DeepWeb-Bench: A Deep Research Benchmark Demanding Massive Cross-Source Evidence and Long-Horizon Derivation
Pith reviewed 2026-05-21 03:49 UTC · model grok-4.3
The pith
DeepWeb-Bench shows that derivation and calibration failures, not retrieval, limit frontier models on tasks requiring massive cross-source evidence and long-horizon derivation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DeepWeb-Bench consists of tasks that each require massive evidence collection, cross-source reconciliation, and long-horizon multi-step derivation. When tested on nine frontier models, retrieval failures account for only 12-14 percent of errors whereas derivation and calibration failures account for over 70 percent. Strong models primarily fail through incomplete derivation, weak models through hallucinated precision, and models exhibit domain specialization with cross-model agreement of rho equal to 0.61.
What carries the argument
DeepWeb-Bench benchmark structured around four capability families (Retrieval, Derivation, Reasoning, and Calibration) with every reference answer paired to a source-provenance record at four disclosure levels and cross-source checks.
If this is right
- Retrieval is not the main performance bottleneck on current frontier models for deep research tasks.
- Strong and weak models display qualitatively different error patterns, with derivation incompleteness versus hallucinated precision.
- Models show genuine specialization across domains rather than uniform capability.
- Detailed source-provenance records make benchmark scores more auditable against underlying evidence.
Where Pith is reading between the lines
- Development efforts may benefit more from advances in multi-step evidence synthesis than from further retrieval improvements.
- Low cross-model agreement suggests potential gains from domain-aware model routing or ensembles.
- The provenance structure could support future benchmarks that test dynamic evidence updating over time.
Load-bearing premise
The selected tasks genuinely demand massive evidence collection, cross-source reconciliation, and long-horizon derivation, with reference answers that are accurate and verifiable from the supplied source records.
What would settle it
A frontier model that scores near the top on DeepWeb-Bench yet continues to produce incorrect or unverifiable answers on independent real-world deep research queries outside the benchmark set.
Figures
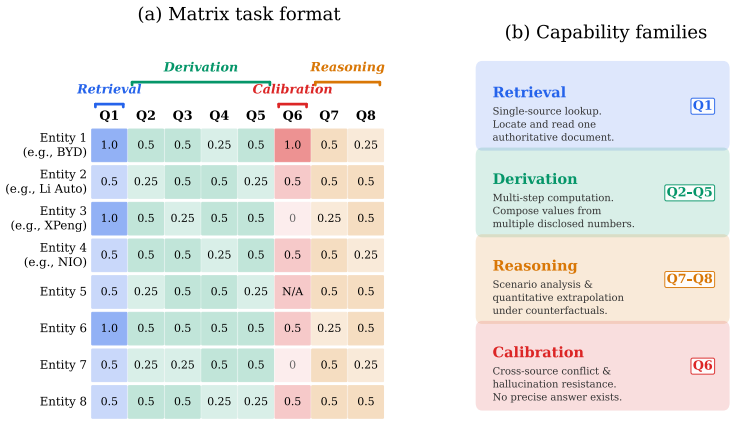








read the original abstract
Deep research, in which an agent searches the open web, collects evidence, and derives an answer through extended reasoning, is a prominent use case for frontier language models. Frontier deep research products score high on existing benchmarks, making it difficult to distinguish their capabilities from current evaluation data alone. We introduce DeepWeb-Bench, a deep research benchmark that is substantially harder than existing benchmarks for the current frontier. Difficulty comes from three properties of the data itself: each task requires massive evidence collection, cross-source reconciliation, and long-horizon multi-step derivation. We represent these three sources of difficulty as four capability families (Retrieval, Derivation, Reasoning, and Calibration) and report results sliced by family. Every reference answer is accompanied by a source-provenance record with four disclosure levels and cross-source checks where available, making scores easier to audit against the underlying evidence. We evaluate DeepWeb-Bench on nine frontier models and report three findings: (1) retrieval is not the bottleneck, as retrieval failures account for only 12-14% of errors while derivation and calibration failures account for over 70%; (2) strong and weak models fail in qualitatively different ways, with strong models' errors dominated by incomplete derivation and weak models' by hallucinated precision; and (3) models exhibit genuine specialization across domains, with cross-model agreement of only rho = 0.61 and per-case disagreement reaching 18.8 percentage points. The public benchmark release includes the data, rubrics, and evaluation code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DeepWeb-Bench, a benchmark for deep research tasks requiring agents to search the open web, collect evidence from multiple sources, reconcile cross-source conflicts, and perform long-horizon multi-step derivation. Difficulty is attributed to three data properties (massive evidence collection, cross-source reconciliation, long-horizon derivation) mapped to four capability families (Retrieval, Derivation, Reasoning, Calibration). Every reference answer includes a four-level source-provenance record. Evaluation on nine frontier models yields three findings: retrieval failures account for only 12-14% of errors while derivation+calibration exceed 70%; strong and weak models exhibit qualitatively different error patterns; and models show domain specialization with cross-model agreement rho=0.61 and per-case disagreement up to 18.8 points. The release includes data, rubrics, and code.
