Evaluating Commercial AI Chatbots as News Intermediaries
Pith reviewed 2026-05-22 05:22 UTC · model grok-4.3
The pith
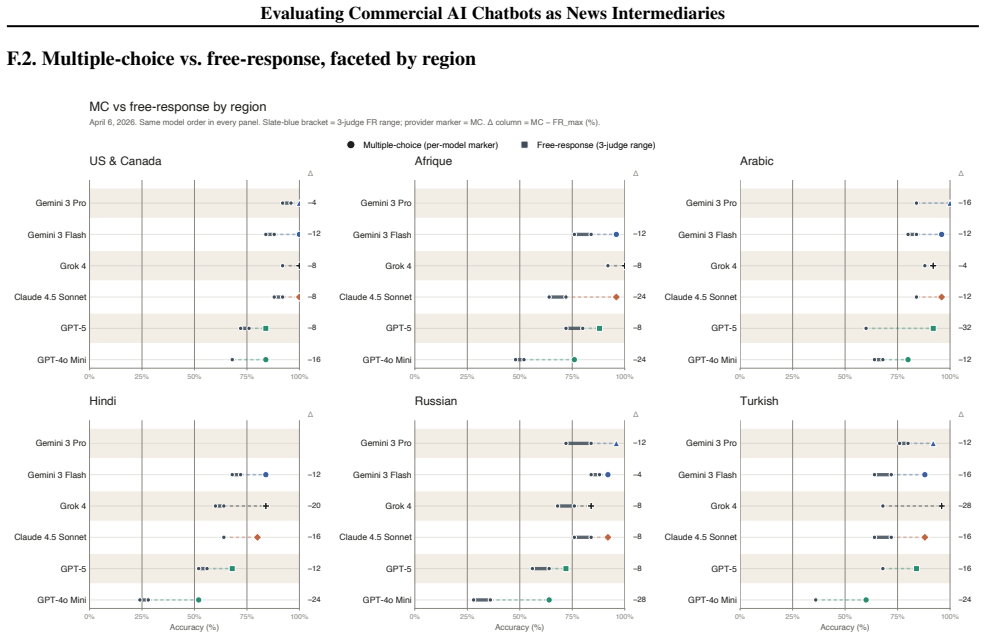
Commercial AI chatbots reach over 90 percent accuracy on multiple-choice questions about news reported hours earlier but lose 11 to 13 percent in free-response settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The best chatbots correctly answer over 90 percent of multiple-choice questions about events reported hours earlier, yet the same systems lose 11-13 percent accuracy under free response and drop further when questions contain subtle false premises. Retrieval failures drive over 70 percent of all errors, and every model shows its lowest accuracy on Hindi queries because of an Anglophone retrieval bias.
What carries the argument
A 14-day benchmark of 2,100 same-day factual questions from six BBC regional news services, scored separately on multiple-choice accuracy, free-response accuracy, and adversarial questions that embed false premises.
If this is right
- High multiple-choice scores do not predict reliable performance when users ask questions in their own words.
- Regional accuracy gaps persist because models retrieve English sources even for non-English queries.
- The main performance limit is locating the right source rather than reasoning over retrieved text.
- Models remain vulnerable to accepting fabricated facts when questions contain subtle false premises.
Where Pith is reading between the lines
- Chatbots may systematically under-serve non-English news audiences even when overall accuracy looks high.
- Improving multilingual retrieval pipelines would address more errors than further gains in reasoning.
- Real-world reliability requires testing on naturally occurring user questions rather than curated clean benchmarks.
Load-bearing premise
That questions derived from BBC News reporting constitute a representative and unbiased sample of real-world factual queries users pose to chatbots.
What would settle it
A field study that logs actual user questions about breaking news events and measures chatbot answer accuracy against the same events reported by primary sources.
