When Cases Get Rare: A Retrieval Benchmark for Off-Guideline Clinical Question Answering
Pith reviewed 2026-05-22 08:25 UTC · model grok-4.3
The pith
Large language models answer only 56% of rare off-guideline clinical questions correctly, but retrieval of medical articles raises accuracy to 82%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
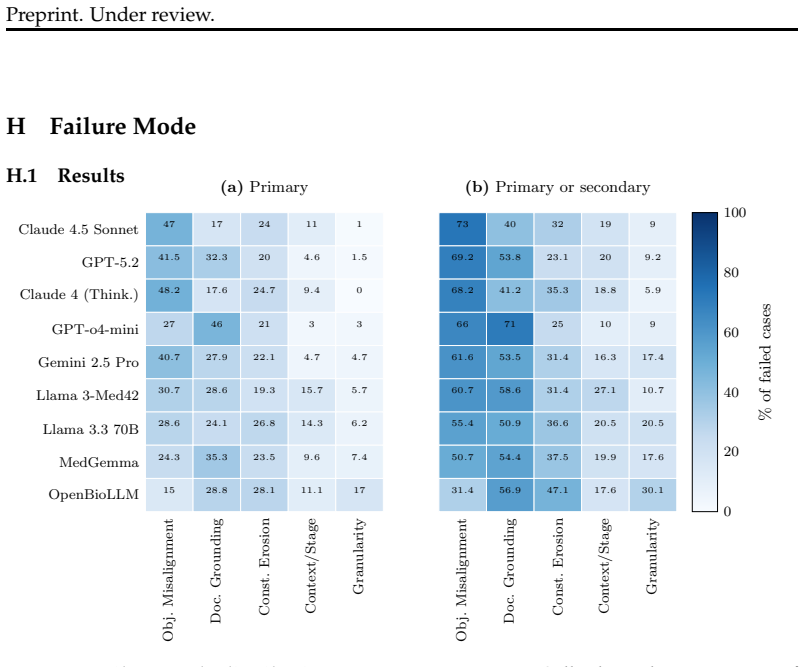
The paper establishes OGCaReBench as a free-form retrieval-focused benchmark built from case reports and expert-validated questions to evaluate LLMs on clinical scenarios not covered by standard guidelines. It reports that the best baseline model correctly answers only 56% of the questions, while augmenting the same models with retrieved medical articles raises performance to as high as 82%, thereby showing the importance of evidence-grounding for open-ended medical reasoning in rare cases.
What carries the argument
OGCaReBench, a benchmark of long-form clinical questions extracted from case reports and validated by medical experts, which tests LLMs on off-guideline scenarios and measures accuracy gains when relevant medical articles are provided as context.
Load-bearing premise
The selected case reports and expert-validated questions accurately represent the long tail of real-world clinical scenarios not covered by guidelines, and that free-text answer correctness can be reliably judged without additional context.
What would settle it
Running the benchmark questions on a model that has been fine-tuned or trained directly on the source case reports and observing whether accuracy stays near 56% without any retrieval step.
Figures



















read the original abstract
Across medical specialties, clinical practice is anchored in evidence-based guidelines that codify best studied diagnostic and treatment pathways. These pathways routinely fall short for the long tail of real-world care not covered by guidelines. Most medical large language models (LLMs), however, are trained to encode common, guideline-focused medical knowledge in their parameters. Current evaluations test models primarily on recalling and reasoning with this memorized content, often in multiple-choice settings. Given the fundamental importance of evidence-based reasoning in medicine, it is neither feasible nor reliable to depend on memorization in practice. To address this gap, we introduce OGCaReBench, a free-form retrieval-focused benchmark aimed at evaluating LLMs at answering clinical questions that require going beyond typical guidelines. Extracted from published medical case reports and validated by medical experts, OGCaReBench contains long-form clinical questions requiring free-text answers, providing a systematic framework for assessing open-ended medical reasoning in rare, case-based scenarios. Our experiments reveal that even the best-performing baseline (GPT-5.2) correctly answers only 56% of our benchmark with specialized models only reaching 42%. Augmenting models with retrieved medical articles improves this performance to up to 82% (using GPT-5.2) highlighting the importance of evidence-grounding for real-world medical reasoning tasks. This work thus establishes a foundation for benchmarking and advancing both general-purpose and medical LLMs to produce reliable answers in challenging clinical contexts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OGCaReBench, a free-form retrieval benchmark for clinical question answering in off-guideline (rare, long-tail) scenarios. Questions are extracted from published medical case reports, expert-validated, and require open-ended free-text answers. Experiments show that even the strongest baseline (GPT-5.2) reaches only 56% correctness, with specialized medical models at 42%; retrieval augmentation raises performance to 82% for GPT-5.2, underscoring the value of evidence-grounding over pure parametric recall.
