RankJudge: A Multi-Turn LLM-as-a-Judge Synthetic Benchmark Generator
Pith reviewed 2026-05-22 08:47 UTC · model grok-4.3
The pith
RankJudge generates paired multi-turn conversations differing by one injected flaw to give LLM judges an unambiguous correctness signal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By injecting exactly one flaw into one turn of an otherwise identical conversation pair grounded in a reference document, RankJudge produces labeled examples that isolate specific failure categories and enable unambiguous better/worse judgments for LLM-as-a-judge evaluation.
What carries the argument
The RankJudge synthetic benchmark generator that creates conversation pairs differing by a single flaw in one turn.
If this is right
- Frontier LLM judges can be ranked by how often they correctly identify the flawless conversation in each pair.
- Difficulty ratings derived from the same pairs allow dynamic selection of evaluation subsets with reduced label noise.
- Judge rankings stay consistent under partial conversation visibility and under coarser or alternative scoring rules.
- The same construction supports precise diagnosis of which error types individual judges fail to detect.
Where Pith is reading between the lines
- The generator could be extended to inject multiple interacting flaws or to simulate longer conversation histories.
- Developers could use the per-turn isolation to create targeted training data that improves judges on specific weaknesses.
- The approach might generalize to non-document-grounded conversations if reference material can be replaced by verifiable external facts.
Load-bearing premise
Injecting a single flaw into one turn produces pairs that are unambiguously better or worse without creating other unintended differences that would confuse the label.
What would settle it
Human annotators systematically disagree on which conversation is better in a large fraction of the generated pairs.
Figures














read the original abstract
As interactive LLM-based applications are created and refined, model developers need to evaluate the quality of generated text along many possible axes. For simpler systems, human evaluation may be practical, but in complicated systems like conversational chatbots, the amount of generated text can overwhelm human annotation resources. Model developers have begun to rely heavily on auto-evaluation, where LLMs are also used to judge generation quality. However, existing LLM-as-a-judge benchmarks largely focus on simple Q\&A tasks that do not match the complexity of multi-turn conversations. We introduce RankJudge, a benchmark generator for evaluating LLM-as-a-judge on multi-turn conversations grounded in reference documents. RankJudge creates pairs of conversations where one conversation has a single flaw injected into one turn. This construction allows paired conversations to be labeled unambiguously as better or worse, and precisely isolates failure categories to individual turns, enabling a strict joint correctness criterion for judging. We implement RankJudge across the domains of machine learning, biomedicine, and finance, evaluate 21 frontier LLM judges, and rank those judges via the Bradley-Terry model. Our formulation also allows ranking each conversation pair with difficulty ratings, which we use to dynamically curate the evaluation slice to reduce label noise, as confirmed via human annotation. We find that judge rankings are stable under partial observability, coarser correctness criteria, and an alternative random-walk rating algorithm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RankJudge, a benchmark generator for evaluating LLM-as-a-judge on multi-turn conversations grounded in reference documents. It creates pairs of conversations differing by a single flaw injected into one turn, enabling unambiguous better/worse labels and precise isolation of failure categories to individual turns for a strict joint correctness criterion. The method is implemented across machine learning, biomedicine, and finance domains; 21 frontier LLM judges are evaluated and ranked via the Bradley-Terry model. Difficulty ratings allow dynamic curation of evaluation slices to reduce label noise (confirmed by human annotation), and judge rankings are reported as stable under partial observability, coarser correctness criteria, and an alternative random-walk rating algorithm.
