RankE: End-to-End Post-Training for Discrete Text-to-Image Generation with Decoder Co-Evolution
Pith reviewed 2026-05-21 05:44 UTC · model grok-4.3
The pith
Policy-only optimization in discrete text-to-image models creates a token-distribution mismatch with the frozen decoder that improves rewards while harming image quality, but co-evolving both resolves the trade-off.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
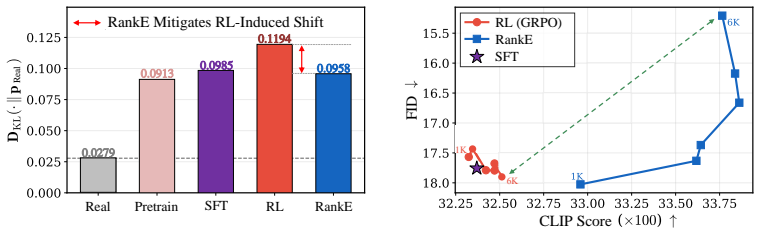
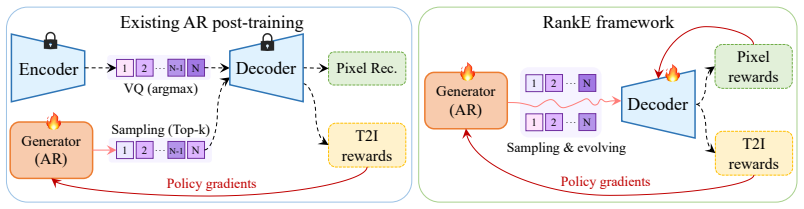
Policy-only post-training induces latent covariate shift between the policy's token distribution and the decoder's original training distribution, producing higher reward metrics but lower decoded image quality; RankE eliminates this mismatch by co-evolving both components through alternating optimization in which each module maximizes a ranking-based alignment objective while being regularized by a stability-preserving anchor suited to its parameter space.
What carries the argument
Alternating optimization of policy and decoder, each maximizing a ranking-based alignment objective while regularized by a stability-preserving anchor.
If this is right
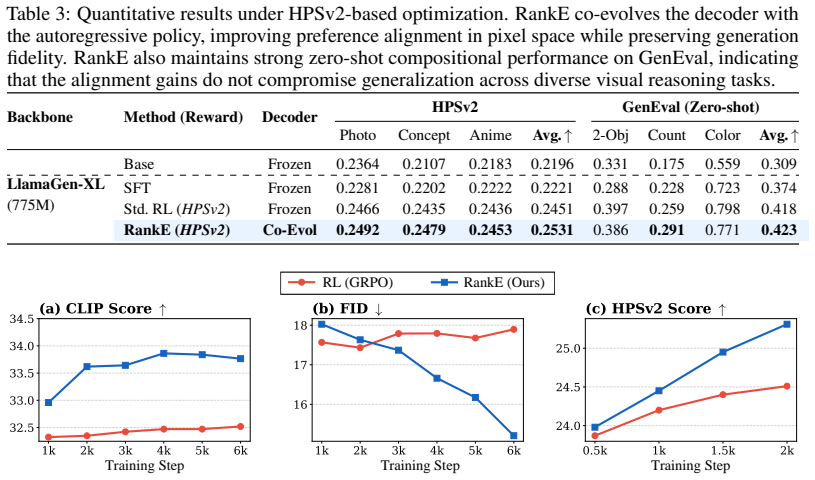
- Standard RL improves CLIP but degrades FID, while RankE improves both simultaneously.
- On LlamaGen-XL (775M) the method reaches FID 15.21 and CLIP 33.76 on MS-COCO 30K.
- Consistent gains appear on Janus-Pro (1B) as well.
- Reward optimization is converted directly into pixel-space quality improvements instead of a trade-off.
Where Pith is reading between the lines
- The same co-evolution pattern could be tested on discrete autoregressive models for video or audio to check whether token-distribution mismatch is a general problem.
- If stability anchors prove unnecessary in later work, full joint gradient updates between policy and decoder might become feasible.
