Inductive Deductive Synthesis: Enabling AI to Generate Formally Verified Systems
Pith reviewed 2026-05-25 04:49 UTC · model grok-4.3
The pith
An AI system called IDS generates formally verified distributed systems by jointly synthesizing code and proofs from failed verification attempts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
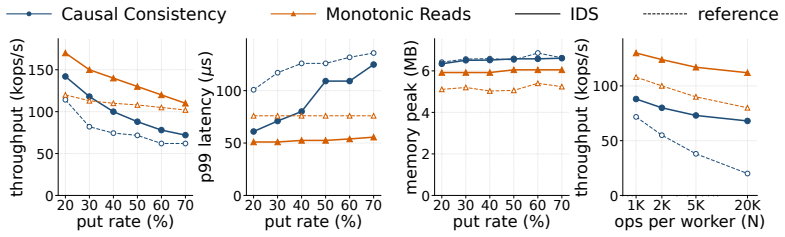
Inductive Deductive Synthesis jointly and incrementally synthesizes implementation and proof, and learns from failed attempts to systematically try promising strategies. Built as an agentic LLM system, IDS achieves 7/7 success on distributed key-value-store specifications in about 6.8 hours and $106 per spec on average, roughly 200x faster than expert effort and 17% cheaper than SOTA agents. IDS further incorporates performance feedback into the same loop, yielding implementations up to 3x faster than published verified systems.
What carries the argument
Inductive Deductive Synthesis (IDS), an incremental loop that produces both code and its formal proof together while using verification failures to select the next synthesis strategy.
If this is right
- All seven distributed key-value-store specifications receive complete verified implementations.
- Average wall-clock time per specification falls to 6.8 hours.
- Average monetary cost per specification is $106.
- Generated implementations run up to three times faster than previously published verified versions.
- Expert human effort is reduced by a factor of roughly 200.
Where Pith is reading between the lines
- The same failure-driven loop could be tested on other domains that need full coverage guarantees, such as cryptographic protocols or concurrent data structures.
- Performance feedback already inside the loop suggests the method can be extended to produce verified code that also meets explicit runtime or resource bounds.
- Success depends on the verification oracle returning informative counterexamples; weaker oracles might cause the strategy-selection component to stall.
- Whether the approach generalizes beyond the seven tested specifications remains open and would be settled by applying it to larger or structurally different systems.
Load-bearing premise
The LLM agent can learn from failed verification attempts and systematically select promising next strategies without becoming trapped in unproductive loops or incurring prohibitive compute cost.
What would settle it
Apply IDS to a fresh collection of distributed-system specifications whose properties were not used during its development and check whether success rate, time, and cost remain comparable to the reported 7/7 result.
Figures























read the original abstract
AI agents increasingly excel at generating, testing, and refining code. However, they fall short on tasks requiring formal guarantees of full coverage that testing alone cannot provide. Distributed systems are a prime example: properties such as consistency between reads and writes must hold under every possible interleaving of events. Mechanized formal verification can guarantee such correctness, but typically demands months to years of expert effort. As evidence, even SOTA coding agents (Codex with GPT-5.4 and Claude Code with Opus 4.6) succeed on only 2/7 distributed key-value-store specifications. In this paper, we present the first effective approach to addressing this gap, Inductive Deductive Synthesis (IDS), which jointly and incrementally synthesizes implementation and proof, and learns from failed attempts to systematically try promising strategies. Built as an agentic LLM system, IDS achieves 7/7 in about 6.8 hours and $106 per spec on average, roughly 200x faster than expert effort and 17% cheaper than SOTA agents. IDS further incorporates performance feedback into the same loop, yielding implementations up to 3x faster than published verified systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Inductive Deductive Synthesis (IDS), an agentic LLM system that jointly and incrementally synthesizes implementations and formal proofs for distributed systems while learning from verification failures to select strategies. It claims 7/7 success on distributed key-value-store specifications (versus 2/7 for SOTA agents), with averages of 6.8 hours and $106 per specification, representing roughly 200x speedup over expert effort, 17% lower cost than baselines, and up to 3x faster runtime than published verified systems.
