Tango3D: Towards Alignment for Global and Local 2D-3D Correspondence
Pith reviewed 2026-05-20 05:44 UTC · model grok-4.3
The pith
Tango3D unifies dense pixel-to-point 2D-3D alignment with global retrieval in one model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
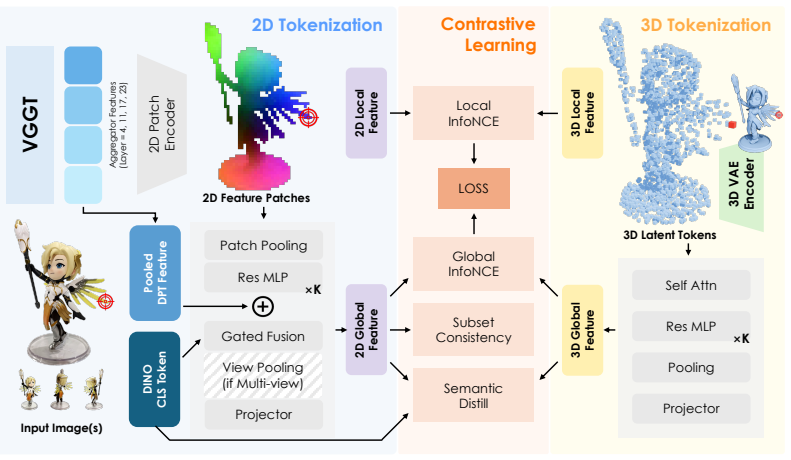
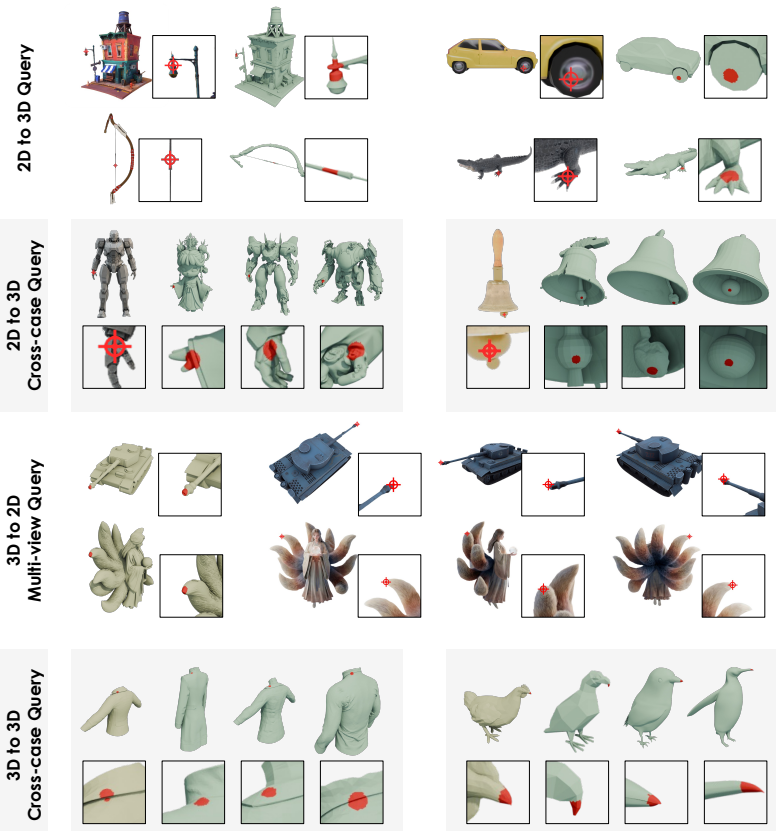
The model maps 2D patches and 3D tokens into a shared space to achieve object-level pixel-to-point alignment while keeping competitive global retrieval performance, using a three-stage progressive training to handle the combined objectives.
What carries the argument
Shared space for aligning 2D image patches from a geometry-aware backbone with 3D tokens from a pretrained VAE.
If this is right
- Injects semantics into geometric 3D tokens for dense downstream tasks.
- Offers a single model for both local correspondence and global retrieval.
- Creates a fine-grained alignment feature space for 2D-3D tasks.
Where Pith is reading between the lines
- Could lead to better performance in tasks requiring precise 3D localization from images.
- Progressive training may help in other settings where local and global objectives compete.
- Opens paths for extending this alignment to dynamic or multi-object scenes.
Load-bearing premise
The three-stage progressive training strategy stabilizes the joint optimization of dense local and global objectives without trade-offs.
What would settle it
Results on a dense correspondence benchmark showing that Tango3D either loses global retrieval accuracy or fails to achieve accurate pixel-to-point matches compared to specialized approaches.