Figures













read the original abstract
AI chatbots are rapidly shaping how people encounter the news, yet no prior study has systematically measured how accurately these systems, with their proprietary search integrations and retrieval-synthesis pipelines, handle emerging facts across languages and regions. We present a 14-day (February 9-22, 2026) evaluation of six AI chatbots (Gemini 3 Flash and Pro, Grok 4, Claude 4.5 Sonnet, GPT-5 and GPT-4o mini) on 2,100 factual questions derived from same-day BBC News reporting across six regional services (US & Canada, Arabic, Afrique, Hindi, Russian, Turkish). The best systems achieve over 90% multiple-choice accuracy on questions about events reported hours earlier. The same systems, however, lose 11-13% under free-response evaluation, and 16-17% across the cohort. We further characterize three failure patterns. First, every model achieves its lowest accuracy on Hindi (79% vs. 89-91% elsewhere) and citations indicate an Anglophone retrieval bias (e.g., models answering Hindi queries cite English Wikipedia more than any Hindi outlet). Second, retrieval, not reasoning, failures drive over 70% of all errors. When models retrieve a correct source, they often extract the correct answer; the problem is to land on the right source in the first place. Third, models achieving 88-96% accuracy on well-formed questions drop to 19-70% when questions contain subtle false premises, with the most vulnerable model accepting fabricated facts 64% of the time. We also identify a detection-accuracy paradox: the best false-premise detector ranks second in adversarial accuracy (abstention rate), while a weaker detector ranks first, showing that premise detection and answer recovery are partially independent capabilities. Overall, these suggest that high accuracy can mask systematic regional inequity, near-total dependence on retrieval infrastructure, and vulnerability to imperfect queries real users pose.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a 14-day evaluation (Feb 9-22, 2026) of six commercial AI chatbots on 2,100 factual questions drawn from same-day BBC News across six regional services. Best systems exceed 90% multiple-choice accuracy on recent events but drop 11-17% in free-response; retrieval failures are said to cause >70% of errors, Hindi accuracy is lowest (79%), models are vulnerable to false-premise questions (dropping to 19-70%), and a detection-accuracy paradox is observed.
Significance. If the headline numbers and failure-mode attributions hold, the work supplies large-scale, time-sensitive evidence on the reliability of commercial chatbots as news intermediaries. The multi-language/regional design and emphasis on emerging facts directly address practical deployment questions around accuracy, equity, and robustness to imperfect user queries.
major comments (2)
- [§4 / abstract] §4 (Failure Patterns) and abstract: The central claim that retrieval failures drive over 70% of errors rests on the ability to classify each mistake as retrieval versus reasoning. The manuscript must supply the explicit, pre-specified decision rule or annotation rubric (e.g., citation presence, lexical-overlap threshold, or blinded protocol) used to label errors for proprietary systems whose internal retrieval traces are unavailable. Without this, the 70% figure and the conclusion that 'the problem is to land on the right source' remain sensitive to post-hoc judgment.
- [Methods] Methods section: The 11-13% drop from multiple-choice to free-response accuracy is a key quantitative result, yet the abstract and reported methods provide no detail on exact question generation, inter-annotator agreement, or the scoring rubric for free-response answers. These choices directly affect the reported accuracy figures and must be documented with sufficient specificity for replication.
minor comments (2)
- [Abstract] Abstract: The phrase 'citations indicate an Anglophone retrieval bias' would be strengthened by reporting the actual citation counts or proportions per language rather than a qualitative statement.
- [Results] Results tables: Adding per-model, per-region sample sizes and confidence intervals would clarify whether the Hindi performance gap is statistically distinguishable from other regions.
Simulated Author's Rebuttal
We are grateful to the referee for highlighting areas where our manuscript can be strengthened with additional methodological transparency. We respond to each major comment in turn and commit to revisions that address the concerns raised.
read point-by-point responses
-
Referee: [§4 / abstract] §4 (Failure Patterns) and abstract: The central claim that retrieval failures drive over 70% of errors rests on the ability to classify each mistake as retrieval versus reasoning. The manuscript must supply the explicit, pre-specified decision rule or annotation rubric (e.g., citation presence, lexical-overlap threshold, or blinded protocol) used to label errors for proprietary systems whose internal retrieval traces are unavailable. Without this, the 70% figure and the conclusion that 'the problem is to land on the right source' remain sensitive to post-hoc judgment.
