Algebraic Machine Learning for Small-to-Medium Datasets Is Competitive against Strong Standard Baselines
Pith reviewed 2026-05-22 08:02 UTC · model grok-4.3
The pith
Algebraic Machine Learning matches or beats cross-validated CNNs and tree methods on small image and tabular datasets without any tuning or validation splits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
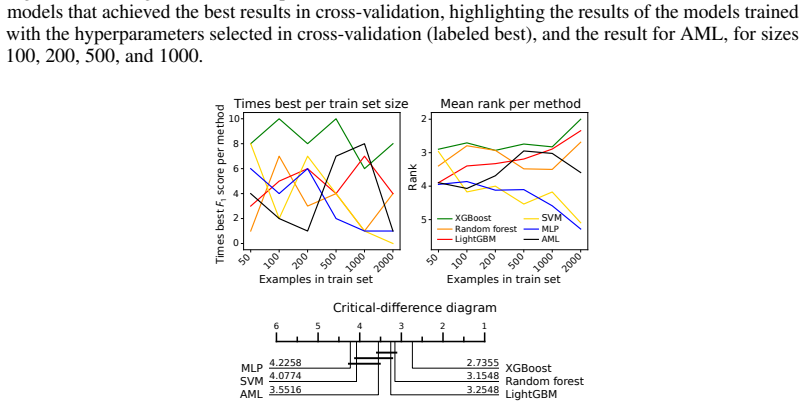
AML trained only on training data without using validation or cross-validation outperforms a family of cross-validated baseline methods including CNNs on small to medium image datasets with 50 to 2000 training examples; on tabular datasets in the same size range AML is comparable to LightGBM and random forests even though XGBoost performs best overall, all achieved with a generic algebraic inductive bias rather than modality-specific biases.
What carries the argument
Subdirect decomposition of algebraic structure, the mechanism AML uses to learn instead of numerical optimization.
If this is right
- The same AML procedure succeeds on two very different data modalities without any modality-specific engineering.
- Skipping cross-validation lets every training example contribute directly to the model rather than being held out for tuning.
- A generic algebraic bias can match the results of methods that embed strong task-specific assumptions such as convolution or gradient boosting.
Where Pith is reading between the lines
- If the algebraic approach continues to work at larger scales it could serve as a low-tuning complement to deep learning in data-scarce settings.
- The result raises the question of whether other algebraic decompositions would show similar robustness across modalities.
- Testing AML on regression or on data types such as sequences would clarify how far the generic bias extends.
Load-bearing premise
The algebraic inductive bias by itself produces competitive performance on both image and tabular data when baselines receive full cross-validation and task-specific tuning.
What would settle it
A new collection of small image datasets on which AML consistently underperforms a cross-validated CNN would disprove the outperformance claim.
Figures





read the original abstract
Symbolic methods are generally not considered competitive with strong modern learners on realistic supervised tasks. We evaluate Algebraic Machine Learning (AML), a framework that learns through subdirect decomposition of algebraic structure rather than numerical optimization, against standard baselines on image and tabular classification across varying training-set sizes. We find that AML trained only on training data without using validation or cross-validation outperforms a family of cross-validated baseline methods including CNNs on small to medium image datasets (50--2000 training examples). On tabular datasets in the same size range, XGBoost is overall the best performing method, but AML is nonetheless comparable to methods incorporating task-specific biases such as LightGBM and random forests. AML achieves this competitive performance across two very different types of datasets using a generic algebraic inductive bias, rather than the modality-specific biases built into standard baselines like CNNs for images or XGBoost for tabular data, and requires no cross validation because it has no task-dependent hyperparameters to tune.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates Algebraic Machine Learning (AML), which learns via subdirect decomposition of algebraic structure, against standard baselines on image and tabular classification tasks with training sets of 50--2000 examples. It reports that AML trained only on the training data (no validation or cross-validation) outperforms cross-validated baselines including CNNs on the image datasets, while on tabular data AML is comparable to LightGBM and random forests even though XGBoost is overall strongest. The central claim is that a generic algebraic inductive bias suffices for competitive performance without modality-specific engineering or hyperparameter tuning.
