Structure Retention in Embedding Spaces as a Predictor of Benchmark Performance
Pith reviewed 2026-05-22 06:18 UTC · model grok-4.3
The pith
High-performing embedding models keep consistent local structure in their spaces, with nearest-neighbor overlap and ICA magnitude differences correlating up to 0.97 with benchmark scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
High-performing embedding models organize their embedding spaces in a consistent way, and nearest-neighbor overlap together with magnitude differences in independent component analysis between paired text instances strongly correlate with performance on retrieval, bitext mining, pair classification, and summarization tasks.
What carries the argument
nearest-neighbor overlap and magnitude differences in independent component analysis (ICA) between paired text instances
If this is right
- Tasks vary in their degree of linearity and dependence on local structure retention.
- Future training objectives could explicitly reward preservation of nearest-neighbor relations and linear components.
- Model selection or ranking could use structure-retention checks as a cheaper proxy for full benchmark runs.
- Both monolingual and multilingual settings exhibit the same pattern of structure-performance linkage.
Where Pith is reading between the lines
- New loss terms that penalize loss of neighbor overlap during training could improve downstream scores.
- The same metrics might identify which embedding dimensions carry task-relevant information without running the full benchmark.
- If the link holds, conditional embeddings for specific tasks could be optimized by maximizing these retention signals rather than only contrastive loss.
Load-bearing premise
The measured correlations reflect genuine retention of local and linear structure that drives task performance rather than artifacts of model size, data overlap, or the choice of metrics.
What would settle it
Fine-tune or retrain an embedding model to increase nearest-neighbor overlap and ICA magnitude consistency on held-out pairs and then measure whether benchmark scores on the original tasks remain unchanged or drop.
Figures










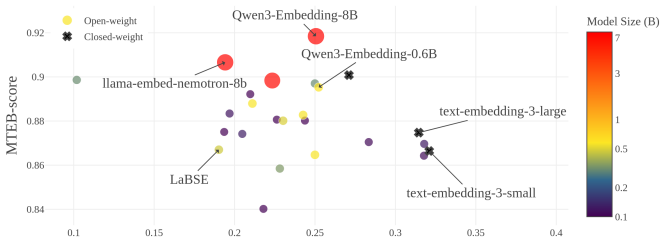

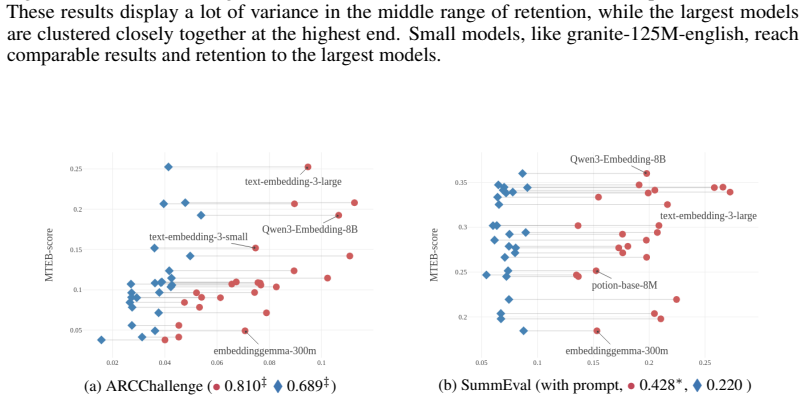
read the original abstract
In this paper, we show that high-performing embedding models organize their embedding spaces in a consistent way. We evaluate 25 contemporary embedding models on five MTEB tasks spanning four diverse task categories (retrieval, bitext mining, pair classification, and summarization) in both English and multilingual settings, and reveal that nearest-neighbor overlap and magnitude differences in independent component analysis (ICA) between paired text instances strongly correlate (even up to 0.97) with performance on the given task. Ultimately, we show that embedding tasks display varying degrees of linearity and reliance on retention of local information. Our results further the understanding of embeddings, their relation to model performance, and shed light on possible future training objectives and optimizing conditional embeddings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates 25 contemporary embedding models on five MTEB tasks spanning retrieval, bitext mining, pair classification, and summarization (English and multilingual). It reports that nearest-neighbor overlap and ICA magnitude differences computed on paired text instances correlate with task performance up to 0.97, and concludes that embedding tasks vary in linearity and reliance on retention of local information, with implications for training objectives.
