RelPrism: A Multi-Faceted Pre-training Framework with Self-Generated Tasks for Relational Databases
Pith reviewed 2026-05-25 05:02 UTC · model grok-4.3
The pith
RelPrism pre-trains relational database models on pseudo-tasks drawn from intrinsic, relational, and hybrid attribute perspectives at multiple granularities to support better downstream adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
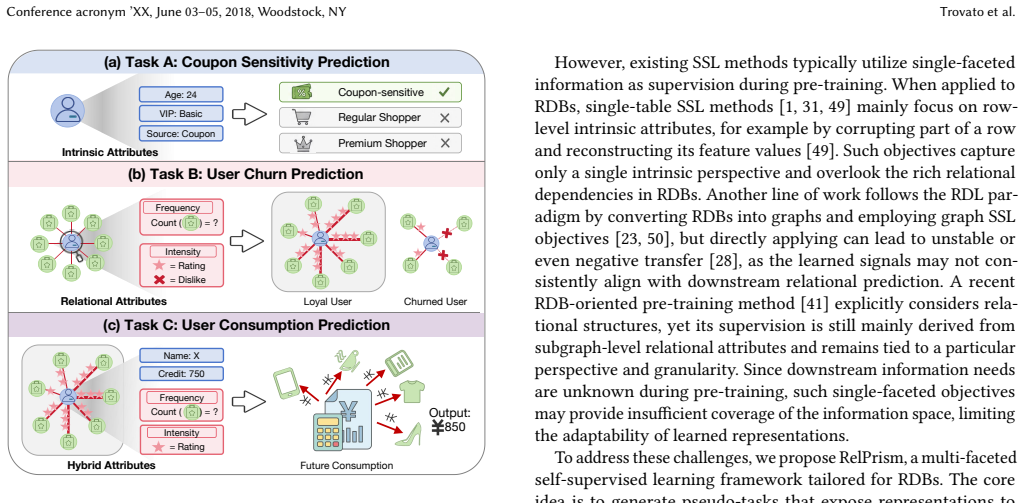
RelPrism constructs intrinsic, relational, and hybrid attributes from distinct perspectives, applies multi-granularity clustering to each perspective to form corresponding pseudo-task pools, and pre-trains over these pools to expose representations to broader perspectives and granularity levels, yielding a stronger basis for downstream adaptation.
What carries the argument
Multi-granularity clustering on intrinsic, relational, and hybrid attribute perspectives to generate pseudo-task pools for self-supervised pre-training.
If this is right
- Representations receive supervision signals from multiple attribute perspectives instead of one facet.
- The same pre-trained model can adapt to downstream tasks that emphasize interaction patterns, intrinsic attributes, or their combination.
- Performance improves on both classification measured by ROC-AUC and regression measured by MAE across real relational databases.
- Self-supervised pre-training becomes feasible without manual labels by converting clustering outputs into pseudo-tasks.
Where Pith is reading between the lines
- The same perspective-construction and clustering procedure could be tested on other structured data formats that admit multiple attribute views.
- Task-specific weighting of the three perspectives during pre-training might further reduce the gap to fully supervised performance.
- Scaling the number of granularity levels or the size of the pseudo-task pools could be examined for additional gains on larger databases.
Load-bearing premise
The pseudo-tasks generated by multi-granularity clustering on the three attribute perspectives supply transferable supervision signals that genuinely improve downstream performance rather than reflecting artifacts of the clustering process or data characteristics.
What would settle it
An ablation that removes either the three-perspective construction or the multi-granularity step and observes no drop in the reported performance margins on the fourteen tasks would falsify the claim that those design choices are responsible for the gains.