Significance. If the baseline comparisons are shown to be fair, the result would be significant for low-data supervised learning: it would indicate that an algebraic approach can match or exceed methods that incorporate strong task-specific biases (CNNs for images, tree ensembles for tabular) while requiring no cross-validation. The dual-modality evaluation and the explicit contrast between AML's lack of tunable hyperparameters and the fully cross-validated baselines are strengths that would make the finding relevant beyond a single domain.
major comments (2)
- [Experimental setup] Experimental setup (likely §4 or §5): the CNN baseline implementations must be described in sufficient detail to confirm they constitute strong small-data methods. In particular, the architectures, regularization (e.g., dropout rates, weight decay), data-augmentation policies, and hyperparameter search ranges should be stated explicitly; if the search spaces exclude small-data adaptations such as shallower networks or aggressive augmentation, the reported outperformance on image tasks (50--2000 examples) may reflect under-tuned baselines rather than superiority of the algebraic bias.
- [Results] Results sections (image and tabular tables): the manuscript should report the precise train/validation/test splits used for each dataset, the number of independent runs, and any statistical tests (e.g., paired t-tests or Wilcoxon) for the performance differences. Without these, it is difficult to assess whether the claimed superiority of AML over cross-validated CNNs is robust to split variability or post-selection effects.
minor comments (2)
- [Abstract] Abstract: the phrase 'strong standard baselines' would be clearer if the specific methods (CNN variants, LightGBM, XGBoost, random forests) were named in the abstract itself.
- [Preliminaries] Notation: ensure that 'AML' and the algebraic decomposition operators are defined at first use and used consistently; a short table summarizing the algebraic primitives would aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects of experimental transparency that will strengthen the paper. We address each major comment below and indicate the revisions we plan to incorporate.
read point-by-point responses
-
Referee: [Experimental setup] Experimental setup (likely §4 or §5): the CNN baseline implementations must be described in sufficient detail to confirm they constitute strong small-data methods. In particular, the architectures, regularization (e.g., dropout rates, weight decay), data-augmentation policies, and hyperparameter search ranges should be stated explicitly; if the search spaces exclude small-data adaptations such as shallower networks or aggressive augmentation, the reported outperformance on image tasks (50--2000 examples) may reflect under-tuned baselines rather than superiority of the algebraic bias.
Authors: We agree that explicit details on the CNN baselines are required to demonstrate they are appropriately strong for the small-data setting. In the revised manuscript we will add a new subsection in the experimental setup that fully specifies the CNN architectures (including layer counts, kernel sizes, and activation functions), regularization parameters (exact dropout rates and weight decay values), data-augmentation policies (including the specific transformations and their probabilities), and the complete hyperparameter search grids used for cross-validation. Our original tuning already considered small-data adaptations such as reduced network depth and moderate augmentation; these choices will now be stated explicitly so readers can judge their suitability. revision: yes
-
Referee: [Results] Results sections (image and tabular tables): the manuscript should report the precise train/validation/test splits used for each dataset, the number of independent runs, and any statistical tests (e.g., paired t-tests or Wilcoxon) for the performance differences. Without these, it is difficult to assess whether the claimed superiority of AML over cross-validated CNNs is robust to split variability or post-selection effects.
