Security, Privacy, and Ethical Risks in OpenClaw
Pith reviewed 2026-05-25 04:24 UTC · model grok-4.3
The pith
OpenClaw's architecture introduces security, privacy, and ethical risks that form major barriers to its trustworthy deployment and adoption.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
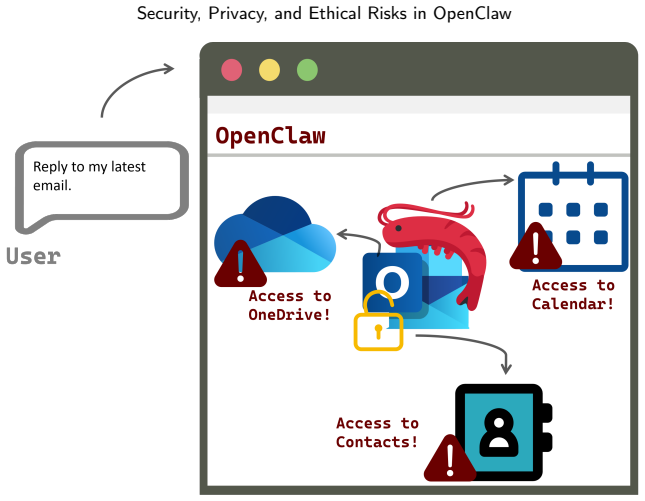
The central claim is that OpenClaw's highly privileged agent, when integrated into personal and organizational environments, raises risks from its persistent local storage, tool invocation capabilities, cross-context information aggregation, multi-user interaction features, and integration of plugins and external services, and that these issues constitute major barriers to the trustworthy deployment and widespread adoption of this technology.
What carries the argument
The system architecture and representative application scenarios of OpenClaw, which enable persistent local storage, tool invocation, cross-context aggregation, multi-user interaction, and plugin integration.
If this is right
- Persistent local storage may expose sensitive user data to unauthorized access.
- Tool invocation could enable unintended or malicious actions on connected systems.
- Cross-context information aggregation risks linking private data across domains.
- Multi-user interactions may lead to access conflicts or unauthorized sharing.
- Plugin and external service integration opens additional attack surfaces.
Where Pith is reading between the lines
- Comparable local AI agent systems would likely require similar risk analyses to ensure safe use.
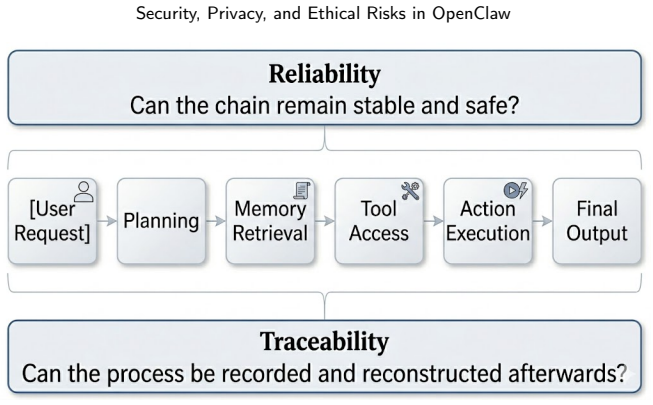
- Standardized traceability requirements could emerge as a practical response to the identified gaps.
- Developers of agent platforms might prioritize built-in controls for storage and invocation as a direct follow-on.
Load-bearing premise
That the listed risks are inherent to the system and remain unmitigated, derived solely from architectural analysis without evidence of implemented defenses or assessments of their actual likelihood and impact.
What would settle it
Empirical testing of OpenClaw in real deployments that shows effective mitigation of the risks through existing or added security measures, or quantitative risk assessments indicating negligible impact.
