Reinforced Graph of Thoughts: RL-Driven Adaptive Prompting for LLMs
Pith reviewed 2026-05-22 07:25 UTC · model grok-4.3
The pith
Reinforcement learning can automatically generate task-specific graphs of operations for large language model prompting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Reinforced Graph of Thoughts (RGoT) is an automated approach to the Graph of Thoughts prompting paradigm that leverages reinforcement learning to adaptively generate a graph of operations from a human-defined set. Results indicate that, under certain constraints, it is possible to construct graphs of operations adaptively to the task's complexity in an automated way.
What carries the argument
Reinforced Graph of Thoughts (RGoT), an RL agent that selects and connects operations from the human-defined set to form a graph whose structure varies with the input task.
If this is right
- Graphs of operations no longer require manual redesign for each new problem instance.
- The generated graph structure can change automatically according to detected task complexity.
- Elaborate LLM problem solving becomes feasible without in-depth knowledge of solution paths for every task.
Where Pith is reading between the lines
- The same RL selection process could be tested on other structured prompting formats such as trees or chains to check transferability.
- Experiments that systematically vary the size and coverage of the operation set would clarify the boundary between workable and intractable constraint regimes.
Load-bearing premise
The human-defined set of operations must contain good solutions for the target tasks yet remain small enough for reinforcement learning to explore the space of possible graphs effectively.
What would settle it
On a high-complexity task solvable by a manually designed graph, measure whether the RL agent fails to discover any viable graph or produces solutions whose accuracy falls below that of the static baseline.
Figures




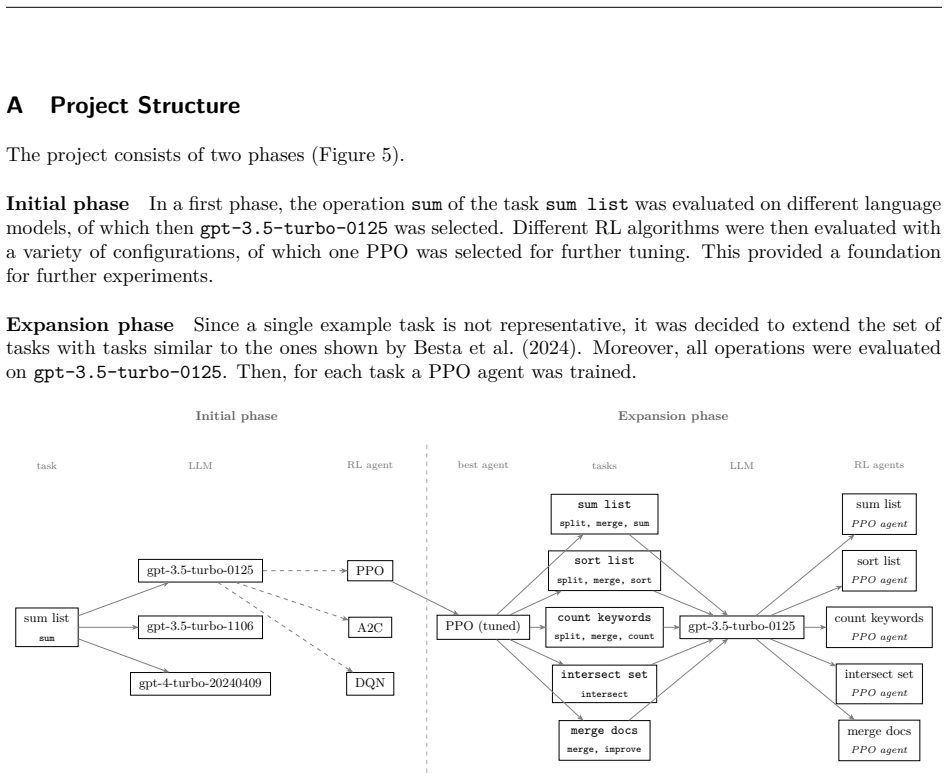











read the original abstract
Graph of Thoughts (GoT), a generalized form of recent prompting paradigms for large language models (LLMs), has been shown to be useful for elaborate problem solving. By executing a graph of operations, thoughts of the LLM are structured as an arbitrary graph, forming the actual graph of thoughts. Originally, the graph of operations is defined manually, which requires in-depth knowledge about the solution of the problem to solve. Such a static graph of operations is rigid and therefore lacks adaptability. We propose Reinforced Graph of Thoughts (RGoT), an automated approach to the GoT prompting paradigm that leverages reinforcement learning (RL) to adaptively generate a graph of operations from a human-defined set. Results indicate that, under certain constraints, it is possible to construct graphs of operations adaptively to the task's complexity in an automated way.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Reinforced Graph of Thoughts (RGoT), which applies reinforcement learning to automatically construct adaptive graphs of operations for LLM prompting, starting from a human-defined set of operations. It claims that under certain constraints this yields graphs tailored to task complexity, overcoming the rigidity of manually specified static graphs in the Graph of Thoughts paradigm.