Authors: We thank the referee for this important point. The error classification in our study was based on whether the model's response included a citation or reference to a source that contained the correct factual information from the BBC article. Errors without such supporting citations were attributed to retrieval failures. However, we recognize that an explicit, pre-specified rubric was not detailed in the submitted manuscript. We will add a dedicated subsection in Methods describing the annotation protocol, including criteria for citation presence and lexical overlap with ground truth, along with agreement metrics from blinded annotation of a subset of errors. This will substantiate the >70% figure. revision: yes
-
Referee: [Methods] Methods section: The 11-13% drop from multiple-choice to free-response accuracy is a key quantitative result, yet the abstract and reported methods provide no detail on exact question generation, inter-annotator agreement, or the scoring rubric for free-response answers. These choices directly affect the reported accuracy figures and must be documented with sufficient specificity for replication.
Authors: We agree that more details on the free-response evaluation are needed for replicability. The free-response questions were generated by converting the multiple-choice questions into open-ended versions by removing the options and adjusting the phrasing slightly for naturalness. Scoring was performed by human annotators who judged whether the model's answer correctly addressed the factual query based on the original BBC report, using a binary correct/incorrect with notes for partial matches. We will revise the Methods section to specify the question generation process, provide the scoring rubric with examples, and report inter-annotator agreement. revision: yes
Circularity Check
No circularity: direct empirical measurement against external ground truth
full rationale
The paper performs a straightforward empirical evaluation by generating factual questions from independent BBC News reports and measuring chatbot accuracy on them. There are no equations, fitted parameters, derivations, or self-citations that reduce any claim to the study's own inputs by construction. Accuracy percentages and the 70% retrieval-failure attribution are computed directly from observed model outputs versus BBC-derived ground truth; the error classification is an observational breakdown rather than a mathematical reduction or self-definitional loop. The study is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption BBC News reports in each regional service are accurate and timely factual sources suitable for deriving ground-truth questions.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
retrieval, not reasoning, failures drive over 70% of all errors... When models retrieve a correct source, they often extract the correct answer
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
MEGA : Multilingual evaluation of generative AI
Ahuja, K., Diddee, H., Hada, R., Ochieng, M., Ramesh, K., Jain, P., Nambi, A., Ganu, T., Segal, S., Ahmed, M., Bali, K., and Sitaram, S. MEGA : Multilingual evaluation of generative AI . In Bouamor, H., Pino, J., and Bali, K. (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp.\ 4232--4267, Singapore, Decembe...
-
[2]
Arguedas, A. R. How audiences think about news personalisation in the AI era, June 2025. URL https://reutersinstitute.politics.ox.ac.uk/digital-news-report/2025/how-audiences-think-about-news-personalisation-ai-era
work page 2025
-
[3]
Self-rag: Learning to retrieve, generate, and critique through self-reflection
Asai, A., Wu, Z., Wang, Y., Sil, A., and Hajishirzi, H. Self-rag: Learning to retrieve, generate, and critique through self-reflection. In The Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[4]
Sam Altman says ChatGPT has hit 800M weekly active users
Bellan, R. Sam Altman says ChatGPT has hit 800M weekly active users. OpenAI Dev Day keynote, reported by TechCrunch, October 2025. URL https://techcrunch.com/2025/10/06/sam-altman-says-chatgpt-has-hit-800m-weekly-active-users/
work page 2025
-
[5]
J., Hitzig, Z., Ong, C., Shan, C
Chatterji, A., Cunningham, T., Deming, D. J., Hitzig, Z., Ong, C., Shan, C. Y., and Wadman, K. How People Use ChatGPT . Technical Report w34255, National Bureau of Economic Research, 2025. URL https://www.nber.org/papers/w34255
work page 2025
-
[6]
Sycophantic AI decreases prosocial intentions and promotes dependence , volume =
Cheng, M., Lee, C., Khadpe, P., Yu, S., Han, D., and Jurafsky, D. Sycophantic ai decreases prosocial intentions and promotes dependence. Science, 391 0 (6792): 0 eaec8352, 2026. doi:10.1126/science.aec8352. URL https://www.science.org/doi/abs/10.1126/science.aec8352
-
[7]
Dahl, M., Magesh, V., Suzgun, M., and Ho, D. E. Large legal fictions: Profiling legal hallucinations in large language models. Journal of Legal Analysis, 16 0 (1): 0 64--93, 2024
work page 2024
-
[8]
Daungsupawong, H. and Wiwanitkit, V. Probing artificial intelligence in neurosurgical training: Correspondence. Brain & Spine, 4: 0 102751, 2024
work page 2024
-
[9]
Dzindolet, M. T., Peterson, S. A., Pomranky, R. A., Pierce, L. G., and Beck, H. P. The role of trust in automation reliance. International journal of human-computer studies, 58 0 (6): 0 697--718, 2003
work page 2003
-
[10]
RAGA s: Automated evaluation of retrieval augmented generation
Es, S., James, J., Espinosa Anke, L., and Schockaert, S. RAGA s: Automated evaluation of retrieval augmented generation. In Aletras, N. and De Clercq, O. (eds.), Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, pp.\ 150--158, St. Julians, Malta, March 2024. Association for ...
