Balancing Uncertainty and Diversity of Samples: Leveraging Diversity of Least, High Confidence Samples for Effective Active Learning
Pith reviewed 2026-05-22 06:37 UTC · model grok-4.3
The pith
A hybrid active learning method selecting both uncertain and diverse samples improves model performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
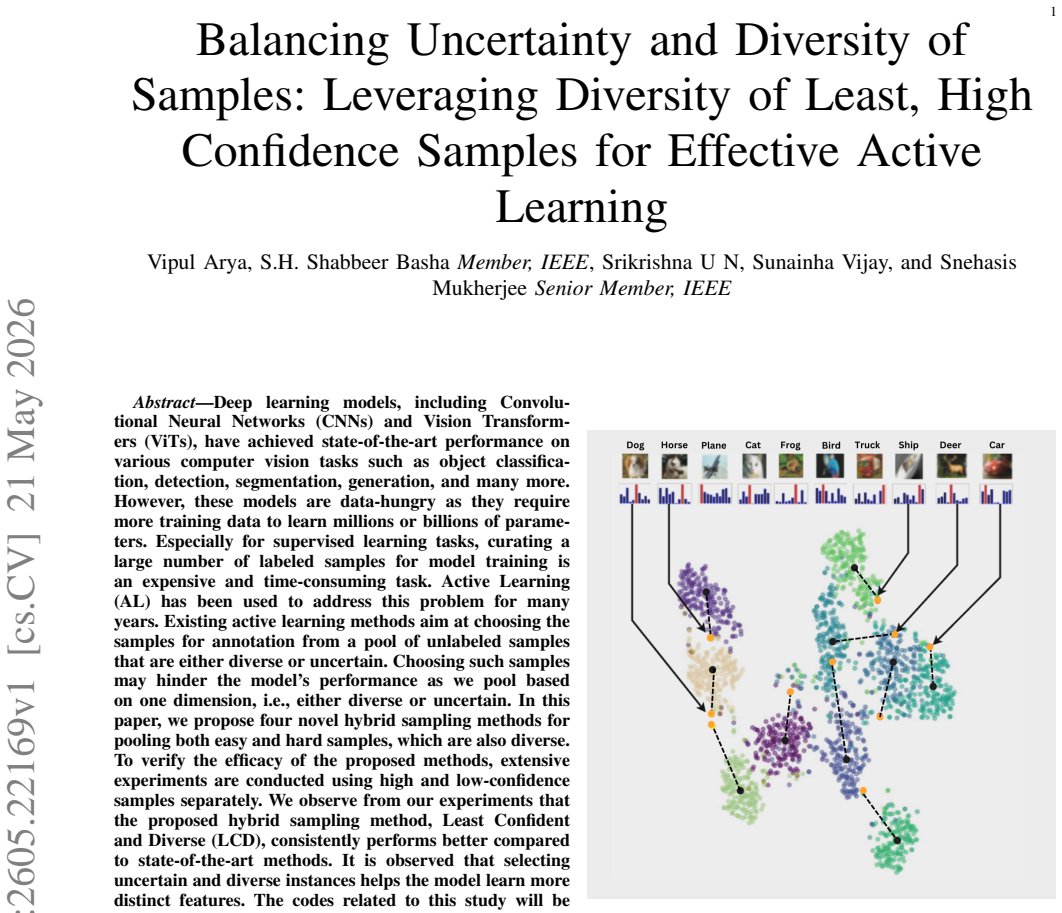
The Least Confident and Diverse (LCD) hybrid sampling method, which selects instances that are both low-confidence and diverse, consistently outperforms state-of-the-art active learning baselines. Selecting uncertain and diverse instances helps the model learn more distinct features from the unlabeled pool.
What carries the argument
The LCD method, which first identifies least-confident samples and then applies a diversity filter to form balanced batches for annotation.
If this is right
- Models acquire more distinct visual features when trained on the hybrid-selected samples.
- Hybrid selection avoids the performance limits seen when using only diversity or only uncertainty.
- The gains appear across CNN and Vision Transformer architectures.
- Fewer total labels are needed to reach target accuracy levels.
