonlinear inverse problems demonstrate that i-DEQ achieves reconstruction quality comparable to state-of-the-art methods, while reducing DEQ's inference time by a factor of two.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces i-DEQ, an inertial variant of Deep Equilibrium Models for image restoration. It embeds momentum into the fixed-point iterations used to solve for the equilibrium, claims that this yields convergence guarantees together with accelerated rates even for explicitly nonconvex learned regularizers, reports markedly improved training stability and robustness to initialization, and shows that reconstruction quality remains comparable to state-of-the-art methods while cutting inference time by roughly a factor of two.
Significance. If the stated convergence guarantees can be shown to hold uniformly for the data-dependent nonconvex operators that arise after training, the work would meaningfully improve the practicality of equilibrium models for inverse problems by simultaneously addressing stability and computational cost; the combination of theoretical acceleration claims with empirical speed-ups on linear and nonlinear restoration tasks would be a useful contribution to the optimization and imaging literature.
major comments (2)
- [§4, Theorem 3] §4 (Convergence analysis), Theorem 3 and the surrounding discussion: the proof of accelerated rates for the inertial fixed-point iteration invokes a Kurdyka-Łojasiewicz inequality and a uniform cocoercivity constant for the learned operator F_θ; however, the manuscript does not verify that these regularity conditions continue to hold after the implicit differentiation step that produces the nonconvex regularizer, nor does it provide any post-training diagnostic (e.g., numerical estimation of the KL exponent or monotonicity violation) on the trained models. Because the central claim of “convergence guarantees and accelerated rates” rests on these conditions, the gap is load-bearing.
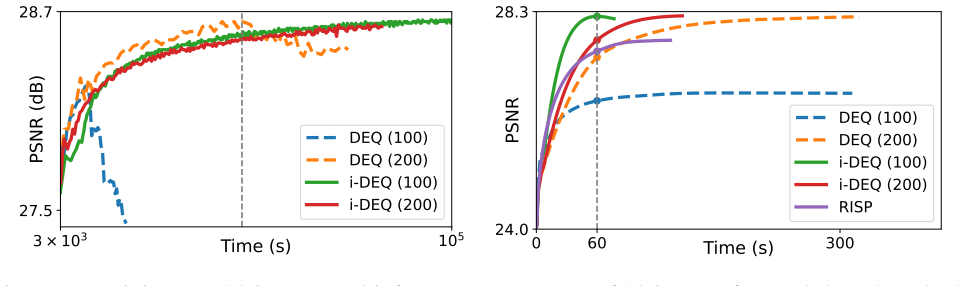
- [§5.2, Figure 4] §5.2 (Training stability experiments) and Figure 4: the claim that i-DEQ is “significantly more stable during training and robust to rough initialization” is supported only by qualitative loss curves and a single initialization sweep; no quantitative metric (e.g., fraction of divergent runs, variance of final PSNR across random seeds, or comparison against standard DEQ with the same momentum schedule) is reported, making it impossible to assess whether the observed stability is systematic or dataset-specific.
minor comments (3)
- [Eq. (7) and Theorem 3] Notation: the symbol for the momentum parameter is introduced as β in Eq. (7) but later appears as α in the convergence-rate statement of Theorem 3; a consistent symbol or explicit cross-reference would remove ambiguity.
- [Table 2] Table 2: the reported inference-time reduction factor of “approximately two” is given without standard deviations or hardware details; adding these would strengthen the reproducibility of the efficiency claim.
- [§2] Related-work section: the discussion of inertial proximal algorithms (e.g., FISTA, heavy-ball) does not cite the recent analyses of inertial methods for nonconvex fixed-point problems that appeared after 2022; adding one or two such references would better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We address each major comment below and will revise the manuscript accordingly to strengthen the theoretical and empirical support.
read point-by-point responses
-
Referee: [§4, Theorem 3] §4 (Convergence analysis), Theorem 3 and the surrounding discussion: the proof of accelerated rates for the inertial fixed-point iteration invokes a Kurdyka-Łojasiewicz inequality and a uniform cocoercivity constant for the learned operator F_θ; however, the manuscript does not verify that these regularity conditions continue to hold after the implicit differentiation step that produces the nonconvex regularizer, nor does it provide any post-training diagnostic (e.g., numerical estimation of the KL exponent or monotonicity violation) on the trained models. Because the central claim of “convergence guarantees and accelerated rates” rests on these conditions, the gap is load-bearing.