- The ranking objective used here might be replaced by other preference signals without changing the core need for decoder updates.
Load-bearing premise
The observed drop in decoded image quality after policy-only optimization is caused by divergence between the new token distribution and the decoder's original training distribution, and alternating co-evolution with anchors can correct the mismatch without introducing fresh instabilities or overfitting.
What would settle it
Sample a large set of tokens from the fully optimized policy, train a fresh decoder on those tokens alone, and measure whether the resulting FID matches or exceeds the co-evolved decoder's FID on the same prompts.
Figures



read the original abstract
Discrete autoregressive (AR) text-to-image (T2I) models pair a VQ tokenizer with an AR policy, and current post-training pipelines optimize only the policy while keeping the VQ decoder frozen. Recent diffusion T2I work, exemplified by REPA-E, has shown that the VAE itself constitutes a key alignment bottleneck, yet no analogous investigation exists for discrete AR models. We show that policy-only optimization induces Latent Covariate Shift: as the policy evolves, the resulting token distribution diverges from the ground-truth distribution on which the decoder was trained, such that reward scores improve while decoded image quality degrades. To address this mismatch, we propose RankE, the first end-to-end post-training framework for discrete T2I generation. Rather than optimizing the policy against a fixed decoder, RankE co-evolves both components through alternating optimization: each module maximizes a ranking-based alignment objective while being regularized by a stability-preserving anchor suited to its parameter space. This co-evolution breaks the fidelity--alignment trade-off that plagues frozen-decoder approaches: on LlamaGen-XL (775M), standard RL improves CLIP but degrades FID, whereas RankE improves both simultaneously (FID 15.21, CLIP 33.76 on MS-COCO 30K). Consistent gains on Janus-Pro (1B) confirm that decoder co-evolution reliably converts reward optimization into pixel-space quality improvements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that policy-only post-training of discrete autoregressive text-to-image models induces latent covariate shift between the evolving token distribution and the frozen VQ decoder, improving alignment (CLIP) at the expense of pixel quality (FID). RankE addresses this via alternating optimization that co-evolves the policy and decoder using ranking-based alignment objectives regularized by stability anchors. On LlamaGen-XL (775M) it reports simultaneous gains (FID 15.21, CLIP 33.76 on MS-COCO 30K) versus standard RL, with consistent results on Janus-Pro (1B).
Significance. If the reported metric improvements are robust and the covariate-shift mechanism is validated, the work offers a practical route to breaking the fidelity-alignment trade-off in discrete T2I post-training. The alternating co-evolution strategy with ranking objectives and stability anchors is a concrete contribution that could generalize beyond the tested models. However, the significance is limited by the absence of direct mechanistic evidence or isolating ablations, leaving the justification for decoder co-evolution as the necessary remedy open to alternative explanations.
major comments (3)
- [Abstract and §3] Abstract and §3: The central claim that policy-only RL induces latent covariate shift (and that this is the cause of FID degradation) is presented without quantitative characterization of the shift, such as token-histogram divergence, per-layer activation statistics, or reconstruction error on policy-generated samples. No ablation isolates decoder co-evolution from other effects of the alternating schedule.
- [Experiments] Experiments section (results on LlamaGen-XL and Janus-Pro): The reported FID and CLIP numbers lack error bars, number of random seeds, or statistical significance tests. It is therefore unclear whether the simultaneous improvement over standard RL is reliable or sensitive to hyper-parameter choices.
- [§4] §4 (ablation studies): The manuscript provides no ablation that removes the stability anchors or the ranking objective individually while keeping the alternating schedule, making it impossible to attribute gains specifically to decoder co-evolution rather than increased optimization capacity or regularization.
minor comments (2)
- [§3.2] The precise mathematical form of the stability-preserving anchor for the decoder (versus the policy) is only sketched; an explicit equation in the main text would improve reproducibility.