Significance. If the empirical demonstration holds with proper validation and baselines, the integration of RL for dynamic operation-graph construction could meaningfully reduce the expert knowledge required for effective LLM reasoning on complex tasks and extend structured prompting techniques. The approach directly addresses adaptability limitations in prior GoT work.
major comments (2)
- [Abstract] Abstract: The statement 'Results indicate that, under certain constraints, it is possible to construct graphs of operations adaptively to the task's complexity in an automated way' supplies no quantitative metrics, error bars, baseline comparisons (e.g., to static GoT or other RL-free methods), or description of the RL setup (policy, reward, state representation). This leaves the central empirical claim without visible support.
- [Method] The human-defined operation set is asserted to enable effective RL exploration, yet no characterization of its cardinality, diversity, or task coverage appears; without this, it is impossible to verify that the set is simultaneously rich enough to contain high-quality solutions and compact enough to avoid prohibitive sample complexity, which is load-bearing for the 'certain constraints' qualifier.
minor comments (2)
- [Method] Clarify the precise RL algorithm (e.g., PPO, REINFORCE) and how the graph-construction action space is represented to avoid ambiguity in reproducibility.
- [Experiments] Add a table summarizing the evaluated tasks, operation-set sizes, and key performance deltas versus baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be incorporated to strengthen the presentation of our results and method.
read point-by-point responses
-
Referee: [Abstract] Abstract: The statement 'Results indicate that, under certain constraints, it is possible to construct graphs of operations adaptively to the task's complexity in an automated way' supplies no quantitative metrics, error bars, baseline comparisons (e.g., to static GoT or other RL-free methods), or description of the RL setup (policy, reward, state representation). This leaves the central empirical claim without visible support.
Authors: We agree that the abstract is currently high-level and does not include quantitative metrics, error bars, or explicit details on the RL setup. The full manuscript reports experimental results with baseline comparisons (including static GoT) and describes the RL components (policy gradient optimization with a reward based on task accuracy and graph efficiency) in the Experiments and Method sections. To better support the central claim, we will revise the abstract to include a concise reference to key performance gains and the RL formulation while maintaining length limits. revision: yes
-
Referee: [Method] The human-defined operation set is asserted to enable effective RL exploration, yet no characterization of its cardinality, diversity, or task coverage appears; without this, it is impossible to verify that the set is simultaneously rich enough to contain high-quality solutions and compact enough to avoid prohibitive sample complexity, which is load-bearing for the 'certain constraints' qualifier.