Significance. If the single-flaw construction reliably isolates quality differences, RankJudge offers a scalable, low-cost way to benchmark judges on complex conversational tasks where human evaluation is impractical. Strengths include the use of Bradley-Terry ranking, human validation of the curation process, explicit stability tests across multiple conditions, and domain-specific implementations. This directly addresses the gap in existing LLM-judge benchmarks that focus primarily on single-turn Q&A.
major comments (2)
- [§3 (RankJudge Construction)] §3 (RankJudge Construction): The central claim that single-flaw injection into one turn produces pairs that can be labeled unambiguously as better or worse, while isolating failure categories, assumes the injected flaw remains the sole source of quality difference without being masked, compensated, or compounded by surrounding turns or the reference document. No post-injection consistency checks, turn-isolation metrics, or verification that context does not alter the net quality delta are described, which is load-bearing for the strict joint correctness criterion.
- [§5 (Evaluation Protocols)] §5 (Evaluation Protocols): The exact prompting templates and decision rules used to apply the joint correctness criterion when scoring judge outputs on the paired conversations are not specified in sufficient detail to reproduce the isolation of failure categories or to confirm that multi-turn context effects do not undermine the labeling.
minor comments (2)
- [§4.3] The description of how difficulty ratings are computed from the Bradley-Terry model and then used for dynamic curation could be expanded with a short pseudocode or equation for clarity.
- [Table 1] Table 1 (domain statistics) would benefit from an additional column reporting the number of unique reference documents per domain to help readers assess diversity.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for identifying areas where additional detail would strengthen the manuscript. We address each major comment below with clarifications based on the existing construction and indicate revisions that will be incorporated.
read point-by-point responses
-
Referee: [§3 (RankJudge Construction)] §3 (RankJudge Construction): The central claim that single-flaw injection into one turn produces pairs that can be labeled unambiguously as better or worse, while isolating failure categories, assumes the injected flaw remains the sole source of quality difference without being masked, compensated, or compounded by surrounding turns or the reference document. No post-injection consistency checks, turn-isolation metrics, or verification that context does not alter the net quality delta are described, which is load-bearing for the strict joint correctness criterion.
Authors: The RankJudge construction generates each pair from an identical reference document and base conversation, modifying only a single targeted turn in one member of the pair with a flaw drawn from a predefined category. This design ensures that any quality difference is localized to that turn by construction. We acknowledge that explicit post-injection verification steps were not detailed in the initial submission. In the revision we will add a dedicated subsection describing sampling-based consistency checks (including human review of a subset of pairs) to confirm that surrounding context does not mask or compound the injected flaw, thereby reinforcing the foundation for the strict joint correctness criterion. revision: yes
-
Referee: [§5 (Evaluation Protocols)] §5 (Evaluation Protocols): The exact prompting templates and decision rules used to apply the joint correctness criterion when scoring judge outputs on the paired conversations are not specified in sufficient detail to reproduce the isolation of failure categories or to confirm that multi-turn context effects do not undermine the labeling.
Authors: We agree that full reproducibility requires the precise prompting templates and decision rules. Section 5 presents the joint correctness criterion at the conceptual level, but the concrete implementation details were omitted. In the revised manuscript we will append the complete judge prompts (including how the paired conversations and reference document are formatted) and the exact decision rules for applying the joint correctness criterion, explicitly addressing how multi-turn context is handled during scoring. revision: yes
Circularity Check
No significant circularity in RankJudge benchmark construction
full rationale