Significance. If the evaluation protocol is reliable, the benchmark fills a clear gap by moving beyond guideline-centric multiple-choice tests to realistic free-text reasoning on rare cases. The reported retrieval lift (56% to 82%) supplies concrete evidence that external grounding helps in precisely the settings where memorization is least trustworthy. The expert validation step and focus on published case reports are positive features that make the resource potentially reusable for both general and medical LLMs.
major comments (2)
- [Evaluation / Results] Evaluation protocol (abstract and methods): the paper reports free-text correctness numbers (56% baseline, 82% with retrieval) but does not specify whether expert judges scored answers against the isolated question alone or with access to the full source case report (patient history, labs, imaging). In off-guideline scenarios multiple clinically defensible answers often exist; without the surrounding context the delta may partly reflect annotation artifacts rather than genuine evidence-grounding gains. This directly affects interpretability of the central performance claims.
- [Dataset / Benchmark Description] Dataset construction: the claim that the selected case reports represent the 'long tail' of real-world off-guideline care requires more explicit justification. The manuscript should report (a) the total number of questions and case reports, (b) the distribution across medical specialties, and (c) the exact criteria used to confirm that each question is not covered by existing guidelines. These details are load-bearing for the benchmark's claimed novelty and generalizability.
minor comments (2)
- [Experiments] Clarify the exact model identifiers (e.g., is 'GPT-5.2' a typo for a known release or a custom variant?) and list the specialized medical LLMs that achieved 42%.
- [Methods] The retrieval setup (corpus, retriever, number of documents, prompting template) should be described with enough detail for reproducibility; currently only the performance lift is stated.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which helps strengthen the clarity and rigor of our benchmark description and evaluation protocol. We address each major comment below and have made revisions to the manuscript to incorporate the requested details and clarifications.
read point-by-point responses
-
Referee: [Evaluation / Results] Evaluation protocol (abstract and methods): the paper reports free-text correctness numbers (56% baseline, 82% with retrieval) but does not specify whether expert judges scored answers against the isolated question alone or with access to the full source case report (patient history, labs, imaging). In off-guideline scenarios multiple clinically defensible answers often exist; without the surrounding context the delta may partly reflect annotation artifacts rather than genuine evidence-grounding gains. This directly affects interpretability of the central performance claims.
Authors: We appreciate this observation on the evaluation protocol. The expert judges were provided with the full source case reports (including patient history, labs, and imaging) when scoring model answers for clinical correctness. This approach ensures judgments reflect the specific rare presentation in each case report rather than generic question answering. We have expanded the Methods section with a precise description of the judging process, including how multiple defensible answers were handled via expert consensus, to enhance interpretability of the 56% to 82% retrieval lift. revision: yes
-
Referee: [Dataset / Benchmark Description] Dataset construction: the claim that the selected case reports represent the 'long tail' of real-world off-guideline care requires more explicit justification. The manuscript should report (a) the total number of questions and case reports, (b) the distribution across medical specialties, and (c) the exact criteria used to confirm that each question is not covered by existing guidelines. These details are load-bearing for the benchmark's claimed novelty and generalizability.