Authors: We appreciate the referee highlighting this aspect of the analysis. Theorem 3 derives accelerated rates for the inertial fixed-point iteration under the standard assumptions of the Kurdyka-Łojasiewicz inequality and uniform cocoercivity of the learned operator F_θ. These conditions are imposed directly on the fixed-point operator used in the iteration, which remains well-defined after training via implicit differentiation. While the current version relies on these assumptions together with the observed empirical convergence across tasks, we agree that explicit post-training verification would make the claims more robust. In the revised manuscript we will add numerical diagnostics, including estimation of the KL exponent and checks for monotonicity or cocoercivity violations on the trained models. revision: yes
-
Referee: [§5.2, Figure 4] §5.2 (Training stability experiments) and Figure 4: the claim that i-DEQ is “significantly more stable during training and robust to rough initialization” is supported only by qualitative loss curves and a single initialization sweep; no quantitative metric (e.g., fraction of divergent runs, variance of final PSNR across random seeds, or comparison against standard DEQ with the same momentum schedule) is reported, making it impossible to assess whether the observed stability is systematic or dataset-specific.
Authors: We agree that quantitative metrics would allow a more rigorous evaluation of the stability improvement. The loss curves and initialization sweep in Figure 4 demonstrate that i-DEQ exhibits fewer oscillations and converges reliably from rough initializations compared with standard DEQ. To strengthen this evidence, the revised manuscript will include quantitative statistics such as the fraction of divergent runs over multiple random seeds, the variance of final PSNR values, and direct comparisons against standard DEQ using the same momentum schedule. revision: yes
Circularity Check
No significant circularity; derivation self-contained via new inertial formulation and experiments
full rationale
The paper proposes i-DEQ by inserting momentum into DEQ fixed-point iterations to obtain convergence guarantees, accelerated rates, and improved training stability for a learned nonconvex regularizer. These claims rest on the algorithmic modification itself plus reported numerical results on linear and nonlinear inverse problems, rather than any reduction of predictions to fitted inputs by construction or load-bearing self-citations that merely rename prior results. No self-definitional steps, uniqueness theorems imported from the same authors, or ansatzes smuggled via citation appear in the abstract or described derivation chain. The central result therefore retains independent content from the proposed momentum mechanism and empirical validation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hemant K Aggarwal, Merry P Mani, and Mathews Jacob. MoDL: Model-based deep learning architecture for inverse problems.IEEE transactions on Medical Imaging, 38(2):394–405, 2019
work page 2019
-
[2]
Michael S. Albergo, Nicholas M. Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unify- ing framework for flows and diffusions. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[3]
Brandon Amos and J. Zico Kolter. OptNet: differentiable optimization as a layer in neural networks. InProceedings of the 34th International Conference on Machine Learning - Volume 70, ICML’17, page 136–145. JMLR.org, 2017
work page 2017
-
[4]
Vega Antun, Francesco Renna, Clarice Poon, Ben Adcock, and Anders C. Hansen. On instabilities of deep learning in image reconstruction.Inverse Problems, 36(12), 2020
work page 2020
-
[5]
Pablo Arbelaez, Michael Maire, Charless Fowlkes, and Jitendra Malik. Contour detection and hierarchical image segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 33(5):898–916, 2011
work page 2011