Figures



read the original abstract
This paper systematically investigates the security, privacy, and ethical risks, as well as the traceability challenges of OpenClaw, a locally executable AI agent system for natural language interaction and real-world task completion. While OpenClaw shows strong potential for personal assistance, office automation, cross-platform task management, and information integration, it also raises serious security, privacy, and ethical concerns. By analyzing its system architecture, core functionalities, deployment model, and representative application scenarios, this paper aims to reveal the risks that may arise when such a highly privileged agent is integrated into personal and organizational digital environments. We focus in particular on the challenges associated with persistent local storage, tool invocation, cross-context information aggregation, multi-user interaction, and the integration of plugins and external services. We argue that these issues constitute major barriers to the trustworthy deployment and widespread adoption of this technology. Finally, we summarize the open challenges in security defenses, privacy protection, ethical governance, and traceability in agent use, and call for joint efforts from researchers, developers, deployers, and regulators to build AI agent systems that are safer, more reliable, and more trustworthy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript systematically investigates security, privacy, and ethical risks, as well as traceability challenges, in OpenClaw, a locally executable AI agent system. Through analysis of its system architecture, core functionalities, deployment model, and representative application scenarios, it identifies risks associated with persistent local storage, tool invocation, cross-context information aggregation, multi-user interaction, and plugin integration with external services. The paper argues that these issues constitute major barriers to trustworthy deployment and widespread adoption, summarizes open challenges in defenses, protection, governance, and traceability, and calls for joint efforts by researchers, developers, deployers, and regulators.
Significance. If the qualitative analysis holds and the enumerated risks are shown to be both inherent and resistant to standard controls, the work would usefully contribute to the literature on AI agent security by providing a structured enumeration of concerns specific to locally executable, highly privileged agents. It could inform design choices and regulatory discussions around personal assistance and office automation tools. The paper's strength lies in its focus on a concrete system and its explicit call for multi-stakeholder collaboration, though its impact is constrained by the lack of quantitative severity assessment or mitigation evaluation.
major comments (1)
- [Abstract] Abstract and § on risk analysis (architecture and scenarios): the central claim that the five listed features 'constitute major barriers to the trustworthy deployment and widespread adoption' is load-bearing but unsupported. The text enumerates potential risks from persistent local storage, tool invocation, cross-context aggregation, multi-user interaction, and plugin integration, yet provides no demonstration that standard mechanisms (sandboxing, capability-based access control, audit logging, or consent flows) would be inadequate, nor any attack traces, probability/impact estimates, or residual-risk evaluation after mitigations. This leaves the 'major barriers' conclusion dependent on the untested premise that the risks are both inherent and effectively unmitigable.
minor comments (1)
- [Abstract] The abstract and conclusion sections could more explicitly distinguish between risks that are unique to OpenClaw versus those common to other agent frameworks, to strengthen the novelty of the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive critique, which highlights an important gap in supporting our central claim. We address the comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract and § on risk analysis (architecture and scenarios): the central claim that the five listed features 'constitute major barriers to the trustworthy deployment and widespread adoption' is load-bearing but unsupported. The text enumerates potential risks from persistent local storage, tool invocation, cross-context aggregation, multi-user interaction, and plugin integration, yet provides no demonstration that standard mechanisms (sandboxing, capability-based access control, audit logging, or consent flows) would be inadequate, nor any attack traces, probability/impact estimates, or residual-risk evaluation after mitigations. This leaves the 'major barriers' conclusion dependent on the untested premise that the risks are both inherent and effectively unmitigable.