Significance. If the tasks were selected or filtered to genuinely require large-scale retrieval plus multi-step derivation and if reference answers are independently verifiable via the provided provenance, the benchmark would offer diagnostic value beyond existing evaluations where frontier models already saturate. The provenance records and capability-family slicing strengthen auditability and error analysis; the reported specialization and non-retrieval bottlenecks are potentially actionable for model development.
major comments (3)
- [Abstract] Abstract: the central claim that 'each task requires massive evidence collection, cross-source reconciliation, and long-horizon multi-step derivation' and that the benchmark is 'substantially harder' rests on task selection without stated quantitative inclusion criteria (e.g., minimum sources per task, minimum derivation depth, or conflict-resolution steps). This directly affects support for the difficulty assertions and the subsequent error breakdowns.
- [Abstract] Abstract and evaluation section: no inter-annotator agreement statistics are reported for reference-answer correctness or provenance labeling, and the error classification protocol (retrieval 12-14%, derivation+calibration >70%) lacks description of blinding or multi-annotator procedures. These details are load-bearing for the reliability of the capability-family slicing and the three main findings.
- [Results] Results: the finding of genuine specialization (rho=0.61, 18.8 pp disagreement) and the qualitative difference between strong-model incomplete-derivation errors and weak-model hallucinated-precision errors would be strengthened by per-task evidence counts or derivation-step counts that confirm the tasks actually exercise the claimed long-horizon properties.
minor comments (2)
- [Abstract] Abstract lists four capability families but the text order (Retrieval, Derivation, Reasoning, Calibration) leaves unclear whether Reasoning is distinct from Derivation; a brief clarification or table mapping families to the three difficulty sources would help.
- [Abstract] The provenance record is described as having 'four disclosure levels'; an explicit enumeration of those levels in the main text or a small table would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our benchmark's difficulty claims, evaluation reliability, and supporting analyses. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'each task requires massive evidence collection, cross-source reconciliation, and long-horizon multi-step derivation' and that the benchmark is 'substantially harder' rests on task selection without stated quantitative inclusion criteria (e.g., minimum sources per task, minimum derivation depth, or conflict-resolution steps). This directly affects support for the difficulty assertions and the subsequent error breakdowns.
Authors: We agree that explicit quantitative criteria would provide stronger grounding for the difficulty claims. In the revised manuscript we will add a 'Task Selection and Curation' subsection that states the inclusion thresholds used: tasks require a minimum of 8 sources with at least one explicit cross-source conflict, derivation chains of at least 4 steps, and evidence of multi-source reconciliation. We will also report aggregate statistics (mean sources per task = 12.4, mean derivation steps = 5.7) drawn from the released dataset to directly support the assertions and the subsequent error breakdowns. revision: yes
-
Referee: [Abstract] Abstract and evaluation section: no inter-annotator agreement statistics are reported for reference-answer correctness or provenance labeling, and the error classification protocol (retrieval 12-14%, derivation+calibration >70%) lacks description of blinding or multi-annotator procedures. These details are load-bearing for the reliability of the capability-family slicing and the three main findings.