-
[6]
Shaojie Bai, Vladlen Koltun, and J. Zico Kolter. Multiscale deep equilibrium models. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Red Hook, NY , USA, 2020. Curran Associates Inc
work page 2020
-
[7]
Shaojie Bai, Vladlen Koltun, and J. Zico Kolter. Neural deep equilibrium solvers. InInternational Conference on Learning Representations (ICLR), 2021. 12
work page 2021
-
[8]
Stabilizing equilibrium models by Jacobian regularization
Shaojie Bai, Vladlen Koltun, and Zico Kolter. Stabilizing equilibrium models by Jacobian regularization. InInternational Conference on Machine Learning (ICML), pages 554–565. PMLR, 2021
work page 2021
-
[9]
Mario Bertero and Patrizia Boccacci.Introduction to Inverse Problems in Imaging. CRC Press, 1998
work page 1998
-
[10]
Efficient and modular implicit differentiation
Mathieu Blondel, Quentin Berthet, Marco Cuturi, Roy Frostig, Stephan Hoyer, Felipe Llinares- L´opez, Fabian Pedregosa, and Jean-Philippe Vert. Efficient and modular implicit differentiation. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, pages 5230–5242, 2022
work page 2022
-
[11]
One-step differentiation of iterative algo- rithms
J´erˆome Bolte, Edouard Pauwels, and Samuel Vaiter. One-step differentiation of iterative algo- rithms. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, pages 77089–77103, 2023
work page 2023
- [12]
-
[13]
Cand `es, Xiaodong Li, Yi Ma, and John Wright
Emmanuel J. Cand `es, Xiaodong Li, Yi Ma, and John Wright. Robust principal component analysis?J. ACM, 58(3), June 2011
work page 2011
-
[14]
Augustin-Louis Cauchy. M´ethode g´en´erale pour la r´esolution des syst`emes d’´equations simul- tan´ees.Comptes Rendus de l’Acad ´emie des Sciences, 1847
-
[15]
A. Chazottes, ´E. Chouzenoux, J.-C. Pesquet, and F. Sureau. Deep equilibrium for hyperparameter estimation in Dynamic PET reconstruction. InIEEE Nuclear Science Symposium (NSS), Medical Imaging Conference (MIC) and Room Temperature Semiconductor Detector Conference (RTSD), pages 1–1, Tampa, FL, USA, October 2024
work page 2024
-
[16]
Theoretical linear convergence of unfolded ISTA and its practical weights and thresholds
Xiaohan Chen, Jialin Liu, Zhangyang Wang, and Wotao Yin. Theoretical linear convergence of unfolded ISTA and its practical weights and thresholds. InProceedings of the 32nd International Conference on Neural Information Processing Systems, NIPS’18, pages 9079––9089, Red Hook, NY , USA, 2018. Curran Associates Inc
work page 2018
-
[17]
Tsz Chiu Chow, Chao Huang, Zhen Wu, Ting Zeng, and Angelica I. Aviles-Rivero. Inertial proximal difference-of-convex algorithm with convergent Bregman plug-and-play for nonconvex imaging.arXiv preprint arXiv:2409.03262, 2024
-
[18]
In Yeop Chun, Zhiqiang Huang, Hyungjin Lim, and Jeffrey A. Fessler. Momentum-Net: Fast and convergent iterative neural network for inverse problems.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(4):4915–4931, 2023. Epub 2023-03-10
work page 2023
-
[19]
Diffusion posterior sampling for general noisy inverse problems
Hyungjin Chung, Jeongsol Kim, Michael Thompson Mccann, Marc Louis Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems. InInternational Conference on Learning Representations (ICLR), 2022
work page 2022
-
[20]
It has potential: gradient-driven denoisers for convergent solutions to inverse problems
Regev Cohen, Yochai Blau, Daniel Freedman, and Ehud Rivlin. It has potential: gradient-driven denoisers for convergent solutions to inverse problems. InProceedings of the 35th International Conference on Neural Information Processing Systems, NIPS ’21, Red Hook, NY , USA, 2021. Curran Associates Inc
work page 2021
-
[21]
Patrick Combettes and Jean-Christophe Pesquet. Deep neural network structures solving varia- tional inequalities.Set-Valued and Variational Analysis, 28, 2020. 13
work page 2020
-
[22]
Combettes and Jean-Christophe Pesquet