Where Pith is reading between the lines
- The same balancing idea could be tested on non-image tasks such as text classification to check broader applicability.
- Incorporating LCD into iterative training loops might further reduce total labeling rounds required.
- Examining failure cases on highly imbalanced or noisy data pools would clarify when the hybrid rule breaks down.
Load-bearing premise
That separate tests on high-confidence and low-confidence samples alone suffice to confirm how the hybrid methods behave on realistic mixed unlabeled pools during full training.
What would settle it
On a benchmark such as CIFAR-10 or ImageNet, if LCD-selected batches produce no higher final accuracy than standard uncertainty or diversity baselines after the same number of labels, the performance advantage claim would be falsified.
Figures



read the original abstract
Deep learning models, including Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), have achieved state-of-the-art performance on various computer vision tasks such as object classification, detection, segmentation, generation, and many more. However, these models are data-hungry as they require more training data to learn millions or billions of parameters. Especially for supervised learning tasks, curating a large number of labeled samples for model training is an expensive and time-consuming task. Active Learning (AL) has been used to address this problem for many years. Existing active learning methods aim at choosing the samples for annotation from a pool of unlabeled samples that are either diverse or uncertain. Choosing such samples may hinder the model's performance as we pool based on one dimension, i.e., either diverse or uncertain. In this paper, we propose four novel hybrid sampling methods for pooling both easy and hard samples, which are also diverse. To verify the efficacy of the proposed methods, extensive experiments are conducted using high and low-confidence samples separately. We observe from our experiments that the proposed hybrid sampling method, Least Confident and Diverse (LCD), consistently performs better compared to state-of-the-art methods. It is observed that selecting uncertain and diverse instances helps the model learn more distinct features. The codes related to this study will be available at https://github.com/XXX/LCD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes four novel hybrid active learning sampling methods for computer vision tasks that combine uncertainty sampling (least confident or high confidence) with diversity to select both easy and hard samples from unlabeled pools. The central claim is that the Least Confident and Diverse (LCD) hybrid method consistently outperforms state-of-the-art approaches, as shown in experiments conducted separately on high- and low-confidence samples, with the observation that selecting uncertain and diverse instances helps models learn more distinct features.
Significance. If the hybrid balancing mechanism can be shown to work under integrated testing on realistic mixed pools, the methods could provide a practical way to improve labeling efficiency for data-hungry models such as CNNs and ViTs. The work targets a known tension in active learning between uncertainty and diversity criteria.
major comments (2)
- [Abstract] Abstract: the claim that LCD 'consistently performs better compared to state-of-the-art methods' is presented without any quantitative metrics, dataset names, baseline implementations, statistical significance tests, or ablation results, preventing evaluation of the reported gains.
- [Abstract] Abstract (and Experiments section): efficacy is verified 'using high and low-confidence samples separately.' This design tests the two criteria in isolation rather than demonstrating that the proposed hybrid scoring function produces balanced batches when applied to a single mixed unlabeled pool containing the full spectrum of model confidences.
minor comments (1)
- [Abstract] Abstract: the GitHub link is listed as https://github.com/XXX/LCD, which is a placeholder and should be replaced with the actual repository URL.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating where we will revise the manuscript to strengthen the presentation and experimental validation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that LCD 'consistently performs better compared to state-of-the-art methods' is presented without any quantitative metrics, dataset names, baseline implementations, statistical significance tests, or ablation results, preventing evaluation of the reported gains.
Authors: We agree that the abstract, as a concise summary, does not include the specific quantitative details mentioned. The Experiments section provides the full results with metrics, dataset names, baseline comparisons (such as uncertainty and diversity sampling methods), and ablation studies supporting the claim for LCD. To address the concern and facilitate evaluation, we will revise the abstract to incorporate key quantitative gains and references to the supporting experimental details. revision: yes
-
Referee: [Abstract] Abstract (and Experiments section): efficacy is verified 'using high and low-confidence samples separately.' This design tests the two criteria in isolation rather than demonstrating that the proposed hybrid scoring function produces balanced batches when applied to a single mixed unlabeled pool containing the full spectrum of model confidences.