Significance. A robust demonstration that local structure metrics in embedding spaces predict benchmark performance would advance mechanistic understanding of embedding models and could guide future objectives that explicitly optimize for neighbor preservation or component magnitudes. The scale of the evaluation (25 models, multiple task categories) is a strength if the reported correlations survive controls for capacity and data overlap.
major comments (1)
- [Results] Results section: the reported correlations (up to 0.97) between nearest-neighbor overlap / ICA magnitude differences and MTEB scores are presented without stratification by parameter count, partial correlation controlling for model size, or within-family comparisons. Because larger models typically produce both higher benchmark scores and more locally structured embeddings, the coefficients may be confounded by capacity rather than indicating independent structure retention; this directly undermines the central claim that the metrics predict performance via structure retention.
minor comments (2)
- [Abstract] Abstract and Methods: no mention of multiple-testing correction, pre-specification of metrics, or whether ICA and neighbor metrics were chosen after inspecting results; this detail is needed to assess the reliability of the highest reported correlations.
- [Figures/Tables] Figure captions and tables: axis labels and correlation values should explicitly state whether they are Pearson or Spearman and whether they are computed across all models or per-task.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for highlighting the importance of controlling for model capacity. We agree this is necessary to isolate the contribution of structure retention. In the revised manuscript we have added the requested controls, which leave the core correlations intact. We address the major comment in detail below.
read point-by-point responses
-
Referee: Results section: the reported correlations (up to 0.97) between nearest-neighbor overlap / ICA magnitude differences and MTEB scores are presented without stratification by parameter count, partial correlation controlling for model size, or within-family comparisons. Because larger models typically produce both higher benchmark scores and more locally structured embeddings, the coefficients may be confounded by capacity rather than indicating independent structure retention; this directly undermines the central claim that the metrics predict performance via structure retention.
Authors: We agree that capacity is a plausible confounder and that explicit controls are required. In the revised Results section we now report: (i) correlations stratified by parameter-count bins, (ii) partial correlations between each structure metric and task performance after controlling for log(parameter count), and (iii) within-family comparisons for model families that contain multiple sizes. After these controls the partial correlations remain high (0.82–0.91 across the primary metrics), indicating that nearest-neighbor overlap and ICA magnitude differences retain substantial predictive power beyond capacity. We have updated the abstract, results, and discussion to reflect these additional analyses and to qualify the original claim accordingly. revision: yes
Circularity Check
No significant circularity in empirical correlation analysis
full rationale
The paper computes nearest-neighbor overlap and ICA magnitude differences directly from the embeddings of 25 models on MTEB task instances, then reports their observed correlations (up to 0.97) with separate benchmark performance scores. These metrics are derived from the embedding spaces without any parameter fitting to the target scores, without self-definitional loops, and without load-bearing self-citations that reduce the central claim to prior unverified assertions by the same authors. The derivation chain consists of independent extraction of structure-retention statistics followed by standard correlation computation against external benchmarks; no step equates a prediction to its own input by construction. This is the most common honest outcome for an empirical observational study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Embedding spaces encode semantic relations primarily through local neighborhood structure.
Reference graph
Works this paper leans on
-
[1]
NeurIPS 2025 Workshop on Symmetry and Geometry in Neural Representations , year=
Towards Identification of Latent Structures in Language Embeddings , author=. NeurIPS 2025 Workshop on Symmetry and Geometry in Neural Representations , year=
work page 2025
-
[4]
Exploring Dimensionality Reduction Techniques in Multilingual Transformers
Huertas-García, Álvaro and Martín, Alejandro and Huertas-Tato, Javier and Camacho, David. Exploring Dimensionality Reduction Techniques in Multilingual Transformers. Cognitive Computation
-
[6]
Identifying Interpretable Visual Features in Artificial and Biological Neural Systems , author=. 2023 , eprint=
work page 2023
-
[7]
Pruning Large Language Models by Identifying and Preserving Functional Networks , author=. 2025 , eprint=
work page 2025
-
[8]
Musil, Tom \'a s and Mare c ek, David. Exploring Interpretability of Independent Components of Word Embeddings with Automated Word Intruder Test. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
work page 2024
-
[11]
Independent component analysis , year =
Hyvärinen, Aapo and Karhunen, Juha and Oja, Erkki , address =. Independent component analysis , year =. Independent component analysis , isbn =
-
[12]
Independent component analysis: Algorithms and applica- tions.Neural Networks, 13(4–5):411–430, 2000
Hyvärinen, Aapo and Oja, Erkki , keywords =. Independent component analysis: algorithms and applications , journal =. 2000 , issn =. doi:https://doi.org/10.1016/S0893-6080(00)00026-5 , url =
-
[13]
Fast and robust fixed-point algorithms for independent component analysis , year=
Hyvärinen, Aapo , journal=. Fast and robust fixed-point algorithms for independent component analysis , year=
-
[14]
Scikit-learn: Machine Learning in
Pedregosa, Fabian and Varoquaux, Ga\". Scikit-learn: Machine Learning in. J. Mach. Learn. Res. , month = nov, pages =. 2011 , issue_date =
work page 2011
-
[16]
Zimnik, Andrew J. and Ames, K. Cora and An, Xinyue and Driscoll, Laura and Lara, Antonio H. and Russo, Abigail A. and Susoy, Vladislav and Cunningham, John P. and Paninski, Liam and Churchland, Mark M. and Glaser, Joshua I. , title =. 2024 , doi =. https://www.biorxiv.org/content/early/2024/02/06/2024.02.05.578988.full.pdf , journal =
work page 2024
-
[19]
The Thirteenth International Conference on Learning Representations , year=
Kenneth Enevoldsen and Isaac Chung and Imene Kerboua and M. The Thirteenth International Conference on Learning Representations , year=
-
[20]
Think you have solved question answering?