Figures






read the original abstract
Existing 3D foundation models typically align point clouds to frozen vision-language spaces like CLIP, which achieve strong cross-modal retrieval by compressing 3D shape into a global vector. However, this global-only alignment cannot establish fine-grained pixel-to-point correspondence. To solve this, we present Tango3D, a foundation model that unifies dense correspondence and global retrieval. We use a geometry-aware 2D visual backbone and a pretrained 3D VAE to encode images into 2D patches and point clouds into 3D tokens. These are mapped into a single shared space to achieve both local pixel-to-point alignment and global semantic alignment. To stabilize the joint learning of dense and global objectives, we introduce a three-stage progressive training strategy. Experiments show our model successfully achieves object-level pixel-to-point alignment while maintaining competitive global retrieval, a joint capability not offered by existing 3D foundation models. By establishing a fine-grained alignment feature space, Tango3D injects rich semantics into purely geometric 3D tokens, paving the way for a wide range of dense 3D downstream tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Tango3D, a foundation model for unifying dense local 2D-3D correspondence (object-level pixel-to-point alignment) and global semantic retrieval. It encodes images via a geometry-aware 2D backbone into patches and point clouds via a pretrained 3D VAE into tokens, maps both into a shared embedding space, and stabilizes joint dense/global optimization with a three-stage progressive training strategy. The central claim is that this yields successful local alignment while preserving competitive global retrieval, a joint capability absent from existing 3D foundation models that rely on global-only CLIP-style alignment.
Significance. If the experimental claims hold with proper verification, the work would offer a useful step toward fine-grained 2D-3D alignment in foundation models, enabling semantic enrichment of geometric 3D tokens for downstream dense tasks. The explicit focus on avoiding trade-offs between local and global objectives via progressive training addresses a practical gap in current approaches.
major comments (2)
- [Abstract] Abstract: the claim that experiments demonstrate successful object-level pixel-to-point alignment while maintaining competitive global retrieval is unsupported by any reported metrics, baselines, ablation results, or error analysis. Without these, it is impossible to verify that the shared space and three-stage training deliver both capabilities without degradation.
- [Method / Training Strategy] Three-stage progressive training strategy (described in the method): the manuscript presents this schedule as sufficient to stabilize joint optimization of dense local and global objectives without trade-offs, yet supplies no ablation (e.g., local correspondence accuracy or global mAP before/after adding the second loss) to confirm the objectives do not pull the shared features in incompatible directions.
minor comments (2)
- Clarify the precise mechanism by which 2D patches and 3D tokens are projected into the shared space (e.g., any additional projection layers or contrastive losses).
- Specify the evaluation protocols for both local correspondence (e.g., pixel-to-point matching accuracy) and global retrieval (e.g., mAP on which datasets).
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The two major comments identify important gaps in the presentation of experimental support for our claims. We address each point below and commit to revisions that will make the results more verifiable.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that experiments demonstrate successful object-level pixel-to-point alignment while maintaining competitive global retrieval is unsupported by any reported metrics, baselines, ablation results, or error analysis. Without these, it is impossible to verify that the shared space and three-stage training deliver both capabilities without degradation.
Authors: We agree that the abstract statement is currently too high-level. The experiments section does report quantitative results for both local pixel-to-point matching accuracy on object-level benchmarks and global retrieval mAP, together with comparisons against global-only 3D foundation models. However, these numbers are not referenced in the abstract, and a concise error analysis is absent. In the revised manuscript we will (i) rewrite the abstract to cite the key metrics (local correspondence accuracy and global mAP) and (ii) add a short error-analysis paragraph that directly compares joint versus single-objective performance to demonstrate the absence of degradation. revision: yes
-
Referee: [Method / Training Strategy] Three-stage progressive training strategy (described in the method): the manuscript presents this schedule as sufficient to stabilize joint optimization of dense local and global objectives without trade-offs, yet supplies no ablation (e.g., local correspondence accuracy or global mAP before/after adding the second loss) to confirm the objectives do not pull the shared features in incompatible directions.