Figures







read the original abstract
Relational databases (RDBs) remain the cornerstone of modern data systems and support diverse predictive tasks. Recent relational deep learning (RDL) methods enable end-to-end prediction by converting RDBs into graphs, where rows are represented as nodes and inter-table interactions are represented as edges, and then applying graph-based models for representation learning. Despite the strong capability of RDL, effective self-supervised pre-training for RDBs remains non-trivial. RDB tasks often require multi-faceted information across different perspectives and granularities. For example, user churn classification may rely more on interaction patterns, whereas consumption value prediction requires both user-item behaviors and intrinsic user attributes for fine-grained regression. Such heterogeneous needs challenge RDB representation learning, as pre-training objectives should cover comprehensive information for downstream adaptation. However, existing SSL methods typically derive supervision from a single facet, such as node-level intrinsic attributes or subgraph-level relational structures, providing limited adaptability. To this end, we propose RelPrism, a multi-faceted self-supervised learning framework for RDBs. RelPrism constructs intrinsic, relational, and hybrid attributes from distinct perspectives, and applies multi-granularity clustering to each perspective to form corresponding pseudo-task pools. Pre-training over these pools exposes representations to broader perspectives and granularity levels, yielding a stronger basis for downstream adaptation. Experiments on 14 tasks across 5 real-world datasets show that RelPrism improves ROC-AUC by 4.15% for classification and reduces MAE by 10.75% for regression over state-of-the-art baselines. Our code is available at https://anonymous.4open.science/r/RelPrism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RelPrism, a multi-faceted self-supervised pre-training framework for relational databases. It constructs intrinsic, relational, and hybrid attributes from distinct perspectives, applies multi-granularity clustering to each to form pseudo-task pools, and pre-trains representations over these pools to improve adaptability for downstream tasks. Experiments on 14 tasks across 5 real-world datasets are reported to yield 4.15% ROC-AUC gains for classification and 10.75% MAE reduction for regression over state-of-the-art baselines.
Significance. If the empirical claims hold under proper controls, the framework could advance self-supervised learning for relational data by addressing multi-perspective and multi-granularity requirements that single-facet SSL methods overlook. The code release is a positive factor for reproducibility.
major comments (2)
- [Abstract] Abstract: The reported performance gains (4.15% ROC-AUC, 10.75% MAE) are stated without any identification of the specific baselines, dataset details, statistical significance tests, variance across runs, or ablation studies. These omissions make it impossible to evaluate whether the central claim—that multi-granularity clustering on the three attribute perspectives supplies transferable supervision—is supported by the data.
- [Abstract] Abstract (method description): The construction of 'hybrid attributes' and 'pseudo-task pools' via clustering is presented at a high level with no information on how leakage between pseudo-label generation and downstream evaluation is prevented or how the clustering process is validated to produce signals independent of data artifacts. This is load-bearing for the claim of improved downstream adaptation.
minor comments (1)
- [Abstract] The anonymous code link is standard for review but should be replaced with a permanent repository upon acceptance.
Simulated Author's Rebuttal
We thank the referee for the detailed comments on the abstract. We address each point below and note that while the abstract is intentionally concise, we agree some additional specificity can be incorporated without exceeding length limits.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported performance gains (4.15% ROC-AUC, 10.75% MAE) are stated without any identification of the specific baselines, dataset details, statistical significance tests, variance across runs, or ablation studies. These omissions make it impossible to evaluate whether the central claim—that multi-granularity clustering on the three attribute perspectives supplies transferable supervision—is supported by the data.
Authors: The abstract summarizes results at a high level, with full details provided in the Experiments section (including the five datasets, fourteen tasks, specific SOTA baselines, mean/std over five runs, significance tests, and ablations). We agree the abstract could better orient readers and will revise it to name the primary baselines and datasets while retaining conciseness. revision: yes
-
Referee: [Abstract] Abstract (method description): The construction of 'hybrid attributes' and 'pseudo-task pools' via clustering is presented at a high level with no information on how leakage between pseudo-label generation and downstream evaluation is prevented or how the clustering process is validated to produce signals independent of data artifacts. This is load-bearing for the claim of improved downstream adaptation.