Authors: We agree these details are necessary to substantiate the benchmark's focus on off-guideline scenarios. The revised manuscript now reports: (a) 312 questions extracted from 245 unique published case reports; (b) specialty distribution with cardiology (28%), oncology (22%), neurology (18%), infectious disease (15%), and the remainder across other fields; (c) off-guideline criteria consisting of a two-stage process—automated search against major society guidelines (AHA, ASCO, etc.) followed by expert review confirming that the specific combination of rare features or atypical presentation is not addressed by any existing guideline recommendation. These additions appear in the Dataset Construction subsection. revision: yes
Circularity Check
Empirical benchmark with no derivation chain or self-citation reduction
full rationale
The paper introduces OGCaReBench by extracting questions from published case reports, expert validation, and direct LLM evaluation (with/without retrieval). No equations, first-principles derivations, fitted parameters, or predictions appear. Central claims rest on measured accuracy deltas (56% to 82%) against external sources rather than any internal construction that reduces to inputs by definition. Self-citations, if present, are not load-bearing for any result. This is a standard self-contained empirical benchmark paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Expert validation of case-report questions produces reliable ground-truth answers for free-text evaluation
- domain assumption Standard automatic or human scoring of free-text medical answers is sufficient to measure correctness
Reference graph
Works this paper leans on
-
[1]
URL http://dx.doi.org/10.1145/3331184.3331303
doi: 10.1145/3331184.3331303. URL http://dx.doi.org/10.1145/3331184.3331303. Xuanzhao Dong, Wenhui Zhu, Hao Wang, Xiwen Chen, Peijie Qiu, Rui Yin, Yi Su, and Yalin Wang. Talk before you retrieve: Agent-led discussions for better rag in medical qa. ArXiv, abs/2504.21252, 2025. URLhttps://api.semanticscholar.org/CorpusID:278208163. Felix J. Dorfner, Amin Da...
-
[2]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
URLhttps://arxiv.org/abs/2104.08663. Augustin Toma, Patrick R. Lawler, Jimmy Ba, Rahul G. Krishnan, Barry B. Rubin, and Bo Wang. Clinical camel: An open expert-level medical language model with dialogue- based knowledge encoding, 2023. URLhttps://arxiv.org/abs/2305.12031. UpToDate. Uptodate: Trusted, evidence-based solutions for modern healthcare. https: ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
URLhttps://arxiv.org/abs/2212.03533. Chaoyi Wu, Weixiong Lin, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Pmc-llama: Towards building open-source language models for medicine, 2023. URL https://arxiv.org/abs/2304.14454. Kevin Wu, Eric Wu, Rahul Thapa, Kevin Wei, Angela Zhang, Arvind Suresh, Jacqueline J. Tao, Min Woo Sun, Alejandro Lozano, and J...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
URLhttps://arxiv.org/abs/2508.10492. Lawrence K. Q. Yan, Qian Niu, Ming Li, Yichao Zhang, Caitlyn Heqi Yin, Cheng Fei, Benji Peng, Ziqian Bi, Pohsun Feng, Keyu Chen, Tianyang Wang, Yunze Wang, Silin Chen, Ming Liu, and Junyu Liu. Large language model benchmarks in medical tasks, 2024. URL https://arxiv.org/abs/2410.21348. W. Zhao, C. Wu, Y. Fan, and et al...
-
[5]
Identify all overlapping content between the detailed and concise queries
-
[6]
You must **preserve** the meaning of all overlapping content exactly yet **mod- ify** the words or expressions. - Keep the core meaning **unchanged**, but vary the surface form: - Use synonyms, abbreviations, or different phrasing. - Do NOT alter the medical intent or expected answer. - Example: ”Management of acute MI”→”Initial treatment of a heart attack”
-
[7]
- Adjust numerical values by adding or subtracting within medically reasonable ranges
Identify the non-overlapping parts of the detailed query: - Use synonyms, abbreviations, or different phrasing. - Adjust numerical values by adding or subtracting within medically reasonable ranges. - Altering the logical flow, sentence structure, or clinical context
-
[8]
Add **extra distracting medical content** that are medically plausible but irrele- vant to the answer: - Comorbidities - Symptoms, tests, and treatments. - Background information. - Past but resolved medical history. - Family history that does not affect the answer. - Redundant or vague phrases. **IMPORTANT:** - The revised detailed query should look **su...
-
[9]
Compare two core medical actions: Extract the core medical action(s) from Gold. Express them as concise medical actions (e.g., “start chemotherapy,” “perform lobectomy,” “order CT scan”). Ignore details such as dose, frequency, or surgical technique/words unless they fundamentally change the type of action. Extract the core medical action(s) from Response...
-
[10]
Compare action, target, and clinical intent
-
[11]
If unsure, default to Mismatch
-
[12]
The output format should be one word: ”Equivalence” or ”Mismatch”. Do not output any other texts. Few-shot examples [Omitted for brevity] Figure 19: GPT-5.2 prompt we used to evaluate the answer and LLM equivalency. The few-shot examples are drawn from early version of the dataset. 32 Preprint. Under review. Instruction for the annotators There are 7 colu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.