Authors: We concur that an explicit ablation is needed to substantiate the claim that the three-stage schedule prevents conflicting gradients. The current text describes the progressive schedule but does not tabulate performance at intermediate stages. In the revision we will insert a new ablation table (or figure) that reports local correspondence accuracy and global retrieval mAP after each training stage, including the transition when the dense loss is introduced. This will directly show that the objectives remain compatible under the proposed schedule. revision: yes
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper presents an architecture using a geometry-aware 2D backbone and pretrained 3D VAE to map patches and tokens into a shared space, stabilized by a three-stage progressive training strategy. The central claims rest on experimental results for pixel-to-point alignment and global retrieval rather than any mathematical derivation that reduces to self-definition or fitted inputs by construction. No equations, parameter fits renamed as predictions, or load-bearing self-citations are described that would make the joint capability equivalent to its inputs. The method choices and training schedule are presented as independent design decisions whose effectiveness is evaluated externally via experiments, making the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A single shared embedding space can simultaneously support both dense local pixel-to-point alignment and global semantic alignment.
Reference graph
Works this paper leans on
-
[1]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Ma- rina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Ma-...
work page 2021
-
[2]
Fine-grained image-to-lidar contrastive distillation with visual foundation models
Yifan Zhang and Junhui Hou. Fine-grained image-to-lidar contrastive distillation with visual foundation models. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors, Advances in Neural Information Processing Systems , volume 37, pages 128396–128429. Curran Associates, Inc., 2024
work page 2024
-
[3]
Im- plicit correspondence learning for image-to-point cloud registration
Xinjun Li, Wenfei Y ang, Jiacheng Deng, Zhixin Cheng, Xu Zhou, and Tianzhu Zhang. Im- plicit correspondence learning for image-to-point cloud registration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 16922– 16931, June 2025
work page 2025
-
[4]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea V edaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
work page 2025
-
[5]
Sigmoid loss for lan- guage image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for lan- guage image pre-training. In Proceedings of the IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 11975–11986, October 2023
work page 2023
-
[6]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Al- abdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Y e Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, local- ization, and dense features. arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Point transformer v2: Grouped vector attention and partition-based pooling
Xiaoyang Wu, Yixing Lao, Li Jiang, Xihui Liu, and Hengshuang Zhao. Point transformer v2: Grouped vector attention and partition-based pooling. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems , volume 35, pages 33330–33342. Curran Associates, Inc., 2022
work page 2022
-
[8]
Point transformer v3: Simpler, faster, stronger
Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xihui Liu, Y u Qiao, Wanli Ouyang, Tong He, and Hengshuang Zhao. Point transformer v3: Simpler, faster, stronger. In CVPR, 2024
work page 2024
-
[9]
Pointnext: Revisiting pointnet++ with improved training and scaling strategies
Guocheng Qian, Y uchen Li, Houwen Peng, Jinjie Mai, Hasan Hammoud, Mohamed Elhoseiny, and Bernard Ghanem. Pointnext: Revisiting pointnet++ with improved training and scaling strategies. In Advances in Neural Information Processing Systems (NeurIPS) , 2022
work page 2022
-
[10]
Qi, Hao Su, Kaichun Mo, and Leonidas J
Charles R. Qi, Hao Su, Kaichun Mo, and Leonidas J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017
work page 2017
-
[11]
Pointnet++: Deep hierarchi- cal feature learning on point sets in a metric space
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchi- cal feature learning on point sets in a metric space. In I. Guyon, U. V on Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Informa- tion Processing Systems, volume 30. Curran Associates, Inc., 2017
work page 2017
-
[12]
Point-bert: Pre-training 3d point cloud transformers with masked point modeling
Xumin Y u, Lulu Tang, Y ongming Rao, Tiejun Huang, Jie Zhou, and Jiwen Lu. Point-bert: Pre-training 3d point cloud transformers with masked point modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 19313– 19322, June 2022
work page 2022
-
[13]
Masked autoencoders for point cloud self-supervised learning
Y atian Pang, Wenxiao Wang, Francis EH Tay, Wei Liu, Y onghong Tian, and Li Y uan. Masked autoencoders for point cloud self-supervised learning. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part II, pages 604–
work page 2022
-
[14]
Lau, Wanli Ouyang, and Wangmeng Zuo
Tianyu Huang, Bowen Dong, Y unhan Y ang, Xiaoshui Huang, Rynson W.H. Lau, Wanli Ouyang, and Wangmeng Zuo. Clip2point: Transfer clip to point cloud classification with image-depth pre-training. In Proceedings of the IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 22157–22167, October 2023
work page 2023
-
[15]
Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding
Le Xue, Mingfei Gao, Chen Xing, Roberto Martín-Martín, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, and Silvio Savarese. Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 1179–1189, June 2023
work page 2023
-
[16]
Ulip-2: Towards scalable multimodal pre-training for 3d understanding
Le Xue, Ning Y u, Shu Zhang, Artemis Panagopoulou, Junnan Li, Roberto Martín-Martín, Jia- jun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, and Silvio Savarese. Ulip-2: Towards scalable multimodal pre-training for 3d understanding. In Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), pages 27091–27101, June 2024
work page 2024
-
[17]
Openshape: Scaling up 3d shape representation towards open-world understanding
Minghua Liu, Ruoxi Shi, Kaiming Kuang, Yinhao Zhu, Xuanlin Li, Shizhong Han, Hong Cai, Fatih Porikli, and Hao Su. Openshape: Scaling up 3d shape representation towards open-world understanding. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems , volume 36, pages 44860–44879. ...
