The Attribution Contract: Feature Attribution for Generative Language Models
Pith reviewed 2026-05-25 05:29 UTC · model grok-4.3
The pith
Generative language models require an explicit Attribution Contract to make feature attribution claims meaningful.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
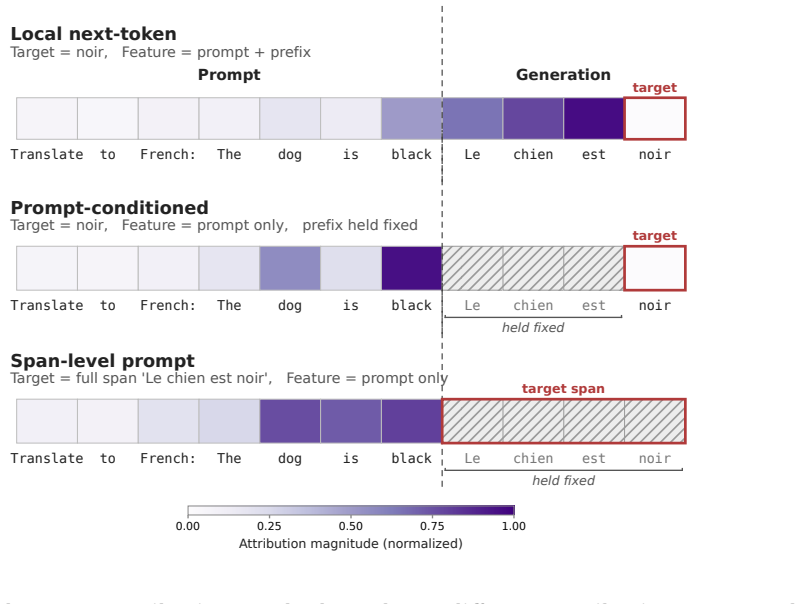
We argue that this ambiguity is not merely an implementation detail, but a conceptual limitation of carrying classifier-era feature attribution directly into generative language modeling. We introduce the Attribution Contract, a specification for feature-attribution claims that names what output is being explained, which features are eligible to receive attribution, what generative process is assumed, what is held fixed, and what model score is being attributed. The contract clarifies why the same attribution method can answer different questions depending on how it is instantiated. We argue that many disagreements about feature attribution in generative language models are not disagreements
What carries the argument
The Attribution Contract, a five-element specification that defines the output explained, eligible features, generative process, fixed elements, and model score for any attribution claim.
If this is right
- The same attribution algorithm produces different insights depending on the chosen contract.
- Attribution to earlier generated tokens is informative only when the contract treats those tokens as eligible features.
- In diffusion models, local explanations can target intermediate denoising states when the contract so specifies.
- Feature-attribution methods must be evaluated as method-contract pairs rather than in isolation.
- Clarifying contracts makes apparent conflicts in the literature traceable to differing premises.
Where Pith is reading between the lines
- Standardizing contract declarations in published work could make explanation results across papers directly comparable.
- New attribution techniques could be developed that are optimized for particular contract choices rather than claimed to be contract-agnostic.
- In applied settings such as debugging generated text, requiring contract statements upfront might reduce misinterpretation of which parts of the input the model actually relied on.
Load-bearing premise
That naming the five elements of the Attribution Contract resolves the conceptual limitation and that observed disagreements arise primarily from unstated contracts rather than algorithmic differences or evaluation choices.
What would settle it
A controlled comparison in which multiple papers explicitly declare their attribution contracts yet continue to produce incompatible conclusions about the same model and output would falsify the claim that unstated contracts are the main source of disagreement.
