PALS: Power-Aware LLM Serving for Mixture-of-Experts Models
Pith reviewed 2026-05-21 04:02 UTC · model grok-4.3
The pith
PALS improves LLM serving energy efficiency up to 26.3% by treating GPU power caps as a tunable control knob alongside batch size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
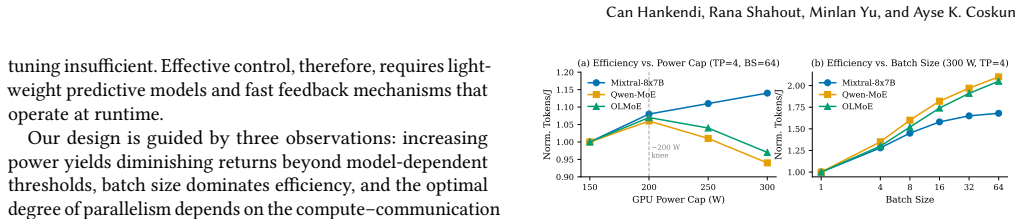
PALS treats GPU power caps as a first-class control knob that is optimized together with batch size. Lightweight offline power-performance models combined with a feedback-driven controller select operating points that satisfy throughput targets while maximizing energy efficiency. The system runs inside an unmodified vLLM serving stack and delivers up to 26.3% better energy efficiency, 4x to 7x fewer QoS violations under power constraints, and the ability to track dynamic power budgets across multi-GPU setups for both dense and MoE models.
What carries the argument
Lightweight offline power-performance models paired with a feedback-driven controller that jointly tunes GPU power caps and batch size to meet throughput targets.
If this is right
- LLM serving systems can operate closer to energy-proportional behavior by actively lowering power when load permits.
- Data centers gain the ability to respect dynamic power caps from the grid without large drops in delivered throughput.
- The same power-aware control loop applies to both dense and sparse mixture-of-experts models without separate tuning paths.
- Existing inference frameworks can adopt the technique through a runtime layer rather than hardware or model changes.
- Quality-of-service targets become easier to maintain when power availability fluctuates.
Where Pith is reading between the lines
- Similar offline modeling plus feedback control could be applied to other GPU-heavy workloads such as training or scientific simulation if comparable power-performance surfaces exist.
- Integration with demand-response signals from utilities would let AI clusters participate in grid stabilization without custom hardware.
- Online refinement of the power models during operation might further reduce the gap between predicted and actual energy use under changing thermal conditions.
Load-bearing premise
Lightweight offline power-performance models built without model retraining can accurately guide a feedback controller to choose batch sizes and power caps that meet throughput targets on both dense and MoE models.
What would settle it
Run the controller on a held-out GPU architecture or workload trace and measure whether the selected power-cap and batch-size pairs consistently miss the target throughput by more than a few percent; sustained misses would show the models do not transfer well enough to support the claims.
Figures









read the original abstract
Large language model (LLM) inference has become a dominant workload in modern data centers, driving significant GPU utilization and energy consumption. While prior systems optimize throughput and latency by batching, scheduling, and parallelism, they largely treat GPU power as a static constraint rather than a controllable resource. In this paper, we present a power-aware runtime for LLM serving, PALS, that treats GPU power caps as a first-class control knob and jointly optimizes them with software parameters such as batch size. The system combines lightweight offline power-performance models with a feedback-driven controller to select configurations that satisfy throughput targets while maximizing energy efficiency. We implement PALS within an existing LLM serving framework, vLLM, demonstrating that it requires no model retraining or API changes. Across multi-GPU systems and both dense and mixture-of-experts (MoE) models, PALS improves energy efficiency by up to 26.3%, reduces QoS violations by 4x to 7x under power constraints, and tracks dynamic power budgets. These results highlight the potential of integrating power control directly into LLM inference runtimes, enabling energy-proportional and grid-interactive AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PALS, a power-aware runtime for LLM serving that treats GPU power caps as a first-class control knob. It combines lightweight offline power-performance models with a feedback-driven controller to jointly tune batch sizes and power caps, aiming to meet throughput targets while maximizing energy efficiency. Implemented in vLLM with no model retraining or API changes, the system is evaluated on multi-GPU setups for both dense and MoE models, claiming up to 26.3% energy efficiency gains, 4x–7x reductions in QoS violations under power constraints, and the ability to track dynamic power budgets.