Significance. If the empirical results and the underlying failure-to-strategy learning mechanism prove robust and reproducible, the work would mark a notable step toward automating formal verification of distributed systems, a domain where expert effort has historically been prohibitive. The joint inductive-deductive loop and incorporation of performance feedback are conceptually promising extensions of current LLM agent techniques.
major comments (3)
- [Abstract] Abstract: success counts, time, and cost figures are stated without any experimental protocol details (selection criteria for the seven specifications, number of independent runs, variance or error bars, or termination criteria), which directly limits evaluation of whether the 7/7 and 200x claims are supported.
- [Method description] Method (strategy learning component): the paper asserts that the agent extracts inductive signals from verification failures (counterexamples or proof obligations) to systematically select or synthesize new deductive strategies, yet supplies no description of strategy representation, the update rule, or conditions that prevent high-cost repetitive loops; this mechanism is load-bearing for the headline 7/7 result and the reported 6.8 h / $106 averages.
- [Results] Results section (performance comparison): the claim of implementations up to 3x faster than published verified systems lacks specification of the exact baseline implementations, measurement methodology, or workload used for the runtime comparison, undermining the cross-system performance assertion.
minor comments (3)
- [Abstract] Abstract and introduction would benefit from explicit mention of the underlying formal logic or verification framework (e.g., TLA+, Coq, or Ivy) employed for the proofs.
- [Results] Table or figure presenting per-specification success rates, times, and costs for IDS versus each named baseline would improve clarity and allow direct inspection of the 17% cost advantage.
- [Introduction] Minor: a short related-work paragraph contrasting IDS with prior LLM-based program synthesis or proof-generation systems (beyond the two named SOTA agents) would help situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications from the paper and indicate revisions where the manuscript will be updated to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: success counts, time, and cost figures are stated without any experimental protocol details (selection criteria for the seven specifications, number of independent runs, variance or error bars, or termination criteria), which directly limits evaluation of whether the 7/7 and 200x claims are supported.
Authors: We agree that the abstract would benefit from additional protocol context to better support the headline claims. The full details (specification selection from prior KV-store benchmarks, three independent runs per spec, reported variance, and 24-hour timeout termination) appear in Section 4. In revision we will add a concise sentence to the abstract referencing these elements and directing readers to the experimental section. revision: yes
-
Referee: [Method description] Method (strategy learning component): the paper asserts that the agent extracts inductive signals from verification failures (counterexamples or proof obligations) to systematically select or synthesize new deductive strategies, yet supplies no description of strategy representation, the update rule, or conditions that prevent high-cost repetitive loops; this mechanism is load-bearing for the headline 7/7 result and the reported 6.8 h / $106 averages.
Authors: The referee correctly notes that the strategy-learning mechanism is central and that the current description is high-level. The manuscript does not yet provide explicit representation, update rule, or loop-prevention details. We will revise Section 3 to add this material, including pseudocode for the failure-to-strategy mapping and the cost-threshold mechanism that avoids repetitive loops. revision: yes
-
Referee: [Results] Results section (performance comparison): the claim of implementations up to 3x faster than published verified systems lacks specification of the exact baseline implementations, measurement methodology, or workload used for the runtime comparison, undermining the cross-system performance assertion.
Authors: We acknowledge the need for explicit baseline and measurement details. The baselines are the verified KV-store implementations from the IronFleet and Verdi papers; runtime was measured as average latency on the YCSB 50/50 read/write workload on identical hardware. We will revise the Results section to state these baselines, the exact workload, and the measurement protocol in a new comparison table. revision: yes
Circularity Check
No circularity: empirical success rates are measured outcomes, not derived quantities
full rationale
The paper reports direct experimental results for the IDS agentic system on 7 distributed KV-store specifications, including success counts, wall-clock time, monetary cost, and comparisons to named baselines (Codex, Claude Code) and expert effort. No equations, fitted parameters, predictions, or first-principles derivations appear in the provided text. The central performance claims rest on measured runtimes and verification outcomes rather than any quantity defined in terms of itself or reduced via self-citation. The learning-from-failure mechanism is described at the level of system behavior, not as a mathematical identity that collapses to its inputs by construction. This is a standard empirical systems paper whose claims are externally falsifiable via replication on the same benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pranjal Aggarwal, Bryan Parno, and Sean Welleck. AlphaVerus: Bootstrapping formally verified code generation through self-improving translation and treefinement.ICML, 2025. arXiv:2412.06176