Authors: The referee correctly notes that the manuscript does not characterize the human-defined operation set in terms of cardinality, diversity, or task coverage. We will add this information in the revised Method section, including the number of operations, their coverage of reasoning primitives, and how the set size balances expressiveness against sample complexity to support the 'certain constraints' under which adaptive graph construction is feasible. revision: yes
Circularity Check
No circularity: empirical RL method proposal with no derivations or self-referential reductions
full rationale
The paper introduces RGoT as an RL-based automation of the GoT prompting paradigm, where a human-defined operation set is an explicit external input and the central claim is an empirical observation that adaptive graph construction is possible under certain constraints. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described content. The method is presented as a practical extension relying on standard RL exploration rather than any closed-form reduction to its own inputs, rendering the derivation chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed H. and Le, Quoc V. and Zhou, Denny , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
work page 2024
-
[3]
Advances in Neural Information Processing Systems , author =
Tree of thoughts: Deliberate problem solving with large language models , volume =. Advances in Neural Information Processing Systems , author =
-
[5]
Watkins, Christopher , title =
-
[6]
Reinforcement Learning, Second Edition , isbn =
Sutton, Richard S and Barto, Andrew G , year =. Reinforcement Learning, Second Edition , isbn =
-
[7]
Large Language Models for Mathematical Reasoning: Progresses and Challenges
Ahn, Janice and Verma, Rishu and Lou, Renze and Liu, Di and Zhang, Rui and Yin, Wenpeng. Large Language Models for Mathematical Reasoning: Progresses and Challenges. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: Student Research Workshop. 2024
work page 2024
- [8]
-
[9]
Asynchronous methods for deep reinforcement learning , pages =
Mnih, Volodymyr and Badia, Adria Puigdomenech and Mirza, Mehdi and Graves, Alex and Lillicrap, Timothy and Harley, Tim and Silver, David and Kavukcuoglu, Koray , year =. Asynchronous methods for deep reinforcement learning , pages =. International conference on machine learning , publisher =
-
[10]
Proximal policy optimization algorithms , journal =
Schulman, John and Wolski, Filip and Dhariwal, Prafulla and Radford, Alec and Klimov, Oleg , year =. Proximal policy optimization algorithms , journal =
- [11]
-
[12]
Retrieval-augmented generation for knowledge-intensive NLP tasks , year =
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-augmented generation for knowledge-intensive NLP tasks , year =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
-
[13]
Wiewiora, Eric , editor =. Reward Shaping , isbn =. Encyclopedia of Machine Learning , publisher =. 2010 , doi =
work page 2010
-
[14]
Matsumoto, Makoto and Nishimura, Takuji , title =. 1998 , month = jan, doi =
work page 1998
- [15]
-
[17]
Welcome to Python.org , howpublished =
-
[18]
Gymnasium Documentation , howpublished =
-
[19]
Journal of Machine Learning Research , author =
Stable-Baselines3: Reliable Reinforcement Learning Implementations , volume =. Journal of Machine Learning Research , author =
-
[21]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
work page 2004
-
[22]
Besta, Maciej and Paleari, Lorenzo and Jiang, Jia and Gerstenberger, Robert and Wu, You and Iff, Patrick and Kubicek, Ales and Nyczyk, Piotr and Khimey, Diana and Hannesson, Jón and Kwasniewski, Grzegorz and Copik, Marcin and Niewiadomski, Hubert and Hoefler, Torsten , year =. 2504.02670 , title =
-
[23]
Large language models for mathematical reasoning: Progresses and challenges
Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, and Wenpeng Yin. Large language models for mathematical reasoning: Progresses and challenges. In Neele Falk, Sara Papi, and Mike Zhang (eds.), Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: Student Research Workshop, pp.\ 225--237, St. Juli...
work page 2024
-
[24]
Graph of thoughts: Solving elaborate problems with large language models
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Michał Podstawski, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. Graph of thoughts: Solving elaborate problems with large language models. Proceedings of the AAAI Conference on Artificial Intelligence , 38 0 (16): 0 17682--17690, 2024. d...
-
[25]
Affordable ai assistants with knowledge graph of thoughts, 2025
Maciej Besta, Lorenzo Paleari, Jia Jiang, Robert Gerstenberger, You Wu, Patrick Iff, Ales Kubicek, Piotr Nyczyk, Diana Khimey, Jón Hannesson, Grzegorz Kwasniewski, Marcin Copik, Hubert Niewiadomski, and Torsten Hoefler. Affordable ai assistants with knowledge graph of thoughts, 2025
work page 2025
-
[26]
Gymnasium. Gymnasium documentation. https://gymnasium.farama.org/, 2026. Accessed: Mar. 12, 2026
work page 2026
-
[27]
Auto graph of thoughts: A hands-free and cost effective method for using graph of thoughts
Thien-Loc Ha, Trong-Bao Ho, Long Nguyen, and Dien Dinh. Auto graph of thoughts: A hands-free and cost effective method for using graph of thoughts. In Proceedings of the 2024 10th International Conference on Computer Technology Applications, ICCTA '24, pp.\ 116–121, New York, NY, USA, 2024. Association for Computing Machinery. ISBN 9798400716386. doi:10.1...