-
[11]
The information ecosystem is being redrawn by AI
Fang, S. The information ecosystem is being redrawn by AI . That might be good news. Reuters Institute for the Study of Journalism, 2026. URL https://reutersinstitute.politics.ox.ac.uk/news/information-ecosystem-being-redrawn-ai-might-be-good-news
work page 2026
-
[12]
Faverio, M. and Sidoti, O. Teens, social media and AI chatbots 2025, December 2025. URL https://www.pewresearch.org/internet/2025/12/09/teens-social-media-and-ai-chatbots-2025/. Report
work page 2025
-
[13]
Ford, M. and Eisele, I. Fact check: How trustworthy are AI fact checks? Deutsche Welle (DW), May 2025. URL https://www.dw.com/en/fact-check-hey-grok-is-this-true-how-trustworthy-are-ai-fact-checks/a-72539345
work page 2025
-
[14]
Enabling large language models to generate text with citations
Gao, T., Yen, H., Yu, J., and Chen, D. Enabling large language models to generate text with citations. In Bouamor, H., Pino, J., and Bali, K. (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp.\ 6465--6488, Singapore, December 2023. Association for Computational Linguistics. doi:10.18653/v1/2023.emnlp-main.3...
-
[15]
M., Hewitt, L., Saunders, E., Black, S., Lin, H., Fist, C., Margetts, H., Rand, D
Hackenburg, K., Tappin, B. M., Hewitt, L., Saunders, E., Black, S., Lin, H., Fist, C., Margetts, H., Rand, D. G., and Summerfield, C. The levers of political persuasion with conversational artificial intelligence. Science, 390 0 (6777): 0 eaea3884, 2025
work page 2025
-
[16]
Around the world in 24 hours: Probing LLM knowledge of time and place
Holtermann, C., R \"o ttger, P., and Lauscher, A. Around the world in 24 hours: Probing LLM knowledge of time and place. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.), Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 22875--22897, Vienna, Austria, July 2025. Associatio...
-
[17]
Won ' t get fooled again: Answering questions with false premises
Hu, S., Luo, Y., Wang, H., Cheng, X., Liu, Z., and Sun, M. Won ' t get fooled again: Answering questions with false premises. In Rogers, A., Boyd-Graber, J., and Okazaki, N. (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 5626--5643, Toronto, Canada, July 2023. Association for C...
-
[18]
Institute for Public Policy Research (IPPR) . Revealed: ChatGPT draws more on GB News , Al Jazeera , and Marie Claire than the BBC , IPPR analysis shows, January 2026. URL https://www.ippr.org/media-office/revealed-chatgpt-draws-more-on-gb-news-al-jazeera-and-marie-claire-than-the-bbc-ippr-analysis-shows
work page 2026
-
[19]
Ja\' z wi\' n ska, K. and Chandrasekar, A. AI Search Has a Citation Problem . Columbia Journalism Review, 2025. URL https://www.cjr.org/tow_center/we-compared-eight-ai-search-engines-theyre-all-bad-at-citing-news.php
work page 2025
-
[20]
Kasai, J., Sakaguchi, K., yoichi takahashi, Bras, R. L., Asai, A., Yu, X. V., Radev, D., Smith, N. A., Choi, Y., and Inui, K. Realtime QA : What's the answer right now? In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. URL https://openreview.net/forum?id=HfKOIPCvsv
work page 2023
-
[21]
A rabic MMLU : Assessing massive multitask language understanding in A rabic
Koto, F., Li, H., Shatnawi, S., Doughman, J., Sadallah, A., Alraeesi, A., Almubarak, K., Alyafeai, Z., Sengupta, N., Shehata, S., Habash, N., Nakov, P., and Baldwin, T. A rabic MMLU : Assessing massive multitask language understanding in A rabic. In Ku, L.-W., Martins, A., and Srikumar, V. (eds.), Findings of the Association for Computational Linguistics:...