work page 2023
-
[18]
Uni3d: Exploring unified 3d representation at scale
Junsheng Zhou, Jinsheng Wang, Baorui Ma, Y u-Shen Liu, Tiejun Huang, and Xinlong Wang. Uni3d: Exploring unified 3d representation at scale. In B. Kim, Y . Y ue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, editors, International Conference on Learning Rep- resentations, volume 2024, pages 46766–46782, 2024
work page 2024
-
[19]
Multi-modal relation distillation for unified 3d representation learning
Huiqun Wang, Yiping Bao, Panwang Pan, Zeming Li, Xiao Liu, Ruijie Y ang, and Di Huang. Multi-modal relation distillation for unified 3d representation learning. In European Confer- ence on Computer Vision, pages 364–381. Springer, 2024
work page 2024
-
[20]
Sculpting holistic 3d representation in contrastive language-image-3d pre-training
Yipeng Gao, Zeyu Wang, Wei-Shi Zheng, Cihang Xie, and Y uyin Zhou. Sculpting holistic 3d representation in contrastive language-image-3d pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 22998–23008, June 2024
work page 2024
-
[21]
Cross-modal 3d repre- sentation with multi-view images and point clouds
Ziyang Zhou, Pinghui Wang, Zi Liang, Haitao Bai, and Ruofei Zhang. Cross-modal 3d repre- sentation with multi-view images and point clouds. In Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR) , pages 3728–3739, June 2025
work page 2025
-
[22]
Structure-from-motion revisited
Johannes Lutz Schönberger and Jan-Michael Frahm. Structure-from-motion revisited. In Con- ference on Computer Vision and Pattern Recognition (CVPR) , 2016
work page 2016
-
[23]
Photo tourism: exploring photo collec- tions in 3d
Noah Snavely, Steven M Seitz, and Richard Szeliski. Photo tourism: exploring photo collec- tions in 3d. In ACM siggraph 2006 papers, pages 835–846. 2006
work page 2006
-
[24]
Sameer Agarwal, Y asutaka Furukawa, Noah Snavely, Ian Simon, Brian Curless, Steven M Seitz, and Richard Szeliski. Building rome in a day. Communications of the ACM, 54(10):105– 112, 2011
work page 2011
-
[25]
Building rome on a cloudless day
Jan-Michael Frahm, Pierre Fite-Georgel, David Gallup, Tim Johnson, Rahul Raguram, Changchang Wu, Yi-Hung Jen, Enrique Dunn, Brian Clipp, Svetlana Lazebnik, et al. Building rome on a cloudless day. In Computer Vision–ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, September 5-11, 2010, Proceedings, Part IV 11 , pages 368–3...
work page 2010
-
[26]
Towards linear-time incremental structure from motion
Changchang Wu. Towards linear-time incremental structure from motion. In 2013 Interna- tional Conference on 3D Vision-3DV 2013, pages 127–134. IEEE, 2013
work page 2013
-
[27]
Robust incremental structure-from-motion with hybrid features
Shaohui Liu, Yidan Gao, Tianyi Zhang, Rémi Pautrat, Johannes L Schönberger, Viktor Lars- son, and Marc Pollefeys. Robust incremental structure-from-motion with hybrid features. In European Conference on Computer Vision, pages 249–269. Springer, 2025. 11
work page 2025
-
[28]
Unsupervised learning of depth and ego-motion from video
Tinghui Zhou, Matthew Brown, Noah Snavely, and David G Lowe. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1851–1858, 2017
work page 2017
-
[29]
Demon: Depth and motion network for learning monocu- lar stereo
Benjamin Ummenhofer, Huizhong Zhou, Jonas Uhrig, Nikolaus Mayer, Eddy Ilg, Alexey Dosovitskiy, and Thomas Brox. Demon: Depth and motion network for learning monocu- lar stereo. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 5038–5047, 2017
work page 2017
-
[30]
Ba-net: Dense bundle adjustment network, 2019
Chengzhou Tang and Ping Tan. Ba-net: Dense bundle adjustment network. arXiv preprint arXiv:1806.04807, 2018
-
[31]
Deepsfm: Struc- ture from motion via deep bundle adjustment
Xingkui Wei, Yinda Zhang, Zhuwen Li, Y anwei Fu, and Xiangyang Xue. Deepsfm: Struc- ture from motion via deep bundle adjustment. In Computer Vision–ECCV 2020: 16th Euro- pean Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I 16 , pages 230–247. Springer, 2020
work page 2020
-
[32]
Deep two-view structure-from-motion revisited
Jianyuan Wang, Yiran Zhong, Y uchao Dai, Stan Birchfield, Kaihao Zhang, Nikolai Smolyan- skiy, and Hongdong Li. Deep two-view structure-from-motion revisited. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition , pages 8953–8962, 2021
