Spatio-Temporal Similarity Volume Aggregation for Open-Vocabulary Action Recognition
Pith reviewed 2026-05-25 05:11 UTC · model grok-4.3
The pith
SimVA builds a 4D similarity volume to transfer CLIP to video action recognition while preserving local patch details.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
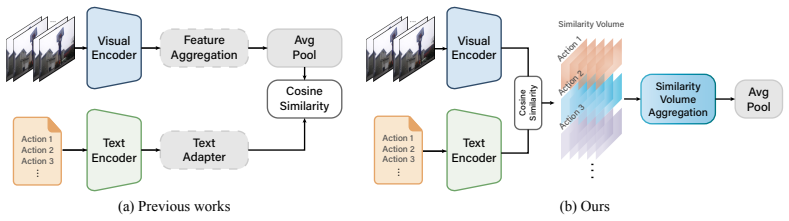
The paper claims that constructing a dense 4D spatio-temporal similarity volume over local video tokens and action classes, then refining it via class sampling, spatial aggregation, motion-aware modulation, and Mamba temporal aggregation, preserves local information and enables effective transfer of CLIP to open-vocabulary video action recognition, delivering competitive results on zero-shot, few-shot, and base-to-novel benchmarks.
What carries the argument
The 4D spatio-temporal similarity volume, which stores patch-level visual-text similarities and is refined by successive aggregation modules to maintain dense correspondence.
If this is right
- Maintains dense visual-text correspondence at every stage instead of collapsing early.
- Achieves competitive zero-shot performance on standard action recognition benchmarks.
- Generalizes in few-shot and base-to-novel settings through the same volume construction.
- Scales to large vocabularies by sampling classes before aggregation.
Where Pith is reading between the lines
- The same volume construction could be tested on other dense prediction video tasks such as temporal action localization.
- Motion-aware modulation may prove especially useful in datasets with rapid camera or actor movement.
- If the volume remains tractable, it suggests a route to adapt frozen image-text models to video without additional backbone training.
Load-bearing premise
That successive aggregation of the dense similarity volume will preserve local information and scale to large vocabularies without introducing artifacts or accuracy loss.
What would settle it
A benchmark result in which SimVA falls below global-feature baselines on a large-vocabulary zero-shot task or when actions are distinguished only by fine local patch motion.
Figures



read the original abstract
Recent Open-Vocabulary Action Recognition (OVAR) methods typically aggregate visual features into a global representation before computing text alignment, a process that obscures local patch information and fine-grained spatio-temporal cues. We propose Similarity Volume Aggregation (SimVA), a framework that constructs a dense 4D spatio-temporal similarity volume from patch-level visual-text similarities. SimVA constructs a spatio-temporal similarity volume over local video tokens and action classes, and employs class sampling to ensure similarity aggregation scalable to large vocabularies. The similarity volume is refined by spatial aggregation, which contextualizes local similarity patterns to improve intra-frame consistency. Motion-aware modulation further injects inter-frame variation cues, highlighting dynamically changing regions. Mamba-based temporal aggregation then models the evolution of class-conditioned similarity patterns across frames. By maintaining dense visual-text correspondence, SimVA effectively transfers CLIP to video action recognition, achieving competitive performance across zero-shot, few-shot, and base-to-novel benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Similarity Volume Aggregation (SimVA) for open-vocabulary action recognition. It constructs a dense 4D spatio-temporal similarity volume over local video tokens and action classes from patch-level CLIP similarities, applies class sampling for scalability to large vocabularies, then refines the volume via spatial aggregation (for intra-frame consistency), motion-aware modulation (for inter-frame cues), and Mamba-based temporal aggregation. The central claim is that this pipeline maintains dense visual-text correspondence, enabling effective CLIP transfer to video and competitive results on zero-shot, few-shot, and base-to-novel benchmarks.
Significance. If the sampling and aggregation steps can be shown to preserve the necessary local alignments, the method would address a common limitation in prior OVAR work (early global aggregation that discards patch-level cues) and provide a constructive, scalable route for dense correspondence in video tasks.
major comments (1)
- [Abstract] Abstract (and method description): class sampling is introduced explicitly 'to ensure similarity aggregation scalable to large vocabularies,' yet no derivation, bound, or analysis is supplied showing that the sampled subset retains the argmax or top-k patch-class similarities obtainable from the full vocabulary. Subsequent spatial aggregation, motion-aware modulation, and Mamba steps operate only on the reduced volume; any discarded high-similarity class cannot be recovered. This directly threatens the load-bearing premise that dense visual-text correspondence is maintained for realistic open-vocabulary settings (|C| ≫ 100).