Authors: We acknowledge that greater precision in reporting splits, run counts, and statistical tests will improve assessment of robustness. The revised results sections will explicitly list the train/validation/test split sizes or indices for every dataset, state that all methods were evaluated over 5 independent runs with distinct random seeds, and include paired t-tests (with p-values) on the per-run accuracies to quantify the significance of differences between AML and the baselines. These additions will directly address concerns about split variability and post-selection effects. revision: yes
Circularity Check
No circularity: empirical claims rest on direct experimental comparisons
full rationale
The paper's central claims consist of empirical performance measurements of AML versus cross-validated baselines on image and tabular datasets of varying sizes. No derivation chain, equations, or fitted parameters are presented that reduce by construction to inputs defined inside the paper itself. The abstract and description emphasize direct out-of-sample evaluation without validation or hyperparameter tuning for AML, contrasted with full cross-validation for baselines; this structure is self-contained against external benchmarks and contains no self-definitional, fitted-input, or self-citation load-bearing steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption AML learns through subdirect decomposition of algebraic structure rather than numerical optimization and requires no task-dependent hyperparameters.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Learning in AML is thus reduced to finding an atomization satisfying the duples... The Sparse Crossing algorithm performs this construction iteratively.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Every algebra admits a subdirect decomposition into irreducible components... atoms... correspond bijectively to the irreducible components
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bishop.Pattern Recognition and Machine Learning (Information Science and Statistics)
Christopher M. Bishop.Pattern Recognition and Machine Learning (Information Science and Statistics). Springer-Verlag, Berlin, Heidelberg, 2006
work page 2006
-
[2]
Ian Goodfellow, Yoshua Bengio, and Aaron Courville.Deep Learning. MIT Press, 2016. http: //www.deeplearningbook.org
work page 2016
-
[3]
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system.Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016
work page 2016
-
[4]
Leo Breiman. Random forests.Mach. Learn., 45(1):5–32, October 2001
work page 2001
-
[5]
Support-vector networks.Machine learning, 20(3):273–297, 1995
Corinna Cortes and Vladimir Vapnik. Support-vector networks.Machine learning, 20(3):273–297, 1995
work page 1995
-
[6]
Allen Newell and Herbert A. Simon. Computer science as empirical inquiry: symbols and search.Commun. ACM, 19(3):113–126, March 1976
work page 1976
-
[7]
Edward A. Feigenbaum. The art of artificial intelligence: Themes and case studies of knowledge engineer- ing. InInternational Joint Conference on Artificial Intelligence, 1977
work page 1977
-
[8]
Frederick Hayes-Roth, Donald A. Waterman, and Douglas B. Lenat.Building expert systems. Addison- Wesley Longman Publishing Co., Inc., USA, 1983
work page 1983
-
[9]
Fernando Martin-Maroto and Gonzalo G. de Polavieja. Algebraic machine learning.arXiv:1803.05252, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
Finite atomized semilattices.arXiv:2102.08050, 2021
Fernando Martin-Maroto and Gonzalo G de Polavieja. Finite atomized semilattices.arXiv:2102.08050, 2021
-
[11]
Semantic embeddings in semilattices
Fernando Martin-Maroto and Gonzalo G de Polavieja. Semantic embeddings in semilattices. arXiv:2205.12618, 2022
- [12]
-
[13]
Lightgbm: a highly efficient gradient boosting decision tree
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: a highly efficient gradient boosting decision tree. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 3149–3157, Red Hook, NY , USA,
-
[14]
Curran Associates Inc
-
[15]
Model-agnostic meta-learning for fast adaptation of deep networks
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. InProceedings of the 34th International Conference on Machine Learning - Volume 70, ICML’17, page 1126–1135. JMLR.org, 2017. 10
work page 2017
-
[16]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InProceedings of the 37th International Conference on Machine Learning, ICML’20. JMLR.org, 2020