Figures
read the original abstract
Feature attribution methods promise to identify which input features matter for a model output. In generative language models, however, it is often unclear what should count as a feature in the first place. In autoregressive language models, earlier generated tokens are both outputs of the model and inputs to later predictions. In diffusion language models, generation proceeds through iterative denoising or unmasking rather than fixed left-to-right prediction, so local explanation may target a state of diffusion rather than a next token. We argue that this ambiguity is not merely an implementation detail, but a conceptual limitation of carrying classifier-era feature attribution directly into generative language modeling. We introduce the Attribution Contract, a specification for feature-attribution claims that names what output is being explained, which features are eligible to receive attribution, what generative process is assumed, what is held fixed, and what model score is being attributed. The contract clarifies why the same attribution method can answer different questions depending on how it is instantiated. We argue that many disagreements about feature attribution in generative language models are not disagreements about attribution algorithms, but about unstated explanatory contracts. Using autoregressive and diffusion language models as case studies, we show when attribution to earlier generated tokens, intermediate states, or denoising stages is informative, when it is misleading, and why feature-attribution methods in generative language models should be evaluated as method-contract pairs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that feature attribution methods developed for classifiers encounter a conceptual limitation when applied to generative language models, due to ambiguities in what counts as a 'feature' (e.g., prior tokens serving as both outputs and inputs in autoregressive models, or intermediate diffusion states). It introduces the Attribution Contract—a five-element specification naming the output explained, eligible features, assumed generative process, what is held fixed, and the model score attributed—as a way to make implicit assumptions explicit. The central claim is that many literature disagreements concern unstated contracts rather than algorithms themselves, and that attribution methods should be evaluated as method-contract pairs, illustrated through case studies on autoregressive and diffusion language models.
Significance. If the framework is adopted, it could provide a useful taxonomy for clarifying explanatory assumptions in generative-model interpretability, encouraging more precise communication and evaluation. The emphasis on method-contract pairs offers a conceptual tool that might reduce certain classes of misinterpretation, though its significance is tempered by the absence of evidence that contract mismatch is the primary source of observed disagreements.
major comments (2)
- [Abstract] Abstract: the claim that 'many disagreements about feature attribution in generative language models are not disagreements about attribution algorithms, but about unstated explanatory contracts' is load-bearing for the paper's contribution, yet the manuscript provides no systematic analysis, citation count, or categorization of existing literature disagreements to demonstrate that contract mismatch dominates over algorithmic differences, baseline choices, or evaluation metrics.
- [Case studies] Case studies section: the illustrative examples show scenarios where attribution to prior tokens or diffusion states is informative versus misleading, but contain no quantitative isolation (e.g., controlled ablation or variance decomposition) of contract specification effects from confounding factors such as normalization or baseline selection, leaving the assertion that the contract resolves the claimed conceptual limitation unsupported.
minor comments (1)
- The five elements of the Attribution Contract are described narratively; formalizing them with explicit notation or pseudocode would improve precision and ease of application.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'many disagreements about feature attribution in generative language models are not disagreements about attribution algorithms, but about unstated explanatory contracts' is load-bearing for the paper's contribution, yet the manuscript provides no systematic analysis, citation count, or categorization of existing literature disagreements to demonstrate that contract mismatch dominates over algorithmic differences, baseline choices, or evaluation metrics.
Authors: We agree that the central claim would be strengthened by more explicit evidence from the literature. The manuscript's argument is primarily conceptual, using the Attribution Contract to identify sources of ambiguity and illustrating them via case studies. In revision we will add a targeted discussion (in the introduction or a new subsection) with specific citations to published attribution results on generative models where outcome differences align with differing implicit contracts (e.g., next-token vs. full-sequence explanation, or token vs. diffusion-state features) rather than algorithmic or baseline choices. A comprehensive citation count or exhaustive categorization remains outside the paper's scope, but concrete examples will be supplied. revision: partial
-
Referee: [Case studies] Case studies section: the illustrative examples show scenarios where attribution to prior tokens or diffusion states is informative versus misleading, but contain no quantitative isolation (e.g., controlled ablation or variance decomposition) of contract specification effects from confounding factors such as normalization or baseline selection, leaving the assertion that the contract resolves the claimed conceptual limitation unsupported.
Authors: The case studies are designed as qualitative illustrations of the conceptual issues the Attribution Contract addresses. We acknowledge that quantitative isolation of contract effects from other factors would offer additional support; however, defining and measuring 'conceptual resolution' via controlled ablations or variance decomposition is not straightforward and would require new metrics beyond the paper's conceptual contribution. The examples demonstrate when attributions become misleading under mismatched contracts and why method-contract pairs are the appropriate unit of evaluation. No quantitative experiments will be added in revision. revision: no
Circularity Check
No significant circularity: definitional framework with no equations, fitted predictions, or load-bearing self-citations.