minor comments (1)
- [Abstract] Abstract supplies no quantitative results, ablation studies, error analysis, or implementation specifics, so the performance claim cannot be checked against the described pipeline.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying this gap in the justification of class sampling. The concern is substantive and directly relevant to the scalability claim. We respond point-by-point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (and method description): class sampling is introduced explicitly 'to ensure similarity aggregation scalable to large vocabularies,' yet no derivation, bound, or analysis is supplied showing that the sampled subset retains the argmax or top-k patch-class similarities obtainable from the full vocabulary. Subsequent spatial aggregation, motion-aware modulation, and Mamba steps operate only on the reduced volume; any discarded high-similarity class cannot be recovered. This directly threatens the load-bearing premise that dense visual-text correspondence is maintained for realistic open-vocabulary settings (|C| ≫ 100).
Authors: We agree that the current manuscript provides no derivation, probabilistic bound, or empirical analysis demonstrating that the sampled class subset preserves the argmax or top-k patch-class similarities from the full vocabulary. This is a genuine limitation of the submitted version. In the revised manuscript we will (1) explicitly describe the sampling procedure (per-video selection of the K classes with highest mean token similarity), (2) add a new subsection with both theoretical discussion (under a mild assumption on similarity score concentration) and empirical measurements of top-k retention rate on the evaluation vocabularies, and (3) report an ablation that measures the performance drop when sampling is replaced by the full vocabulary on the largest benchmark vocabularies used. These additions will be placed in the method and experimental sections and will directly address whether dense correspondence is preserved after sampling. revision: yes
Circularity Check
No circularity: constructive pipeline with no self-referential reductions
full rationale
The paper describes a sequence of explicit construction steps—building a 4D similarity volume from patch-level CLIP similarities, applying class sampling for scalability, then spatial aggregation, motion-aware modulation, and Mamba temporal aggregation—without any equation or claim that reduces a derived quantity to a fitted parameter or prior self-citation by construction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatz is smuggled, and no prediction is statistically forced by an input fit. The central claim of maintaining dense correspondence is presented as a direct consequence of the described operations rather than an input assumed by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. Bain, A. Nagrani, G. Varol, and A. Zisserman. Frozen in time: A joint video and image encoder for end-to-end retrieval. InICCV, pages 1728–1738, 2021
work page 2021
-
[2]
A Short Note about Kinetics-600
J. Carreira, E. Noland, A. Banki-Horvath, C. Hillier, and A. Zisserman. A short note about kinetics-600, 2018. arXiv preprint arXiv:1808.01340
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
T. Chen, H. Yu, Z. Yang, Z. Li, W. Sun, and C. Chen. Ost: Refining text knowledge with optimal spatio-temporal descriptor for general video recognition. InCVPR, pages 18888–18898, 2024
work page 2024
- [4]
-
[5]
S. Cho, S. Hong, S. Jeon, Y . Lee, K. Sohn, and S.-W. Kim. Cats: Cost aggregation transformers for visual correspondence. InNeurIPS, pages 9011–9023, 2021
work page 2021
-
[6]
S. Cho, H. Shin, S. Hong, A. Arnab, P. H. Seo, and S.-W. Kim. Cat-seg: Cost aggregation for open-vocabulary semantic segmentation. InCVPR, pages 4113–4123, 2024
work page 2024
- [7]
-
[8]
R. Goyal, S. E. Kahou, V . Michalski, J. Materzynska, S. Westphal, H. S. Kim, V . Haenel, I. Fruend, P. Yianilos, M. Mueller-Freitag, F. Hoppe, C. Thurau, I. Bax, and R. Memisevic. The "something something" video database for learning and evaluating visual common sense. In ICCV, pages 5842–5850, 2017
work page 2017
- [9]
-
[10]
S. Hong, S. Cho, J. Nam, S. Lin, and S.-W. Kim. Cost aggregation with 4d convolutional swin transformer for few-shot segmentation. InECCV, pages 108–126, 2022
work page 2022
- [11]
-
[12]