- [Figure 2] Figure 2 (qualitative examples) would benefit from side-by-side comparison with the standard RL baseline at matched CLIP score to illustrate the claimed quality difference.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below, proposing specific revisions to strengthen the manuscript while maintaining the integrity of our claims.
read point-by-point responses
-
Referee: [Abstract and §3] The central claim that policy-only RL induces latent covariate shift (and that this is the cause of FID degradation) is presented without quantitative characterization of the shift, such as token-histogram divergence, per-layer activation statistics, or reconstruction error on policy-generated samples. No ablation isolates decoder co-evolution from other effects of the alternating schedule.
Authors: We agree that direct quantitative evidence of the covariate shift would strengthen the central claim. In the revised manuscript, we will add token-histogram KL divergence and reconstruction error metrics on policy-generated samples versus training data in §3. For isolating decoder co-evolution, we will include a new ablation comparing the full alternating RankE against a variant that performs alternating updates but freezes the decoder after initial steps. While perfect isolation is inherently limited by the coupled optimization, this ablation will clarify the contribution of decoder evolution beyond the alternating schedule alone. revision: yes
-
Referee: The reported FID and CLIP numbers lack error bars, number of random seeds, or statistical significance tests. It is therefore unclear whether the simultaneous improvement over standard RL is reliable or sensitive to hyper-parameter choices.
Authors: We acknowledge this limitation in statistical reporting. In the revision, we will rerun the main results on LlamaGen-XL and Janus-Pro using at least three random seeds, reporting means and standard deviations for FID and CLIP. We will also add a brief discussion of hyperparameter sensitivity based on our existing tuning logs to address reliability concerns. revision: yes
-
Referee: The manuscript provides no ablation that removes the stability anchors or the ranking objective individually while keeping the alternating schedule, making it impossible to attribute gains specifically to decoder co-evolution rather than increased optimization capacity or regularization.
Authors: We thank the referee for highlighting this gap. In the updated §4, we will add two targeted ablations while preserving the alternating schedule: (1) disabling stability anchors, and (2) replacing the ranking objective with standard RL loss. These will help attribute performance gains more precisely to decoder co-evolution versus other regularization or optimization effects. revision: yes
Circularity Check
No significant circularity; empirical observation and method proposal remain self-contained
full rationale
The paper motivates RankE from an empirical observation that policy-only RL on discrete AR T2I models improves reward metrics while degrading FID, attributing this to an induced divergence between the evolving token distribution and the decoder's original training support. This observation is presented as a measured phenomenon rather than derived from equations that presuppose the conclusion. The proposed alternating optimization with ranking objectives and stability anchors is introduced as a direct response to the observed mismatch, with performance gains demonstrated via direct comparison to frozen-decoder RL baselines on LlamaGen-XL and Janus-Pro. No load-bearing step reduces a prediction to a fitted parameter by construction, invokes a self-citation as an unverified uniqueness theorem, or renames a known result under new coordinates. The derivation chain is therefore grounded in external experimental contrasts rather than internal redefinition.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Policy-only optimization induces a divergence between generated token distribution and the decoder's original training distribution.