Authors: Our experimental design tested the hybrid methods on high- and low-confidence samples separately to isolate the contributions of the uncertainty and diversity components and observe their combined effect in controlled conditions. We acknowledge that this does not directly show performance on a single mixed pool with the full range of confidences, which would better reflect realistic active learning scenarios. We will add experiments applying the hybrid scoring functions to mixed unlabeled pools in the revised manuscript. revision: yes
Circularity Check
No circularity: purely empirical proposal with no derivation chain
full rationale
The paper proposes four hybrid active-learning sampling strategies (including LCD) and reports that LCD outperforms SOTA in experiments run on separate high-confidence and low-confidence pools. No equations, uniqueness theorems, or self-citations are invoked to derive performance gains; the claims rest on direct empirical comparison. Because the work contains no load-bearing derivation that reduces outputs to inputs by construction, it is self-contained and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Uncertainty and diversity are complementary dimensions whose combination yields superior sample selection
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose four novel hybrid sampling methods for pooling both easy and hard samples, which are also diverse... LCD... selects the instances at which the model is very uncertain, and they are also diverse... KMeans clustering... Euclidean distance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Contextual diversity for active learning
Sharat Agarwal, Himanshu Arora, Saket Anand, and Chetan Arora. Contextual diversity for active learning. InEuropean Conference on Computer Vision, pages 137–153. Springer, 2020
work page 2020
-
[2]
Identifying wrongly predicted samples: A method for active learning
Rahaf Aljundi, Nikolay Chumerin, and Daniel Olmeda Reino. Identifying wrongly predicted samples: A method for active learning. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2290–2298, 2022
work page 2022
-
[3]
Queries and concept learning.Machine learning, 2:319–342, 1988
Dana Angluin. Queries and concept learning.Machine learning, 2:319–342, 1988
work page 1988
-
[4]
Nathan Beck, Durga Sivasubramanian, Apurva Dani, Ganesh Ramakrishnan, and Rishabh Iyer. Effective evaluation of deep active learning on image classification tasks.arXiv preprint arXiv:2106.15324, 2021
-
[5]
Class-balanced active learning for image classification
Javad Zolfaghari Bengar, Joost van de Weijer, Laura Lopez Fuentes, and Bogdan Raducanu. Class-balanced active learning for image classification. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1536–1545, 2022
work page 2022
-
[6]
Reducing label effort: Self- supervised meets active learning, 2021
Javad Zolfaghari Bengar, Joost van de Weijer, Bartlomiej Twar- dowski, and Bogdan Raducanu. Reducing label effort: Self- supervised meets active learning, 2021
work page 2021
-
[7]
Safa Bouguezzi, Hana Ben Fredj, Tarek Belabed, Carlos Valder- rama, Hassene Faiedh, and Chokri Souani. An efficient fpga-based convolutional neural network for classification: Ad- mobilenet.Electronics, 10(18):2272, 2021
work page 2021
-
[8]
Feature-fused ssd: Fast detection for small objects
Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, and Jinjian Wu. Feature-fused ssd: Fast detection for small objects. InNinth international conference on graphic and image processing (ICGIP 2017), volume 10615, pages 381–388. SPIE, 2018. 10
work page 2017
-
[9]
Se- quential graph convolutional network for active learning
Razvan Caramalau, Binod Bhattarai, and Tae-Kyun Kim. Se- quential graph convolutional network for active learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9583–9592, 2021
work page 2021
-
[10]
Quality diversity for visual pre-training
Ruchika Chavhan, Henry Gouk, Da Li, and Timothy Hospedales. Quality diversity for visual pre-training. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5384–5394, 2023
work page 2023
-
[11]
Jian Chen, Yuan Gao, Gaoyang Liu, Ahmed M Abdelmoniem, and Chen Wang. Manipulating pre-trained encoder for targeted poisoning attacks in contrastive learning.IEEE Transactions on Information Forensics and Security, 19:2412–2424, 2024