work page 2020
-
[17]
Ryan Riegel, Alexander G. Gray, Francois P. S. Luus, Naweed Khan, Ndivhuwo Makondo, Ismail Yunus Akhalwaya, Haifeng Qian, Ronald Fagin, Francisco Barahona, Udit Sharma, Shajith Ikbal, Hima Karanam, Sumit Neelam, Ankita Likhyani, and Santosh K. Srivastava. Logical neural networks.arXiv:2006.13155, 2020
-
[18]
Samy Badreddine, Artur d’Avila Garcez, Luciano Serafini, and Michael Spranger. Logic tensor networks. Artificial Intelligence, 303:103649, 2022
work page 2022
-
[19]
Taco S. Cohen and Max Welling. Group equivariant convolutional networks. InProceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48, ICML’16, page 2990–2999. JMLR.org, 2016
work page 2016
-
[20]
Mathias Drton, Bernd Sturmfels, and Seth Sullivant.Lectures on Algebraic Statistics. Birkhäuser Basel, 2009
work page 2009
-
[21]
Spivak.An Invitation to Applied Category Theory: Seven Sketches in Compositionality
Brendan Fong and David I. Spivak.An Invitation to Applied Category Theory: Seven Sketches in Compositionality. Cambridge University Press, 2019
work page 2019
-
[22]
Fernando Martin-Maroto, Nabil Abderrahaman, David Mendez, and Gonzalo G. de Polavieja. Algebraic machine learning: Learning as computing an algebraic decomposition of a task.arXiv:2502.19944, 2025
-
[23]
Stanley Burris and H. P. Sankappanavar.A course in universal algebra. Springer-Verlag, 1981
work page 1981
-
[24]
B. A. Davey and H. A. Priestley.Introduction to Lattices and Order. Cambridge University Press, 2 edition, 2002
work page 2002
-
[25]
Subdirect products in universal algebra.Bull
Garrett Birkhoff. Subdirect products in universal algebra.Bull. Amer. Math. Soc., 50:764–768, 1944
work page 1944
-
[26]
Mnist handwritten digit database.ATT Labs [Online]
Yann LeCun, Corinna Cortes, and CJ Burges. Mnist handwritten digit database.ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist, 2, 2010
work page 2010
-
[27]
Deep Learning for Classical Japanese Literature
Tarin Clanuwat, Mikel Bober-Irizar, Asanobu Kitamoto, Alex Lamb, Kazuaki Yamamoto, and David Ha. Deep learning for classical japanese literature.arXiv:1812.01718, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Andrea Acevedo, Anna Merino, Santiago Alférez, Ángel Molina, Laura Boldú, and José Rodellar. A dataset of microscopic peripheral blood cell images for development of automatic recognition systems. Data in Brief, 30:105474, 2020
work page 2020
-
[29]
Xuanang Xu, Fugen Zhou, Bo Liu, Dongshan Fu, and Xiangzhi Bai. Efficient multiple organ localization in ct image using 3d region proposal network.IEEE Transactions on Medical Imaging, 38(8):1885–1898, 2019
work page 2019
-
[30]
Kermany, Michael Goldbaum, Wenjia Cai, Carolina C.S
Daniel S. Kermany, Michael Goldbaum, Wenjia Cai, Carolina C.S. Valentim, Huiying Liang, Sally L. Baxter, Alex McKeown, Ge Yang, Xiaokang Wu, Fangbing Yan, Justin Dong, Made K. Prasadha, Jacqueline Pei, Magdalene Y .L. Ting, Jie Zhu, Christina Li, Sierra Hewett, Jason Dong, Ian Ziyar, Alexander Shi, Runze Zhang, Lianghong Zheng, Rui Hou, William Shi, Xin F...
work page 2018
-
[31]
Philipp Tschandl, Cliff Rosendahl, and Harald Kittler. The ham10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions.Scientific Data, 5(1), August 2018
work page 2018
-
[32]
Noel Codella, Veronica Rotemberg, Philipp Tschandl, M. Emre Celebi, Stephen Dusza, David Gutman, Brian Helba, Aadi Kalloo, Konstantinos Liopyris, Michael Marchetti, Harald Kittler, and Allan Halpern. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic).arXiv:1902.03368, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
Medmnist v2–a large-scale lightweight benchmark for 2d and 3d biomedical image classification
Jiancheng Yang, Rui Shi, Donglai Wei, Zequan Liu, Lin Zhao, Bilian Ke, Hanspeter Pfister, and Bingbing Ni. Medmnist v2–a large-scale lightweight benchmark for 2d and 3d biomedical image classification. Scientific Data, 10(1):41, 2023
work page 2023
-
[34]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, 2009. 11
work page 2009
-
[35]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms.arXiv:1708.07747, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
An analysis of single-layer networks in unsupervised feature learning
Adam Coates, Andrew Ng, and Honglak Lee. An analysis of single-layer networks in unsupervised feature learning. InInternational Conference on Artificial Intelligence and Statistics, 2011