Significance. If the results hold, this work could meaningfully advance energy-proportional LLM inference by integrating power control into serving runtimes. The practical focus on deployment without retraining or API modifications, along with explicit evaluation on MoE models, is a strength that addresses an increasingly relevant architecture.
major comments (2)
- [§4.2] §4.2 (Offline Power-Performance Models): The central claim that lightweight offline models can accurately guide the feedback controller for MoE models rests on the assumption that profiling runs capture input-dependent expert activation patterns. The manuscript does not describe how the models account for variability in routing decisions or token distributions; if constructed from fixed or average-case traces, predictions may deviate in deployment and directly undermine the reported energy-efficiency and QoS-violation results.
- [§6] §6 (Evaluation): The quantitative claims (26.3% efficiency improvement, 4x–7x QoS reduction) are presented without reported error bars, number of runs, or explicit description of power-measurement methodology and baselines. This information is load-bearing for assessing whether the gains are robust across input distributions and hardware configurations.
minor comments (2)
- [Abstract] Abstract: The phrase 'up to 26.3%' would be clearer if the specific model, hardware configuration, and workload that achieve this maximum were stated.
- [§3] Notation: The symbols for power cap (P_cap) and target throughput could be introduced with a small table or equation early in §3 to improve readability for readers unfamiliar with the control loop.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below, indicating where we agree and plan revisions to strengthen the paper.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Offline Power-Performance Models): The central claim that lightweight offline models can accurately guide the feedback controller for MoE models rests on the assumption that profiling runs capture input-dependent expert activation patterns. The manuscript does not describe how the models account for variability in routing decisions or token distributions; if constructed from fixed or average-case traces, predictions may deviate in deployment and directly undermine the reported energy-efficiency and QoS-violation results.
Authors: We agree that §4.2 would benefit from a more explicit description of how variability is handled. The offline models were constructed from profiling runs using a diverse collection of input traces drawn from real-world workloads, deliberately including sequences with varying lengths, content, and resulting expert routing patterns to capture input-dependent activation behavior in MoE models. The feedback controller then uses online measurements to compensate for any residual deviations from the profiled averages. We will revise the section to detail the trace selection process, the range of routing variability observed, and how this informs the lightweight model construction. revision: yes
-
Referee: [§6] §6 (Evaluation): The quantitative claims (26.3% efficiency improvement, 4x–7x QoS reduction) are presented without reported error bars, number of runs, or explicit description of power-measurement methodology and baselines. This information is load-bearing for assessing whether the gains are robust across input distributions and hardware configurations.
Authors: The referee is correct that these details are necessary for rigorous evaluation. We performed 5 independent runs for each reported configuration and will add error bars showing standard deviation. Power was measured via the NVIDIA NVML API with a 100 ms sampling interval on the multi-GPU testbed; baselines were unmodified vLLM with a static power cap matching the hardware limit. We will expand §6 and the experimental setup to include this methodology, the number of runs, and a discussion of robustness across the tested input distributions and hardware setups. revision: yes
Circularity Check
No circularity: empirical offline models plus runtime feedback form a self-contained systems design.
full rationale
The paper presents PALS as a runtime system that constructs lightweight offline power-performance models from profiling runs and feeds them into a feedback-driven controller for joint batch-size and power-cap selection. No equations, uniqueness theorems, or derivations are shown that reduce any claimed prediction or result to its own fitted inputs by construction. The central claims rest on implementation inside vLLM and experimental measurements across dense and MoE models; these are externally falsifiable via reproduction on the same hardware rather than being forced by self-citation chains or definitional loops. The approach therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The system combines lightweight offline power–performance models with a feedback-driven controller to select configurations that satisfy throughput targets while maximizing energy efficiency.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PALS improves energy efficiency by up to 26.3%, reduces QoS violations by 4×–7× under power constraints
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Am- mar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jian- min Bao, Harkirat Behl, et al. 2024. Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone.arXiv preprint arXiv:2404.14219(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Bilge Acun, Benjamin Lee, Fiodar Kazhamiaka, Kiwan Maeng, Udit Gupta, Manoj Chakkaravarthy, David Brooks, and Carole-Jean Wu
-
[3]
Carbon Explorer: A Holistic Framework for Designing Car- bon Aware Datacenters. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’23). 118–132. doi:10.1145/3575693.3575754
-
[4]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ram- jee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’24). USENIX Association, 117–134
work page 2024
-
[5]
Reza Yazdani Aminabadi, Samyam Rajbhandari, Minjia Zhang, Am- mar Ahmad Awan, Cheng Li, Du Li, Elton Zheng, Jeff Rasley, Shaden Smith, Olatunji Ruwase, and Yuxiong He. 2022. DeepSpeed-Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale. InSC22: International Conference for High Performance Comput- ing, Networking, Storage ...