Authors: We acknowledge that these procedural details are necessary for assessing reliability. In the revision we will add inter-annotator agreement figures (percentage agreement and Cohen's kappa) computed on a 20% random sample for both reference-answer correctness and provenance labeling. We will also expand the evaluation section to describe the error-classification protocol: two annotators performed independent classifications while blinded to model identity, with a third annotator resolving disagreements; the resulting protocol description will make the 12-14% retrieval and >70% derivation+calibration figures fully auditable. revision: yes
-
Referee: [Results] Results: the finding of genuine specialization (rho=0.61, 18.8 pp disagreement) and the qualitative difference between strong-model incomplete-derivation errors and weak-model hallucinated-precision errors would be strengthened by per-task evidence counts or derivation-step counts that confirm the tasks actually exercise the claimed long-horizon properties.
Authors: We concur that per-task or aggregate metrics would strengthen the link between task properties and observed error patterns. The revised results section will include a summary table reporting, for each task, the number of distinct sources and the number of derivation steps required by the reference solution. These counts (overall mean 12.4 sources and 5.7 steps) will be used to confirm that the specialization (rho = 0.61) and the qualitative difference in failure modes between strong and weak models are indeed tied to the long-horizon, cross-source nature of the benchmark. revision: yes
Circularity Check
No circularity; benchmark construction and results are self-contained.
full rationale
The paper defines new tasks with claimed properties of massive evidence collection, cross-source reconciliation, and long-horizon derivation, then evaluates models and slices errors by four capability families. No equations, fitted parameters, or predictions appear in the provided text. Claims rest on task design and provenance records rather than reducing to self-citations or inputs by construction. This is an empirical benchmark paper whose central results are independent of any prior fitted quantities from the same data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Amirhossein Abaskohi, Tianyi Chen, Miguel Muñoz-Mármol, Curtis Fox, Amrutha Varshini Ramesh, Étienne Marcotte, Xing Han Lù, Nicolas Chapados, Spandana Gella, Peter West, Giuseppe Carenini, Christopher Pal, Alexandre Drouin, and Issam H. Laradji. Drbench: A realistic benchmark for enterprise deep research, 2025
work page 2025
-
[2]
Anthropic. Claude code, 2025. Anthropic command-line coding agent documentation
work page 2025
-
[3]
Claude takes research to new places, 2025
Anthropic. Claude takes research to new places, 2025. Anthropic product announcement
work page 2025
-
[4]
Introducing claude opus 4.7, 2026
Anthropic. Introducing claude opus 4.7, 2026. Anthropic product announcement, April 16, 2026
work page 2026
-
[5]
Introducing claude sonnet 4.6, 2026
Anthropic. Introducing claude sonnet 4.6, 2026. Anthropic product announcement, February 17, 2026
work page 2026
-
[6]
Synthesizing scientific literature with retrieval-augmented language models.Nature, pages 1–7, 2026
Akari Asai, Jacqueline He, Rulin Shao, Weijia Shi, Amanpreet Singh, Joseph Chee Chang, Kyle Lo, Luca Soldaini, Sergey Feldman, Mike D’Arcy, et al. Synthesizing scientific literature with retrieval-augmented language models.Nature, pages 1–7, 2026
work page 2026
-
[7]
Anna Bavaresco, Raffaella Bernardi, Leonardo Bertolazzi, Desmond Elliott, Raquel Fernández, Albert Gatt, Esam Ghaleb, Mario Giulianelli, Michael Hanna, Alexander Koller, André F. T. Martins, Philipp Mondorf, Vera Neplenbroek, Sandro Pezzelle, Barbara Plank, David Schlangen, Alessandro Suglia, Aditya K. Surikuchi, Ece Takmaz, and Alberto Testoni. LLMs inst...