-
[2]
Causal memory: Definitions, implementation, and programming.Distributed Computing, 9(1), 1995
Mustaque Ahamad, Gil Neiger, James E Burns, Prince Kohli, and Phillip W Hutto. Causal memory: Definitions, implementation, and programming.Distributed Computing, 9(1), 1995
1995
-
[3]
Claude Code: Anthropic’s agentic coding system.https://www.anthropic.com/product/ claude-code, 2025
Anthropic. Claude Code: Anthropic’s agentic coding system.https://www.anthropic.com/product/ claude-code, 2025
2025
-
[4]
Cursor: The AI code editor.https://cursor.com, 2025
Anysphere. Cursor: The AI code editor.https://cursor.com, 2025
2025
-
[5]
The network is reliable.Commun
Peter Bailis and Kyle Kingsbury. The network is reliable.Commun. ACM, 57(9):48–55, September 2014
2014
-
[6]
DafnyPro: Llm-assisted automated verifica- tion for Dafny programs
Debangshu Banerjee, Olivier Bouissou, and Stefan Zetzsche. DafnyPro: Llm-assisted automated verifica- tion for Dafny programs. 2026. POPL Dafny Workshop; arXiv:2601.05385
-
[7]
Texts in Theoretical Computer Science
Yves Bertot and Pierre Castéran.Interactive Theorem Proving and Program Development: Coq’Art: The Calculus of Inductive Constructions. Texts in Theoretical Computer Science. Springer, 2004
2004
-
[8]
Frans Kaashoek, and Nickolai Zeldovich
Tej Chajed, Joseph Tassarotti, M. Frans Kaashoek, and Nickolai Zeldovich. Verifying concurrent, crash- safe systems with perennial. InProceedings of the 27th ACM Symposium on Operating Systems Principles, SOSP ’19, page 243–258, New York, NY , USA, 2019. Association for Computing Machinery
2019
-
[9]
Frans Kaashoek, and Nickolai Zeldovich
Haogang Chen, Daniel Ziegler, Tej Chajed, Adam Chlipala, M. Frans Kaashoek, and Nickolai Zeldovich. Using crash hoare logic for certifying the FSCQ file system. In Ethan L. Miller and Steven Hand, editors, Proceedings of the 25th Symposium on Operating Systems Principles, SOSP 2015, Monterey, CA, USA, October 4-7, 2015, pages 18–37. ACM, 2015. 10
2015
-
[10]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Counterexample-guided abstraction refinement
Edmund Clarke, Orna Grumberg, Somesh Jha, Yuan Lu, and Helmut Veith. Counterexample-guided abstraction refinement. InInternational Conference on Computer Aided Verification, pages 154–169. Springer, 2000
2000
-
[12]
The Lean 4 theorem prover and programming language
Leonardo de Moura and Sebastian Ullrich. The Lean 4 theorem prover and programming language. In André Platzer and Geoff Sutcliffe, editors,Automated Deduction — CADE 28 — 28th International Conference on Automated Deduction, Virtual Event, July 12–15, 2021, Proceedings, volume 12699 of Lecture Notes in Computer Science, pages 625–635. Springer, 2021
2021
-
[13]
Stp: Self-play llm theorem provers with iterative conjecturing and proving
Kefan Dong and Tengyu Ma. Stp: Self-play llm theorem provers with iterative conjecturing and proving. InInternational Conference on Machine Learning, pages 14114–14136. PMLR, 2025
2025
- [14]
-
[15]
Rabe, Talia Ringer, and Yuriy Brun
Emily First, Markus N. Rabe, Talia Ringer, and Yuriy Brun. Baldur: Whole-proof generation and repair with large language models. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2023, page 1229–1241, New York, NY , USA, 2023. Association for Computing Machinery
2023
-
[16]
Lorch, Bryan Parno, Michael Lowell Roberts, Srinath T
Chris Hawblitzel, Jon Howell, Manos Kapritsos, Jacob R. Lorch, Bryan Parno, Michael Lowell Roberts, Srinath T. V . Setty, and Brian Zill. IronFleet: proving practical distributed systems correct. InProceedings of the 25th Symposium on Operating Systems Principles, SOSP 2015, Monterey, CA, USA, October 4-7,
2015
-
[17]
MetaGPT: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. MetaGPT: Meta programming for a multi-agent collaborative framework. InICLR,
-
[18]
Olympiad-level formal mathematical reasoning with reinforcement learning.Nature, pages 1–3, 2025
Thomas Hubert, Rishi Mehta, Laurent Sartran, Miklós Z Horváth, Goran Žuži´c, Eric Wieser, Aja Huang, Julian Schrittwieser, Yannick Schroecker, Hussain Masoom, et al. Olympiad-level formal mathematical reasoning with reinforcement learning.Nature, pages 1–3, 2025
2025
-
[19]
Zhaoyu Li, Jialiang Sun, Logan Murphy, Qidong Su, Zenan Li, Xian Zhang, Kaiyu Yang, and Xujie Si
Albert Q. Jiang, Sean Welleck, Jin Peng Zhou, Wenda Li, Jiacheng Liu, Mateja Jamnik, Timothée Lacroix, Yuhuai Wu, and Guillaume Lample. Draft, sketch, and prove: Guiding formal theorem provers with informal proofs. InICLR, 2023. arXiv:2210.12283
-
[20]
Iris: Monoids and invariants as an orthogonal basis for concurrent reasoning
Ralf Jung, David Swasey, Filip Sieczkowski, Kasper Svendsen, Aaron Turon, Lars Birkedal, and Derek Dreyer. Iris: Monoids and invariants as an orthogonal basis for concurrent reasoning. In Sriram K. Rajamani and David Walker, editors,Proceedings of the 42nd Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL 2015, Mumbai, India...