work page 2022
-
[6]
Luiz André Barroso, Urs Hölzle, and Parthasarathy Ranganathan. 2019. The Datacenter as a Computer: Designing Warehouse-Scale Machines (3rd ed.). Morgan & Claypool Publishers
work page 2019
-
[7]
Rishabh Bhoria, Anubhav Sehgal, Divyanshu Saxena, Debadatta Mishra, and Purushottam Kulkarni. 2025. TAPAS: Thermal and Power- Aware Scheduling for GPU Clusters. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems
work page 2025
-
[8]
Rishabh Bhoria, Anubhav Sehgal, Divyanshu Saxena, Debadatta Mishra, and Purushottam Kulkarni. 2025. TAPAS: Thermal and Power- Aware Scheduling for GPU Clusters. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’25)
work page 2025
-
[9]
Jae-Won Chung, Yile Gu, Insu Jang, Luoxi Meng, Nikhil Bansal, and Mosharaf Chowdhury. 2023. Zeus: Understanding and Optimizing GPU Energy Consumption of DNN Training. In20th USENIX Sym- posium on Networked Systems Design and Implementation (NSDI ’23). USENIX Association, 119–139
work page 2023
-
[10]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman
-
[11]
Training Verifiers to Solve Math Word Problems.arXiv preprint arXiv:2110.14168(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Damai Dai, Chengqi Deng, Chenggang Zhao, R. X. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y. Wu, Zhenda Xie, Y. K. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui, and Wenfeng Liang. 2024. DeepSeekMoE: Towards Ultimate Expert Spe- cialization in Mixture-of-Experts Language Models.arXiv preprint arXiv:2401.06066(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch Trans- formers: Scaling to Trillion Parameter Models with Simple and Effi- cient Sparsity.Journal of Machine Learning Research23, 120 (2022), 1–39
work page 2022
-
[14]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bam- ford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B.arXiv preprint ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guil- laume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Tev...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Gonzalez, Hao Zhang, and Ion Stoica
Woojin Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica
-
[17]
Efficient Memory Management for Large Language Model Serv- ing with PagedAttention. InProceedings of the ACM SIGOPS 29th Sym- posium on Operating Systems Principles. doi:10.1145/3600006.3613165
-
[18]
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2020. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding.arXiv preprint arXiv:2006.16668 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[19]
Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2022. AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). 663–679
work page 2022
-
[20]
Rohan Mahajan, Minsung Jang, Arjun Singhvi, Krishnan Kutty, Aditya Akella, and Shivaram Venkataraman. 2025. DynamoLLM: Designing LLM Inference Clusters for Performance and Energy Efficiency. In 2025 IEEE International Symposium on High-Performance Computer Architecture (HPCA ’25)
work page 2025
-
[21]
Rohan Mahajan, Minsung Jang, Arjun Singhvi, Krishnan Kutty, Aditya Akella, and Shivaram Venkataraman. 2025. DynamoLLM: Designing LLM Inference Clusters for Performance and Energy Efficiency. In 2025 IEEE International Symposium on High-Performance Computer Architecture (HPCA). 12 PALS: Power-Aware LLM Serving for Mixture-of-Experts Models
work page 2025
-
[22]
Yixuan Mei, Yonghao Zhuang, Xupeng Miao, Juncheng Yang, Zhihao Jia, and Rashmi Vinayak. 2025. Helix: Serving Large Language Models over Heterogeneous GPUs and Network via Max-Flow. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’25). 1–17. doi:10.1145/3669940.3707215
-
[23]
OLMoE: Open Mixture-of-Experts Language Models
Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, and Hannaneh Hajishirzi. 2...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Seyed Morteza Nabavinejad, Sherief Reda, and Masoumeh Ebrahimi
-
[25]
Coordinated Batching and DVFS for DNN Inference on GPU Accelerators.IEEE Transactions on Parallel and Distributed Systems33, 10 (2022), 2496–2508. doi:10.1109/TPDS.2021.3137867
-
[26]
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGres- ley, Mostofa Patwary, Vijay Anand Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, Amar Phan- ishayee, and Matei Zaharia. 2021. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM. InProceedings of the International Conference ...