C. Jia, Y . Yang, Y . Xia, Y .-T. Chen, Z. Parekh, H. Pham, Q. V . Le, Y . Wu, Z. Chen, and T. Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In ICML, pages 4904–4916, 2021
work page 2021
-
[13]
C. Ju, T. Han, K. Zheng, Y . Zhang, and W. Xie. Prompting visual-language models for efficient video understanding. InECCV, pages 105–124, 2022
work page 2022
-
[14]
W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijayanarasimhan, F. Viola, T. Green, T. Back, P. Natsev, M. Suleyman, and A. Zisserman. The kinetics human action video dataset,
-
[15]
arXiv preprint arXiv:1705.06950
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
M. Kim, D. Han, T. Kim, and B. Han. Leveraging temporal contextualization for video action recognition. InECCV, pages 74–91, 2024
work page 2024
- [17]
-
[18]
J. Li, D. Li, C. Xiong, and S. C. H. Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InICML, pages 12888–12900, 2022
work page 2022
-
[19]
K. Li, X. Li, Y . Wang, Y . He, Y . Wang, L. Wang, and Y . Qiao. Videomamba: State space model for efficient video understanding. InECCV, pages 237–255, 2024
work page 2024
-
[20]
L. H. Li, P. Zhang, H. Zhang, J. Yang, C. Li, Y . Zhong, and J. Gao. Grounded language-image pre-training. InCVPR, pages 10965–10975, 2022
work page 2022
- [21]
-
[22]
W. Lin, L. Karlinsky, N. Shvetsova, H. Possegger, M. Kozinski, R. Panda, and H. Bischof. Match, expand and improve: Unsupervised finetuning for zero-shot action recognition with language knowledge. InICCV, pages 2851–2862, 2023
work page 2023
-
[23]
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InICCV, pages 10012–10022, 2021
work page 2021
-
[24]
F. Long, X. Li, J. Lv, H. Yang, X. Cheng, and P. Li. Bdc-clip: Brownian distance covariance for adapting clip to action recognition. InICML, 2025
work page 2025
-
[25]
Y . Ma, G. Xu, X. Sun, M. Yan, J. Zhang, and R. Ji. X-clip: End-to-end multi-grained contrastive learning for video-text retrieval. InACM MM, pages 638–647, 2022
work page 2022
- [26]
-
[27]
J. Pan, Z. Lin, X. Zhu, J. Shao, and H. Li. St-adapter: Parameter-efficient image-to-video transfer learning. InNeurIPS, pages 26462–26477, 2022
work page 2022
-
[28]
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. InICML, pages 8748–8763, 2021
work page 2021
-
[29]
Y . Rao, W. Zhao, G. Chen, Y . Tang, Z. Zhu, G. Huang, J. Zhou, and J. Lu. Denseclip: Language- guided dense prediction with context-aware prompting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18082–18091, 2022
work page 2022
-
[30]
H. Rasheed, M. U. Khattak, M. Maaz, S. Khan, and F. S. Khan. Fine-tuned clip models are efficient video learners. InCVPR, pages 6545–6554, 2023
work page 2023
-
[31]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
K. Soomro, A. R. Zamir, and M. Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild, 2012. arXiv preprint arXiv:1212.0402
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[32]
Z. Teed and J. Deng. Raft: Recurrent all-pairs field transforms for optical flow. InECCV, pages 402–419, 2020
work page 2020
-
[33]
M. Tschannen, A. Gritsenko, X. Zhai, X. Wang, M. F. Naeem, I. Alabdulmohsin, N. Parthasarathy, and L. Beyer. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features, 2025. arXiv preprint arXiv:2502.14786
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [34]
- [35]
-
[36]
Z. Weng, X. Yang, A. Li, Z. Wu, and Y .-G. Jiang. Open-vclip: Transforming clip to an open- vocabulary video model via interpolated weight optimization. InICML, pages 36978–36989, 2023
work page 2023
-
[37]
H. Xu, G. Ghosh, P.-Y . Huang, D. Okhonko, A. Aghajanyan, F. Metze, and C. Feichtenhofer. Videoclip: Contrastive pre-training for zero-shot video-text understanding. InEMNLP, pages 6787–6800, 2021
work page 2021
- [38]
-
[39]
L. Yao, R. Huang, L. Hou, G. Lu, M. Niu, H. Xu, X. Liang, Z. Li, X. Jiang, and C. Xu. Filip: Fine-grained interactive language-image pre-training. InInternational Conference on Learning Representations, 2022
work page 2022
-
[40]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre-training. InICCV, pages 11975–11986, 2023. 11
work page 2023
- [41]
- [42]
-
[43]
X. Zhou, R. Girdhar, A. Joulin, P. Krähenbühl, and I. Misra. Detecting twenty-thousand classes using image-level supervision. InECCV, pages 350–368, 2022. 12 Appendix Overview We provide additional details in this appendix, organized as follows: •Sec. A:Detailed architecture of the aggregation modules. •Sec. B:Robustness of our method to training frame va...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.