The paper introduces RankJudge as an explicit synthetic benchmark generator that creates conversation pairs by injecting a single flaw into one turn of a reference-grounded multi-turn dialogue. This construction is presented as an external process for producing labeled data rather than a derivation from fitted parameters, self-referential equations, or self-citation chains. The subsequent ranking of LLM judges via the standard Bradley-Terry model is applied to the generated pairs without any reduction of the central claims back to the inputs by definition. No load-bearing uniqueness theorems, ansatzes smuggled via prior work, or renamings of known results appear in the described approach; the method remains self-contained with independent content from the flaw-injection mechanism itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Injecting a single flaw into one turn creates pairs that can be labeled unambiguously as better or worse while isolating failure categories
Reference graph
Works this paper leans on
-
[1]
Judg- ing LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph Gonzalez, and Ion Stoica. Judg- ing LLM-as-a-Judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems, volume 36, pages 46595–46623, 2023
work page 2023
-
[2]
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference. InProceedings of the 41st International Conference on Machine Learning, 2024
work page 2024
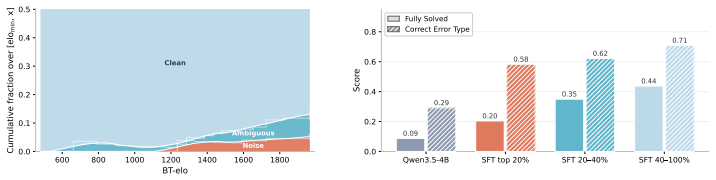
-
[3]
Mert Cemri, Melissa Z Pan, Shuyi Yang, Lakshya A Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. Why Do Multi-Agent LLM Systems Fail? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
work page 2025
-
[4]
LLMs Get Lost In Multi-Turn Conversation
Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. LLMs Get Lost In Multi-Turn Conversation.arXiv:2505.06120, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring Massive Multitask Language Understanding. InInternational Conference on Learning Representations, 2021
work page 2021
-
[6]
Pervasive label errors in test sets destabilize machine learning benchmarks
Curtis G Northcutt, Anish Athalye, and Jonas Mueller. Pervasive label errors in test sets destabilize machine learning benchmarks. InAdvances in Neural Information Processing Systems, volume 34, 2021
work page 2021
-
[7]
Aryo Pradipta Gema, Joshua Ong Jun Leang, Giwon Hong, Alessio Devoto, Alberto Carlo Maria Mancino, Rohit Saxena, Xuanli He, Yu Zhao, Xiaotang Du, Mohammad Reza Ghasemi Madani, et al. Are we done with MMLU? InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologi...
work page 2025
-
[8]
EIP: Weighted ranking of LLMs by quantifying question difficulty
Xingjian Hu, Ziqian Zhang, Yue Huang, Kai Zhang, Ruoxi Chen, Yixin Liu, Qingsong Wen, Kaidi Xu, Xiangliang Zhang, Neil Zhenqiang Gong, and Lichao Sun. EIP: Weighted ranking of LLMs by quantifying question difficulty. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[9]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
MINT: Evaluating LLMs in Multi-turn Interaction with Tools and Language Feedback
Xingyao Wang, Zihan Wang, Jiateng Liu, Yangyi Chen, Lifan Yuan, Hao Peng, and Heng Ji. MINT: Evaluating LLMs in Multi-turn Interaction with Tools and Language Feedback. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[11]
Kaustubh Deshpande, Ved Sirdeshmukh, Johannes Baptist Mols, Lifeng Jin, Ed-Yeremai Hernandez-Cardona, Dean Lee, Jeremy Kritz, Willow E Primack, Summer Yue, and Chen Xing. Multichallenge: A realistic multi-turn conversation evaluation benchmark challenging to frontier LLMs. InFindings of the Association for Computational Linguistics: ACL 2025, pages 18632–...
work page 2025
-
[12]
MT-Eval: A multi-turn capabilities evaluation benchmark for large language models
Wai-Chung Kwan, Xingshan Zeng, Yuxin Jiang, Yufei Wang, Liangyou Li, Lifeng Shang, Xin Jiang, Qun Liu, and Kam-Fai Wong. MT-Eval: A multi-turn capabilities evaluation benchmark for large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 20153–20177, 2024
work page 2024
-
[13]
Hal- luHard: A Hard Multi-Turn Hallucination Benchmark.arXiv:2602.01031, 2026
Dongyang Fan, Sebastien Delsad, Nicolas Flammarion, and Maksym Andriushchenko. Hal- luHard: A Hard Multi-Turn Hallucination Benchmark.arXiv:2602.01031, 2026
-
[14]
Jacob Eisenstein, Fantine Huot, Adam Fisch, Jonathan Berant, and Mirella Lapata. MT-PingEval: Evaluating Multi-Turn Collaboration with Private Information Games.arXiv:2602.24188, 2026. 11
-
[15]
Beyond Single-Turn: A Survey on Multi-Turn Interactions with Large Language Models
Yubo Li, Xiaobin Shen, Xinyu Yao, Xueying Ding, Yidi Miao, Ramayya Krishnan, and Rema Padman. Beyond single-turn: A survey on multi-turn interactions with large language models. arXiv:2504.04717, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedbac...