work page 2021
-
[33]
arXiv preprint arXiv:1812.04605 , year =
Zachary Teed and Jia Deng. Deepv2d: Video to depth with differentiable structure from motion. arXiv preprint arXiv:1812.04605, 2018
-
[34]
Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras
Zachary Teed and Jia Deng. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras. Advances in neural information processing systems , 34:16558–16569, 2021
work page 2021
-
[35]
Eric Brachmann, Jamie Wynn, Shuai Chen, Tommaso Cavallari, Áron Monszpart, Daniyar Turmukhambetov, and Victor Adrian Prisacariu. Scene coordinate reconstruction: Posing of image collections via incremental learning of a relocalizer. In ECCV, 2024
work page 2024
-
[36]
FlowMap: high- quality camera poses, intrinsics, and depth via gradient descent
Cameron Smith, David Charatan, Ayush Tewari, and Vincent Sitzmann. FlowMap: high- quality camera poses, intrinsics, and depth via gradient descent. 2404.15259, 2024
-
[37]
VGGSfM: visual geometry grounded deep structure from motion
Jianyuan Wang, Nikita Karaev, Christian Rupprecht, and David Novotny. VGGSfM: visual geometry grounded deep structure from motion. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2024
work page 2024
-
[38]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Y ohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. In CVPR, 2024
work page 2024
-
[39]
Grounding image matching in 3d with mast3r
Vincent Leroy, Y ohann Cabon, and Jerome Revaud. Grounding image matching in 3d with mast3r. In ECCV, 2024
work page 2024
-
[40]
Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli
Jianing Y ang, Alexander Sax, Kevin J. Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21924–21935, June 2025
work page 2025
-
[41]
Sem-mast3r: Semantically guided feature matching with mast3r
Dario Tenore, Daniel Barath, Marc Pollefeys, and Qunjie Zhou. Sem-mast3r: Semantically guided feature matching with mast3r. In Proceedings of the IEEE/CVF International Confer- ence on Computer Vision (ICCV) Workshops, pages 130–139, October 2025
work page 2025
-
[42]
Reconviagen: Towards accurate multi-view 3d object reconstruction via generation
Jiahao Chang, Chongjie Y e, Y ushuang Wu, Y uantao Chen, Yidan Zhang, Zhongjin Luo, Chenghong Li, Yihao Zhi, and Xiaoguang Han. Reconviagen: Towards accurate multi-view 3d object reconstruction via generation. In The F ourteenth International Conference on Learning Representations, 2026
work page 2026
-
[43]
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Team Hunyuan3D, Shuhui Y ang, Mingxin Y ang, Yifei Feng, Xin Huang, Sheng Zhang, Zebin He, Di Luo, Haolin Liu, Y unfei Zhao, et al. Hunyuan3d 2.1: From images to high-fidelity 3d assets with production-ready pbr material. arXiv preprint arXiv:2506.15442, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, V asil Khali- dov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Y ao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, V asu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patr...
work page 2024
-
[45]
Ashish V aswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017
work page 2017
-
[46]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli V anderBilt, Lud- wig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pages 13142– 13153, 2023
work page 2023
-
[47]
Objaverse-xl: A universe of 10m+ 3d objects
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, et al. Objaverse-xl: A universe of 10m+ 3d objects. In Proc. Adv. Neural Inf. Process. Syst., pages 35799–35813, 2023
work page 2023
-
[48]
3d shapenets: A deep representation for volumetric shapes
Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Y u, Linguang Zhang, Xiaoou Tang, and Jianxiong Xiao. 3d shapenets: A deep representation for volumetric shapes. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages 1912–1920, 2015
work page 2015
-
[49]
SAM 2: Segment anything in images and videos
Nikhila Ravi, V alentin Gabeur, Y uan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan V asudev Alwala, Nicolas Carion, Chao-Y uan Wu, Ross Girshick, Piotr Dollar, and Christoph Feichtenhofer. SAM 2: Segment anything in images and videos. In The Thirteenth Intern...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.