Authors: The abstract is a high-level summary; the full manuscript details hybrid attribute construction (Section 3.2) and multi-granularity clustering (Section 3.3), with explicit statements that pseudo-labels are derived only from pre-training splits and that downstream data is held out. We will add one sentence to the abstract clarifying the separation of pre-training and evaluation data to address this concern directly. revision: yes
Circularity Check
No significant circularity; derivation is self-contained with external validation
full rationale
The paper describes a standard self-supervised construction: attribute perspectives are extracted from the input RDB, multi-granularity clustering produces pseudo-task pools, and representations are pre-trained on those pools before downstream adaptation. No equations, fitted parameters, or self-citations are shown that would make any claimed improvement equivalent to the inputs by construction. Performance gains are reported on 14 external downstream tasks across 5 real-world datasets against independent baselines, satisfying the criterion for non-circular empirical support. The framework does not rename known results or import uniqueness via author self-citation in the supplied text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-granularity clustering on constructed attributes produces pseudo-labels that provide transferable supervision for downstream RDB tasks
invented entities (2)
-
hybrid attributes
no independent evidence
-
pseudo-task pools
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
2022.The Kaggle Book: Data analysis and machine learning for competitive data science
Konrad Banachewicz and Luca Massaron. 2022.The Kaggle Book: Data analysis and machine learning for competitive data science. Packt Publishing Ltd
work page 2022
-
[3]
Yoshua Bengio, Aaron Courville, and Pascal Vincent. 2013. Representation learning: A review and new perspectives.IEEE transactions on pattern analysis and machine intelligence35, 8 (2013), 1798–1828
work page 2013
-
[4]
Vadim Borisov, Tobias Leemann, Kathrin Seßler, Johannes Haug, Martin Pawel- czyk, and Gjergji Kasneci. 2022. Deep neural networks and tabular data: A survey. IEEE transactions on neural networks and learning systems35, 6 (2022), 7499–7519
work page 2022
-
[5]
Tianqi Chen. 2016. XGBoost: A Scalable Tree Boosting System.Cornell University (2016)
work page 2016
- [6]
- [7]
- [8]
-
[9]
Gabriele Corso, Luca Cavalleri, Dominique Beaini, Pietro Liò, and Petar Veličković
-
[10]
Principal neighbourhood aggregation for graph nets.Advances in neural information processing systems33 (2020), 13260–13271
work page 2020
-
[11]
Alexis Cvetkov-Iliev, Alexandre Allauzen, and Gaël Varoquaux. 2023. Relational data embeddings for feature enrichment with background information.Machine Learning112, 2 (2023), 687–720
work page 2023
- [12]
-
[13]
Kaiwen Dong, Padmaja Jonnalagedda, Xiang Gao, Ayan Acharya, Maria Kissa, Mauricio Flores, Nitesh V Chawla, and Kamalika Das. 2025. Transaction Cat- egorization with Relational Deep Learning in QuickBooks. InJoint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 143–160
work page 2025
- [14]
-
[15]
Vijay Prakash Dwivedi, Charilaos Kanatsoulis, Shenyang Huang, and Jure Leskovec. 2025. Relational deep learning: Challenges, foundations and next- generation architectures. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 5999–6009
work page 2025
-
[16]
Michalis Faloutsos, Petros Faloutsos, and Christos Faloutsos. 1999. On power-law relationships of the internet topology.ACM SIGCOMM computer communication review29, 4 (1999), 251–262
work page 1999
- [17]
-
[18]
Matthias Fey, Vid Kocijan, Federico Lopez, J Lenssen, and Jure Leskovec. 2025. Kumorfm: A foundation model for in-context learning on relational data
work page 2025
-
[19]
Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-agnostic meta- learning for fast adaptation of deep networks. InInternational conference on machine learning. PMLR, 1126–1135
work page 2017
-
[20]
Jerome H Friedman. 2001. Greedy function approximation: a gradient boosting machine.Annals of statistics(2001), 1189–1232
work page 2001
-
[21]
Léo Grinsztajn, Klemens Flöge, Oscar Key, Felix Birkel, Philipp Jund, Brendan Roof, Mihir Manium, Shi Bin, Magnus Bühler, Anurag Garg, et al. 2026. TabPFN-3: Technical Report.arXiv preprint arXiv:2605.13986(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs.Advances in neural information processing systems30 (2017)
work page 2017
-
[23]
Stefan Hegselmann, Alejandro Buendia, Hunter Lang, Monica Agrawal, Xiaoyi Jiang, and David Sontag. 2023. Tabllm: Few-shot classification of tabular data with large language models. InInternational conference on artificial intelligence and statistics. PMLR, 5549–5581
work page 2023
-
[24]
Zhenyu Hou, Xiao Liu, Yukuo Cen, Yuxiao Dong, Hongxia Yang, Chunjie Wang, and Jie Tang. 2022. Graphmae: Self-supervised masked graph autoencoders. In Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining. 594–604
