Hinge Regression Trees and HRT-Boost: Newton-Optimized Oblique Learning for Compact Tabular Models
Pith reviewed 2026-05-25 04:49 UTC · model grok-4.3
The pith
Hinge regression trees reframe oblique splits as Newton-optimized least-squares problems to establish universal approximation with quadratic rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
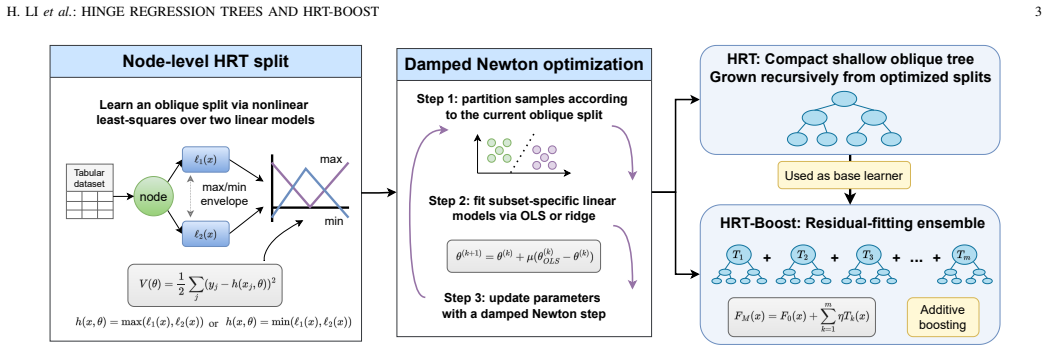
By recasting each oblique split as a nonlinear least-squares problem over two linear predictors whose max/min envelope supplies ReLU-like capacity, the node optimization becomes a damped Newton method whose backtracking variant monotonically decreases the local objective. This construction makes the Hinge Regression Tree a universal approximator with an explicit O(δ²) approximation rate. The same machinery extends to HRT-Boost, which couples the per-node Newton steps with stage-wise functional gradient descent and thereby admits a stage-wise empirical-risk-reduction guarantee under squared loss.
What carries the argument
The hinge regression tree, which converts each oblique split into a nonlinear least-squares problem over two linear predictors whose max/min envelope supplies the needed representation capacity.
If this is right
- HRT single trees match the accuracy of established oblique-tree baselines on tabular data.
- HRT-Boost ensembles deliver stage-wise decreases in squared empirical risk.
- The models produced are substantially more compact than competing ensembles while remaining competitive in accuracy.
- Node-level objectives decrease monotonically under the backtracking line-search variant.
- The explicit O(δ²) rate supplies a concrete quantitative guarantee on how well the trees can approximate continuous functions.
Where Pith is reading between the lines
- The ReLU-like envelope may let practitioners import approximation results already known for shallow ReLU networks into the tree setting.
- Compactness could translate into lower memory and latency when the models are deployed on edge devices that process tabular streams.
- The stage-wise risk guarantee is stated only for squared loss; analogous guarantees for other convex losses remain open.
- Because each node solve is a damped Newton step, the method may combine naturally with second-order boosting variants that already use Hessian information.
Load-bearing premise
Treating the original discrete split choice as the max or min envelope of two linear predictors must faithfully reproduce the discrete optimization without adding bias or shrinking the representable function class.
What would settle it
Construct a target function such as a simple step or quadratic on a fine grid, fit an HRT with successively smaller discretization parameter δ, and measure whether the approximation error decreases quadratically; any observed rate slower than O(δ²) would falsify the universal-approximation claim.