-
[22]
AI platform citation patterns: How ChatGPT , Google AI Overviews , and Perplexity source information
Lafferty, N. AI platform citation patterns: How ChatGPT , Google AI Overviews , and Perplexity source information. Profound, June 2025. URL https://www.tryprofound.com/blog/ai-platform-citation-patterns
work page 2025
-
[23]
D., Ngo, N., Pouran Ben Veyseh, A., Man, H., Dernoncourt, F., Bui, T., and Nguyen, T
Lai, V. D., Ngo, N., Pouran Ben Veyseh, A., Man, H., Dernoncourt, F., Bui, T., and Nguyen, T. H. C hat GPT beyond E nglish: Towards a comprehensive evaluation of large language models in multilingual learning. In Bouamor, H., Pino, J., and Bali, K. (eds.), Findings of the Association for Computational Linguistics: EMNLP 2023, pp.\ 13171--13189, Singapore,...
-
[24]
u ttler, H., Lewis, M., Yih, W.-t., Rockt \
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., K \"u ttler, H., Lewis, M., Yih, W.-t., Rockt \"a schel, T., et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in neural information processing systems, 33: 0 9459--9474, 2020
work page 2020
-
[25]
Li, A. O. and Goyal, T. Memorization vs. reasoning: Updating LLM s with new knowledge. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.), Findings of the Association for Computational Linguistics: ACL 2025, pp.\ 25853--25874, Vienna, Austria, July 2025. Association for Computational Linguistics. ISBN 979-8-89176-256-5. doi:10.18653/v1/2025....
-
[26]
Lin, Q., Li, J., and Ng, H. T. D yna Q uest: A dynamic question answering dataset reflecting real-world knowledge updates. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.), Findings of the Association for Computational Linguistics: ACL 2025, pp.\ 26918--26936, Vienna, Austria, July 2025. Association for Computational Linguistics. ISBN 979-...
-
[27]
URLhttps://doi.org/10.18653/v1/2022.acl-long.229
Lin, S., Hilton, J., and Evans, O. T ruthful QA : Measuring how models mimic human falsehoods. In Muresan, S., Nakov, P., and Villavicencio, A. (eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 3214--3252, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi:1...
-
[28]
Lipka, M. and Eddy, K. Relatively few Americans are getting news from AI chatbots like ChatGPT , October 2025. URL https://www.pewresearch.org/short-reads/2025/10/01/relatively-few-americans-are-getting-news-from-ai-chatbots-like-chatgpt/. Short Reads
work page 2025
-
[29]
Evaluating verifiability in generative search engines
Liu, N., Zhang, T., and Liang, P. Evaluating verifiability in generative search engines. In Bouamor, H., Pino, J., and Bali, K. (eds.), Findings of the Association for Computational Linguistics: EMNLP 2023, pp.\ 7001--7025, Singapore, December 2023. Association for Computational Linguistics. doi:10.18653/v1/2023.findings-emnlp.467. URL https://aclantholog...
-
[30]
Magesh, V., Surani, F., Dahl, M., Suzgun, M., Manning, C. D., and Ho, D. E. Hallucination-free? assessing the reliability of leading ai legal research tools. Journal of empirical legal studies, 22 0 (2): 0 216--242, 2025
work page 2025
-
[31]
Manic, S. S. The ai user-agent landscape in 2026: A complete reference, 2026. URL https://nohacks.co/blog/ai-user-agents-landscape-2026. Published April 13, 2026; accessed May 12, 2026
work page 2026
-
[32]
BBC threatens ai firm over unauthorised content use
McMahon, L. BBC threatens ai firm over unauthorised content use. BBC News , jun 2025. URL https://www.bbc.com/news/articles/cy7ndgylzzmo
work page 2025
-
[33]
Min, S., Krishna, K., Lyu, X., Lewis, M., Yih, W.-t., Koh, P., Iyyer, M., Zettlemoyer, L., and Hajishirzi, H. FA ct S core: Fine-grained atomic evaluation of factual precision in long form text generation. In Bouamor, H., Pino, J., and Bali, K. (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp.\ 12076--1210...