Patrick L. Combettes and Jean-Christophe Pesquet. Proximal splitting methods in signal process- ing. In Heinz H. Bauschke, Regina S. Burachik, Patrick L. Combettes, Veit Elser, D. Russell Luke, and Henryk Wolkowicz, editors,Fixed-Point Algorithms for Inverse Problems in Science and Engineering, pages 185–212. Springer, 2011
work page 2011
-
[23]
Combettes and Jean-Christophe Pesquet
Patrick L. Combettes and Jean-Christophe Pesquet. Lipschitz certificates for layered network structures driven by averaged activation operators.SIAM Journal on Mathematics of Data Science, 2(2):529–557, 2020
work page 2020
-
[24]
Patrick L. Combettes and Val ´erie R. Wajs. Signal recovery by proximal forward-backward splitting.Multiscale Modeling & Simulation, 4(4):1168–1200, 2005
work page 2005
-
[25]
Deep equilibrium models for poisson imaging inverse problems via mirror descent
Christian Daniele, Silvia Villa, Samuel Vaiter, and Luca Calatroni. Deep equilibrium models for poisson imaging inverse problems via mirror descent. HAL preprint hal-05163926, 2025
work page 2025
-
[26]
Ingrid Daubechies, Michel Defrise, and Christine De Mol. An iterative thresholding algorithm for linear inverse problems with a sparsity constraint.Communications on Pure and Applied Mathematics: A Journal Issued by the Courant Institute of Mathematical Sciences, 57(11):1413– 1457, 2004
work page 2004
-
[27]
Brice˜no-Arias, and Nelly Pustelnik
Leo Davy, Luis M. Brice˜no-Arias, and Nelly Pustelnik. Chapter 7 - restarted contractive operators to learn at equilibrium. In Andreas Hauptmann, Bangti Jin, and Carola-Bibiane Sch¨onlieb, editors, Machine Learning Solutions for Inverse Problems: Part A, volume 26 ofHandbook of Numerical Analysis, pages 315–340. Elsevier, 2025
work page 2025
-
[28]
Convergence of denoising diffusion models under the manifold hypothesis
Valentin De Bortoli. Convergence of denoising diffusion models under the manifold hypothesis. Transactions on Machine Learning Research, 2022
work page 2022
-
[29]
Compressed sensing.IEEE Transactions on Information Theory, 52(4):1289– 1306, 2006
David L Donoho. Compressed sensing.IEEE Transactions on Information Theory, 52(4):1289– 1306, 2006
work page 2006
-
[30]
Andrea Ebner and Markus Haltmeier. Plug-and-play image reconstruction is a convergent regularization method.IEEE Transactions on Image Processing, 33:1476–1486, 2024
work page 2024
-
[31]
Laurent El Ghaoui, Fangda Gu, Bertrand Travacca, Armin Askari, and Alicia Y . Tsai. Implicit deep learning.SIAM Journal on Mathematics of Data Science, 3(3):930–958, 2021
work page 2021
-
[32]
Kluwer Academic Publishers, 1996
Heinz W Engl, Martin Hanke, and Andreas Neubauer.Regularization of Inverse Problems. Kluwer Academic Publishers, 1996
work page 1996
-
[33]
Rita Fermanian, Mikael Le Pendu, and Christine Guillemot. PnP-ReG: Learned regularizing gradient for plug-and-play gradient descent.SIAM Journal on Imaging Sciences, 16(2):585–613, 2023
work page 2023
-
[34]
JFB: Jacobian-free backpropagation for implicit networks
Samy Wu Fung, Howard Heaton, Qiuwei Li, Daniel McKenzie, Stanley Osher, and Wotao Yin. JFB: Jacobian-free backpropagation for implicit networks. InConference on Artificial Intelligence (AAAI), 2022
work page 2022
-
[35]
A hybrid interior point - deep learning approach for Poisson image deblurring
Mathieu Galinier, Michele Prato, Emilie Chouzenoux, and Jean-Christophe Pesquet. A hybrid interior point - deep learning approach for Poisson image deblurring. InIEEE International Workshop on Machine Learning for Signal Processing (MLSP), 2020
work page 2020
-
[36]
Weijie Gan, Chunwei Ying, Parna Eshraghi Boroojeni, Tongyao Wang, Cihat Eldeniz, Yuyang Hu, Jiaming Liu, Yasheng Chen, Hongyu An, and Ulugbek S. Kamilov. Self-supervised deep equilibrium models with theoretical guarantees and applications to MRI reconstruction.IEEE Transactions on Computational Imaging, 9:796–807, 2023. 14