Figures




read the original abstract
Learning high-quality oblique decision trees remains a significant challenge due to the discrete and non-convex nature of split optimization. We present the Hinge Regression Tree (HRT) framework, which reframes each oblique split as a nonlinear least-squares problem over two linear predictors whose max/min envelope induces ReLU-like representation capacity. We show that the resulting node-level optimization can be interpreted as a damped Newton method, and we establish the monotonic decrease of the node objective for its backtracking line-search variant. We establish, theoretically, that HRT is a universal approximator with an explicit $O(\delta^2)$ approximation rate. Building upon this base learner, we propose HRT-Boost, a mathematically synergistic ensemble extension that couples node-level Newton updates with stage-wise functional gradient descent. We show that this ensemble construction admits a stage-wise empirical risk reduction guarantee under the squared loss. Empirical evaluations on synthetic and real-world benchmarks show that HRT is highly competitive with established single-tree baselines, and HRT-Boost compares favorably with strong ensemble baselines and often yields substantially more compact models. The code is publicly available at https://github.com/Hongyi-Li-sz/HRT-Boost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Hinge Regression Trees (HRT), reframing each oblique split as a nonlinear least-squares problem over two linear predictors whose max/min envelope induces ReLU-like capacity. Node optimization is interpreted as a damped Newton method with a backtracking line-search variant that guarantees monotonic decrease of the node objective. The paper claims HRT is a universal approximator with an explicit O(δ²) approximation rate. HRT-Boost extends this by coupling node-level Newton updates with stage-wise functional gradient descent, yielding a stage-wise empirical risk reduction guarantee under squared loss. Experiments on synthetic and real-world data show HRT competitive with single-tree baselines and HRT-Boost favorable to ensemble baselines while producing more compact models.
Significance. If the envelope construction faithfully reproduces the function class of discrete oblique splits and the stated approximation rate and risk-reduction guarantees are rigorously established, the work supplies a continuous, Newton-optimizable surrogate for oblique tree learning together with explicit rates and monotonicity, which could enable more compact and theoretically grounded tabular models. Public code availability is a positive factor for reproducibility.
major comments (2)
- [Abstract] Abstract: the universal-approximation claim with explicit O(δ²) rate rests on the max/min-envelope construction being a faithful surrogate for discrete oblique hyperplane splits. No explicit statement or argument is supplied that the continuous optimum coincides with the discrete argmin or that every piecewise-linear partition inducible by standard oblique splits is realizable by the envelope; if the classes differ, both the rate and the subsequent boosting guarantees apply only to the relaxed model.
- [Abstract] Abstract (stage-wise risk reduction): the claim that coupling node-level Newton updates with functional gradient descent yields a stage-wise empirical risk reduction guarantee under squared loss is presented without the governing equations or derivation. It is therefore impossible to determine whether the result is independent or reduces to standard boosting analysis; this is load-bearing for the HRT-Boost contribution.
minor comments (1)
- [Abstract] The symbol δ appearing in the O(δ²) rate is not defined in the abstract; its meaning (e.g., maximum leaf diameter, mesh size) should be stated explicitly when the rate is introduced.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and the opportunity to address these important points regarding the theoretical claims in our manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the universal-approximation claim with explicit O(δ²) rate rests on the max/min-envelope construction being a faithful surrogate for discrete oblique hyperplane splits. No explicit statement or argument is supplied that the continuous optimum coincides with the discrete argmin or that every piecewise-linear partition inducible by standard oblique splits is realizable by the envelope; if the classes differ, both the rate and the subsequent boosting guarantees apply only to the relaxed model.
Authors: We acknowledge that the abstract does not explicitly detail the equivalence between the envelope construction and discrete oblique splits. The theoretical development in the manuscript is based on the envelope being a faithful surrogate, as the max/min of two linear functions can induce the same piecewise linear partitions as oblique splits by appropriate parameter choice. The O(δ²) rate is derived for this class. To address the concern, we will revise the abstract to include a short statement affirming that the continuous model class includes the discrete oblique splits and that the optimum coincides. revision: yes
-
Referee: [Abstract] Abstract (stage-wise risk reduction): the claim that coupling node-level Newton updates with functional gradient descent yields a stage-wise empirical risk reduction guarantee under squared loss is presented without the governing equations or derivation. It is therefore impossible to determine whether the result is independent or reduces to standard boosting analysis; this is load-bearing for the HRT-Boost contribution.