Authors: We agree that the manuscript's qualitative enumeration of risks does not include quantitative severity assessments, explicit attack traces, or systematic evaluation of residual risk after applying standard controls such as sandboxing or capability-based access. The paper's analysis is grounded in the architectural requirements of OpenClaw (local execution with persistent storage and broad tool privileges needed for its intended functionality), which we argue create tensions that standard mechanisms cannot fully resolve without reducing utility. However, we acknowledge this reasoning is presented at a high level without detailed mitigation analysis. We will revise the abstract and the risk-analysis sections to (1) explicitly state the qualitative basis of the 'major barriers' claim, (2) add a short discussion of why certain standard controls are likely to be insufficient given the agent's design goals, and (3) temper the language to reflect the absence of quantitative evidence while preserving the call for further multi-stakeholder work. revision: yes
Circularity Check
No circularity: qualitative risk enumeration from architecture is self-contained
full rationale
The paper performs a direct architectural analysis to enumerate risks (persistent storage, tool invocation, cross-context aggregation, etc.) and concludes they form major barriers. No equations, fitted parameters, predictions, or self-citations appear in the provided text. The central claim follows from describing the system features without any reduction of outputs to inputs by construction, self-definition, or load-bearing self-reference. This is a standard qualitative review with no derivation chain that collapses into its own premises.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Chase, Langchain,https://github.com/langchain-ai/langchain, software, accessed 2026-03-24 (2022)
H. Chase, Langchain,https://github.com/langchain-ai/langchain, software, accessed 2026-03-24 (2022)
work page 2026
-
[4]
P.Steinberger,theOpenClawCommunity,Openclaw,https://github.com/openclaw/openclaw,software,accessed2026-03-24(2026)
work page 2026
-
[5]
H. Su, J. Luo, C. Liu, X. Yang, Y. Zhang, Y. Dong, J. Zhu, A survey on autonomy-induced security risks in large model-based agents, arXiv preprint arXiv:2506.23844 (2025). First Author et al.:Preprint submitted to ElsevierPage 19 of 21 Security, Privacy, and Ethical Risks in OpenClaw
-
[6]
Z.Deng,Y.Guo,C.Han,W.Ma,J.Xiong,S.Wen,Y.Xiang,Aiagentsunderthreat:Asurveyofkeysecuritychallengesandfuturepathways, ACM Computing Surveys 57 (7) (2025) 1–36
work page 2025
- [7]
-
[8]
The Dark Side of LLMs: Agent-based Attack Vectors for System-level Compromise
M. Lupinacci, F. A. Pironti, F. Blefari, F. Romeo, L. Arena, A. Furfaro, The dark side of llms: Agent-based attacks for complete computer takeover, arXiv preprint arXiv:2507.06850 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
ReAct: Synergizing Reasoning and Acting in Language Models
S.Yao,J.Zhao,D.Yu,N.Du,I.Shafran,K.Narasimhan,Y.Cao,React:Synergizingreasoningandactinginlanguagemodels,in:International Conference on Learning Representations (ICLR), 2023. URLhttps://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Generative Agents: Interactive Simulacra of Human Behavior
J.S.Park,J.C.O’Brien,C.J.Cai,M.R.Morris,P.Liang,M.S.Bernstein,Generativeagents:Interactivesimulacraofhumanbehavior,arXiv preprint arXiv:2304.03442 (2023). URLhttps://arxiv.org/abs/2304.03442
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
L.Weng,Llmpoweredautonomousagents,https://lilianweng.github.io/posts/2023-06-23-agent/,lil’Log,accessed2026-03- 24 (Jun. 2023)