work page 2022
-
[17]
Deep reinforcement learning from human preferences
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems, volume 30, 2017
work page 2017
-
[18]
Learning to summarize with human feedback
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. InAdvances in Neural Information Processing Systems, volume 33, pages 3008–3021, 2020
work page 2020
-
[19]
Ask a Strong LLM Judge when Your Reward Model is Uncertain
Zhenghao Xu, Qin Lu, Qingru Zhang, Liang Qiu, Ilgee Hong, Changlong Yu, Wenlin Yao, Yao Liu, Haoming Jiang, Lihong Li, Hyokun Yun, and Tuo Zhao. Ask a Strong LLM Judge when Your Reward Model is Uncertain. InAdvances in Neural Information Processing Systems, volume 38, pages 74639–74664, 2025
work page 2025
-
[20]
Is ChatGPT a Good NLG Evaluator? A Preliminary Study
Jiaan Wang, Yunlong Liang, Fandong Meng, Zengkui Sun, Haoxiang Shi, Zhixu Li, Jinan Xu, Jianfeng Qu, and Jie Zhou. Is ChatGPT a Good NLG Evaluator? A Preliminary Study. In Proceedings of the 4th New Frontiers in Summarization Workshop, pages 1–11. Association for Computational Linguistics, 2023
work page 2023
-
[21]
G- Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G- Eval: NLG Evaluation using GPT-4 with Better Human Alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511–2522. Association for Computational Linguistics, 2023
work page 2023
-
[22]
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Ren Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, and Sushant Prakash. RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback. InProceed- ings of the 41st International Conference on Machine Learning, volume 235 ofProceedings o...
work page 2024
-
[23]
Prometheus: Inducing fine-grained evaluation capability in language models
Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, and Minjoon Seo. Prometheus: Inducing fine-grained evaluation capability in language models. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[24]
Learning to Plan & Reason for Evaluation with Thinking-LLM-as-a-Judge
Swarnadeep Saha, Xian Li, Marjan Ghazvininejad, Jason E Weston, and Tianlu Wang. Learning to Plan & Reason for Evaluation with Thinking-LLM-as-a-Judge. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 52565–52583, 2025
work page 2025
-
[25]
WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct
Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Jian-Guang Lou, Chongyang Tao, Xiubo Geng, Qingwei Lin, Shifeng Chen, Yansong Tang, and Dongmei Zhang. WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[26]
MLLM-as-a-Judge: Assessing Multimodal LLM-as-a-Judge with Vision-Language Benchmark
Dongping Chen, Ruoxi Chen, Shilin Zhang, Yaochen Wang, Yinuo Liu, Huichi Zhou, Qihui Zhang, Yao Wan, Pan Zhou, and Lichao Sun. MLLM-as-a-Judge: Assessing Multimodal LLM-as-a-Judge with Vision-Language Benchmark. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 6562–6595, 2024
work page 2024
-
[27]
Yutong Wang, Pengliang Ji, Chaoqun Yang, Kaixin Li, Ming Hu, Jiaoyang Li, and Guil- laume Sartoretti. MCTS-Judge: Test-Time Scaling in LLM-as-a-Judge for Code Correctness Evaluation.arXiv:2502.12468, 2025. 12
-
[28]
J1: Incentivizing thinking in LLM-as-a-judge via reinforcement learning
Chenxi Whitehouse, Tianlu Wang, Ping Yu, Xian Li, Jason E Weston, Ilia Kulikov, and Swarnadeep Saha. J1: Incentivizing thinking in LLM-as-a-judge via reinforcement learning. In The Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[29]