work page 2024
-
[12]
” bnn-bn=?”: Training binary neural networks without batch normalization
Tianlong Chen, Zhenyu Zhang, Xu Ouyang, Zechun Liu, Zhiqiang Shen, and Zhangyang Wang. ” bnn-bn=?”: Training binary neural networks without batch normalization. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4619–4629, 2021
work page 2021
-
[13]
Active learning for deep object detection via probabilistic modeling
Jiwoong Choi, Ismail Elezi, Hyuk-Jae Lee, Clement Farabet, and Jose M Alvarez. Active learning for deep object detection via probabilistic modeling. InProceedings of the IEEE/CVF interna- tional conference on computer vision, pages 10264–10273, 2021
work page 2021
-
[14]
Improving gener- alization with active learning.Machine Learning, 15(2):201–221, 1994
David A Cohn, Les Atlas, and Richard Ladner. Improving gener- alization with active learning.Machine Learning, 15(2):201–221, 1994
work page 1994
-
[15]
Selection via proxy: Efficient data selection for deep learning
C Coleman, C Yeh, S Mussmann, B Mirzasoleiman, P Bailis, P Liang, J Leskovec, and M Zaharia. Selection via proxy: Efficient data selection for deep learning. InInternational Conference on Learning Representations (ICLR), 2020
work page 2020
-
[16]
Ana Paula G. S. de Almeida and Flavio de Barros Vidal. Turning old models fashion again: Recycling classical cnn networks using the lattice transformation, 2021
work page 2021
-
[17]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recogni- tion, pages 248–255. Ieee, 2009
work page 2009
-
[18]
Ensemble methods in machine learning
Thomas G Dietterich. Ensemble methods in machine learning. InInternational workshop on multiple classifier systems, pages 1–15. Springer, 2000
work page 2000
-
[19]
Rasha A Dihin, Ebtesam N Al Shemmary, and Waleed A Mah- moud Al-Jawher. Implementation of the swin transformer and its application in image classification.Journal Port Science Research, 6(4):318–331, 2023
work page 2023
-
[20]
Michael Dodds, Jeff Guo, Thomas L ¨ohr, Alessandro Tibo, Ola Engkvist, and Jon Paul Janet. Sample efficient reinforcement learning with active learning for molecular design.Chemical Science, 15(11):4146–4160, 2024
work page 2024
-
[21]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa De- hghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recog- nition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[22]
Semi-supervised learning on a budget: scaling up to large datasets
Sandra Ebert, Mario Fritz, and Bernt Schiele. Semi-supervised learning on a budget: scaling up to large datasets. InAsian Conference on Computer Vision, pages 232–245. Springer, 2012
work page 2012
-
[23]
Deep bayesian active learning with image data
Yarin Gal, Riashat Islam, and Zoubin Ghahramani. Deep bayesian active learning with image data. InProc. 34th Int. Conf. Mach. Learn., pages 1183–1192, 2017
work page 2017
-
[24]
Consistency-based semi-supervised active learning: Towards minimizing labeling cost
Mingfei Gao, Zizhao Zhang, Guo Yu, Sercan ¨O Arık, Larry S Davis, and Tomas Pfister. Consistency-based semi-supervised active learning: Towards minimizing labeling cost. InEuropean Conference on Computer Vision, pages 510–526. Springer, 2020
work page 2020
-
[25]
Deep active learning for biased datasets via fisher kernel self-supervision
Denis Gudovskiy, Alec Hodgkinson, Takuya Yamaguchi, and Sotaro Tsukizawa. Deep active learning for biased datasets via fisher kernel self-supervision. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9041–9049, 2020
work page 2020
-
[26]
Yuhong Guo and Dale Schuurmans. Discriminative batch mode active learning.Advances in neural information processing systems, 20, 2007
work page 2007
-
[27]
Escaping the big data paradigm with compact transformers, 2022
Ali Hassani, Steven Walton, Nikhil Shah, Abulikemu Abuduweili, Jiachen Li, and Humphrey Shi. Escaping the big data paradigm with compact transformers, 2022
work page 2022
-
[28]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[29]
Deal: Deep evidential active learning for image classification