Clark, Peter and Cowhey, Isaac and Etzioni, Oren and Khot, Tushar and Sabharwal, Ashish and Schoenick, Carissa and Tafjord, Oyvind , journal =. Think you have solved question answering?
-
[21]
RAR-b: Reasoning as Retrieval Benchmark , year =
Xiao, Chenghao and Hudson, G Thomas and Moubayed, Noura Al , journal =. RAR-b: Reasoning as Retrieval Benchmark , year =
- [22]
-
[24]
Tatoeba: Collection of sentences and translations , year =
Tatoeba community. Tatoeba: Collection of sentences and translations , year =
-
[27]
Forty-second International Conference on Machine Learning , year=
Layer by Layer: Uncovering Hidden Representations in Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[28]
The Thirteenth International Conference on Learning Representations , year=
The Geometry of Categorical and Hierarchical Concepts in Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[31]
Sentence- BERT : Sentence Embeddings using Siamese BERT -Networks
Reimers, Nils and Gurevych, Iryna. Sentence- BERT : Sentence Embeddings using Siamese BERT -Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. 2019
work page 2019
-
[32]
Situating Sentence Embedders with Nearest Neighbor Overlap , author=. 2019 , eprint=
work page 2019
-
[33]
Second Conference on Language Modeling , year=
Interpreting the linear structure of vision-language model embedding spaces , author=. Second Conference on Language Modeling , year=
-
[34]
Group information guided ICA for fMRI data analysis , journal =
Yuhui Du and Yong Fan , keywords =. Group information guided ICA for fMRI data analysis , journal =. 2013 , issn =. doi:https://doi.org/10.1016/j.neuroimage.2012.11.008 , url =
-
[35]
Jarno M.A. Tanskanen and Jarno E. Mikkonen and Markku Penttonen , keywords =. Independent component analysis of neural populations from multielectrode field potential measurements , journal =. 2005 , issn =. doi:https://doi.org/10.1016/j.jneumeth.2005.01.004 , url =
-
[36]
Linguistic Regularities in Continuous Space Word Representations
Mikolov, Tomas and Yih, Wen-tau and Zweig, Geoffrey. Linguistic Regularities in Continuous Space Word Representations. Proceedings of the 2013 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies. 2013
work page 2013
- [37]
-
[38]
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. 2023 , eprint=
work page 2023
-
[39]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Park, Kiho and Choe, Yo Joong and Veitch, Victor , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
work page 2024
-
[41]
Transactions on Machine Learning Research , issn=
Finding Neurons in a Haystack: Case Studies with Sparse Probing , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
work page 2023
-
[42]
The Twelfth International Conference on Learning Representations , year=
Language Models Represent Space and Time , author=. The Twelfth International Conference on Learning Representations , year=
- [43]
-
[44]
A Text is Worth Several Tokens: Text Embedding from LLM s Secretly Aligns Well with The Key Tokens
Nie, Zhijie and Zhang, Richong and Wu, Zhanyu. A Text is Worth Several Tokens: Text Embedding from LLM s Secretly Aligns Well with The Key Tokens. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.379
-
[46]
Pitfalls in the Evaluation of Sentence Embeddings
Eger, Steffen and R. Pitfalls in the Evaluation of Sentence Embeddings. Proceedings of the 4th Workshop on Representation Learning for NLP (RepL4NLP-2019). 2019. doi:10.18653/v1/W19-4308
-
[47]
The Limitations of Cross-language Word Embeddings Evaluation
Bakarov, Amir and Suvorov, Roman and Sochenkov, Ilya. The Limitations of Cross-language Word Embeddings Evaluation. Proceedings of the Seventh Joint Conference on Lexical and Computational Semantics. 2018. doi:10.18653/v1/S18-2010
