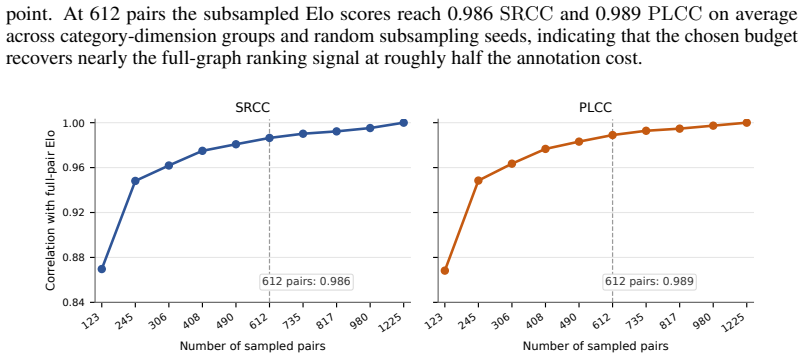
Preferences Order, Ratings Anchor: From Fused Expert Aesthetic Ground Truth to Self-Distillation
Pith reviewed 2026-05-21 07:22 UTC · model grok-4.3
The pith
Fusing expert pairwise preferences with pointwise ratings produces a consistent aesthetic ground truth for self-distilling vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fusing expert pairwise preferences and pointwise ratings via two independent preference-to-score methods yields a consistent ground truth, and extending the same conversion to a VLM's self-judgments followed by confidence-weighted ranking optimization produces a distilled single-pass aesthetic scorer that improves mean SRCC from 0.504 to 0.709 while matching closed-source models.
What carries the argument
The preference-to-score conversion method applied first to fuse expert annotations into ground truth and then to convert VLM pairwise judgments into calibrated pseudo-scores for self-distillation training.
If this is right
- The fused ground truth provides a more robust benchmark for aesthetic assessment models.
- Self-distillation enables significant performance gains in open-source VLMs without external labels.
- The method transfers across domains as validated on APDDv2.
- Single-pass inference keeps the distilled model efficient for practical deployment.
Where Pith is reading between the lines
- This fusion strategy could apply to other domains requiring both relative ordering and absolute scaling in annotations.
- VLMs may contain untapped knowledge about aesthetics that self-generated preferences can surface effectively.
- Extending the approach to additional aesthetic dimensions or non-painting domains could further test its generality.
Load-bearing premise
The near-identical scores from two different preference-to-score constructions on the fused expert data confirm the fusion as a reliable ground truth instead of a methodological artifact.
What would settle it
Collecting annotations from a new group of experts using a different protocol and finding that the resulting scores diverge markedly from the fused ground truth would undermine the reliability of the fusion.
Figures






read the original abstract
Pairwise preferences and pointwise ratings are the two dominant annotation protocols in image aesthetic assessment (IAA), yet existing benchmarks adopt only one, leaving their complementarity unmeasured under controlled conditions. We introduce PPaint, a matched dual-protocol benchmark in which 15 domain experts, 5 per category, annotate 150 Chinese paintings under both protocols across five aesthetic dimensions, collecting 45,900 pairwise expert judgments through a locally dense preference design alongside the matched ratings. The matched design reveals complementary strengths: preferences yield more consistent ordinal rankings, while ratings anchor the absolute score scale. Fusing both signals via two independent preference-to-score methods yields a fused expert ground truth on which the two constructions converge to nearly identical scores. The same preference-to-score principle extends to label-free VLM training. PSDistill converts VLM pairwise judgments into calibrated pseudo-scores via an Elo reference pool, and trains the same VLM with confidence-weighted ranking optimization to produce a single-pass aesthetic scorer. Trained on a single painting category, the distilled Qwen3-VL-8B improves mean SRCC from 0.504 to 0.709 across all three categories, outperforming all open-source baselines including the dedicated aesthetic model ArtiMuse and matching closed-source Gemini-3.1-Pro within 0.04 SRCC at single-pass inference cost, with cross-domain transfer further validated on APDDv2. We will release the full PPaint dataset and training code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PPaint, a matched dual-protocol benchmark in which 15 domain experts annotate 150 Chinese paintings under both pairwise preference and pointwise rating protocols across five aesthetic dimensions. It claims that fusing the two signals via two independent preference-to-score methods produces a reliable expert ground truth, as evidenced by convergence of the resulting scores. The authors then extend the preference-to-score conversion to a VLM's own judgments via an Elo reference pool in the PSDistill self-distillation procedure, training with confidence-weighted ranking optimization to raise mean SRCC from 0.504 to 0.709 across categories while matching closed-source performance at single-pass cost.