Patrick Hemmer, Niklas K ¨uhl, and Jakob Sch ¨offer. Deal: Deep evidential active learning for image classification. InDeep Learning Applications, Volume 3, pages 171–192. Springer, 2021
work page 2021
-
[30]
Batch mode active learning and its application to medical image classification
Steven CH Hoi, Rong Jin, Jianke Zhu, and Michael R Lyu. Batch mode active learning and its application to medical image classification. InProc. 23rd Int. Conf. Mach. Learn., pages 417– 424, 2006
work page 2006
-
[31]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neu- ral networks for mobile vision applications.arXiv preprint arXiv:1704.04861, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Densely connected convolutional networks
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4700–4708, 2017
work page 2017
-
[33]
Semi-supervised active learning with temporal output discrepancy
Siyu Huang, Tianyang Wang, Haoyi Xiong, Jun Huan, and Dejing Dou. Semi-supervised active learning with temporal output discrepancy. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3447–3456, 2021
work page 2021
-
[34]
Akshay Jain, Shiv Ram Dubey, Satish Kumar Singh, KC Santosh, and Bidyut Baran Chaudhuri. Non-uniform illumination attack for fooling convolutional neural networks.IEEE Transactions on Artificial Intelligence, 2025
work page 2025
-
[35]
Randomness is the root of all evil: more reliable evaluation of deep active learning
Yilin Ji, Daniel Kaestner, Oliver Wirth, and Christian Wressneg- ger. Randomness is the root of all evil: more reliable evaluation of deep active learning. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 3943–3952, 2023
work page 2023
-
[36]
Army of thieves: Enhancing black-box model extraction via en- semble based sample selection
Akshit Jindal, Vikram Goyal, Saket Anand, and Chetan Arora. Army of thieves: Enhancing black-box model extraction via en- semble based sample selection. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 3823–3832, 2024
work page 2024
-
[37]
Regression tree- based active learning.Data Mining and Knowledge Discovery, 38(2):420–460, 2024
Ashna Jose, Jo ˜ao Paulo Almeida de Mendonc ¸a, Emilie Devijver, No¨el Jakse, Val´erie Monbet, and Roberta Poloni. Regression tree- based active learning.Data Mining and Knowledge Discovery, 38(2):420–460, 2024
work page 2024
-
[38]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
work page 2009
-
[39]
Punit Kumar and Atul Gupta. Active learning query strategies for classification, regression, and clustering: A survey.Journal of Computer Science and Technology, 35(4):913–945, 2020
work page 2020
-
[40]
Budgeted semi-supervised support vector machine
Trung Le, Phuong Duong, Mi Dinh, Tu Dinh Nguyen, Vu Nguyen, and Dinh Phung. Budgeted semi-supervised support vector machine. InConference in Uncertainty in Artificial Intelligence 2016, pages 377–386. AUAI Press, 2016
work page 2016
-
[41]
Training deep spiking neural networks, 2020
Eimantas Ledinauskas, Julius Ruseckas, Alfonsas Jur ˇs˙enas, and Giedrius Bura ˇcas. Training deep spiking neural networks, 2020
work page 2020
-
[42]
A sequential algorithm for training text classifiers
David D Lewis and William A Gale. A sequential algorithm for training text classifiers. InProc. 17th Annu. Int. ACM SIGIR Conf. Res. Develop. Inf. Retrieval, pages 3–12, 1994
work page 1994
-
[43]
Mingkun Li and Ishwar K Sethi. Confidence-based active learning.IEEE transactions on pattern analysis and machine intelligence, 28(8):1251–1261, 2006
work page 2006
- [44]
-
[45]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll ´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InCom- puter Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014. 11
work page 2014
-
[46]
Jiaying Liu, Wenhan Yang, Shuai Yang, and Zongming Guo. D3r- net: Dynamic routing residue recurrent network for video rain removal.IEEE Transactions on Image Processing, 28(2):699– 712, 2018
work page 2018
-
[47]
Influence selection for active learning
Zhuoming Liu, Hao Ding, Huaping Zhong, Weijia Li, Jifeng Dai, and Conghui He. Influence selection for active learning. InProceedings of the IEEE/CVF international conference on computer vision, pages 9274–9283, 2021
work page 2021
-
[48]