-
[34]
Newman, N., Ross Arguedas, A., Robertson, C. T., Nielsen, R. K., and Fletcher, R. Reuters institute digital news report 2025, 2025. URL https://reutersinstitute.politics.ox.ac.uk/sites/default/files/2025-06/Digital_News-Report_2025.pdf
work page 2025
-
[35]
Orth, T. and Carl, B. Trust in media 2025: Which news sources Americans use and trust, May 2025. URL https://yougov.com/en-us/articles/52272-trust-in-media-2025-which-news-sources-americans-use-and-trust
work page 2025
-
[36]
Ouyang, J., Pan, T., Cheng, M., Yan, R., Luo, Y., Lin, J., and Liu, Q. H o H : A dynamic benchmark for evaluating the impact of outdated information on retrieval-augmented generation. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.), Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pap...
-
[37]
MIRAGE : A metric-intensive benchmark for retrieval-augmented generation evaluation
Park, C., Moon, H., Park, C., and Lim, H. MIRAGE : A metric-intensive benchmark for retrieval-augmented generation evaluation. In Chiruzzo, L., Ritter, A., and Wang, L. (eds.), Findings of the Association for Computational Linguistics: NAACL 2025, pp.\ 2883--2900, Albuquerque, New Mexico, April 2025. Association for Computational Linguistics. ISBN 979-8-8...
-
[38]
Peskoff, D. and Stewart, B. Credible without credit: Domain experts assess generative language models. In Rogers, A., Boyd-Graber, J., and Okazaki, N. (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp.\ 427--438, Toronto, Canada, July 2023. Association for Computational Linguistics...
-
[39]
Petrov, A., Malfa, E. L., Torr, P. H., and Bibi, A. Language model tokenizers introduce unfairness between languages. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS '23, Red Hook, NY, USA, 2023. Curran Associates Inc
work page 2023
-
[40]
Pezeshkpour, P. and Hruschka, E. Large language models sensitivity to the order of options in multiple-choice questions. In Duh, K., Gomez, H., and Bethard, S. (eds.), Findings of the Association for Computational Linguistics: NAACL 2024, pp.\ 2006--2017, Mexico City, Mexico, June 2024. Association for Computational Linguistics. doi:10.18653/v1/2024.findi...
-
[41]
It's High Time: A Survey of Temporal Question Answering
Piryani, B., Abdallah, A., Mozafari, J., Anand, A., and Jatowt, A. It's high time: A survey of temporal question answering. arXiv preprint arXiv:2505.20243, 2025. URL https://arxiv.org/abs/2505.20243
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Pletenev, S., Marina, M., Ivanov, N., Galimzianova, D., Krayko, N., Salnikov, M., Konovalov, V., Panchenko, A., and Moskvoretskii, V. Will it still be true tomorrow? multilingual evergreen question classification to improve trustworthy QA . In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V. (eds.), Proceedings of the 2025 Conference on Emp...
-
[43]
LLM targeted underperformance disproportionately impacts vulnerable users
Poole-Dayan, E., Roy, D., and Kabbara, J. LLM targeted underperformance disproportionately impacts vulnerable users. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pp.\ 39116--39124, 2026. URL https://ojs.aaai.org/index.php/AAAI/article/view/41259
work page 2026
-
[44]
Rashkin, H., Nikolaev, V., Lamm, M., Aroyo, L., Collins, M., Das, D., Petrov, S., Tomar, G. S., Turc, I., and Reitter, D. Measuring attribution in natural language generation models. Computational Linguistics, 49 0 (4): 0 777--840, December 2023. doi:10.1162/coli_a_00486. URL https://aclanthology.org/2023.cl-4.2/
-
[45]
Reuters Institute for the Study of Journalism . AI adoption by UK journalists and their newsrooms: surveying applications, approaches, and attitudes, November 2025. URL https://reutersinstitute.politics.ox.ac.uk/ai-adoption-uk-journalists-and-their-newsrooms-surveying-applications-approaches-and-attitudes
work page 2025
-
[46]
How will AI reshape the news in 2026? forecasts by 17 experts from around the world, January 2026
Reuters Institute for the Study of Journalism . How will AI reshape the news in 2026? forecasts by 17 experts from around the world, January 2026. URL https://reutersinstitute.politics.ox.ac.uk/news/how-will-ai-reshape-news-2026-forecasts-17-experts-around-world
work page 2026
-
[47]
RAGC hecker: A fine-grained framework for diagnosing retrieval-augmented generation
Ru, D., Qiu, L., Hu, X., Zhang, T., Shi, P., Chang, S., Jiayang, C., Wang, C., Sun, S., Li, H., Zhang, Z., Wang, B., Jiang, J., He, T., Wang, Z., Liu, P., Zhang, Y., and Zhang, Z. RAGC hecker: A fine-grained framework for diagnosing retrieval-augmented generation. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchma...