2015
-
[21]
Cock, Philip Derrin, Dham- mika Elkaduwe, Kai Engelhardt, Rafal Kolanski, Michael Norrish, Thomas Sewell, Harvey Tuch, and Simon Winwood
Gerwin Klein, Kevin Elphinstone, Gernot Heiser, June Andronick, David A. Cock, Philip Derrin, Dham- mika Elkaduwe, Kai Engelhardt, Rafal Kolanski, Michael Norrish, Thomas Sewell, Harvey Tuch, and Simon Winwood. seL4: Formal verification of an OS kernel. InProceedings of the 22nd ACM Symposium on Operating Systems Principles, SOSP 2009, Big Sky, Montana, U...
2009
-
[22]
Lorch, Oded Padon, and Bryan Parno
Andrea Lattuada, Travis Hance, Jay Bosamiya, Matthias Brun, Chanhee Cho, Hayley LeBlanc, Pranav Srinivasan, Reto Achermann, Tej Chajed, Chris Hawblitzel, Jon Howell, Jacob R. Lorch, Oded Padon, and Bryan Parno. Verus: A practical foundation for systems verification. In Emmett Witchel, Christopher J. Rossbach, Andrea C. Arpaci-Dusseau, and Kimberly Keeton,...
2024
-
[23]
Lukman, Shan Lu, and Haryadi S
Tanakorn Leesatapornwongsa, Jeffrey F. Lukman, Shan Lu, and Haryadi S. Gunawi. TaxDC: A taxonomy of non-deterministic concurrency bugs in datacenter distributed systems. InProceedings of the 21st International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), pages 517–530, 2016
2016
-
[24]
Rustan M
K. Rustan M. Leino. Dafny: An automatic program verifier for functional correctness. In Edmund M. Clarke and Andrei V oronkov, editors,Logic for Programming, Artificial Intelligence, and Reasoning — 16th International Conference, LPAR-16, Dakar, Senegal, April 25–May 1, 2010, Revised Selected Papers, volume 6355 ofLecture Notes in Computer Science, pages ...