Swin transformer: Hierar- chical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierar- chical vision transformer using shifted windows. InProceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021
work page 2021
-
[49]
Fully con- volutional networks for semantic segmentation
Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully con- volutional networks for semantic segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3431–3440, 2015
work page 2015
-
[50]
Some methods for classification and analysis of multivariate observations
James MacQueen et al. Some methods for classification and analysis of multivariate observations. InProceedings of the fifth Berkeley symposium on mathematical statistics and probability, volume 1, pages 281–297. Oakland, CA, USA, 1967
work page 1967
-
[51]
Employing em and pool- based active learning for text classification
Andrew McCallum and Kamal Nigam. Employing em and pool- based active learning for text classification. InProc. 15th Int. Conf. Mach. Learn., pages 350–358, 1998
work page 1998
-
[52]
Robert Munro Monarch.Human-in-the-Loop Machine Learning: Active learning and annotation for human-centered AI. Simon and Schuster, 2021
work page 2021
-
[53]
Reading digits in natural images with unsupervised feature learning
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Baolin Wu, Andrew Y Ng, et al. Reading digits in natural images with unsupervised feature learning. InNIPS workshop on deep learning and unsupervised feature learning, volume 2011, page 4. Granada, 2011
work page 2011
-
[54]
Vu-Linh Nguyen, Mohammad Hossein Shaker, and Eyke H¨ullermeier. How to measure uncertainty in uncertainty sampling for active learning.Machine Learning, 111(1):89–122, 2022
work page 2022
-
[55]
Mesa: A memory-saving training framework for transformers, 2022
Zizheng Pan, Peng Chen, Haoyu He, Jing Liu, Jianfei Cai, and Bohan Zhuang. Mesa: A memory-saving training framework for transformers, 2022
work page 2022
-
[56]
Convergence of uncertainty sam- pling for active learning
Anant Raj and Francis Bach. Convergence of uncertainty sam- pling for active learning. InInternational conference on machine learning, pages 18310–18331. PMLR, 2022
work page 2022
-
[57]
Efficacy of bayesian neu- ral networks in active learning
Vineeth Rakesh and Swayambhoo Jain. Efficacy of bayesian neu- ral networks in active learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2601–2609, 2021
work page 2021
-
[58]
Semi-supervised learning with scarce annotations
Sylvestre-Alvise Rebuffi, Sebastien Ehrhardt, Kai Han, Andrea Vedaldi, and Andrew Zisserman. Semi-supervised learning with scarce annotations. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 762–763, 2020
work page 2020
-
[59]
Active learning for convolu- tional neural networks: A core-set approach
Ozan Sener and Silvio Savarese. Active learning for convolu- tional neural networks: A core-set approach. 2018
work page 2018
-
[60]
An analysis of active learning strategies for sequence labeling tasks
Burr Settles and Mark Craven. An analysis of active learning strategies for sequence labeling tasks. InProc. Conf. Empirical Methods in Natural Language Processing, pages 1070–1079, 2008
work page 2008
-
[61]
H Sebastian Seung, Manfred Opper, and Haim Sompolinsky. Query by committee. InProc. 5th Annu. Workshop Comput. Learn. Theory, pages 287–294, 1992
work page 1992
-
[62]
Hsu-Tung Shih and Tian-Sheuan Chang. Zebra: memory band- width reduction for cnn accelerators with zero block regulariza- tion of activation maps. In2020 IEEE international symposium on circuits and systems (ISCAS), pages 1–5. IEEE, 2020
work page 2020
-
[63]
Deep active learning: Unified and principled method for query and training
Changjian Shui, Fan Zhou, Christian Gagn ´e, and Boyu Wang. Deep active learning: Unified and principled method for query and training. InInternational conference on artificial intelligence and statistics, pages 1308–1318. PMLR, 2020
work page 2020
-
[64]
Viewal: Active learning with viewpoint entropy for semantic segmenta- tion
Yawar Siddiqui, Julien Valentin, and Matthias Nießner. Viewal: Active learning with viewpoint entropy for semantic segmenta- tion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9433–9443, 2020
work page 2020
-
[65]
Very deep convolutional networks for large-scale image recognition