full rationale
The paper introduces the Attribution Contract as a five-element specification (output explained, eligible features, generative process, what is held fixed, model score attributed) to clarify feature attribution in generative language models. This is presented as a conceptual taxonomy rather than a mathematical derivation. No equations appear in the provided text that could reduce outputs to inputs by construction. The claim that disagreements arise from unstated contracts is argued via case studies on autoregressive and diffusion models, without statistical fitting or self-citation chains that force the result. The framework does not rename known results or smuggle ansatzes; it functions as an organizational proposal. Per the rules, this is a normal non-finding of circularity (score 0-2) for a self-contained definitional work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Feature attribution methods become well-defined in generative models once the explanatory contract is explicitly stated.
invented entities (1)
-
Attribution Contract
no independent evidence
Reference graph
Works this paper leans on
-
[1]
ContextCite: Attributing Model Generation to Context
Benjamin Cohen-Wang, Harshay Shah, Kristian Georgiev, and Aleksander Mądry. ContextCite: Attributing Model Generation to Context. InAdvances in Neural Information Processing Sys- tems, volume 37, 2024.https://proceedings.neurips.cc/paper_files/paper/2024/hash/ adbea136219b64db96a9941e4249a857-Abstract-Conference.html
work page 2024
-
[2]
Sequential Integrated Gradients: a Simple but Effective Method for Explaining Language Models
Joseph Enguehard. Sequential Integrated Gradients: a Simple but Effective Method for Explaining Language Models. InFindings of the Association for Computational Linguistics: ACL 2023, pages 7555–7565, 2023.https://aclanthology.org/2023.findings-acl.477/
work page 2023
-
[3]
Liu, Baran Zadeoğlu, Nicolas Boullé, Raphaël Sarfati, and Christopher J
Toni J.B. Liu, Baran Zadeoğlu, Nicolas Boullé, Raphaël Sarfati, and Christopher J. Earls. Jacobian Scopes: Token-level Causal Attributions in LLMs. arXiv preprint arXiv:2601.16407, 2026.https://arxiv.org/abs/2601.16407
-
[4]
Locating and Edit- ing Factual Associations in GPT
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and Edit- ing Factual Associations in GPT. InAdvances in Neural Information Processing Sys- tems, volume 35, 2022.https://proceedings.neurips.cc/paper_files/paper/2022/hash/ 6f1d43d5a82a37e89b0665b33bf3a182-Abstract-Conference.html
work page 2022
-
[5]
Markosyan, Diego Garcia-Olano, and Narine Kokhlikyan
Vivek Miglani, Aobo Yang, Aram H. Markosyan, Diego Garcia-Olano, and Narine Kokhlikyan. Using Captum to Explain Generative Language Models. InProceedings of the 3rd Workshop for Natural Language Processing Open Source Software (NLP-OSS 2023), pages 165–173, 2023. https://aclanthology.org/2023.nlposs-1.19/
work page 2023
-
[6]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large Language Diffusion Models. InAdvances in Neural Information Processing Systems, 2025.https://openreview.net/forum?id=KnqiC0znVF
work page 2025
-
[7]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 32819–32848. PMLR, 2024.https://proceedings.mlr.press/v235/lou24a.html
work page 2024
-
[8]
Continuous Diffusion Model for Language Modeling
Jaehyeong Jo and Sung Ju Hwang. Continuous Diffusion Model for Language Modeling. arXiv preprint arXiv:2502.11564, 2025.https://arxiv.org/abs/2502.11564
-
[9]
Vishal Pramanik, Maisha Maliha, Nathaniel D. Bastian, and Sumit Kumar Jha. Hessian- Enhanced Token Attribution (HETA): Interpreting Autoregressive LLMs. InInternational Con- ference on Learning Representations, 2026.https://openreview.net/forum?id=XsEZcigEjq
work page 2026
-
[10]
Hannah Rashkin, Vitaly Nikolaev, Matthew Lamm, Lora Aroyo, Michael Collins, Dipanjan Das, Slav Petrov, Gaurav Singh Tomar, Iulia Turc, and David Reitter. Measuring Attribution in Natural Language Generation Models.Computational Linguistics, 49(4):777–840, 2023. https://aclanthology.org/2023.cl-4.2/
work page 2023
-
[11]
Discretized Integrated Gradients for Explaining Language Models
Soumya Sanyal and Xiang Ren. Discretized Integrated Gradients for Explaining Language Models. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 10285–10299, 2021.https://aclanthology.org/2021.emnlp-main.805/
work page 2021
-
[12]
Inseq: An Interpretability Toolkit for Sequence Generation Models
Gabriele Sarti, Nils Feldhus, Ludwig Sickert, and Oskar van der Wal. Inseq: An Interpretability Toolkit for Sequence Generation Models. InProceedings of the 61st Annual Meeting of the 12 Association for Computational Linguistics (Volume 3: System Demonstrations), pages 421–435, 2023.https://aclanthology.org/2023.acl-demo.40/
work page 2023
-
[13]
Axiomatic Attribution for Deep Networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic Attribution for Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 3319–3328. PMLR, 2017.https://proceedings.mlr. press/v70/sundararajan17a.html
work page 2017
-
[14]
What the DAAM: Interpreting Stable Diffusion Using Cross Attention
Raphael Tang, Linqing Liu, Akshat Pandey, Zhiying Jiang, Gefei Yang, Karun Kumar, Pontus Stenetorp, Jimmy Lin, and Ferhan Ture. What the DAAM: Interpreting Stable Diffusion Using Cross Attention. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5644–5659, 2023.https://aclanthology.org...