-
[52]
Second Conference on Language Modeling , year=
Shared Global and Local Geometry of Language Model Embeddings , author=. Second Conference on Language Modeling , year=
-
[53]
A Deep Dive into Multi-Head Attention and Multi-Aspect Embedding
Teimouri, Maryam and Kanerva, Jenna and Ginter, Filip. A Deep Dive into Multi-Head Attention and Multi-Aspect Embedding. Proceedings of the 15th International Conference on Recent Advances in Natural Language Processing - Natural Language Processing in the Generative AI Era. 2025
work page 2025
-
[54]
Quantifying Feature Space Universality Across Large Language Models via Sparse Autoencoders , author=. 2025 , eprint=
work page 2025
-
[57]
Proceedings of The 33rd International Conference on Machine Learning , pages =
Unsupervised Deep Embedding for Clustering Analysis , author =. Proceedings of The 33rd International Conference on Machine Learning , pages =. 2016 , editor =
work page 2016
-
[58]
Jianlv Chen and Shitao Xiao and Peitian Zhang and Kun Luo and Defu Lian and Zheng Liu , year=. 2402.03216 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
C-Pack: Packed Resources For General Chinese Embeddings
Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff , year=. C-Pack: Packaged Resources To Advance General. 2309.07597 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Jina Embeddings: A Novel Set of High-Performance Sentence Embedding Models , author=. 2023 , eprint=
work page 2023
-
[61]
Jina Embeddings 2: 8192-Token General-Purpose Text Embeddings for Long Documents , author=. 2023 , eprint=
work page 2023
-
[62]
Wang, Liang and Yang, Nan and Huang, Xiaolong and Yang, Linjun and Majumder, Rangan and Wei, Furu , journal=. Multilingual
-
[65]
Model2Vec: Fast State-of-the-Art Static Embeddings , year =
Stephan Tulkens and. Model2Vec: Fast State-of-the-Art Static Embeddings , year =. doi:10.5281/zenodo.17270888 , url =
- [66]
-
[68]
Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Wen and Dai, Ziqi and Tang, Jialong and Lin, Huan and Yang, Baosong and Xie, Pengjun and Huang, Fei and others , booktitle=
-
[70]
Llama-Embed-Nemotron-8B: A Universal Text Embedding Model for Multilingual and Cross-Lingual Tasks , author=. 2025 , eprint=
work page 2025
-
[71]
Arctic-Embed 2.0: Multilingual Retrieval Without Compromise , author=. 2024 , eprint=
work page 2024
-
[73]
Gemini: A Family of Highly Capable Multimodal Models , author="Gemini. 2025 , eprint=
work page 2025
-
[76]
Towards identification of latent structures in language embeddings
Ryunosuke Abe, Takatomi Kubo, and Kazushi Ikeda. Towards identification of latent structures in language embeddings. In NeurIPS 2025 Workshop on Symmetry and Geometry in Neural Representations, 2025. URL https://openreview.net/forum?id=HgRkUfQSa4
work page 2025
-
[77]
SCDT our: Embedding axis ordering and merging for interpretable semantic change detection
Taichi Aida and Danushka Bollegala. SCDT our: Embedding axis ordering and merging for interpretable semantic change detection. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Findings of the Association for Computational Linguistics: EMNLP 2025, pages 14775--14785, Suzhou, China, November 2025. Association for C...
-
[78]
Granite embedding models, 2025
Parul Awasthy, Aashka Trivedi, Yulong Li, Mihaela Bornea, David Cox, Abraham Daniels, Martin Franz, Gabe Goodhart, Bhavani Iyer, Vishwajeet Kumar, Luis Lastras, Scott McCarley, Rudra Murthy, Vignesh P, Sara Rosenthal, Salim Roukos, Jaydeep Sen, Sukriti Sharma, Avirup Sil, Kate Soule, Arafat Sultan, and Radu Florian. Granite embedding models, 2025. URL htt...