Significance. If the fused ground truth proves robust against conversion artifacts and the self-distillation gains hold without substantial circularity, the work would usefully demonstrate complementarity between annotation protocols and provide a practical route for improving open VLMs on aesthetic scoring. The concrete SRCC numbers and planned release of the PPaint dataset plus training code are positive for reproducibility.
major comments (3)
- [Matched design results paragraph] Matched design results paragraph: the claim that convergence of the two preference-to-score constructions on the fused expert ground truth validates the fusion as reliable is load-bearing for the central claim, yet both constructions operate on identical fused inputs and employ overlapping ranking aggregation and normalization steps; this leaves open the possibility that agreement is induced by shared conversion assumptions rather than reflecting independent confirmation of underlying aesthetic quality.
- [PSDistill section and experimental results] PSDistill section and experimental results: the self-distillation converts the VLM's own pairwise judgments to pseudo-scores via an Elo reference pool whose scaling factor is listed among the free parameters; it is unclear whether this pool is fitted on the same data subsequently used for training, which would make the reported SRCC lift from 0.504 to 0.709 partly reducible to re-using model outputs as targets and would require explicit separation or ablation to support the improvement claim.
- [Abstract and results tables] Abstract and results tables: the reported mean SRCC gains and cross-category transfer are presented without error bars, statistical significance tests, or sensitivity analysis to post-hoc choices in the preference-to-score mappings; these omissions make it difficult to judge whether the central empirical improvements are robust or sensitive to implementation details.
minor comments (1)
- [Methods] Notation for the two preference-to-score methods should be introduced with explicit equations or pseudocode in the methods section to clarify their claimed independence.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, clarifying methodological distinctions where possible and committing to revisions that strengthen the empirical support and presentation.
read point-by-point responses
-
Referee: [Matched design results paragraph] the claim that convergence of the two preference-to-score constructions on the fused expert ground truth validates the fusion as reliable is load-bearing for the central claim, yet both constructions operate on identical fused inputs and employ overlapping ranking aggregation and normalization steps; this leaves open the possibility that agreement is induced by shared conversion assumptions rather than reflecting independent confirmation of underlying aesthetic quality.
Authors: We appreciate the referee's scrutiny of this central claim. The two methods are not identical in formulation: one applies a Bradley-Terry maximum-likelihood estimator directly to the preference graph, while the other solves a constrained least-squares problem that incorporates the pointwise ratings as absolute anchors before normalization. Although both start from the fused expert annotations, their aggregation objectives and handling of ties differ, and the near-identical output scores (mean absolute deviation <0.05) occur despite these differences. We will revise the paragraph to explicitly contrast the algorithmic steps and add a supplementary ablation that reapplies each method to preferences-only and ratings-only inputs to isolate the contribution of fusion. revision: partial
-
Referee: [PSDistill section and experimental results] the self-distillation converts the VLM's own pairwise judgments to pseudo-scores via an Elo reference pool whose scaling factor is listed among the free parameters; it is unclear whether this pool is fitted on the same data subsequently used for training, which would make the reported SRCC lift from 0.504 to 0.709 partly reducible to re-using model outputs as targets and would require explicit separation or ablation to support the improvement claim.