K Simonyan and A Zisserman. Very deep convolutional networks for large-scale image recognition. In3rd International Confer- ence on Learning Representations (ICLR 2015). Computational and Biological Learning Society, 2015
work page 2015
-
[66]
Variational adversarial active learning
Samarth Sinha, Sayna Ebrahimi, and Trevor Darrell. Variational adversarial active learning. InProceedings of the IEEE/CVF international conference on computer vision, pages 5972–5981, 2019
work page 2019
-
[67]
Shuang Song, David Berthelot, and Afshin Rostamizadeh. Com- bining mixmatch and active learning for better accuracy with fewer labels.arXiv preprint arXiv:1912.00594, 2019
-
[68]
Dynamic Neural Network Channel Execution for Efficient Training
Simeon E Spasov and Pietro Lio. Dynamic neural net- work channel execution for efficient training.arXiv preprint arXiv:1905.06435, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[69]
Active learning for image classifica- tion: A deep reinforcement learning approach
Le Sun and Yihong Gong. Active learning for image classifica- tion: A deep reinforcement learning approach. In2019 2nd China Symposium on Cognitive Computing and Hybrid Intelligence (CCHI), pages 71–76. IEEE, 2019
work page 2019
-
[70]
Semi-supervised learning via triplet network based active learning
Divyanshu Sundriyal, Soumyadeep Ghosh, Mayank Vatsa, and Richa Singh. Semi-supervised learning via triplet network based active learning. 2021
work page 2021
-
[71]
Support vector machine active learning for image retrieval
Simon Tong and Edward Y Chang. Support vector machine active learning for image retrieval. InProc. 9th ACM Int. Conf. Multimedia, pages 107–118, 2001
work page 2001
-
[72]
Spatial pattern templates for recognition of objects with regular structure
Radim Tyle ˇcek and Radim ˇS´ara. Spatial pattern templates for recognition of objects with regular structure. InGerman conference on pattern recognition, pages 364–374. Springer, 2013
work page 2013
-
[73]
Uncertainty sampling based active learning with diversity constraint by sparse selection
Gaoang Wang, Jenq-Neng Hwang, Craig Rose, and Farron Wal- lace. Uncertainty sampling based active learning with diversity constraint by sparse selection. In2017 IEEE 19th International Workshop on Multimedia Signal Processing (MMSP), pages 1–6. IEEE, 2017
work page 2017
-
[74]
Active learning through label error statistical methods.Knowledge-Based Sys- tems, 189:105140, 2020
Min Wang, Ke Fu, Fan Min, and Xiuyi Jia. Active learning through label error statistical methods.Knowledge-Based Sys- tems, 189:105140, 2020
work page 2020
-
[75]
Ran Wang, Xi-Zhao Wang, Sam Kwong, and Chen Xu. Incor- porating diversity and informativeness in multiple-instance active learning.IEEE transactions on fuzzy systems, 25(6):1460–1475, 2017
work page 2017
-
[76]
Entropy-based active learning for object detection with progressive diversity constraint
Jiaxi Wu, Jiaxin Chen, and Di Huang. Entropy-based active learning for object detection with progressive diversity constraint. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9397–9406, 2022
work page 2022
-
[77]
Yi Yang, Zhigang Ma, Feiping Nie, Xiaojun Chang, and Alexan- der G Hauptmann. Multi-class active learning by uncertainty sampling with diversity maximization.International Journal of Computer Vision, 113:113–127, 2015
work page 2015
-
[78]
A data efficient transformer based on swin transformer.The Visual Computer, 40(4):2589–2598, 2024
Dazhi Yao and Yunxue Shao. A data efficient transformer based on swin transformer.The Visual Computer, 40(4):2589–2598, 2024
work page 2024
-
[79]
Improving bayesian neural networks by adversarial sampling
Jiaru Zhang, Yang Hua, Tao Song, Hao Wang, Zhengui Xue, Ruhui Ma, and Haibing Guan. Improving bayesian neural networks by adversarial sampling. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 10110– 10117, 2022
work page 2022
-
[80]
Zizhao Zhang, Han Zhang, Long Zhao, Ting Chen, Sercan ¨O Arik, and Tomas Pfister. Nested hierarchical transformer: To- wards accurate, data-efficient and interpretable visual under- standing. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 3417–3425, 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.