-
[79]
Yauhen Babakhin, Radek Osmulski, Ronay Ak, Gabriel Moreira, Mengyao Xu, Benedikt Schifferer, Bo Liu, and Even Oldridge. Llama-embed-nemotron-8b: A universal text embedding model for multilingual and cross-lingual tasks, 2025. URL https://arxiv.org/abs/2511.07025
-
[80]
Chang, Zhuowen Tu, and Benjamin K
Tyler A. Chang, Zhuowen Tu, and Benjamin K. Bergen. The geometry of multilingual language model representations. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors, Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 119--136, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational L...
-
[81]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. BGE M3 -embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation, 2024
work page 2024
-
[82]
The knowledge microscope: Features as better analytical lenses than neurons
Yuheng Chen, Pengfei Cao, Kang Liu, and Jun Zhao. The knowledge microscope: Features as better analytical lenses than neurons. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10493--10515, Vienna, ...
-
[83]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? T ry ARC , the AI 2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[84]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models, 2023. URL https://arxiv.org/abs/2309.08600
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[85]
Analyzing transformers in embedding space
Guy Dar, Mor Geva, Ankit Gupta, and Jonathan Berant. Analyzing transformers in embedding space. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16124--16170, Toronto, Canada, July 2023. Association for Computational Lingu...
-
[86]
WebFAQ : A multilingual collection of natural Q&A datasets for dense retrieval
Michael Dinzinger, Laura Caspari, Kanishka Ghosh Dastidar, Jelena Mitrovi\' c , and Michael Granitzer. WebFAQ : A multilingual collection of natural Q&A datasets for dense retrieval. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR '25, page 3802–3811, New York, NY, USA, 2025. Associ...
-
[87]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of superposition, 2022. URL https://arxiv.org/abs/2209.10652
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[88]
Kenneth Enevoldsen, Isaac Chung, Imene Kerboua, M \'a rton Kardos, Ashwin Mathur, David Stap, Jay Gala, Wissam Siblini, Dominik Krzemi \'n ski, Genta Indra Winata, Saba Sturua, Saiteja Utpala, Mathieu Ciancone, Marion Schaeffer, Diganta Misra, Shreeya Dhakal, Jonathan Rystr m, Roman Solomatin, \"O mer Veysel C a g atan, Akash Kundu, Martin Bernstorff, Shi...
work page 2025
-
[89]
Fabbri, Wojciech Kry \'s ci \'n ski, Bryan McCann, Caiming Xiong, Richard Socher, and Dragomir Radev
Alexander R. Fabbri, Wojciech Kry \'s ci \'n ski, Bryan McCann, Caiming Xiong, Richard Socher, and Dragomir Radev. S umm E val: Re-evaluating summarization evaluation. Transactions of the Association for Computational Linguistics, 9: 0 391--409, 2021. doi:10.1162/tacl_a_00373. URL https://aclanthology.org/2021.tacl-1.24/
-
[90]
Language-agnostic BERT sentence embedding, 2022
Fangxiaoyu Feng, Yinfei Yang, Daniel Cer, Naveen Arivazhagan, and Wei Wang. Language-agnostic BERT sentence embedding, 2022. URL https://arxiv.org/abs/2007.01852
-
[91]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team. Gemini: A family of highly capable multimodal models, 2025. URL https://arxiv.org/abs/2312.11805
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[92]
The third PASCAL recognizing textual entailment challenge
Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and Bill Dolan. The third PASCAL recognizing textual entailment challenge. In Proceedings of the ACL - PASCAL Workshop on Textual Entailment and Paraphrasing , pages 1--9, Prague, jun 2007. Association for Computational Linguistics. URL https://aclanthology.org/W07-1401
work page 2007
-
[93]
Language models represent space and time
Wes Gurnee and Max Tegmark. Language models represent space and time. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=jE8xbmvFin
work page 2024
-
[94]
Finding neurons in a haystack: Case studies with sparse probing
Wes Gurnee, Neel Nanda, Matthew Pauly, Katherine Harvey, Dmitrii Troitskii, and Dimitris Bertsimas. Finding neurons in a haystack: Case studies with sparse probing. Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=JYs1R9IMJr
work page 2023
-
[95]
Jina embeddings: A novel set of high-performance sentence embedding models, 2023 a