work page 2023
-
[37]
Image restoration by denoising diffusion models with iteratively preconditioned guidance
Tomer Garber and Tom Tirer. Image restoration by denoising diffusion models with iteratively preconditioned guidance. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 25245–25254, 2024
work page 2024
-
[38]
Zhengyang Geng, Xin-Yu Zhang, Shaojie Bai, Yisen Wang, and Zhouchen Lin. On training implicit models. arXiv preprint arXiv:2111.05177, 2022
-
[39]
Martin Genzel, Jan Macdonald, and Maximilian M¨arz. Solving inverse problems with deep neural networks–robustness included?IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(1):1119–1134, 2022
work page 2022
-
[40]
Unrolled deep networks for sparse signal restoration in analytical chemistry
Mouna Gharbi, Silvia Villa, Emilie Chouzenoux, Jean-Christophe Pesquet, and Laurent Duval. Unrolled deep networks for sparse signal restoration in analytical chemistry. InIEEE International Workshop on Machine Learning for Signal Processing (MLSP), pages 1–6, 2024
work page 2024
-
[41]
Davis Gilton, Gregory Ongie, and Rebecca Willett. Deep equilibrium architectures for inverse problems in imaging.IEEE Transactions on Computational Imaging, 7(4):1123–1133, 2021
work page 2021
-
[42]
Diffusion models as plug-and-play priors
Alexandros Graikos, Nikolay Malkin, Nebojsa Jojic, and Dimitris Samaras. Diffusion models as plug-and-play priors. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[43]
Learning fast approximations of sparse coding
Karol Gregor and Yann LeCun. Learning fast approximations of sparse coding. InInternational Conference on Machine Learning (ICML), 2010
work page 2010
-
[44]
Memory- efficient backpropagation through time
Audr¯unas Gruslys, R ´emi Munos, Ivo Danihelka, Marc Lanctot, and Alex Graves. Memory- efficient backpropagation through time. InProceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16, page 4132–4140, Red Hook, NY , USA, 2016. Curran Associates Inc
work page 2016
-
[45]
The Rician distribution of noisy MRI data.Magnetic Resonance in Medicine, 34(6):910–914, 1995
Hannes Gudbjartsson and Samuel Patz. The Rician distribution of noisy MRI data.Magnetic Resonance in Medicine, 34(6):910–914, 1995. Erratum in Magnetic Resonance in Medicine, 36(2):332, 1996
work page 1995
-
[46]
Sur les probl `emes aux d´eriv´ees partielles et leur signification physique, 1902
Jacques Hadamard. Sur les probl `emes aux d´eriv´ees partielles et leur signification physique, 1902
work page 1902
-
[47]
Kerstin Hammernik, Teresa Klatzer, Erich Kobler, Michael P Recht, Daniel K Sodickson, Thomas Pock, and Florian Knoll. Learning a variational network for reconstruction of accelerated MRI data.Magnetic Resonance in Medicine, 79(6):3055–3071, 2018
work page 2018
-
[48]
Parseval proximal neural networks.Journal of Fourier Analysis and Applications, 26(4), 2020
Mahdi Hasannasab, Jonas Hertrich, Sebastian Neumayer, Gerlind Plonka, Sven Setzer, and Gabriele Steidl. Parseval proximal neural networks.Journal of Fourier Analysis and Applications, 26(4), 2020
work page 2020
-
[49]
Tao He, Yujie Sun, Bo Chen, Jian Qi, Wei Liu, and Jun Hu. Plug-and-play inertial forward–backward algorithm for Poisson image deconvolution.Journal of Electronic Imag- ing, 28(4):043020–043020, 2019
work page 2019
-
[50]
Johannes Hertrich, Sebastian Neumayer, and Gabriele Steidl. Convolutional proximal neural networks and plug-and-play algorithms.Linear Algebra and its Applications, 631:203–234, 2021
work page 2021
-
[51]
Ehrhardt, and Sebastian Neumayer
Johannes Hertrich, Hok Shing Wong, Alexander Denker, Stanislas Ducotterd, Zhenghan Fang, Markus Haltmeier, ˇZeljko Kereta, Erich Kobler, Oscar Leong, Mohammad Sadegh Salehi, Carola- Bibiane Sch¨onlieb, Johannes Schwab, Zakhar Shumaylov, Jeremias Sulam, German Shˆama Wache, Martin Zach, Yasi Zhang, Matthias J. Ehrhardt, and Sebastian Neumayer. Learning reg...