work page 2022
-
[25]
Kyle Hsu, Sergey Levine, and Chelsea Finn. 2018. Unsupervised learning via meta-learning.arXiv preprint arXiv:1810.02334(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[26]
James Max Kanter and Kalyan Veeramachaneni. 2015. Deep feature synthesis: Towards automating data science endeavors. In2015 IEEE international conference on data science and advanced analytics (DSAA). IEEE, 1–10
work page 2015
-
[27]
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. 2017. Lightgbm: A highly efficient gradient boosting decision tree.Advances in neural information processing systems30 (2017)
work page 2017
-
[28]
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing.ACM computing surveys55, 9 (2023), 1–35
work page 2023
-
[29]
Shengchao Liu, David Vazquez, Jian Tang, and Pierre-André Noël. 2023. Flaky performances when pretraining on relational databases (student abstract). In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 16266–16267
work page 2023
-
[30]
Stuart Lloyd. 1982. Least squares quantization in PCM.IEEE transactions on information theory28, 2 (1982), 129–137
work page 1982
-
[31]
Miller McPherson, Lynn Smith-Lovin, and James M Cook. 2001. Birds of a feather: Homophily in social networks.Annual review of sociology27, 1 (2001), 415–444
work page 2001
- [32]
-
[33]
Jennifer Neville and David Jensen. 2000. Iterative classification in relational data. InProc. AAAI-2000 workshop on learning statistical models from relational data. Austin Texas, TX, 13–20
work page 2000
-
[34]
Karl Pearson. 1901. LIII. On lines and planes of closest fit to systems of points in space.The London, Edinburgh, and Dublin philosophical magazine and journal of science2, 11 (1901), 559–572
work page 1901
-
[35]
Rishabh Ranjan, Valter Hudovernik, Mark Znidar, Charilaos Kanatsoulis, Roshan Upendra, Mahmoud Mohammadi, Joe Meyer, Tom Palczewski, Carlos Guestrin, and Jure Leskovec. 2025. Relational Transformer: Toward Zero-Shot Foundation Models for Relational Data.arXiv preprint arXiv:2510.06377(2025)
-
[36]
Joshua Robinson, Rishabh Ranjan, Weihua Hu, Kexin Huang, Jiaqi Han, Alejandro Dobles, Matthias Fey, Jan Eric Lenssen, Yiwen Yuan, Zecheng Zhang, et al. 2024. Relbench: A benchmark for deep learning on relational databases.Advances in Neural Information Processing Systems37 (2024), 21330–21341
work page 2024
-
[37]
Michael Schlichtkrull, Thomas N Kipf, Peter Bloem, Rianne Van Den Berg, Ivan Titov, and Max Welling. 2018. Modeling relational data with graph convolutional networks. InEuropean semantic web conference. Springer, 593–607
work page 2018
- [38]
-
[39]
Jake Snell, Kevin Swersky, and Richard Zemel. 2017. Prototypical networks for few-shot learning.Advances in neural information processing systems30 (2017)
work page 2017
- [40]
-
[41]
Luis Torgo and Joao Gama. 1997. Regression using classification algorithms. Intelligent Data Analysis1, 4 (1997), 275–292
work page 1997
- [42]
-
[43]
Talip Ucar, Ehsan Hajiramezanali, and Lindsay Edwards. 2021. Subtab: Subsetting features of tabular data for self-supervised representation learning.Advances in Neural Information Processing Systems34 (2021), 18853–18865
work page 2021
-
[44]
Dennis Ulmer, Lotta Meijerink, and Giovanni Cinà. 2020. Trust issues: Uncertainty estimation does not enable reliable ood detection on medical tabular data. In Machine Learning for Health. PMLR, 341–354
work page 2020
-
[45]
Petar Veličković, William Fedus, William L Hamilton, Pietro Liò, Yoshua Bengio, and R Devon Hjelm. 2018. Deep graph infomax.arXiv preprint arXiv:1809.10341 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[46]
Minjie Wang, Quan Gan, David Wipf, Zheng Zhang, Christos Faloutsos, Weinan Zhang, Muhan Zhang, Zhenkun Cai, Jiahang Li, Zunyao Mao, et al. 2024. 4DBIn- fer: A 4d benchmarking toolbox for graph-centric predictive modeling on RDBs. Advances in Neural Information Processing Systems37 (2024), 27236–27273
work page 2024
-
[47]
Tongzhou Wang and Phillip Isola. 2020. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. InInternational conference on machine learning. PMLR, 9929–9939
work page 2020
-
[48]
Xiao Wang, Houye Ji, Chuan Shi, Bai Wang, Yanfang Ye, Peng Cui, and Philip S Yu
-
[49]
InThe world wide web conference
Heterogeneous graph attention network. InThe world wide web conference. 2022–2032
work page 2022
- [50]
-
[51]
Jinsung Yoon, Yao Zhang, James Jordon, and Mihaela Van der Schaar. 2020. Vime: Extending the success of self-and semi-supervised learning to tabular domain. Advances in neural information processing systems33 (2020), 11033–11043
work page 2020
-
[52]
Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. 2020. Graph contrastive learning with augmentations.Advances in neural information processing systems33 (2020), 5812–5823. Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Trovato et al. A Dataset and Task Statistics Specific statistics regarding the datasets and task...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.