Authors: We agree the abstract omits the equations for brevity. The stage-wise guarantee is derived by showing that each HRT node update corresponds to a functional gradient step with Newton damping, leading to monotonic risk reduction independent of standard boosting because the per-node optimization is exact for the hinge regression. The full equations and proof are in the main body. We will update the abstract to mention the key coupling mechanism briefly. revision: yes
Circularity Check
No significant circularity; derivation chain remains independent of inputs
full rationale
The abstract and provided excerpts present a reframing of oblique splits into a nonlinear least-squares problem over max/min envelopes of linear predictors, followed by Newton-method interpretation, monotonicity via line search, an explicit O(δ²) universal-approximation rate, and a stage-wise risk-reduction guarantee obtained by coupling node-level Newton steps with functional gradient descent under squared loss. None of these steps are shown to reduce by construction to fitted parameters, self-citations, or definitional renaming; the approximation rate and monotonicity claims are stated as derived results rather than tautologies. The stage-wise guarantee is described as arising from the specific coupling, not merely restating standard boosting analysis. No load-bearing self-citation chains or ansatz smuggling are exhibited in the given text. The derivation therefore qualifies as self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The max/min envelope of two linear predictors induces ReLU-like representation capacity
Reference graph
Works this paper leans on
-
[1]
Hinge regression tree: A newton method for oblique regression tree splitting,
H. Li, H. Lin, and J. Xu, “Hinge regression tree: A newton method for oblique regression tree splitting,” inInternational Conference on Learning Representations (ICLR), 2026
work page 2026
-
[2]
L. Breiman, J. H. Friedman, R. A. Olshen, and C. J. Stone,Classification and Regression Trees. Wadsworth International Group, 1984
work page 1984
- [3]
-
[4]
A system for induction of oblique decision trees,
S. K. Murthy, S. Kasif, and S. Salzberg, “A system for induction of oblique decision trees,”Journal of Artificial Intelligence Research, vol. 2, pp. 1–32, 1994. 14 IEEE TRANSACTIONS ON XXXX, VOL. 00, NO. 0, MONTH 2026
work page 1994
-
[5]
Constructing optimal binary decision trees is NP-complete,
H. Laurent and R. L. Rivest, “Constructing optimal binary decision trees is NP-complete,”Information Processing Letters, vol. 5, no. 1, pp. 15– 17, 1976
work page 1976
-
[6]
Lower bounds on learning decision lists and trees,
T. Hancock, T. Jiang, M. Li, and J. Tromp, “Lower bounds on learning decision lists and trees,”Information and Computation, vol. 126, no. 2, pp. 114–122, 1996
work page 1996
-
[7]
Fifty years of classification and regression trees,
W.-Y . Loh, “Fifty years of classification and regression trees,”Interna- tional Statistical Review, vol. 82, no. 3, pp. 329–348, 2014
work page 2014
-
[8]
Vanilla gradient descent for oblique decision trees,
S. P. Panda, B. Genest, A. Easwaran, and P. N. Suganthan, “Vanilla gradient descent for oblique decision trees,”arXiv preprint arXiv:2408.09135, 2024
-
[9]
Learning accurate decision trees with bandit feedback via quantized gradient descent,
A. Karthikeyan, N. Jain, N. Natarajan, and P. Jain, “Learning accurate decision trees with bandit feedback via quantized gradient descent,” Transactions on Machine Learning Research, 2022
work page 2022
-
[10]
Improving the precision of classification trees,
W.-Y . Loh, “Improving the precision of classification trees,”The Annals of Applied Statistics, pp. 1710–1737, 2009
work page 2009
-
[11]
Alternating optimization of decision trees, with application to learning sparse oblique trees,
M. A. Carreira-Perpin ´an and P. Tavallali, “Alternating optimization of decision trees, with application to learning sparse oblique trees,” in Advances in Neural Information Processing Systems, 2018
work page 2018
-
[12]
Xgboost: A scalable tree boosting system,
T. Chen and C. Guestrin, “Xgboost: A scalable tree boosting system,” inProceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, 2016, pp. 785–794
work page 2016
-
[13]
LightGBM: A highly efficient gradient boosting decision tree,
G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye, and T.-Y . Liu, “LightGBM: A highly efficient gradient boosting decision tree,” in Advances in Neural Information Processing Systems, vol. 30. Curran Associates, Inc., 2017