Authors: We thank the referee for identifying this potential source of circularity. The manuscript describes the Elo reference pool as a calibration device but does not explicitly state its construction details relative to the training split. We will revise the PSDistill section to clarify that the reference pool is built from VLM judgments on a disjoint set of images sampled from the same distribution, and we will add an ablation that compares the reported SRCC gains against a version that uses only a fixed scaling factor or training-set judgments alone. revision: yes
-
Referee: [Abstract and results tables] the reported mean SRCC gains and cross-category transfer are presented without error bars, statistical significance tests, or sensitivity analysis to post-hoc choices in the preference-to-score mappings; these omissions make it difficult to judge whether the central empirical improvements are robust or sensitive to implementation details.
Authors: We agree that the current results lack these robustness indicators. In the revised version we will augment all SRCC tables with error bars obtained via bootstrap resampling, include paired statistical tests (Wilcoxon signed-rank) between baseline and distilled models, and add a sensitivity subsection that varies the Elo scaling factor and confidence-weighting threshold to demonstrate that the mean improvement from 0.504 to 0.709 remains consistent across the tested ranges. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained against external expert ground truth.
full rationale
The paper constructs a new matched dual-protocol benchmark (PPaint) with external expert annotations, fuses pairwise preferences and pointwise ratings via two stated independent conversion methods, and treats their convergence on the fused data as a robustness check rather than a definitional identity. The self-distillation (PSDistill) generates pseudo-scores from the VLM's own pairwise judgments via an Elo pool and optimizes the same model against those pseudo-labels, but evaluates the resulting SRCC gains directly against the held-out expert ground truth rather than against the pseudo-labels themselves. No equation or step reduces a claimed prediction or ground-truth reliability result to a fitted parameter or self-generated target by construction; the expert annotations and cross-category transfer provide external anchors. This is the normal non-circular outcome for a paper whose central claims rest on new data collection and standard self-distillation mechanics.
Axiom & Free-Parameter Ledger
free parameters (2)
- fusion weight between preference-derived and rating-derived scores
- Elo reference pool scaling factor
axioms (1)
- domain assumption Expert annotations under both protocols are consistent and complementary measures of the same underlying aesthetic quality.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Fusing both signals via two independent preference-to-score methods yields a fused expert ground truth on which the two constructions converge to nearly identical scores... anchored Elo... anchored Davidson Bradley-Terry... sigmoid calibration
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A V A: A large-scale database for aesthetic visual analysis
Naila Murray, Luca Marchesotti, and Florent Perronnin. A V A: A large-scale database for aesthetic visual analysis. In2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 2408–2415, 2012. doi: 10.1109/CVPR.2012.6247954
-
[2]
Shu Kong, Xiaohui Shen, Zhe Lin, Radomir Mech, and Charless C. Fowlkes. Photo aesthetics ranking network with attributes and content adaptation. InComputer Vision – ECCV 2016, volume 9905 ofLecture Notes in Computer Science, pages 662–679. Springer, 2016. doi: 10.1007/978-3-319-46448-0_40
-
[3]
Q-Align: Teaching LMMs for visual scoring via discrete text-defined levels
Haoning Wu, Zicheng Zhang, Weixia Zhang, Chaofeng Chen, Liang Liao, Chunyi Li, Yixuan Gao, Annan Wang, Erli Zhang, Wenxiu Sun, Qiong Yan, Xiongkuo Min, Guangtao Zhai, and Weisi Lin. Q-Align: Teaching LMMs for visual scoring via discrete text-defined levels. InProceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings o...
work page 2024
-
[4]
Maria Perez-Ortiz, Aliaksei Mikhailiuk, Emin Zerman, Vedad Hulusic, Giuseppe Valenzise, and Rafal K. Mantiuk. From pairwise comparisons and rating to a unified quality scale.IEEE Transactions on Image Processing, 29:1139–1151, 2019. doi: 10.1109/TIP.2019.2936103
-
[5]
Pairwise or pointwise? eval- uating feedback protocols for bias in LLM-based evaluation
Tuhina Tripathi, Manya Wadhwa, Greg Durrett, and Scott Niekum. Pairwise or pointwise? eval- uating feedback protocols for bias in LLM-based evaluation. InProceedings of the Conference on Language Modeling, 2025. URLhttps://openreview.net/forum?id=uyX5Vnow3U
work page 2025
-
[6]
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: An open platform for evaluating LLMs by human preference. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine L...