RM-R1: Reward Modeling as Reasoning
Xiusi Chen, Gaotang Li, Ziqi Wang, Bowen Jin, Cheng Qian, Yu Wang, Hongru Wang, Yu Zhang, Denghui Zhang, Tong Zhang, Hanghang Tong, and Heng Ji. RM-R1: Reward Modeling as Reasoning. InThe Fourteenth International Conference on Learning Representa- tions, 2026
work page 2026
-
[30]
Evaluat- ing large language models at evaluating instruction following
Zhiyuan Zeng, Jiatong Yu, Tianyu Gao, Yu Meng, Tanya Goyal, and Danqi Chen. Evaluat- ing large language models at evaluating instruction following. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[31]
JudgeBench: A Benchmark for Evaluating LLM- Based Judges
Sijun Tan, Siyuan Zhuang, Kyle Montgomery, William Yuan Tang, Alejandro Cuadron, Chen- guang Wang, Raluca Popa, and Ion Stoica. JudgeBench: A Benchmark for Evaluating LLM- Based Judges. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[32]
Does context matter? ContextualJudgeBench for evaluating LLM-based judges in contextual settings
Austin Xu, Srijan Bansal, Yifei Ming, Semih Yavuz, and Shafiq Joty. Does context matter? ContextualJudgeBench for evaluating LLM-based judges in contextual settings. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, July 2025
work page 2025
-
[33]
Yicheng Wang, Jiayi Yuan, Yu-Neng Chuang, Zhuoer Wang, Yingchi Liu, Mark Cusick, Param Kulkarni, Zhengping Ji, Yasser Ibrahim, and Xia Hu. DHP benchmark: Are LLMs good NLG evaluators? InFindings of the Association for Computational Linguistics: NAACL 2025. Association for Computational Linguistics, April 2025
work page 2025
-
[34]
ReIFE: Re-evaluating instruction-following evaluation
Yixin Liu, Kejian Shi, Alexander Fabbri, Yilun Zhao, PeiFeng Wang, Chien-Sheng Wu, Shafiq Joty, and Arman Cohan. ReIFE: Re-evaluating instruction-following evaluation. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computa- tional Linguistics: Human Language Technologies (Volume 1: Long Papers). Associat...
work page 2025
-
[35]
JuStRank: Benchmarking LLM judges for system ranking
Ariel Gera, Odellia Boni, Yotam Perlitz, Roy Bar-Haim, Lilach Eden, and Asaf Yehudai. JuStRank: Benchmarking LLM judges for system ranking. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, July 2025
work page 2025
-
[36]
Judge Arena: Benchmarking LLMs as Evaluators, 2024
Kyle Dai, Maurice Burger, Roman Engeler, Max Bartolo, Clémentine Fourrier, Toby Drane, Mathias Leys, and Jake Golden. Judge Arena: Benchmarking LLMs as Evaluators, 2024. Accessed: 2026-05-01
work page 2024
-
[37]
MEDAL: A Framework for Benchmarking LLMs as Multilingual Open-Domain Dialogue Evaluators
John Mendonça, Alon Lavie, and Isabel Trancoso. MEDAL: A Framework for Benchmarking LLMs as Multilingual Open-Domain Dialogue Evaluators. InFindings of the Association for Computational Linguistics: EACL 2026, 2026
work page 2026
-
[38]
MT-Bench-101: A Fine-Grained Benchmark for Evaluating Large Language Models in Multi-Turn Dialogues
Ge Bai, Jie Liu, Xingyuan Bu, Yancheng He, Jiaheng Liu, Zhanhui Zhou, Zhuoran Lin, Wenbo Su, Tiezheng Ge, Bo Zheng, and Wanli Ouyang. MT-Bench-101: A Fine-Grained Benchmark for Evaluating Large Language Models in Multi-Turn Dialogues. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Associa...