work page 2017
-
[14]
A decision-theoretic generalization of on-line learning and an application to boosting,
Y . Freund and R. E. Schapire, “A decision-theoretic generalization of on-line learning and an application to boosting,”Journal of computer and system sciences, vol. 55, no. 1, pp. 119–139, 1997
work page 1997
-
[15]
The random subspace method for constructing decision forests,
T. K. Ho, “The random subspace method for constructing decision forests,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, vol. 20, no. 8, pp. 832–844, 1998
work page 1998
-
[16]
Greedy function approximation: a gradient boosting machine,
J. H. Friedman, “Greedy function approximation: a gradient boosting machine,”Annals of statistics, pp. 1189–1232, 2001
work page 2001
-
[17]
Learning nonlinear functions using regular- ized greedy forest,
R. Johnson and T. Zhang, “Learning nonlinear functions using regular- ized greedy forest,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 36, no. 5, pp. 942–954, 2014
work page 2014
-
[18]
Tabnet: Attentive interpretable tabular learn- ing,
S. ¨O. Arik and T. Pfister, “Tabnet: Attentive interpretable tabular learn- ing,” inProceedings of the AAAI conference on artificial intelligence, vol. 35, no. 8, 2021, pp. 6679–6687
work page 2021
-
[19]
Tabm: Advancing tabular deep learning with parameter-efficient ensembling,
Y . Gorishniy, A. Kotelnikov, and A. Babenko, “Tabm: Advancing tabular deep learning with parameter-efficient ensembling,” inInternational Conference on Learning Representations, 2025
work page 2025
-
[20]
Approximation by superpositions of a sigmoidal function,
G. Cybenko, “Approximation by superpositions of a sigmoidal function,” Mathematics of Control, Signals and Systems, vol. 2, no. 4, pp. 303–314, 1989
work page 1989
-
[21]
Approximation capabilities of multilayer feedforward net- works,
K. Hornik, “Approximation capabilities of multilayer feedforward net- works,”Neural Networks, vol. 4, no. 2, pp. 251–257, 1991
work page 1991
-
[22]
Convergence rates of oblique regression trees for flexible function libraries,
M. D. Cattaneo, R. Chandak, and J. M. Klusowski, “Convergence rates of oblique regression trees for flexible function libraries,”The Annals of Statistics, vol. 52, no. 2, pp. 466–490, 2024
work page 2024
-
[23]
Hinging hyperplanes for regression, classification, and function approximation,
L. Breiman, “Hinging hyperplanes for regression, classification, and function approximation,”IEEE Transactions on Information Theory, vol. 39, no. 3, pp. 999–1013, 1993
work page 1993
-
[24]
C. Cortes and V . Vapnik, “Support-vector networks,”Machine Learning, vol. 20, no. 3, pp. 273–297, 1995
work page 1995
-
[25]
Rectified linear units improve restricted boltz- mann machines,
V . Nair and G. E. Hinton, “Rectified linear units improve restricted boltz- mann machines,” inProceedings of the 27th International Conference on Machine Learning (ICML), 2010, pp. 807–814
work page 2010
-
[26]
Deep sparse rectifier neural networks,
X. Glorot, A. Bordes, and Y . Bengio, “Deep sparse rectifier neural networks,” inProceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics. JMLR Workshop and Conference Proceedings, 2011, pp. 315–323
work page 2011
-
[27]
Non-greedy algorithms for decision tree optimization: An experimental comparison,
A. Zharmagambetov, S. S. Hada, M. Gabidolla, and M. A. Carreira- Perpin´an, “Non-greedy algorithms for decision tree optimization: An experimental comparison,” in2021 International Joint Conference on Neural Networks (IJCNN). IEEE, 2021, pp. 1–8
work page 2021
-
[28]
Inducing model trees for continuous classes,
Y . Wang and I. H. Witten, “Inducing model trees for continuous classes,” inProceedings of the ninth European conference on machine learning, vol. 9, no. 1, 1997, pp. 128–137
work page 1997
-
[29]
Linear-tree: A python library for model trees with linear models at the leaves,
M. Cerliani, “Linear-tree: A python library for model trees with linear models at the leaves,” https://github.com/cerlymarco/linear-tree, 2022
work page 2022
-
[30]
L. Breiman, “Random forests,”Machine learning, vol. 45, no. 1, pp. 5–32, 2001
work page 2001
-
[31]
Scikit-learn: Machine learning in python,
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourget al., “Scikit-learn: Machine learning in python,”Journal of machine learning research, vol. 12, no. Oct, pp. 2825–2830, 2011. Hongyi Lireceived his B.S. degree in Automation and M.S. degree in Control Science and Engineering from...
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.