work page 2025
-
[8]
MLR-Bench: Evaluating AI Agents on Open-Ended Machine Learning Research
Hui Chen, Miao Xiong, Yujie Lu, Wei Han, Ailin Deng, Yufei He, Jiaying Wu, Yibo Li, Yue Liu, and Bryan Hooi. MLR-Bench: Evaluating AI Agents on Open-Ended Machine Learning Research. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[9]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harrison Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavar...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Mind2web: Towards a generalist agent for the web
Shijie Chen, Xiang Deng, Yu Gu, Sam Stevens, Yu Su, Huan Sun, Boshi Wang, and Boyuan Zheng. Mind2web: Towards a generalist agent for the web. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[11]
João Coelho, Jingjie Ning, Jingyuan He, Kangrui Mao, Abhijay Paladugu, Pranav Setlur, Jiahe Jin, Jamie Callan, João Magalhães, Bruno Martins, et al. Deepresearchgym: A free, transparent, and reproducible evaluation sandbox for deep research.arXiv preprint arXiv:2505.19253, 2025
-
[12]
Deepseek v4 preview release, 2026
DeepSeek AI. Deepseek v4 preview release, 2026. DeepSeek API documentation news, April 24, 2026
work page 2026
-
[13]
Deepresearch bench: A comprehensive benchmark for deep research agents, 2025
Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui Wang, and Zhendong Mao. Deepresearch bench: A comprehensive benchmark for deep research agents, 2025. 10
work page 2025
-
[14]
Center for AI Safety Phan Long agibenchmark@ safe. ai 1 Gatti Alice 1 Li Nathaniel 1 Khoja Adam 1 Kim Ryan 1 Ren Richard 1 Hausenloy Jason 1 Zhang Oliver 1 Mazeika Mantas 1 Hendrycks Dan dan@ safe. ai 1. A benchmark of expert-level academic questions to assess ai capabilities.Nature, 649(8099):1139–1146, 2026
work page 2026
-
[15]
Gemini: Try deep research and gemini 2.0 flash experimental, 2024
Google. Gemini: Try deep research and gemini 2.0 flash experimental, 2024. Google product announcement
work page 2024
-
[16]
Mind2web 2: Evaluating agentic search with agent-as-a-judge
Boyu Gou, Zanming Huang, Yuting Ning, Yu Gu, Michael Lin, Weijian Qi, Andrei Kopanev, Botao Yu, Bernal Jimenez Gutierrez, Yiheng Shu, Chan Hee Song, Jiaman Wu, Shijie Chen, Hanane Nour Moussa, TIANSHU ZHANG, Jian Xie, Yifei Li, Tianci Xue, Zeyi Liao, Kai Zhang, Boyuan Zheng, Zhaowei Cai, Viktor Rozgic, Morteza Ziyadi, Huan Sun, and Yu Su. Mind2web 2: Eval...
work page 2026
-
[17]
Deepsearchqa: Bridging the comprehensiveness gap for deep research agents, 2026
Nikita Gupta, Riju Chatterjee, Lukas Haas, Connie Tao, Andrew Wang, Chang Liu, Hidekazu Oiwa, Elena Gribovskaya, Jan Ackermann, John Blitzer, Sasha Goldshtein, and Dipanjan Das. Deepsearchqa: Bridging the comprehensiveness gap for deep research agents, 2026
work page 2026
-
[18]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025
work page 2025
-
[19]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. Swe-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
work page 2024
-
[20]
Haohang Li, Yupeng Cao, Yangyang Yu, Shashidhar Reddy Javaji, Zhiyang Deng, Yueru He, Yuechen Jiang, Zining Zhu, K. P. Subbalakshmi, Jimin Huang, Lingfei Qian, Xueqing Peng, Jordan W. Suchow, and Qianqian Xie. INVESTORBENCH: A Benchmark for Financial Decision-Making Tasks with LLM-based Agent. InProceedings of the 63rd Annual Meeting of the Association fo...