2010
-
[25]
Formal verification of a realistic compiler.Communications of the ACM, 52(7):107–115, 2009
Xavier Leroy. Formal verification of a realistic compiler.Communications of the ACM, 52(7):107–115, 2009
2009
-
[26]
Bell, and Adam Chlipala
Mohsen Lesani, Christian J. Bell, and Adam Chlipala. Chapar: certified causally consistent distributed key-value stores. In Rastislav Bodík and Rupak Majumdar, editors,Proceedings of the 43rd Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL 2016, St. Petersburg, FL, USA, January 20 - 22, 2016, pages 357–370. ACM, 2016
2016
-
[27]
Goedel-code-prover: Hierarchical proof search for open state-of-the-art code verification
Zenan Li, Ziran Yang, Haoyu Zhao, Andrew Zhao, Shange Tang, Kaiyu Yang, Aarti Gupta, Zhendong Su, Chi Jin, et al. Goedel-code-prover: Hierarchical proof search for open state-of-the-art code verification. arXiv preprint arXiv:2603.19329, 2026
-
[28]
Freedman, Michael Kaminsky, and David G
Wyatt Lloyd, Michael J. Freedman, Michael Kaminsky, and David G. Andersen. Stronger semantics for low-latency geo-replicated storage. InProc. NSDI, 2013
2013
-
[29]
miniCodeProps: A minimal benchmark for proving code properties
Evan Lohn and Sean Welleck. miniCodeProps: A minimal benchmark for proving code properties. 2024. arXiv:2406.11915
-
[30]
DafnyBench: A benchmark for formal software verification
Chloe Loughridge, Qinyi Sun, Seth Ahrenbach, Federico Cassano, Chuyue Sun, Ying Sheng, Anish Mudide, Md Rakib Hossain Misu, Nada Amin, and Max Tegmark. DafnyBench: A benchmark for formal software verification. 2024. arXiv:2406.08467
-
[31]
Daniel J. Mankowitz, Andrea Michi, Anton Zhernov, Marco Gelmi, Marco Selvi, Cosmin Paduraru, Edouard Leurent, Shariq Iqbal, Jean-Baptiste Lespiau, Alex Ahern, Thomas Köppe, Kevin Millikin, Stephen Gaffney, Sophie Elster, Jackson Broshear, Chris Gamble, Kieran Milan, Robert Tung, Minjae Hwang, A. Taylan Cemgil, Mohammadamin Barekatain, Yujia Li, Amol Mandh...
2023
-
[32]
Synthesis: Dreams → programs.IEEE Transactions on Software Engineering, SE-5(4):294–328, 1979
Zohar Manna and Richard Waldinger. Synthesis: Dreams → programs.IEEE Transactions on Software Engineering, SE-5(4):294–328, 1979
1979
-
[33]
A deductive approach to program synthesis.ACM Transactions on Programming Languages and Systems, 2(1):90–121, 1980
Zohar Manna and Richard Waldinger. A deductive approach to program synthesis.ACM Transactions on Programming Languages and Systems, 2(1):90–121, 1980
1980
-
[34]
Laurel: Unblocking automated verification with large language models.PACMPL (OOPSLA), 2025
Eric Mugnier, Emmanuel Anaya Gonzalez, Ranjit Jhala, Nadia Polikarpova, and Yuanyuan Zhou. Laurel: Unblocking automated verification with large language models.PACMPL (OOPSLA), 2025. arXiv:2405.16792
-
[35]
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. AlphaEvolve: A coding agent for scientific and algor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Azim Ospanov, Farzan Farnia, and Roozbeh Yousefzadeh. APOLLO: Automated LLM and Lean collabo- ration for advanced formal reasoning. 2025. arXiv:2505.05758
-
[37]
Arpaci-Dusseau, and Remzi H
Thanumalayan Sankaranarayana Pillai, Vijay Chidambaram, Ramnatthan Alagappan, Samer Al-Kiswany, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau. All file systems are not created equal: on the complexity of crafting crash-consistent applications. InProceedings of the 11th USENIX Conference on Operating Systems Design and Implementation, OSDI’14, page...
2014
-
[38]
Program synthesis from polymorphic refinement types
Nadia Polikarpova, Ivan Kuraj, and Armando Solar-Lezama. Program synthesis from polymorphic refinement types. InProceedings of the 37th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI 2016, Santa Barbara, CA, USA, June 13-17, 2016, pages 522–538. ACM, 2016. 12
2016
-
[39]
ChatDev: Communicative Agents for Software Development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. ChatDev: Communicative agents for software development. InACL, 2024. arXiv:2307.07924
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Z. Z. Ren, Zhihong Shao, Junxiao Song, Huajian Xin, Haocheng Wang, Wanjia Zhao, Liyue Zhang, Zhe Fu, Qihao Zhu, Dejian Yang, Z. F. Wu, Zhibin Gou, Shirong Ma, Hongxuan Tang, Yuxuan Liu, Wenjun Gao, Daya Guo, and Chong Ruan. DeepSeek-Prover-V2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition. 2025. arXiv:2504.21801
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Pawan Kumar, Emilien Dupont, Francisco J
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi. Mathematical discoveries from program search with large language models.Nature, 625(7995):468–475, 2024
2024
-
[42]
Ma-lot: Model-collaboration lean-based long chain-of-thought reasoning enhances formal theorem proving
W ANG Ruida, Rui Pan, Yuxin Li, Jipeng Zhang, Yizhen Jia, Shizhe Diao, Renjie Pi, Junjie Hu, and Tong Zhang. Ma-lot: Model-collaboration lean-based long chain-of-thought reasoning enhances formal theorem proving. InForty-second International Conference on Machine Learning, 2025
2025
-
[43]
Frans Kaashoek, and Nickolai Zeldovich
Upamanyu Sharma, Ralf Jung, Joseph Tassarotti, M. Frans Kaashoek, and Nickolai Zeldovich. Grove: a separation-logic library for verifying distributed systems. In Jason Flinn, Margo I. Seltzer, Peter Druschel, Antoine Kaufmann, and Jonathan Mace, editors,Proceedings of the 29th Symposium on Operating Systems Principles, SOSP 2023, Koblenz, Germany, October...