Michael Günther, Louis Milliken, Jonathan Geuter, Georgios Mastrapas, Bo Wang, and Han Xiao. Jina embeddings: A novel set of high-performance sentence embedding models, 2023 a
work page 2023
-
[96]
Jina embeddings 2: 8192-token general-purpose text embeddings for long documents, 2023 b
Michael Günther, Jackmin Ong, Isabelle Mohr, Alaeddine Abdessalem, Tanguy Abel, Mohammad Kalim Akram, Susana Guzman, Georgios Mastrapas, Saba Sturua, Bo Wang, Maximilian Werk, Nan Wang, and Han Xiao. Jina embeddings 2: 8192-token general-purpose text embeddings for long documents, 2023 b
work page 2023
-
[97]
Validating the independent components of neuroimaging time series via clustering and visualization
Johan Himberg, Aapo Hyvärinen, and Fabrizio Esposito. Validating the independent components of neuroimaging time series via clustering and visualization. NeuroImage, 22 0 (3): 0 1214--1222, 2004. ISSN 1053-8119. doi:https://doi.org/10.1016/j.neuroimage.2004.03.027. URL https://www.sciencedirect.com/science/article/pii/S1053811904001661
-
[98]
KaLM - E mbedding: Superior training data brings a stronger embedding model, 2025
Xinshuo Hu, Zifei Shan, Xinping Zhao, Zetian Sun, Zhenyu Liu, Dongfang Li, Shaolin Ye, Xinyuan Wei, Qian Chen, Baotian Hu, Haofen Wang, Jun Yu, and Min Zhang. KaLM - E mbedding: Superior training data brings a stronger embedding model, 2025. URL https://arxiv.org/abs/2501.01028
-
[99]
Embedding-based retrieval in facebook search
Jui-Ting Huang, Ashish Sharma, Shuying Sun, Li Xia, David Zhang, Philip Pronin, Janani Padmanabhan, Giuseppe Ottaviano, and Linjun Yang. Embedding-based retrieval in facebook search. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD '20, page 2553–2561, New York, NY, USA, 2020. Association for Computi...
-
[100]
Exploring dimensionality reduction techniques in multilingual transformers
Álvaro Huertas-García, Alejandro Martín, Javier Huertas-Tato, and David Camacho. Exploring dimensionality reduction techniques in multilingual transformers. Cognitive Computation, 15: 0 590–612, 2023. doi:https://doi.org/10.1007/s12559-022-10066-8
-
[101]
Fast and robust fixed-point algorithms for independent component analysis
Aapo Hyvärinen. Fast and robust fixed-point algorithms for independent component analysis. IEEE Transactions on Neural Networks, 10 0 (3): 0 626--634, 1999. doi:10.1109/72.761722
-
[102]
Quantifying feature space universality across large language models via sparse autoencoders, 2025
Michael Lan, Philip Torr, Austin Meek, Ashkan Khakzar, David Krueger, and Fazl Barez. Quantifying feature space universality across large language models via sparse autoencoders, 2025. URL https://arxiv.org/abs/2410.06981
-
[103]
Shared global and local geometry of language model embeddings
Andrew Lee, Melanie Weber, Fernanda Vi \'e gas, and Martin Wattenberg. Shared global and local geometry of language model embeddings. In Second Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=aJDykpJAYF
work page 2025
-
[104]
Exploring intra and inter-language consistency in embeddings with ICA
Rongzhi Li, Takeru Matsuda, and Hitomi Yanaka. Exploring intra and inter-language consistency in embeddings with ICA . In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 19104--19111, Miami, Florida, USA, November 2024. Association for Computational L...
-
[105]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. Towards general text embeddings with multi-stage contrastive learning. arXiv preprint arXiv:2308.03281, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[106]
Lucy H. Lin and Noah A. Smith. Situating sentence embedders with nearest neighbor overlap, 2019. URL https://arxiv.org/abs/1909.10724
-
[107]
Pruning large language models by identifying and preserving functional networks, 2025
Yiheng Liu, Junhao Ning, Sichen Xia, Xiaohui Gao, Ning Qiang, Bao Ge, Junwei Han, and Xintao Hu. Pruning large language models by identifying and preserving functional networks, 2025. URL https://arxiv.org/abs/2508.05239
-
[108]
How to dissect a M uppet: The structure of transformer embedding spaces
Timothee Mickus, Denis Paperno, and Mathieu Constant. How to dissect a M uppet: The structure of transformer embedding spaces. Transactions of the Association for Computational Linguistics, 10: 0 981--996, 2022. doi:10.1162/tacl_a_00501. URL https://aclanthology.org/2022.tacl-1.57/
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.