work page 2011
-
[37]
Will Cukierski. Aerial cactus identification. https://kaggle.com/competitions/ aerial-cactus-identification, 2019. Kaggle
work page 2019
-
[38]
Efren López-Jiménez, Juan Irving Vasquez-Gomez, Miguel Angel Sanchez-Acevedo, Juan Carlos Herrera- Lozada, and Abril Valeria Uriarte-Arcia. Columnar cactus recognition in aerial images using a deep learning approach.Ecological Informatics, 52:131–138, 2019
work page 2019
-
[39]
Yuval Netzer, Tao Wang, Adam Coates, A. Bissacco, Bo Wu, and A. Ng. Reading digits in natural images with unsupervised feature learning. 2011
work page 2011
- [40]
-
[41]
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, January 2025
work page 2025
-
[42]
Statistical comparisons of classifiers over multiple data sets.J
Janez Demšar. Statistical comparisons of classifiers over multiple data sets.J. Mach. Learn. Res., 7:1–30, December 2006
work page 2006
-
[43]
Alessio Benavoli, Giorgio Corani, and Francesca Mangili. Should we really use post-hoc tests based on mean-ranks?Journal of Machine Learning Research, 17(5):1–10, 2016
work page 2016
-
[44]
Sture Holm. A simple sequentially rejective multiple test procedure.Scandinavian Journal of Statistics, 6(2):65–70, 1979
work page 1979
-
[45]
statistical comparisons of classifiers over multiple data sets
Salvador García and Francisco Herrera. An extension on “statistical comparisons of classifiers over multiple data sets” for all pairwise comparisons.Journal of Machine Learning Research, 9(89):2677–2694, 2008
work page 2008
-
[46]
Wolfe, and Eric Chicken.Nonparametric Statistical Methods
Myles Hollander, Douglas A. Wolfe, and Eric Chicken.Nonparametric Statistical Methods. Wiley, 2015
work page 2015
-
[47]
Springer International Publishing, Cham, 2019
Isabelle Guyon, Lisheng Sun-Hosoya, Marc Boullé, Hugo Jair Escalante, Sergio Escalera, Zhengying Liu, Damir Jajetic, Bisakha Ray, Mehreen Saeed, Michèle Sebag, Alexander Statnikov, Wei-Wei Tu, and Evelyne Viegas.Analysis of the AutoML Challenge Series 2015–2018, pages 177–219. Springer International Publishing, Cham, 2019
work page 2015
-
[48]
Statlog (Australian Credit Approval)
Ross Quinlan. Statlog (Australian Credit Approval). UCI Machine Learning Repository, 1987. DOI: https://doi.org/10.24432/C59012
-
[49]
I-Cheng Yeh, King-Jang Yang, and Tao-Ming Ting. Knowledge discovery on rfm model using bernoulli sequence.Expert Systems with Applications, 36(3, Part 2):5866–5871, 2009
work page 2009
-
[50]
Knowledge acquisition and explanation for multi-attribute decision making
Marko Bohanec and Vladislav Rajkovic. Knowledge acquisition and explanation for multi-attribute decision making. In8th intl workshop on expert systems and their applications, pages 59–78. Avignon France, 1988
work page 1988
-
[51]
Unknown. Churn. OpenML Dataset Repository. OpenML ID: 40701
-
[52]
Tjen-Sien Lim. Contraceptive Method Choice. UCI Machine Learning Repository, 1999. DOI: https://doi.org/10.24432/C59W2D
-
[53]
Hans Hofmann. Statlog (German Credit Data). UCI Machine Learning Repository, 1994. DOI: https://doi.org/10.24432/C5NC77
-
[54]
UCI Machine Learning Repository, 1991
Molecular Biology (Splice-junction Gene Sequences). UCI Machine Learning Repository, 1991. DOI: https://doi.org/10.24432/C5M888
-
[55]
Blake Bulloch. Eucalyptus species selection for soil conservation in seasonally dry hill country - twelfth year assessment.New Zealand journal of forestry science, 21:10–31, 1991
work page 1991
-
[56]
James Bridge, Sean Holden, and Lawrence Paulson. First-order theorem proving. UCI Machine Learning Repository, 2012. DOI: https://doi.org/10.24432/C5RC9X. 12
-
[57]
Renata C. B. Madeo, Clodoaldo A. M. Lima, and Sarajane M. Peres. Gesture unit segmentation using support vector machines: segmenting gestures from rest positions. InProceedings of the 28th Annual ACM Symposium on Applied Computing, SAC ’13, page 46–52, New York, NY , USA, 2013. Association for Computing Machinery
work page 2013
-
[58]
Design of the 2015 chalearn automl challenge
Isabelle Guyon, Kristin Bennett, Gavin Cawley, {Hugo Jair} Escalante, Sergio Escalera, {Tin Kam} Ho, Núria Macià, Bisakha Ray, Mehreen Saeed, Alexander Statnikov, and Evelyne Viegas. Design of the 2015 chalearn automl challenge. In2015 International Joint Conference on Neural Networks, IJCNN 2015, Proceedings of the International Joint Conference on Neura...