2023
-
[44]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InNeurIPS, 2023. arXiv:2303.11366
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
PhD thesis, UC Berkeley, 2008
Armando Solar-Lezama.Program Synthesis by Sketching. PhD thesis, UC Berkeley, 2008
2008
-
[46]
Seshia, and Vijay A
Armando Solar-Lezama, Liviu Tancau, Rastislav Bodík, Sanjit A. Seshia, and Vijay A. Saraswat. Combi- natorial sketching for finite programs. In John Paul Shen and Margaret Martonosi, editors,Proceedings of the 12th International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS 2006, San Jose, CA, USA, October 21-...
2006
-
[47]
Clover: Closed-loop verifiable code generation
Chuyue Sun, Ying Sheng, Oded Padon, and Clark Barrett. Clover: Closed-loop verifiable code generation. InSAIV, 2024. arXiv:2310.17807
-
[48]
Anvil: Verifying liveness of cluster management controllers
Xudong Sun, Wenjie Ma, Jiawei Tyler Gu, Zicheng Ma, Tej Chajed, Jon Howell, Andrea Lattuada, Oded Padon, Lalith Suresh, Adriana Szekeres, and Tianyin Xu. Anvil: Verifying liveness of cluster management controllers. In Ada Gavrilovska and Douglas B. Terry, editors,18th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2024, Santa Clara,...
2024
-
[49]
An in-context learning agent for formal theorem-proving
Amitayush Thakur, George Tsoukalas, Yeming Wen, Jimmy Xin, and Swarat Chaudhuri. An in-context learning agent for formal theorem-proving. InCOLM, 2024. arXiv:2310.04353
-
[50]
Ferreira, Sorin Lerner, and Emily First
Kyle Thompson, Nuno Saavedra, Pedro Carrott, Kevin Fisher, Alex Sanchez-Stern, Yuriy Brun, João F. Ferreira, Sorin Lerner, and Emily First. Rango: Adaptive retrieval-augmented proving for automated software verification. InICSE, 2025. arXiv:2412.14063. Introduces the CoqStoq benchmark
-
[51]
Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning
Haiming Wang, Mert Unsal, Xiaohan Lin, Mantas Baksys, Junqi Liu, Marco Dos Santos, Flood Sung, Marina Vinyes, Zhenzhe Ying, Zekai Zhu, Jianqiao Lu, Hugues de Saxcé, Bolton Bailey, Chendong Song, Chenjun Xiao, Dehao Zhang, Ebony Zhang, Frederick Pu, Han Zhu, Jiawei Liu, Jonas Bayer, Julien Michel, Longhui Yu, Léo Dreyfus-Schmidt, Lewis Tunstall, Luigi Paga...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Theoremllama: Transforming general-purpose llms into lean4 experts
Ruida Wang, Jipeng Zhang, Yizhen Jia, Rui Pan, Shizhe Diao, Renjie Pi, and Tong Zhang. Theoremllama: Transforming general-purpose llms into lean4 experts. In2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, pages 11953–11974. Association for Computational Linguistics (ACL), 2024
2024
-
[53]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed H. Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models.CoRR, abs/2201.11903, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[54]
Cheng Wen, Jialun Cao, Jie Su, Zhiwu Xu, Shengchao Qin, Mengda He, Haokun Li, Shing-Chi Cheung, and Cong Tian. Enchanting program specification synthesis by large language models using static analysis and program verification. 2024. arXiv:2404.00762. 13
-
[55]
Wilcox, Doug Woos, Pavel Panchekha, Zachary Tatlock, Xi Wang, Michael D
James R. Wilcox, Doug Woos, Pavel Panchekha, Zachary Tatlock, Xi Wang, Michael D. Ernst, and Thomas E. Anderson. Verdi: a framework for implementing and formally verifying distributed systems. In David Grove and Stephen M. Blackburn, editors,Proceedings of the 36th ACM SIGPLAN Conference on Programming Language Design and Implementation, Portland, OR, USA...