work page 2024
-
[7]
Ruihang Li, Leigang Qu, Jingxu Zhang, Dongnan Gui, Mengde Xu, Xiaosong Zhang, Han Hu, Wenjie Wang, and Jiaqi Wang. GenArena: How can we achieve human-aligned evaluation for visual generation tasks?arXiv preprint arXiv:2602.06013, 2026. doi: 10.48550/arXiv.2602. 06013
-
[8]
Wei Zhang, Jian-Wei Zhang, Kam-Kwai Wong, Yi-Fang Wang, Ying-Chao-Jie Feng, Lu-Wei Wang, and Wei Chen. Computational approaches for traditional chinese painting: From the “six principles of painting” perspective.Journal of Computer Science and Technology, 39(2): 269–285, 2024. doi: 10.1007/s11390-024-3408-x
-
[9]
Hongji Yang, Yucheng Zhou, Wencheng Han, Songlian Li, Xiaotong Zhao, and Jianbing Shen. HanMoVLM: Large vision-language models for professional artistic painting evaluation.arXiv preprint arXiv:2603.10814, 2026. doi: 10.48550/arXiv.2603.10814
-
[10]
Ran Yi, Haoyuan Tian, Zhihao Gu, Yu-Kun Lai, and Paul L. Rosin. Towards artistic image aesthetics assessment: A large-scale dataset and a new method. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22388–22397, 2023. doi: 10.1109/CVPR52729.2023.02144
-
[11]
APDDv2: Aesthetics of paintings and drawings dataset with artist labeled scores and comments
Xin Jin, Qianqian Qiao, Yi Lu, Huaye Wang, Heng Huang, Shan Gao, Jianfei Liu, and Rui Li. APDDv2: Aesthetics of paintings and drawings dataset with artist labeled scores and comments. InAdvances in Neural Information Processing Systems, volume 37, 2024. doi: 10.52202/079017-3274
-
[12]
Artimuse: Fine-grained image aesthetics assessment with joint scoring and expert-level understanding
Shuo Cao, Nan Ma, Jiayang Li, Xiaohui Li, Lihao Shao, Kaiwen Zhu, Yu Zhou, Yuandong Pu, Jiarui Wu, Jiaquan Wang, Bo Qu, Wenhai Wang, Yu Qiao, Dajuin Yao, and Yihao Liu. ArtiMuse: Fine-grained image aesthetics assessment with joint scoring and expert-level understanding. arXiv preprint arXiv:2507.14533, 2025. doi: 10.48550/arXiv.2507.14533. 11
-
[13]
Zhichao Yang, Jianjie Wang, Zhixianhe Zhang, Pangu Xie, Xiangfei Sheng, Pengfei Chen, and Leida Li. Fine-grained image aesthetic assessment: Learning discriminative scores from relative ranks.arXiv preprint arXiv:2603.03907, 2026. doi: 10.48550/arXiv.2603.03907. Accepted to CVPR 2026
-
[14]
NIMA: Neural image assessment.IEEE Transactions on Image Processing, 27(8):3998–4011, 2018
Hossein Talebi and Peyman Milanfar. NIMA: Neural image assessment.IEEE Transactions on Image Processing, 27(8):3998–4011, 2018. doi: 10.1109/TIP.2018.2831899
-
[15]
Motiondiffuser: Controllable multi-agent motion prediction using diffusion
Junjie Ke, Keren Ye, Jiahui Yu, Yonghui Wu, Peyman Milanfar, and Feng Yang. VILA: Learning image aesthetics from user comments with vision-language pretraining. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10041–10051, 2023. doi: 10.1109/CVPR52729.2023.00968
-
[16]
Zhaokun Zhou, Qiulin Wang, Bin Lin, Yiwei Su, Rui Chen, Xin Tao, Amin Zheng, Li Yuan, Pengfei Wan, and Di Zhang. UNIAA: A unified multi-modal image aesthetic assessment baseline and benchmark.arXiv preprint arXiv:2404.09619, 2024. doi: 10.48550/arXiv.2404.09619
-
[17]
Jun-Tae Lee and Chang-Su Kim. Image aesthetic assessment based on pairwise comparison: A unified approach to score regression, binary classification, and personalization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1191–1200, 2019
work page 2019
-
[18]
Yixiao Song, Parker Riley, Daniel Deutsch, and Markus Freitag. Enhancing human evaluation in machine translation with comparative judgement. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 20536–20551, Vienna, Austria, 2025. Association for Computational Linguistics. doi: 10.18653/v...