work page 2024
-
[48]
AI use in American newspapers is widespread, uneven, and rarely disclosed
Russell, J., Karpinska, M., Akinode, D., Thai, K., Emi, B., Spero, M., and Iyyer, M. Ai use in american newspapers is widespread, uneven, and rarely disclosed. arXiv preprint arXiv:2510.18774, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
ARES : An automated evaluation framework for retrieval-augmented generation systems
Saad-Falcon, J., Khattab, O., Potts, C., and Zaharia, M. ARES : An automated evaluation framework for retrieval-augmented generation systems. In Duh, K., Gomez, H., and Bethard, S. (eds.), Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), ...
-
[50]
The great masquerade: How ai agents are spoofing their way in, December 2025
Segura, J. The great masquerade: How ai agents are spoofing their way in, December 2025. URL https://datadome.co/agent-trust-management/ai-agent-spoofing/. Published December 11, 2025; accessed May 12, 2026
work page 2025
-
[51]
Multi- FA ct: Assessing factuality of multilingual LLM s using FA ctscore
Shafayat, S., Kim, E., Oh, J., and Oh, A. Multi- FA ct: Assessing factuality of multilingual LLM s using FA ctscore. In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=lkrH6ovzsj
work page 2024
-
[52]
R., DURMUS, E., Hatfield-Dodds, Z., Johnston, S
Sharma, M., Tong, M., Korbak, T., Duvenaud, D., Askell, A., Bowman, S. R., DURMUS, E., Hatfield-Dodds, Z., Johnston, S. R., Kravec, S. M., Maxwell, T., McCandlish, S., Ndousse, K., Rausch, O., Schiefer, N., Yan, D., Zhang, M., and Perez, E. Towards understanding sycophancy in language models. In The Twelfth International Conference on Learning Representat...
work page 2024
-
[53]
Shaw, S. D. and Nave, G. Thinking-fast, slow, and artificial: How ai is reshaping human reasoning and the rise of cognitive surrender. Available at SSRN 6097646, 2026. URL https://papers.ssrn.com/sol3/papers.cfm?abstract_id=6097646
work page 2026
-
[54]
Sidoti, O. and McClain, C. 34\ URL https://www.pewresearch.org/short-reads/2025/06/25/34-of-us-adults-have-used-chatgpt-about-double-the-share-in-2023/. Short Reads
work page 2025
-
[55]
xai transparency report, December 2025
Stanford CRFM . xai transparency report, December 2025. URL https://crfm.stanford.edu/fmti/December-2025/company-reports/xAI_FinalReport_FMTI2025.html. Accessed May 12, 2026
work page 2025
-
[56]
E., Icard, T., Jurafsky, D., and Zou, J
Suzgun, M., Gur, T., Bianchi, F., Ho, D. E., Icard, T., Jurafsky, D., and Zou, J. Belief in the machine: Investigating epistemological blind spots of language models. arXiv preprint arXiv:2410.21195, 2024
-
[57]
E., Icard, T., Jurafsky, D., and Zou, J
Suzgun, M., Gur, T., Bianchi, F., Ho, D. E., Icard, T., Jurafsky, D., and Zou, J. Language models cannot reliably distinguish belief from knowledge and fact. Nature Machine Intelligence, pp.\ 1--11, 2025
work page 2025
-
[58]
Turpin, M., Michael, J., Perez, E., and Bowman, S. R. Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=bzs4uPLXvi
work page 2023
-
[59]
F resh LLM s: Refreshing large language models with search engine augmentation
Vu, T., Iyyer, M., Wang, X., Constant, N., Wei, J., Wei, J., Tar, C., Sung, Y.-H., Zhou, D., Le, Q., and Luong, T. F resh LLM s: Refreshing large language models with search engine augmentation. In Ku, L.-W., Martins, A., and Srikumar, V. (eds.), Findings of the Association for Computational Linguistics: ACL 2024, pp.\ 13697--13720, Bangkok, Thailand, Aug...