2015
-
[56]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst conference on language modeling, 2024
2024
-
[57]
Lorch, Shuai Lu, Fan Yang, Ziqiao Zhou, and Shan Lu
Chenyuan Yang, Xuheng Li, Md Rakib Hossain Misu, Jianan Yao, Weidong Cui, Yeyun Gong, Chris Hawblitzel, Shuvendu Lahiri, Jacob R. Lorch, Shuai Lu, Fan Yang, Ziqiao Zhou, and Shan Lu. AutoVerus: Automated proof generation for Rust code. InOOPSLA, 2025. arXiv:2409.13082
-
[58]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated software engineering. InNeurIPS,
-
[59]
Learning to prove theorems via interacting with proof assistants
Kaiyu Yang and Jia Deng. Learning to prove theorems via interacting with proof assistants. InICML,
-
[60]
Kaiyu Yang, Aidan M. Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan Prenger, and Anima Anandkumar. LeanDojo: Theorem proving with retrieval-augmented language models. InNeurIPS, 2023. arXiv:2306.15626
-
[61]
VERINA: Bench- marking verifiable code generation
Zhe Ye, Zhengxu Yan, Jingxuan He, Timothé Kasriel, Kaiyu Yang, and Dawn Song. VERINA: Bench- marking verifiable code generation. InInternational Conference on Learning Representations (ICLR),
-
[62]
Veeravalli, Aarti Gupta, and Sanjeev Arora
Haoyu Zhao, Ziran Yang, Jiawei Li, Deyuan He, Zenan Li, Chi Jin, Venugopal V . Veeravalli, Aarti Gupta, and Sanjeev Arora. AlgoVeri: An aligned benchmark for verified code generation on classical algorithms. arXiv preprint arXiv:2602.09464, 2026
-
[63]
Xueliang Zhao, Lin Zheng, Haige Bo, Changran Hu, Urmish Thakker, and Lingpeng Kong. Subgoalxl: Subgoal-based expert learning for theorem proving.arXiv preprint arXiv:2408.11172, 2024. 14 A Specifications and the IDS Suite Dataset Of the seven specifications evaluated in §5, one is Chapar’s published causal-consistency spec [26] and the other six are IDS s...
-
[64]
Read the lemma statement.What does it claim? What are the hypotheses? What is the conclusion type?
-
[65]
Identify the proof structure needed: forall x, P x→intros x ; inductive type (list, trace, nat) →induction on it; step/transition →destruct on the step type, then case analysis; simulation → invariant + induction on trace length; two functions equal→functional_extensionality
-
[66]
Suggest: prove it separately;Admitit in the main proof; close it
Identify missing helper lemmas.For each subgoal you cannot close directly, state the EXACT helper (name, signature, informal meaning). Suggest: prove it separately;Admitit in the main proof; close it
-
[67]
Cannot unify X with Y
If the proof is >30 lines, decompose:by cases ( X_case_C1, X_case_C2, . . . for each constructor); by subgoal (ifA∧B, proveAandBseparately); extract common patterns repeating3+ times. 5.Suggest specific tactic sequences,not vague directions. For compile errors,diagnose using a decision tree (e.g.,“Cannot unify X with Y” → type mismatch, use Check expr. ;“...
-
[68]
Data representation.Concrete types for state and messages: records, bounded lists, nats, not functions
-
[69]
This is the KEY creative choice; if previous attempts failed on the simulation proof, the abstraction was wrong
Abstraction function.How concrete state maps to abstract state. This is the KEY creative choice; if previous attempts failed on the simulation proof, the abstraction was wrong
-
[70]
The invariant must be (a) true initially, (b) preserved by every step, (c) strong enough to prove the final theorem
Invariant.What property holds at every reachable state. The invariant must be (a) true initially, (b) preserved by every step, (c) strong enough to prove the final theorem. 4.Proof decomposition.Which helper lemmas are needed, stated explicitly with signatures
-
[71]
skip the out-of- bound element, keep checking
Minimum information.For each function that takes a collection, could the caller pass a smaller collection and still get a correct result? The most precise design passes only what is needed per call. Output.Write META_GUIDANCE_L{N}.md as a CONCRETE blueprint a worker can directly implement: exact Record types, method signatures, abstraction function, invar...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.