- ad hoc to paper Alternating optimization with ranking objectives and stability anchors can break the fidelity-alignment trade-off without introducing instability.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
policy-only optimization induces Latent Covariate Shift... RankE co-evolves both components through alternating optimization
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Generalized EM interpretation... stability-preserving anchor
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Scheduled sampling for sequence prediction with recurrent neural networks
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks. InNeurIPS, 2015. 2
work page 2015
-
[2]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432, 2013. 2, 3, 15
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[3]
Improving image generation with better captions.Computer Science, 2023
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions.Computer Science, 2023. 21
work page 2023
-
[4]
Training diffusion models with reinforcement learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning. InICLR, 2024. 3
work page 2024
-
[5]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
MaskGIT: Masked generative image transformer
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. MaskGIT: Masked generative image transformer. InCVPR, 2022. 15
work page 2022
-
[7]
Muse: Text-to-image generation via masked generative transformers
Huiwen Chang, Han Zhang, Jarred Barber, AJ Maschinot, Jose Lezama, Lu Jiang, Ming-Hsuan Yang, Kevin Murphy, William T Freeman, Michael Rubinstein, et al. Muse: Text-to-image generation via masked generative transformers. InICML, 2023. 15
work page 2023
-
[8]
Softvq-vae: Efficient 1-dimensional continuous tokenizer
Hao Chen, Ze Wang, Xiang Li, Ximeng Sun, Fangyi Chen, Jiang Liu, Jindong Wang, Bhiksha Raj, Zicheng Liu, and Emad Barsoum. Softvq-vae: Efficient 1-dimensional continuous tokenizer. InCVPR, 2025. 15
work page 2025
-
[9]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Silvio Savarese, et al. Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset.arXiv preprint arXiv:2505.09568, 2025. 21
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025. 1, 3, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Directly fine-tuning diffusion models on differentiable rewards
Kevin Clark, Paul Vicol, Kevin Swersky, and David J Fleet. Directly fine-tuning diffusion models on differentiable rewards. InICLR, 2024. 2, 3, 5, 7
work page 2024
-
[12]
Reward model ensembles help mitigate overoptimization
Thomas Coste, Usman Anwar, Robert Kirk, and David Krueger. Reward model ensembles help mitigate overoptimization. InICLR, 2024. 4
work page 2024
-
[13]
Arthur P Dempster, Nan M Laird, and Donald B Rubin. Maximum likelihood from incomplete data via the EM algorithm.Journal of the Royal Statistical Society: Series B, 1977. 17
work page 1977
-
[14]
CogView: Mastering text-to-image generation via transformers
Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, and Jie Tang. CogView: Mastering text-to-image generation via transformers. In NeurIPS, 2021. 15
work page 2021
-
[15]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InCVPR, 2021. 1, 6, 15
work page 2021
-
[16]
Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Mo- hammad Ghavamzadeh, Kangwook Lee, and Kimin Lee. Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models. InNeurIPS, 2024. 3, 7
work page 2024
-
[17]
Scaling laws for reward model overoptimization
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. InICML,
-
[18]
GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Alexander Schwing. GenEval: An object-focused framework for evaluating text-to-image alignment.arXiv preprint arXiv:2310.11513, 2023. 6, 21
-
[19]
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. InNeurIPS, 2014. 5, 17
work page 2014
-
[20]
Bootstrap your own latent: A new approach to self-supervised learning
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent: A new approach to self-supervised learning. InNeurIPS, 2020. 6
work page 2020
-
[21]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. InNeurIPS, 2017. 6 11
work page 2017
-
[22]
Minyoung Huh, Brian Cheung, Pulkit Agrawal, and Phillip Isola. Straightening out the straight-through estimator: Overcoming optimization challenges in vector quantized networks.ICML, 2023. 2, 16
work page 2023
-
[23]
Image-to-image translation with conditional adversarial networks
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. InCVPR, 2017. 20
work page 2017
-
[24]
Categorical reparameterization with Gumbel-softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with Gumbel-softmax. InICLR,