work page 2023
-
[15]
Explaining the Reasoning of Large Language Models Using Attribution Graphs
Chase Walker and Rickard Ewetz. Explaining the Reasoning of Large Language Models Using Attribution Graphs. arXiv preprint arXiv:2512.15663, 2025.https://arxiv.org/abs/2512. 15663
-
[16]
Unifying Corroborative and Contributive Attributions in Large Language Models
Theodora Worledge, Judy Hanwen Shen, Nicole Meister, Caleb Winston, and Carlos Guestrin. Unifying Corroborative and Contributive Attributions in Large Language Models. arXiv preprint arXiv:2311.12233, 2023.https://arxiv.org/abs/2311.12233
-
[17]
Towards Unified Attri- bution in Explainable AI, Data-Centric AI, and Mechanistic Interpretability
Shichang Zhang, Tessa Han, Usha Bhalla, and Himabindu Lakkaraju. Towards Unified Attri- bution in Explainable AI, Data-Centric AI, and Mechanistic Interpretability. arXiv preprint arXiv:2501.18887, 2025.https://arxiv.org/abs/2501.18887
-
[18]
ReAGent: A Model-Agnostic Feature Attribution Method for Generative Language Models
Zhixue Zhao and Boxuan Shan. ReAGent: A Model-Agnostic Feature Attribution Method for Generative Language Models. InProceedings of the AAAI Workshop on Responsible Language Models, 2024.https://arxiv.org/abs/2402.00794
-
[19]
Blair Bilodeau, Natasha Jaques, Pang Wei Koh, and Been Kim. Impossibility Theorems for Feature Attribution.Proceedings of the National Academy of Sciences, 121(2):e2304406120, 2024.https://www.pnas.org/doi/10.1073/pnas.2304406120
-
[20]
Giang Nguyen, Daeyoung Kim, and Anh Nguyen. The Effectiveness of Feature Attribution Methods and Its Correlation with Automatic Evaluation Scores. InAdvances in Neural Information Processing Systems, volume 34, pages 26422–26436, 2021.https://proceedings. neurips.cc/paper/2021/hash/de043a5e421240eb846da8effe472ff1-Abstract.html
work page 2021
-
[21]
Post Hoc Explanations May Be Ineffective for Detecting Unknown Spurious Correlation
Julius Adebayo, Michael Muelly, Harold Abelson, and Been Kim. Post Hoc Explanations May Be Ineffective for Detecting Unknown Spurious Correlation. InInternational Conference on Learning Representations, 2022.https://openreview.net/forum?id=xNOVfCCvDpM
work page 2022
-
[22]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, Andy Jones, Sam Bowman, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Nelson Elhage, Sheer El-Showk, Stanislav Fort, Zac Hatfield-Dodds, Tom Henighan, Danny Hernandez, Tristan Hume, Josh Jacobson, Scott Joh...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Chen, Wenhao Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions.ACM Transactions on Information Systems, 2024.https://dl.acm.org/doi/10.1145/3703155
-
[24]
Survey of Hallucination in Natural Language Generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of Hallucination in Natural Language Generation. ACM Computing Surveys, 55(12):1–38, 2023.https://dl.acm.org/doi/10.1145/3571730
-
[25]
Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 11048–11064, 2022.https://aclanthology.org/2022.emnlp-main.759/
work page 2022
-
[26]
Red Teaming Language Models with Language Models
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red Teaming Language Models with Language Models. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2022.https://arxiv.org/abs/2202.03286 14
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.