-
[27]
NVIDIA Corporation.https://docs.nvidia.com/ deploy/nvml-api/index.htmlVersion R550
NVIDIA Corporation 2024.NVIDIA Management Library (NVML) API Reference Guide. NVIDIA Corporation.https://docs.nvidia.com/ deploy/nvml-api/index.htmlVersion R550
work page 2024
-
[28]
NVIDIA Corporation.https://developer.nvidia.com/nvidia- system-management-interface
NVIDIA Corporation 2024.nvidia-smi: NVIDIA System Management Interface. NVIDIA Corporation.https://developer.nvidia.com/nvidia- system-management-interface
work page 2024
-
[29]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Íñigo Goiri, Brijesh Warrier, Nithish Mahalingam, and Ricardo Bianchini. 2024. Charac- terizing Power Management Opportunities for LLMs in the Cloud. In Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’24). 207–222. doi:10.114...
-
[30]
Qwen Team. 2024. Qwen1.5-MoE: Matching 7B Model Performance with 1/3 of the Parameters.Qwen Blog(2024).https://qwenlm.github. io/blog/qwen-moe/
work page 2024
-
[31]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language Models are Unsupervised Multitask Learners.OpenAI Blog1, 8 (2019), 9.https://openai.com/research/ language-unsupervised
work page 2019
-
[32]
Ana Radovanovic, Ross Koningstein, Ian Schneider, Bokan Chen, Alexandre Duarte, Binz Roy, Diyue Xiao, Maya Haridasan, Patrick Hung, Nick Care, Saurav Talukdar, Eric Mullen, Kendal Smith, MariEllen Cottman, and Walfredo Cirne. 2023. Carbon-Aware Com- puting for Datacenters.IEEE Transactions on Power Systems38, 2 (2023), 1270–1280. doi:10.1109/TPWRS.2022.3173250
- [33]
- [34]
-
[35]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V. Le, Geoffrey E. Hinton, and Jeff Dean. 2017. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. In5th International Conference on Learning Representations (ICLR ’17). https://openreview.net/forum?id=B1ckMDqlg
work page 2017
-
[36]
Fu, Zhiqiang Xie, Beidi Chen, Clark W
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Daniel Y. Fu, Zhiqiang Xie, Beidi Chen, Clark W. Barrett, Joseph E. Gonzalez, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang. 2023. FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU. InProceedings of the 40th International Conference on Machine...
work page 2023
-
[37]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. InarXiv preprint arXiv:1909.08053
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[38]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Alma- hairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Har...
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [39]
-
[40]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A distributed serving system for {Transformer-Based} generative models. In16th USENIX symposium on operating systems design and implementation (OSDI 22). 521–538
work page 2022
-
[41]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. HellaSwag: Can a Machine Really Finish Your Sentence?. InProceedings of the 57th Annual Meeting of the Association for Com- putational Linguistics (ACL ’19). 4791–4800. doi:10.18653/v1/P19-1472
-
[42]
Zhuoran Zhang, Daniel Wang, and Ayse K. Coskun. 2021. HPC Data Center Participation in Demand Response: An Adaptive Policy with QoS Assurance.IEEE Transactions on Sustainable Computing8, 3 (2021), 754–768. doi:10.1109/TSUSC.2021.3079166
-
[43]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prefill and Decoding for Goodput-Optimized Large Language Model Serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’24). USENIX Association, 193–210. 13
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.