work page 2015
-
[59]
Nan Niu and A. Mahmoud. Enhancing candidate link generation for requirements tracing: The cluster hypothesis revisited. InRequirements Engineering Conference (RE), 2012 20th IEEE International, pages 81–90, Sept 2012
work page 2012
-
[60]
Alen Shapiro. Chess (King-Rook vs. King-Pawn). UCI Machine Learning Repository, 1983. DOI: https://doi.org/10.24432/C5DK5C
-
[61]
Robert Duin. Multiple Features. UCI Machine Learning Repository, 1998. DOI: https://doi.org/10.24432/C5HC70
-
[62]
Kun Zhang, Wei Fan, and XiaoJing Yuan. Ozone Level Detection. UCI Machine Learning Repository,
-
[63]
DOI: https://doi.org/10.24432/C5NG6W
-
[64]
T. Menzies and J.S. Di Stefano. How good is your blind spot sampling policy. InHigh Assurance Systems Engineering, 2004. Proceedings. Eighth IEEE International Symposium on, pages 129–138, March 2004
work page 2004
-
[65]
Esprit ii project 5516 roars robust analytic speech recognition system
Pierre Alinat and Jean-Marie Pierrel. Esprit ii project 5516 roars robust analytic speech recognition system. 1994
work page 1994
-
[66]
Kamel Mansouri, Tine Ringsted, Davide Ballabio, Roberto Todeschini, and Viviana Consonni. QSAR biodegradation. UCI Machine Learning Repository, 2013. DOI: https://doi.org/10.24432/C5H60M
-
[67]
Unsupervised Anomaly Detection Benchmark, 2015
Markus Goldstein. Unsupervised Anomaly Detection Benchmark, 2015
work page 2015
-
[68]
UCI Machine Learning Repository, 1990
Image Segmentation. UCI Machine Learning Repository, 1990. DOI: https://doi.org/10.24432/C5GP4N
-
[69]
M Buscema, S Terzi, and W Tastle. Steel Plates Faults. UCI Machine Learning Repository, 2010. DOI: https://doi.org/10.24432/C5J88N
-
[70]
Vehicle recognition using rule based methods, project report
Jan Paul Siebert. Vehicle recognition using rule based methods, project report. InTuring Institute, Glasgow, 1987
work page 1987
-
[71]
Brian Johnson. Wilt. UCI Machine Learning Repository, 2013. DOI: https://doi.org/10.24432/C5KS4M
-
[72]
Cortez, Antonio Luíz Cerdeira, Fernando Almeida, Telmo Matos, and José Reis
P. Cortez, Antonio Luíz Cerdeira, Fernando Almeida, Telmo Matos, and José Reis. Modeling wine preferences by data mining from physicochemical properties.Decis. Support Syst., 47:547–553, 2009
work page 2009
-
[73]
Kenta Nakai. Yeast. UCI Machine Learning Repository, 1991. DOI: https://doi.org/10.24432/C5KG68. 13 A Datasets characteristics Table 3 contains the characteristics of the analyzed image datasets. The train/validation/test splits are irrelevant for our purposes as we only take examples from the train dataset. All datasets are provided under a license allow...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.