work page 2024
-
[39]
Ruiqi Wang, Xinchen Wang, Cuiyun Gao, Chun Yong Chong, Xin Xia, and Qing Liao. AXIOM: Benchmarking LLM-as-a-Judge for Code via Rule-Based Perturbation and Multisource Quality Calibration.arXiv:2512.20159, 2025
-
[40]
Songze Li, Chuokun Xu, Jiaying Wang, Xueluan Gong, Chen Chen, Jirui Zhang, Jun Wang, Kwok-Yan Lam, and Shouling Ji. LLMs Cannot Reliably Judge (Yet?): A Comprehensive Assessment on the Robustness of LLM-as-a-Judge.arXiv:2506.09443, 2025
-
[41]
Judging the judges: A systematic study of position bias in LLM-as-a-judge
Lin Shi, Chiyu Ma, Wenhua Liang, Xingjian Diao, Weicheng Ma, and Soroush V osoughi. Judging the judges: A systematic study of position bias in LLM-as-a-judge. InProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of 13 the Asia-Pacific Chapter of the Association for Computational Linguistics. The As...
work page 2025
-
[42]
Wider and Deeper LLM Networks are Fairer LLM Evaluators.arXiv:2308.01862, 2023
Xinghua Zhang, Bowen Yu, Haiyang Yu, Yangyu Lv, Tingwen Liu, Fei Huang, Hongbo Xu, and Yongbin Li. Wider and Deeper LLM Networks are Fairer LLM Evaluators.arXiv:2308.01862, 2023
-
[43]
Reasoning Gets Harder for LLMs Inside A Dialogue
Ivan Kartáˇc, Mateusz Lango, and Ondˇrej Dušek. Reasoning Gets Harder for LLMs Inside A Dialogue.arXiv:2603.20133, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Google. Gemini 3.1 pro. https://gemini.google.com/, May 2026. Large language model
work page 2026
-
[45]
Kin Kwan Leung, Mouloud Belbahri, Yi Sui, Alex Labach, Xueying Zhang, Stephen Anthony Rose, and Jesse C. Cresswell. Classifying and Addressing the Diversity of Errors in Retrieval- Augmented Generation Systems. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3185–...
work page 2026
-
[46]
HaluEval: A Large- Scale Hallucination Evaluation Benchmark for Large Language Models
Junyi Li, Xiaoxue Cheng, Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. HaluEval: A Large- Scale Hallucination Evaluation Benchmark for Large Language Models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6449–6464. Association for Computational Linguistics, 2023
work page 2023
-
[47]
Aegis: Automated error generation and attribution for multi-agent systems
Fanqi Kong, Ruijie Zhang, Huaxiao Yin, Guibin Zhang, Xiaofei Zhang, Ziang Chen, Zhaowei Zhang, Xiaoyuan Zhang, Song-Chun Zhu, and Xue Feng. Aegis: Automated error generation and attribution for multi-agent systems. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[48]
Self-critiquing models for assisting human evaluators
William Saunders, Catherine Yeh, Jeff Wu, Steven Bills, Long Ouyang, Jonathan Ward, and Jan Leike. Self-critiquing models for assisting human evaluators.arXiv:2206.05802, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[49]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s Verify Step by Step. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[50]
Variable Selection using MM Algorithms.Annals of Statistics, 33(4):1617, 2005
David R Hunter and Runze Li. Variable Selection using MM Algorithms.Annals of Statistics, 33(4):1617, 2005
work page 2005
-
[51]
Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
work page 2026
-
[52]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models. InInternational Conference on Learning Representations, 2022
work page 2022
-
[53]
RPC-Bench: A Fine-grained Benchmark for Research Paper Comprehension
Yelin Chen, Fanjin Zhang, Suping Sun, Yunhe Pang, Yuanchun Wang, Jian Song, Xiaoyan Li, Lei Hou, Shu Zhao, Jie Tang, and Juanzi Li. RPC-Bench: A Fine-grained Benchmark for Research Paper Comprehension.arXiv:2601.14289, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
PubMedQA: A Dataset for Biomedical Research Question Answering
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. PubMedQA: A Dataset for Biomedical Research Question Answering. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Confer- ence on Natural Language Processing (EMNLP-IJCNLP), pages 2567–2577. Association for Computa...