-
[28]
John T. Hancock and Taghi M. Khoshgoftaar. Survey on categorical data for neural networks. Journal of Big Data, 7 0 (1): 0 28, 2020. ISSN 2196-1115. doi:10.1186/s40537-020-00305-w. URL https://doi.org/10.1186/s40537-020-00305-w
-
[29]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt\
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K\" u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt\" a schel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks. In Proceedings of the 34th International Conference on Neural Information Processing Systems,...
work page 2020
-
[30]
ROUGE : A package for automatic evaluation of summaries
Chin-Yew Lin. ROUGE : A package for automatic evaluation of summaries. In Text Summarization Branches Out, pp.\ 74--81, Barcelona, Spain, July 2004. Association for Computational Linguistics. URL https://aclanthology.org/W04-1013/
work page 2004
-
[31]
Mersenne Twister: A 6 23-dimensionally equidistributed uniform pseudorandom number generator
Makoto Matsumoto and Takuji Nishimura. Mersenne twister: A 623-dimensionally equidistributed uniform pseudo-random number generator. ACM Transactions on Modeling and Computer Simulation , 8 0 (1): 0 3--30, January 1998. doi:10.1145/272991.272995
-
[32]
Playing Atari with Deep Reinforcement Learning
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin A. Riedmiller. Playing atari with deep reinforcement learning. CoRR , abs/1312.5602, 2013. URL http://arxiv.org/abs/1312.5602
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[33]
Asynchronous methods for deep reinforcement learning
Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. In International conference on machine learning, pp.\ 1928--1937. PMLR , 2016
work page 1928
-
[34]
Melissa E. O'Neill. PCG : A family of simple fast space-efficient statistically good algorithms for random number generation. Technical Report HMC-CS-2014-0905, Harvey Mudd College, Claremont, CA, September 2014
work page 2014
-
[35]
OpenAPI Models. Models - OpenAI API . https://platform.openai.com/docs/models/overview, 2024
work page 2024
-
[36]
Python. Welcome to python.org. https://www.python.org/, 2026. Accessed: Mar. 12, 2026
work page 2026
-
[37]
Stable-baselines3: Reliable reinforcement learning implementations
Antonin Raffin, Ashley Hill, Adam Gleave, Anssi Kanervisto, Maximilian Ernestus, and Noah Dormann. Stable-baselines3: Reliable reinforcement learning implementations. Journal of Machine Learning Research, 22 0 (268): 0 1--8, 2021. URL http://jmlr.org/papers/v22/20-1364.html
work page 2021
-
[38]
John K. Salmon, Mark A. Moraes, Ron O. Dror, and David E. Shaw. Parallel random numbers: as easy as 1, 2, 3. In Proceedings of 2011 International Conference for High Performance Computing, Networking, Storage and Analysis, pp.\ 1--12. ACM , 2011. ISBN 978-1-4503-0771-0. doi:10.1145/2063384.2063405. URL https://dl.acm.org/doi/10.1145/2063384.2063405
-
[39]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv :1707.06347 , 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Developer guide --- Stable Baselines3 2.3.2 documentation
Stable Baselines3. Developer guide --- Stable Baselines3 2.3.2 documentation. https://stable-baselines3.readthedocs.io/en/master/guide/developer.html, 2026. Accessed: Mar. 15, 2026
work page 2026
-
[41]
Reinforcement Learning, Second Edition
Richard S Sutton and Andrew G Barto. Reinforcement Learning, Second Edition. The MIT Press, 2018. ISBN 978-0-262-36401-0
work page 2018
-
[42]
Christopher Watkins. Learning from Delayed Rewards. PhD thesis, King's College, Cambridge, 1989
work page 1989
-
[43]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS '22, Red Hook, NY, USA, 2024. Curran Associates Inc. ISBN 9781713871088
work page 2024
-
[44]
Eric Wiewiora. Reward shaping. In Claude Sammut and Geoffrey I. Webb (eds.), Encyclopedia of Machine Learning, pp.\ 863--865. Springer US , 2010. ISBN 978-0-387-30164-8. doi:10.1007/978-0-387-30164-8_731. URL https://doi.org/10.1007/978-0-387-30164-8_731
-
[45]
Tree of thoughts: Deliberate problem solving with large language models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.