work page 2025
-
[21]
Ruizhe Li, Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui Wang, and Zhendong Mao. Deepresearch bench ii: Diagnosing deep research agents via rubrics from expert report.arXiv preprint arXiv:2601.08536, 2026
-
[22]
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E. Gonzalez, and Ion Stoica. From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[23]
Autobencher: Towards declarative benchmark construction
Xiang Lisa Li, Farzaan Kaiyom, Evan Zheran Liu, Yifan Mai, Percy Liang, and Tatsunori Hashimoto. Autobencher: Towards declarative benchmark construction. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[24]
OpenResearcher: A fully open pipeline for long-horizon deep research trajectory synthesis, 2026
Zhuofan Li et al. OpenResearcher: A fully open pipeline for long-horizon deep research trajectory synthesis, 2026
work page 2026
-
[25]
Wildbench: Benchmarking llms with challenging tasks from real users in the wild
Bill Yuchen Lin, Yuntian Deng, Khyathi Raghavi Chandu, Abhilasha Ravichander, Valentina Pyatkin, Nouha Dziri, Ronan Le Bras, and Yejin Choi. Wildbench: Benchmarking llms with challenging tasks from real users in the wild. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025
work page 2025
-
[26]
Agentbench: Evaluating llms as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating llms as agents. InThe Twelfth International Conference on Learning R...
work page 2024
-
[27]
Jiarui Lu, Thomas Holleis, Yizhe Zhang, Bernhard Aumayer, Feng Nan, Haoping Bai, Shuang Ma, Shen Ma, Mengyu Li, Guoli Yin, Zirui Wang, and Ruoming Pang. Toolsandbox: A stateful, conversational, interactive evaluation benchmark for LLM tool use capabilities. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Findings of the Association for Computational L...
work page 2025
-
[28]
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, Anu...
work page 2026
-
[29]
Gaia: a benchmark for general AI assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general AI assistants. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
- [30]
- [31]
- [32]
- [33]
-
[34]
Introducing deep research, 2025
OpenAI. Introducing deep research, 2025. OpenAI product announcement
work page 2025
-
[35]
OpenAI. Introducing gpt-5.5, 2026. OpenAI product release, April 23, 2026
work page 2026
-
[36]
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. The berkeley function calling leaderboard (BFCL): From tool use to agentic evaluation of large language models. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[37]
Introducing perplexity deep research, 2025
Perplexity. Introducing perplexity deep research, 2025. Perplexity product announcement
work page 2025
-
[38]
Qwen3.6-plus: Towards real world agents, 2026
Qwen Team. Qwen3.6-plus: Towards real world agents, 2026. Qwen product announcement, April 1, 2026
work page 2026
-
[39]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024
work page 2024
-
[40]
Appworld: A controllable world of apps and people for benchmarking interactive coding agents
Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian. Appworld: A controllable world of apps and people for benchmarking interactive coding agents. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Associa- tio...
work page 2024
-
[41]
Liveresearchbench: A live benchmark for user-centric deep research in the wild, 2025
Jiayu Wang, Yifei Ming, Riya Dulepet, Qinglin Chen, Austin Xu, Zixuan Ke, Frederic Sala, Aws Albarghouthi, Caiming Xiong, and Shafiq Joty. Liveresearchbench: A live benchmark for user-centric deep research in the wild, 2025. 12
work page 2025
-
[42]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, and et al. Openhands: An open platform for AI software developers as generalist agents. InThe...