-
[52]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pages 6840–6851, 2020
work page 2020
-
[53]
Gradient step denoiser for convergent plug-and-play
Samuel Hurault, Arthur Leclaire, and Nicolas Papadakis. Gradient step denoiser for convergent plug-and-play. InInternational Conference on Learning Representations (ICLR), 2022
work page 2022
-
[54]
Proximal denoiser for convergent plug- and-play optimization with nonconvex regularization
Samuel Hurault, Arthur Leclaire, and Nicolas Papadakis. Proximal denoiser for convergent plug- and-play optimization with nonconvex regularization. InInternational Conference on Machine Learning (ICML), pages 9483–9505, 2022
work page 2022
-
[55]
Robust compressed sensing MRI with deep generative priors
Ajil Jalal, Marius Arvinte, Giannis Daras, Eric Price, Alexandros G Dimakis, and Jon Tamir. Robust compressed sensing MRI with deep generative priors. InAdvances in Neural Information Processing Systems (NeurIPS), volume 34, pages 14938–14954, 2021
work page 2021
-
[56]
McCann, Emmanuel Froustey, and Michael Unser
Kyong Hwan Jin, Michael T. McCann, Emmanuel Froustey, and Michael Unser. Deep convolu- tional neural network for inverse problems in imaging.IEEE Transactions on Image Processing, 26(9):4509–4522, 2017
work page 2017
-
[57]
Muckley, Mary Bruno, Aaron Defazio, Marc Parente, Krzysztof J
Florian Knoll, Jure Zbontar, Anuroop Sriram, Matthew J. Muckley, Mary Bruno, Aaron Defazio, Marc Parente, Krzysztof J. Geras, Joe Katsnelson, Hersh Chandarana, Zizhao Zhang, Michal Drozdzal, Adriana Romero, Michael Rabbat, Pascal Vincent, James Pinkerton, Duo Wang, Nafissa Yakubova, Erich Owens, C. Lawrence Zitnick, Michael P. Recht, Daniel K. Sodickson, ...