work page 2023
-
[12]
K.Greshake,S.Abdelnabi,S.Mishra,C.Endres,T.Holz,M.Fritz,Notwhatyou’vesignedupfor:Compromisingreal-worldLLM-integrated applicationswithindirectpromptinjection,in:Proceedingsofthe16thACMWorkshoponArtificialIntelligenceandSecurity(AISec@CCS), 2023
work page 2023
-
[13]
Defeating Prompt Injections by Design
E. Debenedetti, et al., CaMeL: Capability-based security for LLM agents, arXiv preprint arXiv:2503.18813Google DeepMind/ETH Zurich (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Q. Zhan, Z. Liang, Z. Ying, D. Kang, InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents, in: Findings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 10471–10506
work page 2024
-
[15]
E. Debenedetti, J. Zhang, M. Balunović, L. Beurer-Kellner, M. Fischer, F. Tramèr, AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents, in: NeurIPS 2024, Datasets and Benchmarks Track, 2024
work page 2024
-
[16]
M.Nasr,N.Carlini,etal.,Theattackermovessecond,arXivpreprintarXiv:2510.09023JointOpenAI/Anthropic/GoogleDeepMindevaluation (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [17]
- [18]
- [19]
-
[20]
Wang, MCPTox: A systematic benchmark for MCP server security, arXiv preprint arXiv:2508.14925 (2025)
o. Wang, MCPTox: A systematic benchmark for MCP server security, arXiv preprint arXiv:2508.14925 (2025)
-
[21]
X. Gu, X. Zheng, T. Pang, C. Du, Q. Liu, Y. Wang, J. Jiang, M. Lin, Agent smith: A single image can jailbreak one million multimodal LLM agents exponentially fast, in: International Conference on Machine Learning (ICML), 2024
work page 2024
- [22]
-
[23]
T. Peigné-Lefebvre, et al., The multi-agent security tax, in: AAAI Conference on Artificial Intelligence, 2025, arXiv:2502.19145
- [24]
-
[25]
OpenClaw, Openclaw trust center,https://trust.openclaw.ai/, accessed: 2026-03-19 (2026)
work page 2026
-
[26]
OpenClaw Documentation, Gateway security,https://docs.openclaw.ai/gateway/security, accessed: 2026-03-19 (2026)
work page 2026
-
[27]
Microsoft Security, Running openclaw safely: Identity, isolation, and runtime risk,https://www.microsoft.com/en-us/security/ blog/2026/02/19/running-openclaw-safely-identity-isolation-runtime-risk/, accessed: 2026-03-19 (2026)
work page 2026
-
[28]
OpenClaw Documentation, Memory - openclaw,https://docs.openclaw.ai/concepts/memory, accessed: 2026-03-19 (2026)
work page 2026
-
[29]
OpenClawDocumentation,Pluginarchitecture-openclaw,https://docs.openclaw.ai/plugins/architecture,accessed:2026-03-19 (2026)
work page 2026
-
[30]
OpenClaw Documentation, Multi-agent routing - openclaw,https://docs.openclaw.ai/concepts/multi-agent, accessed: 2026-03- 19 (2026)
work page 2026
-
[31]
OpenClaw Documentation, Context - openclaw,https://docs.openclaw.ai/concepts/context, accessed: 2026-03-19 (2026)
work page 2026
- [32]
- [33]
- [34]
-
[35]
AgentCrypt: Advancing Privacy and (Secure) Computation in AI Agent Collaboration
H. Karthikeyan, Y. Guo, L. de Castro, A. Polychroniadou, L. Ardon, U. M. Sehwag, S. Ganesh, M. Veloso, Agentcrypt: Advancing privacy and (secure) computation in ai agent collaboration (2025).arXiv:2512.08104. URLhttps://arxiv.org/abs/2512.08104
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
25013–25030.doi:10.18653/v1/2025.acl-long.1227
B.Wang,W.He,P.He,S.Zeng,Z.Xiang,Y.Xing,J.Tang,Unveilingprivacyrisksinllmagentmemory,in:Proceedingsofthe63rdAnnual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Association for Computational Linguistics, 2025, pp. 25013–25030.doi:10.18653/v1/2025.acl-long.1227. URLhttps://aclanthology.org/2025.acl-long.1227/
-
[37]