-
[25]
Dongzhi Jiang, Ziyu Guo, Renrui Zhang, Zhuofan Zong, Hao Li, Le Zhuo, Shilin Yan, Pheng-Ann Heng, and Hongsheng Li. T2i-r1: Reinforcing image generation with collaborative semantic-level and token-level cot.arXiv preprint arXiv:2505.00703, 2025. 1, 3
-
[26]
Fast decoding in sequence models using discrete latent variables
Łukasz Kaiser, Aurko Roy, Ashish Vaswani, Niki Parmar, Samy Bengio, Jakob Unkber, and Noam Shazeer. Fast decoding in sequence models using discrete latent variables. InICML, 2018. 2, 16
work page 2018
-
[27]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020. 1, 15
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[28]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 2017. 6
work page 2017
-
[29]
Rl with kl penalties is better viewed as bayesian inference
Tomasz Korbak, Hady Elsahar, Germán Kruszewski, and Marc Dymetman. Rl with kl penalties is better viewed as bayesian inference. InEMNLP, 2022. 3, 4
work page 2022
-
[30]
Repa-e: Unlocking vae for end-to-end tuning of latent diffusion transformers
Xingjian Leng, Jaskirat Singh, Yunzhong Hou, Zhenchang Xing, Saining Xie, and Liang Zheng. Repa-e: Unlocking vae for end-to-end tuning of latent diffusion transformers. InCVPR, 2025. 1, 2, 3, 7, 16
work page 2025
-
[31]
Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
Sergey Levine. Reinforcement learning and control as probabilistic inference: Tutorial and review.arXiv preprint arXiv:1805.00909, 2018. 3, 4, 16
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
Siyuan Li, Luyuan Zhang, Zedong Wang, Juanxi Tian, Cheng Tan, Zicheng Liu, Chang Yu, Qingsong Xie, Haonan Lu, Haoqian Wang, and Zhen Lei. Mergevq: A unified framework for visual generation and representation with disentangled token merging and quantization. InCVPR, 2025. 15
work page 2025
-
[33]
Va-π: Variational policy alignment for pixel-aware autoregressive generation
Xinyao Liao, Qiyuan He, Kai Xu, Xiaoye Qu, Yicong Li, Wei Wei, and Angela Yao. Va-π: Variational policy alignment for pixel-aware autoregressive generation. InCVPR, 2026. 1, 3, 7
work page 2026
-
[34]
Microsoft COCO: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft COCO: Common objects in context. InECCV, 2014. 6, 18, 21
work page 2014
-
[35]
Flow matching for generative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InICLR, 2023. 7
work page 2023
-
[36]
Flow-grpo: Training flow matching models via online rl
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl. InNeurIPS, 2025. 7
work page 2025
-
[37]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR, 2019. 20
work page 2019
-
[38]
Open-magvit2: An open-source project toward democratizing auto-regressive visual gener- ation
Zhuoyan Luo, Fengyuan Shi, Yixiao Ge, Yujiu Yang, Limin Wang, and Ying Shan. Open-magvit2: An open- source project toward democratizing auto-regressive visual generation.arXiv preprint arXiv:2409.04410,
-
[39]
A view of the em algorithm that justifies incremental, sparse, and other variants
Radford M Neal and Geoffrey E Hinton. A view of the em algorithm that justifies incremental, sparse, and other variants. InLearning in graphical models, pages 355–368. Springer, 1998. 5, 17
work page 1998
-
[40]
Training language models to follow instructions with human feedback.NeurIPS, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.NeurIPS, 2022. 10
work page 2022
-
[41]
Ziqi Pang, Tianyuan Zhang, Fujun Luan, Yunze Man, Hao Tan, Kai Zhang, William T. Freeman, and Yu-Xiong Wang. Randar: Decoder-only autoregressive visual generation in random orders. InCVPR, 2024. 15
work page 2024
-
[42]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023. 7
work page 2023
-
[43]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Xue Bin Peng, Aravind Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177, 2019. 5, 17 12
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[44]
Reinforcement learning by reward-weighted regression for operational space control
Jan Peters and Stefan Schaal. Reinforcement learning by reward-weighted regression for operational space control. InICML, 2007. 5, 17
work page 2007
-
[45]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. In ICLR, 2024. 7
work page 2024
-
[46]
Mihir Prabhudesai, Anirudh Goyal, Deepak Pathak, and Katerina Fragkiadaki. Aligning text-to-image diffusion models with reward backpropagation.arXiv preprint arXiv:2310.03739, 2023. 2, 3, 5
-
[47]
Qwen2.5 technical report.arXiv preprint, 2024
Qwen Team. Qwen2.5 technical report.arXiv preprint, 2024. 21, 22
work page 2024
-
[48]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InICML, 2021. 6, 20
work page 2021
-
[49]