work page 2020
-
[58]
Cheng Guan Koay and Peter J. Basser. Analytically exact correction scheme for signal extraction from noisy magnitude MR signals.Journal of Magnetic Resonance, 179(2):317–322, 2006
work page 2006
-
[59]
H. T. V . Le, A. Repetti, and N. Pustelnik. Unfolded proximal neural networks for robust image Gaussian denoising.IEEE Transactions on Image Processing, 33:4475–4487, 2024
work page 2024
- [60]
-
[61]
NETT: Solving inverse problems with deep neural networks.Inverse Problems, 36(6), 2020
Hang Li, J¨org Schwab, Simon Antholzer, and Markus Haltmeier. NETT: Solving inverse problems with deep neural networks.Inverse Problems, 36(6), 2020
work page 2020
- [62]
-
[63]
Zenan Ling, Longbo Li, Zhanbo Feng, Yixuan Zhang, Feng Zhou, Robert C. Qiu, and Zhenyu Liao. Deep equilibrium models are almost equivalent to not-so-deep explicit models for high- dimensional Gaussian mixtures. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
work page 2024
-
[64]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[65]
J. Liu, X. Xu, W. Gan, S. Shoushtari, and U. S. Kamilov. Online deep equilibrium learning for regularization by denoising. InAdvances in Neural Information Processing Systems (NeurIPS 35), 2022. 16
work page 2022
-
[66]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[67]
Yu Liu, Yanwei Pang, Xiaohan Liu, Yiming Liu, and Jing Nie. DIIK-Net: A full-resolution cross-domain deep interaction convolutional neural network for MR image reconstruction.Neuro- computing, 517:213–222, 2023
work page 2023
-
[68]
Fuqiang Lu, Xia Xiao, Zengxiang Wang, Yu Liu, and Jiannan Zhou. DFFKI-Net: A dual-domain feature fusion deep convolutional neural network for under-sampled MR image reconstruction. Biomedical Signal Processing and Control, 106:107732, 2025
work page 2025
-
[69]
Stephane Mallat.A wavelet tour of signal processing. 1999
work page 1999
-
[70]
A variational perspective on solving inverse problems with diffusion models
Morteza Mardani, Jiaming Song, Jan Kautz, and Arash Vahdat. A variational perspective on solving inverse problems with diffusion models. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[71]
PNP-FLOW: Plug-and- play image restoration with flow matching
S´egol`ene Martin, Anne Gagneux, Paul Hagemann, and Gabriele Steidl. PNP-FLOW: Plug-and- play image restoration with flow matching. InInternational Conference on Learning Representa- tions (ICLR), OpenReview, 2025
work page 2025
-
[72]
Reversible deep equilibrium models
Sam McCallum, Kamran Arora, and James Foster. Reversible deep equilibrium models. arXiv preprint arXiv:2509.12917, 2025
-
[73]
Abolfazl Mehranian and Andrew J. Reader. Model-based deep learning PET image reconstruction using forward–backward splitting expectation–maximization.IEEE Transactions on Radiation and Plasma Medical Sciences, 5(1):54–64, 2021
work page 2021
-
[74]
Equivariant deep equilibrium models for imaging inverse problems
Alexander Mehta, Ruangrawee Kitichotkul, Vivek K Goyal, and Juli ´an Tachella. Equivariant deep equilibrium models for imaging inverse problems. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 11437–11441, 2026
work page 2026
-
[76]
Vishal Monga, Yuelong Li, and Yonina C Eldar. Algorithm unrolling: Interpretable, efficient deep learning for signal and image processing.IEEE Signal Processing Magazine, 38(2):18–44, 2021
work page 2021
-
[77]
Pravin Nair and Kunal N Chaudhury. Averaged deep denoisers for image regularization.Journal of Mathematical Imaging and Vision, 66(3):362–379, 2024
work page 2024
-
[78]
Adaptive restart for accelerated gradient schemes
Brendan O’Donoghue and Emmanuel J Cand`es. Adaptive restart for accelerated gradient schemes. Foundations of Computational Mathematics, 15(3):715–732, 2015
work page 2015
-
[79]
Proximal algorithms.Foundations and Trends in Optimization, 1(3):127–239, 2014
Neal Parikh and Stephen Boyd. Proximal algorithms.Foundations and Trends in Optimization, 1(3):127–239, 2014
work page 2014
-
[80]
Adam Paszke, Sam Gross, and Francisco et al. Massa. Pytorch: An imperative style, high- performance deep learning library. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
work page 2019
-
[81]
Jean-Christophe Pesquet, Audrey Repetti, Matthieu Terris, and Yves Wiaux. Learning maximally monotone operators for image recovery.SIAM Journal on Imaging Sciences, 14(3):1206–1237, 2021. 17
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.