-
[60]
Wang, H., Xue, B., Zhou, B., Zhang, T., Wang, C., Wang, H., Chen, G., and Wong, K.-F. Self- DC : When to reason and when to act? self divide-and-conquer for compositional unknown questions. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: L...
work page 2025
-
[61]
Wang, L. and Haner, J. Many Americans say they often come across inaccurate news and have a hard time knowing what’s true, October 2025. URL https://www.pewresearch.org/short-reads/2025/10/29/many-americans-say-they-often-come-across-inaccurate-news-and-have-a-hard-time-knowing-whats-true/. Short Reads
work page 2025
-
[62]
Wei, J., Huang, D., Lu, Y., Zhou, D., and Le, Q. V. Simple synthetic data reduces sycophancy in large language models, 2025. URL https://openreview.net/forum?id=WDheQxWAo4
work page 2025
-
[63]
An automated framework for assessing how well llms cite relevant medical references
Wu, K., Wu, E., Wei, K., Zhang, A., Casasola, A., Nguyen, T., Riantawan, S., Shi, P., Ho, D., and Zou, J. An automated framework for assessing how well llms cite relevant medical references. Nature Communications, 16 0 (1): 0 3615, 2025
work page 2025
-
[64]
Deconstructing self-bias in llm-generated translation benchmarks
Xu, W., Agrawal, S., Zouhar, V., Freitag, M., and Deutsch, D. Deconstructing self-bias in llm-generated translation benchmarks. arXiv preprint arXiv:2509.26600, 2025 a
-
[65]
Let LLM s take on the latest challenges! a C hinese dynamic question answering benchmark
Xu, Z., Li, Y., Ding, R., Wang, X., Chen, B., Jiang, Y., Zheng, H., Lu, W., Xie, P., and Huang, F. Let LLM s take on the latest challenges! a C hinese dynamic question answering benchmark. In Rambow, O., Wanner, L., Apidianaki, M., Al-Khalifa, H., Eugenio, B. D., and Schockaert, S. (eds.), Proceedings of the 31st International Conference on Computational ...
work page 2025
-
[66]
Corrective retrieval augmented generation, 2024
Yan, S.-Q., Gu, J.-C., Zhu, Y., and Ling, Z.-H. Corrective retrieval augmented generation, 2024. URL https://openreview.net/forum?id=JnWJbrnaUE
work page 2024
-
[67]
Three key findings from the 2025 digital news report, June 2025
YouGov . Three key findings from the 2025 digital news report, June 2025. URL https://yougov.com/articles/52379-three-key-findings-from-the-2025-digital-news-report
work page 2025
-
[68]
Silencer: From discovery to mitigation of self-bias in llm-as-benchmark-generator
Yuan, P., Li, Y., Feng, S., Wang, X., Zhang, Y., Shi, J., Tan, C., Pan, B., Hu, Y., and Li, K. Silencer: From discovery to mitigation of self-bias in llm-as-benchmark-generator. arXiv preprint arXiv:2505.20738, 2025
-
[69]
Y \"u ksel, A., K \"o ksal, A., Senel, L. K., Korhonen, A., and Schuetze, H. T urkish MMLU : Measuring massive multitask language understanding in T urkish. In Al-Onaizan, Y., Bansal, M., and Chen, Y.-N. (eds.), Findings of the Association for Computational Linguistics: EMNLP 2024, pp.\ 7035--7055, Miami, Florida, USA, November 2024. Association for Compu...
-
[70]
Zack, T., Lehman, E., Suzgun, M., Rodriguez, J. A., Celi, L. A., Gichoya, J., Jurafsky, D., Szolovits, P., Bates, D. W., Abdulnour, R.-E. E., et al. Assessing the potential of gpt-4 to perpetuate racial and gender biases in health care: a model evaluation study. The Lancet Digital Health, 6 0 (1): 0 e12--e22, 2024
work page 2024
-
[71]
Large language models are not robust multiple choice selectors
Zheng, C., Zhou, H., Meng, F., Zhou, J., and Huang, M. Large language models are not robust multiple choice selectors. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=shr9PXz7T0
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.