-
[19]
Peering through preferences: Unraveling feedback acquisition for aligning large language models
Hritik Bansal, John Dang, and Aditya Grover. Peering through preferences: Unraveling feedback acquisition for aligning large language models. InInternational Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=dKl6lMwbCy
work page 2024
- [20]
-
[21]
Ralph Allan Bradley and Milton E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
work page 1952
- [22]
-
[23]
Elo.The Rating of Chessplayers, Past and Present
Arpad E. Elo.The Rating of Chessplayers, Past and Present. Arco Publishing, 1978
work page 1978
-
[24]
Hanwei Zhu, Haoning Wu, Yixuan Li, Zicheng Zhang, Baoliang Chen, Lingyu Zhu, Yuming Fang, Guangtao Zhai, Weisi Lin, and Shiqi Wang. Adaptive image quality assessment via teaching large multimodal model to compare.arXiv preprint arXiv:2405.19298, 2024. doi: 10.48550/arXiv.2405.19298
-
[25]
Tianhe Wu, Jian Zou, Jie Liang, Lei Zhang, and Kede Ma. VisualQuality-R1: Reasoning- induced image quality assessment via reinforcement learning to rank.arXiv preprint arXiv:2505.14460, 2025. doi: 10.48550/arXiv.2505.14460
-
[26]
Wen Wen, Tianwu Zhi, Kanglong Fan, Yang Li, Xinge Peng, Yabin Zhang, Yiting Liao, Junlin Li, and Li Zhang. Self-evolving vision-language models for image quality assessment via voting and ranking.arXiv preprint arXiv:2509.25787, 2025. doi: 10.48550/arXiv.2509.25787
-
[27]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. doi: 10.48550/arXiv.2402.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[28]
FRank: A ranking method with fidelity loss
Ming-Feng Tsai, Tie-Yan Liu, Tao Qin, Hsin-Hsi Chen, and Wei-Ying Ma. FRank: A ranking method with fidelity loss. InProceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 383–390. ACM,
-
[29]
doi: 10.1145/1277741.1277808. 12
-
[30]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, et al. Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025. doi: 10.48550/arXiv.2511.21631
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21631 2025
-
[31]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Yuchen Duan, Hao Tian, Weijie Su, Jie Shao, et al. InternVL3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. doi: 10.48550/arXiv.2504.10479. 13 A Dataset and Annotation Protocol Details A.1 Dataset Compositio...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.10479 2025
-
[32]
technique 2) coloration 3) composition 4) mood 5) overall First output the thinking process in⟨think⟩ ⟨/think⟩tags and then output the final answer as valid JSON in⟨answer⟩ ⟨/answer⟩tags: {“technique”:⟨1.00–5.00⟩, “coloration”:⟨1.00–5.00⟩, “composition”: ⟨1.00–5.00⟩, “mood”:⟨1.00–5.00⟩, “overall”:⟨1.00–5.00⟩} 23 Pairwise prompt. You are an expert in tradi...
-
[33]
technique 2) coloration 3) composition 4) mood 5) overall First output the thinking process in⟨think⟩ ⟨/think⟩tags and then output the final answer as valid JSON in⟨answer⟩ ⟨/answer⟩tags: {“technique”: “A”/“B”/“TIE”, “coloration”: “A”/“B”/“TIE”, “composition”: “A”/“B”/“TIE”, “mood”: “A”/“B”/“TIE”, “overall”: “A”/“B”/“TIE”} D.4 Closed-Source Model Versions...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.