Zero-shot text-to-image generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. InICML, 2021. 15
work page 2021
-
[50]
Sequence level training with recurrent neural networks
Marc’Aurelio Ranzato, Sumit Chopra, Michael Auli, and Wojciech Zaremba. Sequence level training with recurrent neural networks. InICLR, 2016. 2
work page 2016
-
[51]
Generating diverse high-fidelity images with VQ-V AE-2
Ali Razavi, Aaron Van den Oord, and Oriol Vinyals. Generating diverse high-fidelity images with VQ-V AE-2. InNeurIPS, 2019. 1
work page 2019
-
[52]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022. 7
work page 2022
-
[53]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. InarXiv preprint arXiv:1707.06347, 2017. 4, 16
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[54]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, YK Li, Y Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 2, 3, 4, 6, 20
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
Scalable image tokenization with index backpropagation quantization
Fengyuan Shi, Zhuoyan Luo, Yixiao Ge, Yujiu Yang, Ying Shan, and Limin Wang. Scalable image tokenization with index backpropagation quantization. InCVPR, 2025. 15
work page 2025
-
[56]
Journeydb: A benchmark for generative image understanding.NeurIPS, 2023
Keqiang Sun, Junting Pan, Yuying Ge, Hao Li, Haodong Duan, Xiaoshi Wu, Renrui Zhang, Aojun Zhou, Zipeng Qin, Yi Wang, et al. Journeydb: A benchmark for generative image understanding.NeurIPS, 2023. 21
work page 2023
-
[57]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autore- gressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised learning results. InNeurIPS, 2017. 6
work page 2017
-
[59]
Visual autoregressive modeling: Scalable image generation via next-scale prediction.NeurIPS, 2024
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction.NeurIPS, 2024. 7, 15
work page 2024
-
[60]
Neural discrete representation learning
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. InNeurIPS, 2017. 1, 15
work page 2017
-
[61]
Diffusion model alignment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization. InCVPR, 2024. 3, 7
work page 2024
-
[62]
Simplear: Pushing the frontier of autoregressive visual generation through pretraining, sft, and rl
Junke Wang, Zhi Tian, Xun Wang, Xinyu Zhang, Weilin Huang, Zuxuan Wu, and Yu-Gang Jiang. Simplear: Pushing the frontier of autoregressive visual generation through pretraining, sft, and rl.arXiv preprint arXiv:2504.11455, 2025. 1, 3
-
[63]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need.arXiv preprint arXiv:2409.18869, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [64]
-
[65]
C. F. Jeff Wu. On the convergence properties of the EM algorithm.The Annals of Statistics, 11(1):95–103,
-
[66]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341, 2023. 3, 6, 20
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[67]
Gigatok: Scaling visual tokenizers to 3 billion parameters for autoregressive image generation
Tianwei Xiong, Jun Hao Liew, Zilong Huang, Jiashi Feng, and Xihui Liu. Gigatok: Scaling visual tokenizers to 3 billion parameters for autoregressive image generation. InCVPR, 2025. 15
work page 2025
-
[68]
Imagereward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. InNeurIPS, 2023. 3
work page 2023
-
[69]
Scaling autoregressive models for content-rich text-to-image generation.TMLR, 2022
Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Amin Karbasi, et al. Scaling autoregressive models for content-rich text-to-image generation.TMLR, 2022. 7, 15
work page 2022
-
[70]
An image is worth 32 tokens for reconstruction and generation
Qihang Yu, Mark Weber, Xueqing Deng, Xiaohui Shen, Daniel Cremers, and Liang-Chieh Chen. An image is worth 32 tokens for reconstruction and generation. InNeurIPS, 2024. 15
work page 2024
-
[71]
Group critical-token policy optimization for autoregressive image generation
Guohui Zhang, Hu Yu, Xiaoxiao Ma, Jinghao Zhang, Yaning Pan, Mingde Yao, Jie Xiao, Linjiang Huang, and Feng Zhao. Group critical-token policy optimization for autoregressive image generation. InICLR,
-
[72]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, 2018. 6
work page 2018
-
[73]
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Chunting Zhou, Lili Yu, Arun Babu, Kushal Tirumala, Michihiro Yasunaga, Leonid Shamis, Jacob Kahn, Xuezhe Ma, Luke Zettlemoyer, and Omer Levy. Transfusion: Predict the next token and diffuse images with one multi-modal model.arXiv preprint arXiv:2408.11039, 2024. 7 14 Appendix for RankE Roadmap The appendix is organized into three parts, progressing from ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.