B.D.Sunil,I.Sinha,P.Maheshwari,S.Todmal,S.Mallik,S.Mishra,Memorypoisoningattackanddefenseonretrieval-augmentedgeneration based llm agents (2026).arXiv:2601.05504. URLhttps://arxiv.org/abs/2601.05504 First Author et al.:Preprint submitted to ElsevierPage 20 of 21 Security, Privacy, and Ethical Risks in OpenClaw
-
[38]
K. Zhu, X. Yang, J. Wang, W. Guo, W. Y. Wang, Melon: Indirect prompt injection defense via masked re-execution and tool comparison, in: Proceedings of the 42nd International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=gt1MmGaKdZ
work page 2025
-
[39]
H.Li,X.Liu,H.-C.Chiu,D.Li,N.Zhang,C.Xiao,Drift:Dynamicrule-baseddefensewithinjectionisolationforsecuringllmagents(2025). arXiv:2506.12104. URLhttps://arxiv.org/abs/2506.12104
-
[40]
rep., World Economic Forum (Nov
World Economic Forum, Ai agents in action: Foundations for evaluation and governance, Tech. rep., World Economic Forum (Nov. 2025). URLhttps://reports.weforum.org/docs/WEF_AI_Agents_in_Action_Foundations_for_Evaluation_and_Governance_ 2025.pdf
work page 2025
-
[41]
M. Hahn, M. Tretter, P. Dabrock, Ethical perspectives on AI agents and agentic AI, AI and Ethics 6 (2026) 218.doi:10.1007/ s43681-026-01027-0. URLhttps://link.springer.com/article/10.1007/s43681-026-01027-0
-
[42]
N. Kosmyna, E. Hauptmann, Y. T. Yuan, J. Situ, X.-H. Liao, A. V. Beresnitzky, I. Braunstein, P. Maes, Your brain on chatgpt: Accumulation of cognitive debt when using an ai assistant for essay writing task (2025).arXiv:2506.08872. URLhttps://arxiv.org/abs/2506.08872
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
M. Constantinescu, M. Kaptein, Responsibility gaps, LLMs & organisations: Many agents, many levels, and many interactions, Science and Engineering Ethics 31 (2025) 36.doi:10.1007/s11948-025-00560-1. URLhttps://doi.org/10.1007/s11948-025-00560-1
-
[44]
B. Lange, G. Keeling, A. Manzini, A. McCroskery, We need accountability in human–AI agent relationships, npj Artificial Intelligence 1 (2025) 38.doi:10.1038/s44387-025-00041-7. URLhttps://doi.org/10.1038/s44387-025-00041-7
-
[45]
Organisation for Economic Co-operation and Development, The agentic ai landscape and its conceptual foundations, Tech. Rep. 56, OECD Publishing, Paris (Feb. 2026).doi:10.1787/396cf758-en. URLhttps://doi.org/10.1787/396cf758-en
-
[46]
Blaise, Openclaw agents can be guilt-tripped into self-sabotage, WIRED (Mar
D. Blaise, Openclaw agents can be guilt-tripped into self-sabotage, WIRED (Mar. 2026). URLhttps://www.wired.com/story/openclaw-ai-agent-manipulation-security-northeastern-study/
work page 2026
-
[47]
URLhttps://arxiv.org/abs/2601.06223
E.C.Cheng,J.Cheng,A.Siu,Towardsafeandresponsibleaiagents:Athree-pillarmodelfortransparency,accountability,andtrustworthiness (2026).arXiv:2601.06223. URLhttps://arxiv.org/abs/2601.06223
- [48]
-
[49]
S. Rabanser, S. Kapoor, P. Kirgis, K. Liu, S. Utpala, A. Narayanan, Towards a science of ai agent reliability (2026).arXiv:2602.16666, doi:10.48550/arXiv.2602.16666. URLhttps://arxiv.org/abs/2602.16666
-
[50]
R. Souza, A. Gueroudji, S. DeWitt, D. Rosendo, T. Ghosal, R. Ross, P. Balaprakash, R. F. da Silva, Prov-agent: Unified provenance for tracking ai agent interactions in agentic workflows, in: 2025 IEEE International Conference on eScience (eScience), 2025.doi:10.1109/ eScience65000.2025.00093. URLhttps://arxiv.org/abs/2508.02866
- [51]
-
[52]
First Author et al.:Preprint submitted to ElsevierPage 21 of 21
OpenTelemetry, Semantic conventions for genai agent and framework spans,https://opentelemetry.io/docs/specs/semconv/ gen-ai/gen-ai-agent-spans/, openTelemetry specification, accessed 2026-03-31 (2025). First Author et al.:Preprint submitted to ElsevierPage 21 of 21
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.