work page 2025
-
[43]
Measuring short-form factuality in large language models, 2024
Jason Wei, Nguyen Karina, Hyung Won Chung, Yunxin Joy Jiao, Spencer Papay, Amelia Glaese, John Schulman, and William Fedus. Measuring short-form factuality in large language models, 2024
work page 2024
-
[44]
Browsecomp: A simple yet challenging benchmark for browsing agents, 2025
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents, 2025
work page 2025
-
[45]
Widesearch: Benchmarking agentic broad info-seeking, 2025
Ryan Wong, Jiawei Wang, Junjie Zhao, Li Chen, Yan Gao, Long Zhang, Xuan Zhou, Zuo Wang, Kai Xiang, Ge Zhang, Wenhao Huang, Yang Wang, and Ke Wang. Widesearch: Benchmarking agentic broad info-seeking, 2025
work page 2025
-
[46]
Webwalker: Benchmarking LLMs in web traversal
Jialong Wu, Wenbiao Yin, Yong Jiang, Zhenglin Wang, Zekun Xi, Runnan Fang, Linhai Zhang, Yulan He, Deyu Zhou, Pengjun Xie, and Fei Huang. Webwalker: Benchmarking LLMs in web traversal. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10290–10305. Association for Computational Linguist...
work page 2025
-
[47]
DeepResearch-9K: A challenging benchmark dataset of deep-research agent, 2026
Tongzhou Wu et al. DeepResearch-9K: A challenging benchmark dataset of deep-research agent, 2026
work page 2026
-
[48]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. In Amir Globersons, Lester Mackey,...
work page 2024
-
[49]
SWE-agent: Agent-computer interfaces enable automated soft- ware engineering
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated soft- ware engineering. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[50]
τ-bench: A benchmark for tool-agent-user interaction in real-world domains, 2024
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains, 2024
work page 2024
-
[51]
AutoResearchBench: Benchmarking AI agents on complex scientific literature discovery, 2026
Cher You, Bowen Chen, Xuan Wang, et al. AutoResearchBench: Benchmarking AI agents on complex scientific literature discovery, 2026
work page 2026
-
[52]
Retrieval augmented fact verification by synthesizing contrastive arguments
Zhenrui Yue, Huimin Zeng, Lanyu Shang, Yifan Liu, Yang Zhang, and Dong Wang. Retrieval augmented fact verification by synthesizing contrastive arguments. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2024
work page 2024
- [53]
-
[54]
Benchmarking data science agents
Yuge Zhang, Qiyang Jiang, Xingyu Han, Nan Chen, Yuqing Yang, and Kan Ren. Benchmarking data science agents. InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 5677–5700. Association for Computational Linguistics, 2024
work page 2024
-
[55]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. In Alice Oh, Tristan Naumann, 13 Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural...
work page 2023
-
[56]
Draco: a cross-domain benchmark for deep research accuracy, completeness, and objectivity, 2026
Joey Zhong, Hao Zhang, Clare Southern, Jeremy Yang, Thomas Wang, Kate Jung, Shu Zhang, Denis Yarats, Johnny Ho, and Jerry Ma. Draco: a cross-domain benchmark for deep research accuracy, completeness, and objectivity, 2026
work page 2026
-
[57]
Browsecomp-zh: Benchmarking web browsing ability of large language models in chinese, 2025
Peilin Zhou, Bruce Leon, Xiang Ying, Can Zhang, Yifan Shao, Qichen Ye, Dading Chong, Zhiling Jin, Chenxuan Xie, Meng Cao, Yuxin Gu, Sixin Hong, Jing Ren, Jian Chen, Chao Liu, and Yining Hua. Browsecomp-zh: Benchmarking web browsing ability of large language models in chinese, 2025
work page 2025
-
[58]
Terry Yue Zhuo, Vu Minh Chien, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, Simon Brunner, Chen GONG, James Hoang, Armel Randy Zebaze, Xiaoheng Hong, Wen-Ding Li, Jean Kaddour, Ming Xu, Zhihan Zhang, Prateek Yadav, Naman Jain, Alex Gu, Zhoujun Cheng, Jiawei Liu, Qian Liu, Zijian Wang, Davi...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.