work page 2019
- [55]
- [56]
-
[57]
Think-J: Learning to Think for Generative LLM-as-a-Judge
Hui Huang, Yancheng He, Hongli Zhou, Rui Zhang, Wei Liu, Weixun Wang, Jiaheng Liu, and Wenbo Su. Think-J: Learning to Think for Generative LLM-as-a-Judge. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 31158–31166, 2026. 14
work page 2026
-
[58]
Anthropic. Claude Opus 4.7 System Card. https://www.anthropic.com/system-cards,
-
[59]
Accessed: 2026-05-06
work page 2026
-
[60]
Language models with conformal factuality guarantees
Christopher Mohri and Tatsunori Hashimoto. Language models with conformal factuality guarantees. InProceedings of the 41st International Conference on Machine Learning, 2024
work page 2024
-
[61]
Bruce Kuwahara, Chen-Yuan Lin, Xiao Shi Huang, Kin Kwan Leung, Jullian Yapeter, Ilya Stanevich, Felipe Perez, and Jesse C. Cresswell. Document summarization with conformal importance guarantees. InAdvances in Neural Information Processing Systems, volume 38, pages 67107–67152, 2025
work page 2025
-
[62]
Brendan Leigh Ross, Noël V ouitsis, Atiyeh Ashari Ghomi, Rasa Hosseinzadeh, Ji Xin, Zhaoyan Liu, Yi Sui, Shiyi Hou, Kin Kwan Leung, Gabriel Loaiza-Ganem, and Jesse C. Cresswell. Textual bayes: Quantifying prompt uncertainty in LLM-based systems. InThe Fourteenth International Conference on Learning Representations, 2026. 15 A Additional Results A.1 Detail...
work page 2026
-
[63]
and disorganized (1475) consistently beat judges, while unnecessary_refusal and fabricated_answer (both 849) are the easiest to catch: refusals stand out in context and fab- rications are directly checkable against the grounding document. User behavior, by contrast, barely shifts pair difficulty: the seven categories span only 979 to 1247 in median Elo wi...
work page 2000
-
[64]
Triage by judge-disagreement signal.Open the Overview tab and scan the per-judge accuracy summary. Pairs that nearly all judges miss, or that split close to 50/50 between the two candidate conversations, are the most likely to be mislabelled and are inspected first; pairs on which the ensemble agrees with the declared verdict are quickly skimmed and moved through
-
[65]
Confirm the injected flaw is on-target.On the Plan tab, read plan.bad and verify that the planned weakness is consistent with the declared assistant_behavior_type. The plan is a single narrative paragraph rather than a turn-by-turn script, but it must be specific enough to determine which turn realises the flaw. Hold the planned weakness in mind for the r...
-
[66]
Confirm the bad conversation executes the plan.On the Conversations tab, locate the turn at bad_round_index in convo_b and verify that the assistant response realises the 44 planned weakness, neither a different category nor a milder version. If convo_b exhibits a different assistant_behavior_type than the one declared, or if no turn realises the planned ...
-
[67]
Cross-check using the judge ensemble.Open the Judges tab. If the strongest judges in the registry (gemini-3.1-pro, gpt-5.5, opus-4.7) consistently miss the verdict while several weaker judges (gpt-oss-20b, gemma-4-31b) get it right, treat the pair as suspicious. The strong judges’ reasoning text usually points at a competing flaw inconvo_a, which is the n...
-
[68]
those little indicator things,
Verify the good conversation has no competing flaw.For each strong judge that picked the wrong side: (i) locate the disputed turn in convo_a on the Conversations tab, (ii) retrieve the relevant span from metadata.context (the source document), and (iii) consult an external LLM with a focused fact-check prompt that contains only the disputed turn, the matc...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.